LDA PCA 学习笔记
提要:
本文主要介绍了和推导了LDA和PCA,参考了这篇博客
LDA
LDA的原理是,将带上标签的数据(点),通过投影的方法,投影到维度更低的空间中,使得投影后的点,会形成按类别区分,一簇一簇的情况,相同类别的点,将会在投影后的空间中更接近。要说明白LDA,首先得弄明白线性分类器(Linear Classifier):因为LDA是一种线性分类器。对于K-分类的一个分类问题,会有K个线性函数:
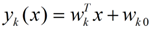
PS 上面一大段话完全可以不看,看不懂也完全没有关系,你只要知道不同类的x,经过上面那个式子算出y(x和y的维数可能不同,一般y的维数要小一点,因为LDA和PCA就是用来降维的嘛,PPS就是用维数较低的数据就可以将较高维的数据分开)后仍然可以分开就行了。举个例子吧,二维数据x分为两类,其中第一类都在第一、四象限,如(1,0)、(7,7)等等,第二类则都在第二象限,如(-1,2)、(-5,8)等等,然后你选取合适的wk,带入的式子可以有第一类算出的y都大于0,而第二类y都小于0(这里只是假设为0,实际上算出来可能是其他的数),这样是不是仅用y的大小就能表示出两类的区别了啊,下面讲的就是怎么求出合适的wk。
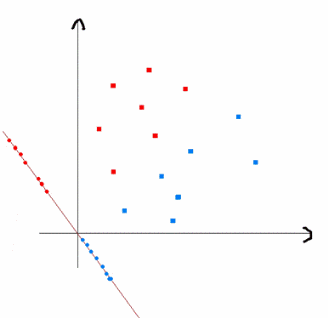
此图是原博客主举得例子,可以看出红蓝在那条直线上的投影,就是降维的操作
在这里我们应当考虑用什么标准考量投影后的数据的好坏了(即y的分布了),自然而然,我们希望
1、原来的就是不同类的x计算成y以后也能分的越开越好(如上图的那些在线上的红点和蓝点分的越开越好),
2、而同一类则离得越近越好(如上图中我们希望映射后的红点我们希望他可以更密集些)
对于1,我们选取了每类的中心点用来衡量他们的距离,而2,我们用了万能的方差君⊙﹏⊙b
说了那么多,我们总算是将我们的猪脚弄出来了,~\(≧▽≦)/~啦啦啦

大家想来已经知道m1~(公式编辑器坏了的人伤不起),m2~是投影后的类1、2 的中心点了,s1~ s2~的平方则是方差了,我们现在只要求出J(w)取最大值时,w的取值就行了,下面所有的推导、计算什么的都是围绕这一点展开的,下面是上述公式的数学解释
类别i的原始中心点为:(Di表示属于类别i的点)
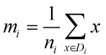
类别i投影后的中心点为:
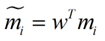
衡量类别i投影后,类别点之间的分散程度(方差)为:
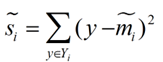
然后就是对J(w)的化简了,具体来就是将 m1~,m2~,s1~,s2~用我们现在可以知道的数据代替
这是原来的方差(在我们举得例子中就是其在x的方差)

华丽丽的化成了y的方差

求个和
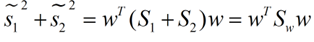
同理(你妹的同理)
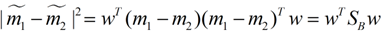
这样损失函数可以化成下面的形式:
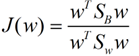
解释一下我们为什么要将J(w)化成这个样子,第一点全部用已知的数据表示出来了,也就是说这个式子中只有w是变量了,其他都是常量了,第二点、化成这样我们可以用拉格朗日法了,至于是什么是拉格朗日法,请看这里,下面就是用拉格朗日法来处理J(w),来求出J(w)最大值时的w值了
如果分子、分母是都可以取任意值的,那就会使得有无穷解,我们将分母限制为长度为1(这是用拉格朗日乘子法一个很重要的技巧,在下面将说的PCA里面也会用到,如果忘记了,请复习一下高数),并作为拉格朗日乘子法的限制条件,带入得到:
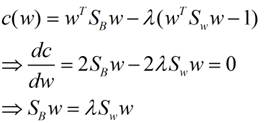
这样的式子就是一个求特征值的问题了。
这样问题就解决了,我们就求出了w了。
对于二维以上的分类的问题,我就直接写出下面的结论了:

这同样是一个求特征值的问题,我们求出的第i大的特征向量,就是对应的Wi了。
PCA
推完LDA后看PCA应该很快了,毕竟两种方法没有本质上的区别,只不过PCA是不带标签的,将方差取最大的结果罢了(LDA是将J(w)取最大了,且带标签的,即事先已经分好类了),推导过程完全一样,而最小投影误差法则是立足于投影的误差最小这一思想然后给强推出来的,最后证明两者结果相同。
原博客讲得不错,我就直接复制粘贴了。。。
PCA的全部工作简单点说,就是对原始的空间中顺序地找一组相互正交的坐标轴,第一个轴是使得方差最大的,第二个轴是在与第一个轴正交的平面中使得方差最大的,第三个轴是在与第1、2个轴正交的平面中方差最大的,这样假设在N维空间中,我们可以找到N个这样的坐标轴,我们取前r个去近似这个空间,这样就从一个N维的空间压缩到r维的空间了,但是我们选择的r个坐标轴能够使得空间的压缩使得数据的损失最小。
主成分分析(PCA)与LDA有着非常近似的意思,LDA的输入数据是带标签的,而PCA的输入数据是不带标签的,所以PCA是一种unsupervised learning。LDA通常来说是作为一个独立的算法存在,给定了训练数据后,将会得到一系列的判别函数(discriminate function),之后对于新的输入,就可以进行预测了。而PCA更像是一个预处理的方法,它可以将原本的数据降低维度,而使得降低了维度的数据之间的方差最大(也可以说投影误差最小,具体在之后的推导里面会谈到)。
我下面将用两种思路来推导出一个同样的表达式。首先是最大化投影后的方差,其次是最小化投影后的损失(投影产生的损失最小)。
最大化方差法:
假设我们还是将一个空间中的点投影到一个向量中去。首先,给出原空间的中心点:
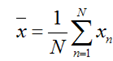
假设u1为投影向量,投影之后的方差为:
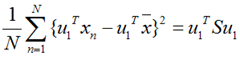
上面这个式子如果看懂了之前推导LDA的过程,应该比较容易理解,如果线性代数里面的内容忘记了,可以再温习一下,优化上式等号右边的内容,还是用拉格朗日乘子法:
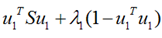
将上式求导,使之为0,得到:

这是一个标准的特征值表达式了,λ对应的特征值,u对应的特征向量。上式的左边取得最大值的条件就是λ1最大,也就是取得最大的特征值的时候。假设我们是要将一个D维的数据空间投影到M维的数据空间中(M < D), 那我们取前M个特征向量构成的投影矩阵就是能够使得方差最大的矩阵了。
最小化损失法:
假设输入数据x是在D维空间中的点,那么,我们可以用D个正交的D维向量去完全的表示这个空间(这个空间中所有的向量都可以用这D个向量的线性组合得到)。在D维空间中,有无穷多种可能找这D个正交的D维向量,哪个组合是最合适的呢?
假设我们已经找到了这D个向量,可以得到:
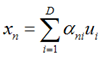
我们可以用近似法来表示投影后的点:
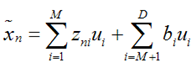
上式表示,得到的新的x是由前M 个基的线性组合加上后D - M个基的线性组合,注意这里的z是对于每个x都不同的,而b对于每个x是相同的,这样我们就可以用M个数来表示空间中的一个点,也就是使得数据降维了。但是这样降维后的数据,必然会产生一些扭曲,我们用J描述这种扭曲,我们的目标是,使得J最小:
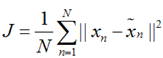
上式的意思很直观,就是对于每一个点,将降维后的点与原始的点之间的距离的平方和加起来,求平均值,我们就要使得这个平均值最小。我们令:
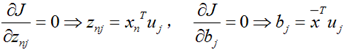
将上面得到的z与b带入降维的表达式:
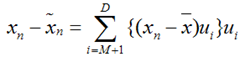
将上式带入J的表达式得到:
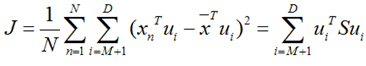
再用上拉普拉斯乘子法(此处略),可以得到,取得我们想要的投影基的表达式为:
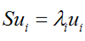
这里又是一个特征值的表达式,我们想要的前M个向量其实就是这里最大的M个特征值所对应的特征向量。证明这个还可以看看,我们J可以化为:
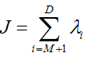
也就是当误差J是由最小的D - M个特征值组成的时候,J取得最小值。跟上面的意思相同。
LDA PCA 学习笔记的更多相关文章
- PCA学习笔记
主成分分析(Principal Component Analysis,简称PCA)是最常用过的一种降维方法 在引入PCA之前先提到了如何使用一个超平面对所有的样本进行恰当的表达? 即若存在这样的超平面 ...
- 数据降维PCA——学习笔记
PCA主成分分析 无监督学习 使方差(数据离散量)最大,更易于分类. 可以对隐私数据PCA,数据加密. 基变换 投影->内积 基变换 正交的基,两个向量垂直(内积为0,线性无关) 先将基化成各维 ...
- PCA 学习笔记
先简单记下,等有时间再整理 PCA 主要思想,把 协方差矩阵 对角化,协方差矩阵是实对称的.里面涉及到矩阵论的一点基础知识: 基变换: Base2 = P · Base1 相应的 坐标变换 P · c ...
- 机器学习13—PCA学习笔记
主成分分析PCA 机器学习实战之PCA test13.py #-*- coding:utf-8 import sys sys.path.append("pca.py") impo ...
- LDA主题模型学习笔记5:C源代码理解
1.说明 本文对LDA原始论文的作者所提供的C代码中LDA的主要逻辑部分做凝视,原代码可在这里下载到:https://github.com/Blei-Lab/lda-c 这份代码实现论文<Lat ...
- 机器学习实战(Machine Learning in Action)学习笔记————09.利用PCA简化数据
机器学习实战(Machine Learning in Action)学习笔记————09.利用PCA简化数据 关键字:PCA.主成分分析.降维作者:米仓山下时间:2018-11-15机器学习实战(Ma ...
- cips2016+学习笔记︱简述常见的语言表示模型(词嵌入、句表示、篇章表示)
在cips2016出来之前,笔者也总结过种类繁多,类似词向量的内容,自然语言处理︱简述四大类文本分析中的"词向量"(文本词特征提取)事实证明,笔者当时所写的基本跟CIPS2016一 ...
- 概率图模型学习笔记:HMM、MEMM、CRF
作者:Scofield链接:https://www.zhihu.com/question/35866596/answer/236886066来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商 ...
- AI学习笔记:特征工程
一.概述 Andrew Ng:Coming up with features is difficult, time-consuming, requires expert knowledge. &quo ...
随机推荐
- buf.readInt16BE()
buf.readInt16BE(offset[, noAssert]) buf.readInt16LE(offset[, noAssert]) offset {Number} 0 noAssert { ...
- eshing wind/tidal turbine using Turbogrid
Table of Contents 1. meshing wind turbine using Turbogrid 1.1. ref 1 meshing wind turbine using Turb ...
- Keil uVision “已停止工作”
之前一直受这个问题的困扰,但是因为只是下载程序,下载镜像文件完事就算了.随便keil挂掉. 今天要调试程序,发现开启调试keil就挂掉了,烦. 解决办法参见: http://218.244.144.1 ...
- HDU - 6158 The Designer
传送门:http://acm.hdu.edu.cn/showproblem.php?pid=6158 本题是一个计算几何题——四圆相切. 平面上的一对内切圆,半径分别为R和r.现在这一对内切圆之间,按 ...
- orcad中注意的事情
1.地的标识不能放到已经分配了网络的线上. 在用orcad画原理图的时候,把电源放到网络的时候需要特别的注意,如果,将电源地直接放到线上,而这根线又已经被分配了网络标号,那这个地会随已经分配了的网络号 ...
- CodeForcesGym 100753B Bounty Hunter II
Bounty Hunter II Time Limit: 5000ms Memory Limit: 262144KB This problem will be judged on CodeForces ...
- Leetcode 79.单词搜索
单词搜索 给定一个二维网格和一个单词,找出该单词是否存在于网格中. 单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中"相邻"单元格是那些水平相邻或垂直相邻的单元格.同一个单 ...
- excel 2003 默认保存后出现超级连接解决方法
在excel 2003 中当选中某个单元格然后拷贝出来后发现总是出现超级连接,每次都要取消下很是麻烦 . 于是经过研究找到解决方法,真是累的我够呛 ,先将方法介绍给大家. 工具---自动更正选项--- ...
- [luoguP2904] [USACO08MAR]跨河River Crossing(DP)
传送门 f[i] 表示送前 i 头牛过去再回来的最短时间 f[i] = min(f[i], f[j] + sum[i - j] + m) (0 <= j < i) ——代码 #includ ...
- uestc 1903
#include<stdio.h> int main() { int n,m,i,t; scanf("%d",&t); while(t--){ scanf(&q ...