一次使用NodeJS实现网页爬虫记
前言
几个月之前,有同事找我要PHP CI框架写的OA系统。他跟我说,他需要学习PHP CI框架,我建议他学习大牛写的国产优秀框架QeePHP。
我上QeePHP官网,发现官方网站打不开了,GOOGLE了一番,发现QeePHP框架已经没人维护了。API文档资料都没有了,那可怎么办?
毕竟QeePHP学习成本挺高的。GOOGLE时,我发现已经有人把文档整理好,放在自己的个人网站上了。我在想:万一放文档的个人站点也挂了,
怎么办?还是保存到自己的电脑上比较保险。于是就想着用NodeJS写个爬虫抓取需要的文档到本地。后来抓取完成之后,干脆写了一个通用版本的,
可以抓取任意网站的内容。
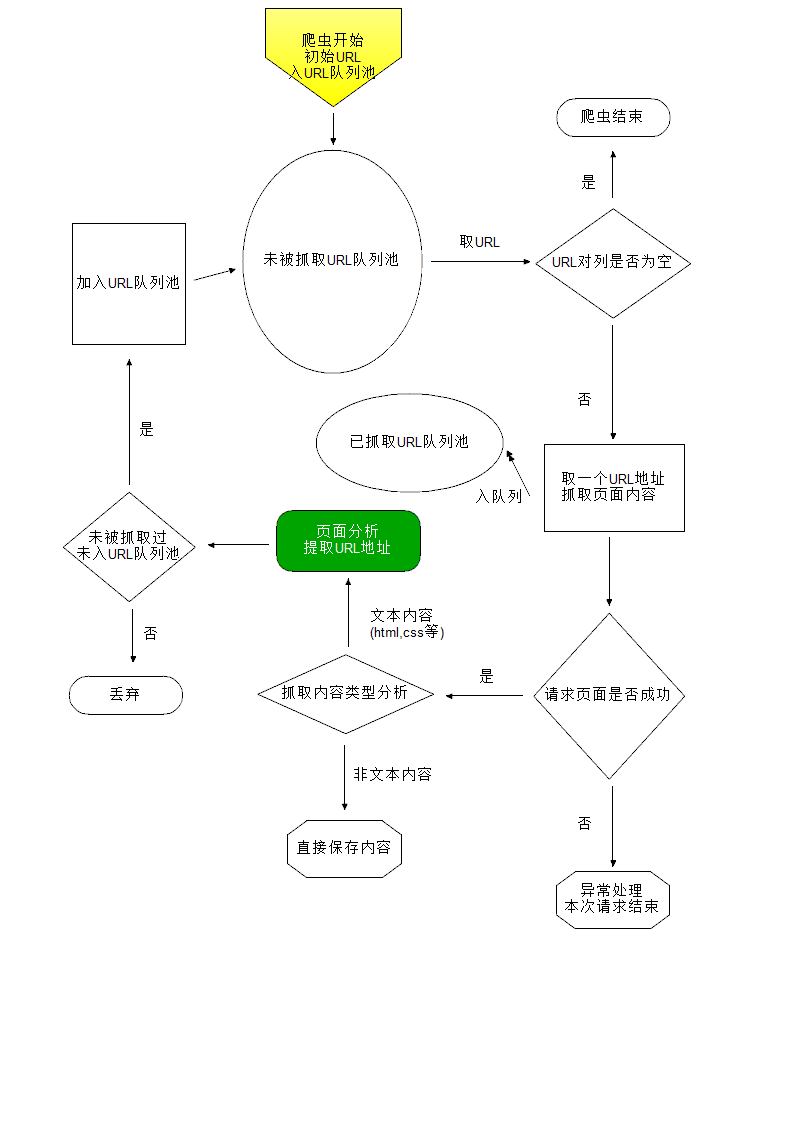
爬虫原理
抓取初始URL的页面内容,提取URL列表,放入URL队列中,
从URL队列中取一个URL地址,抓取这个URL地址的内容,提取URL列表,放入URL队列中
。。。。。。
。。。。。。
NodeJS实现源码
/**
* @desc 网页爬虫 抓取某个站点
*
* @todolist
* URL队列很大时处理
* 302跳转
* 处理COOKIE
* iconv-lite解决乱码
* 大文件偶尔异常退出
*
* @author WadeYu
* @date 2015-05-28
* @copyright by WadeYu
* @version 0.0.1
*/
/**
* @desc 依赖的模块
*/
var fs = require("fs");
var http = require("http");
var https = require("https");
var urlUtil = require("url");
var pathUtil = require("path");
/**
* @desc URL功能类
*/
var Url = function(){};
/**
* @desc 修正被访问地址分析出来的URL 返回合法完整的URL地址
*
* @param string url 访问地址
* @param string url2 被访问地址分析出来的URL
*
* @return string || boolean
*/
Url.prototype.fix = function(url,url2){
if(!url || !url2){
return false;
}
var oUrl = urlUtil.parse(url);
if(!oUrl["protocol"] || !oUrl["host"] || !oUrl["pathname"]){//无效的访问地址
return false;
}
if(url2.substring(0,2) === "//"){
url2 = oUrl["protocol"]+url2;
}
var oUrl2 = urlUtil.parse(url2);
if(oUrl2["host"]){
if(oUrl2["hash"]){
delete oUrl2["hash"];
}
return urlUtil.format(oUrl2);
}
var pathname = oUrl["pathname"];
if(pathname.indexOf('/') > -1){
pathname = pathname.substring(0,pathname.lastIndexOf('/'));
}
if(url2.charAt(0) === '/'){
pathname = '';
}
url2 = pathUtil.normalize(url2); //修正 ./ 和 ../
url2 = url2.replace(/\\/g,'/');
while(url2.indexOf("../") > -1){ //修正以../开头的路径
pathname = pathUtil.dirname(pathname);
url2 = url2.substring(3);
}
if(url2.indexOf('#') > -1){
url2 = url2.substring(0,url2.lastIndexOf('#'));
} else if(url2.indexOf('?') > -1){
url2 = url2.substring(0,url2.lastIndexOf('?'));
}
var oTmp = {
"protocol": oUrl["protocol"],
"host": oUrl["host"],
"pathname": pathname + '/' + url2,
};
return urlUtil.format(oTmp);
};
/**
* @desc 判断是否是合法的URL地址一部分
*
* @param string urlPart
*
* @return boolean
*/
Url.prototype.isValidPart = function(urlPart){
if(!urlPart){
return false;
}
if(urlPart.indexOf("javascript") > -1){
return false;
}
if(urlPart.indexOf("mailto") > -1){
return false;
}
if(urlPart.charAt(0) === '#'){
return false;
}
if(urlPart === '/'){
return false;
}
if(urlPart.substring(0,4) === "data"){//base64编码图片
return false;
}
return true;
};
/**
* @desc 获取URL地址 路径部分 不包含域名以及QUERYSTRING
*
* @param string url
*
* @return string
*/
Url.prototype.getUrlPath = function(url){
if(!url){
return '';
}
var oUrl = urlUtil.parse(url);
if(oUrl["pathname"] && (/\/$/).test(oUrl["pathname"])){
oUrl["pathname"] += "index.html";
}
if(oUrl["pathname"]){
return oUrl["pathname"].replace(/^\/+/,'');
}
return '';
};
/**
* @desc 文件内容操作类
*/
var File = function(obj){
var obj = obj || {};
this.saveDir = obj["saveDir"] ? obj["saveDir"] : ''; //文件保存目录
};
/**
* @desc 内容存文件
*
* @param string filename 文件名
* @param mixed content 内容
* @param string charset 内容编码
* @param Function cb 异步回调函数
* @param boolean bAppend
*
* @return boolean
*/
File.prototype.save = function(filename,content,charset,cb,bAppend){
if(!content || !filename){
return false;
}
var filename = this.fixFileName(filename);
if(typeof cb !== "function"){
var cb = function(err){
if(err){
console.log("内容保存失败 FILE:"+filename);
}
};
}
var sSaveDir = pathUtil.dirname(filename);
var self = this;
var cbFs = function(){
var buffer = new Buffer(content,charset ? charset : "utf8");
fs.open(filename, bAppend ? 'a' : 'w', 0666, function(err,fd){
if (err){
cb(err);
return ;
}
var cb2 = function(err){
cb(err);
fs.close(fd);
};
fs.write(fd,buffer,0,buffer.length,0,cb2);
});
};
fs.exists(sSaveDir,function(exists){
if(!exists){
self.mkdir(sSaveDir,"0666",function(){
cbFs();
});
} else {
cbFs();
}
});
};
/**
* @desc 修正保存文件路径
*
* @param string filename 文件名
*
* @return string 返回完整的保存路径 包含文件名
*/
File.prototype.fixFileName = function(filename){
if(pathUtil.isAbsolute(filename)){
return filename;
}
if(this.saveDir){
this.saveDir = this.saveDir.replace(/[\\/]$/,pathUtil.sep);
}
return this.saveDir + pathUtil.sep + filename;
};
/**
* @递归创建目录
*
* @param string 目录路径
* @param mode 权限设置
* @param function 回调函数
* @param string 父目录路径
*
* @return void
*/
File.prototype.mkdir = function(sPath,mode,fn,prefix){
sPath = sPath.replace(/\\+/g,'/');
var aPath = sPath.split('/');
var prefix = prefix || '';
var sPath = prefix + aPath.shift();
var self = this;
var cb = function(){
fs.mkdir(sPath,mode,function(err){
if ( (!err) || ( ([47,-4075]).indexOf(err["errno"]) > -1 ) ){ //创建成功或者目录已存在
if (aPath.length > 0){
self.mkdir( aPath.join('/'),mode,fn, sPath.replace(/\/$/,'')+'/' );
} else {
fn();
}
} else {
console.log(err);
console.log('创建目录:'+sPath+'失败');
}
});
};
fs.exists(sPath,function(exists){
if(!exists){
cb();
} else if(aPath.length > 0){
self.mkdir(aPath.join('/'),mode,fn, sPath.replace(/\/$/,'')+'/' );
} else{
fn();
}
});
};
/**
* @递归删除目录 待完善 异步不好整
*
* @param string 目录路径
* @param function 回调函数
*
* @return void
*/
File.prototype.rmdir = function(path,fn){
var self = this;
fs.readdir(path,function(err,files){
if(err){
if(err.errno == -4052){ //不是目录
fs.unlink(path,function(err){
if(!err){
fn(path);
}
});
}
} else if(files.length === 0){
fs.rmdir(path,function(err){
if(!err){
fn(path);
}
});
}else {
for(var i = 0; i < files.length; i++){
self.rmdir(path+'/'+files[i],fn);
}
}
});
};
/**
* @desc 简单日期对象
*/
var oDate = {
time:function(){//返回时间戳 毫秒
return (new Date()).getTime();
},
date:function(fmt){//返回对应格式日期
var oDate = new Date();
var year = oDate.getFullYear();
var fixZero = function(num){
return num < 10 ? ('0'+num) : num;
};
var oTmp = {
Y: year,
y: (year+'').substring(2,4),
m: fixZero(oDate.getMonth()+1),
d: fixZero(oDate.getDate()),
H: fixZero(oDate.getHours()),
i: fixZero(oDate.getMinutes()),
s: fixZero(oDate.getSeconds()),
};
for(var p in oTmp){
if(oTmp.hasOwnProperty(p)){
fmt = fmt.replace(p,oTmp[p]);
}
}
return fmt;
},
};
/**
* @desc 未抓取过的URL队列
*/
var aNewUrlQueue = [];
/**
* @desc 已抓取过的URL队列
*/
var aGotUrlQueue = [];
/**
* @desc 统计
*/
var oCnt = {
total:0,//抓取总数
succ:0,//抓取成功数
fSucc:0,//文件保存成功数
};
/**
* 可能有问题的路径的长度 超过打监控日志
*/
var sPathMaxSize = 120;
/**
* @desc 爬虫类
*/
var Robot = function(obj){
var obj = obj || {};
//所在域名
this.domain = obj.domain || '';
//抓取开始的第一个URL
this.firstUrl = obj.firstUrl || '';
//唯一标识
this.id = this.constructor.incr();
//内容落地保存路径
this.saveDir = obj.saveDir || '';
//是否开启调试功能
this.debug = obj.debug || false;
//第一个URL地址入未抓取队列
if(this.firstUrl){
aNewUrlQueue.push(this.firstUrl);
}
//辅助对象
this.oUrl = new Url();
this.oFile = new File({saveDir:this.saveDir});
};
/**
* @desc 爬虫类私有方法---返回唯一爬虫编号
*
* @return int
*/
Robot.id = 1;
Robot.incr = function(){
return this.id++;
};
/**
* @desc 爬虫开始抓取
*
* @return boolean
*/
Robot.prototype.crawl = function(){
if(aNewUrlQueue.length > 0){
var url = aNewUrlQueue.pop();
this.sendReq(url);
oCnt.total++;
aGotUrlQueue.push(url);
} else {
if(this.debug){
console.log("抓取结束");
console.log(oCnt);
}
}
return true;
};
/**
* @desc 发起HTTP请求
*
* @param string url URL地址
*
* @return boolean
*/
Robot.prototype.sendReq = function(url){
var req = '';
if(url.indexOf("https") > -1){
req = https.request(url);
} else {
req = http.request(url);
}
var self = this;
req.on('response',function(res){
var aType = self.getResourceType(res.headers["content-type"]);
var data = '';
if(aType[2] !== "binary"){
//res.setEncoding(aType[2] ? aType[2] : "utf8");//非支持的内置编码会报错
} else {
res.setEncoding("binary");
}
res.on('data',function(chunk){
data += chunk;
});
res.on('end',function(){ //获取数据结束
self.debug && console.log("抓取URL:"+url+"成功\n");
self.handlerSuccess(data,aType,url);
data = null;
});
res.on('error',function(){
self.handlerFailure();
self.debug && console.log("服务器端响应失败URL:"+url+"\n");
});
}).on('error',function(err){
self.handlerFailure();
self.debug && console.log("抓取URL:"+url+"失败\n");
}).on('finish',function(){//调用END方法之后触发
self.debug && console.log("开始抓取URL:"+url+"\n");
});
req.end();//发起请求
};
/**
* @desc 提取HTML内容里的URL
*
* @param string html HTML文本
*
* @return []
*/
Robot.prototype.parseUrl = function(html){
if(!html){
return [];
}
var a = [];
var aRegex = [
/<a.*?href=['"]([^"']*)['"][^>]*>/gmi,
/<script.*?src=['"]([^"']*)['"][^>]*>/gmi,
/<link.*?href=['"]([^"']*)['"][^>]*>/gmi,
/<img.*?src=['"]([^"']*)['"][^>]*>/gmi,
/url\s*\([\\'"]*([^\(\)]+)[\\'"]*\)/gmi, //CSS背景
];
html = html.replace(/[\n\r\t]/gm,'');
for(var i = 0; i < aRegex.length; i++){
do{
var aRet = aRegex[i].exec(html);
if(aRet){
this.debug && this.oFile.save("_log/aParseUrl.log",aRet.join("\n")+"\n\n","utf8",function(){},true);
a.push(aRet[1].trim().replace(/^\/+/,'')); //删除/是否会产生问题
}
}while(aRet);
}
return a;
};
/**
* @desc 判断请求资源类型
*
* @param string Content-Type头内容
*
* @return [大分类,小分类,编码类型] ["image","png","utf8"]
*/
Robot.prototype.getResourceType = function(type){
if(!type){
return '';
}
var aType = type.split('/');
aType.forEach(function(s,i,a){
a[i] = s.toLowerCase();
});
if(aType[1] && (aType[1].indexOf(';') > -1)){
var aTmp = aType[1].split(';');
aType[1] = aTmp[0];
for(var i = 1; i < aTmp.length; i++){
if(aTmp[i] && (aTmp[i].indexOf("charset") > -1)){
aTmp2 = aTmp[i].split('=');
aType[2] = aTmp2[1] ? aTmp2[1].replace(/^\s+|\s+$/,'').replace('-','').toLowerCase() : '';
}
}
}
if((["image"]).indexOf(aType[0]) > -1){
aType[2] = "binary";
}
return aType;
};
/**
* @desc 抓取页面内容成功调用的回调函数
*
* @param string str 抓取的内容
* @param [] aType 抓取内容类型
* @param string url 请求的URL地址
*
* @return void
*/
Robot.prototype.handlerSuccess = function(str,aType,url){
if((aType[0] === "text") && ((["css","html"]).indexOf(aType[1]) > -1)){ //提取URL地址
aUrls = (url.indexOf(this.domain) > -1) ? this.parseUrl(str) : []; //非站内只抓取一次
for(var i = 0; i < aUrls.length; i++){
if(!this.oUrl.isValidPart(aUrls[i])){
this.debug && this.oFile.save("_log/aInvalidRawUrl.log",url+"----"+aUrls[i]+"\n","utf8",function(){},true);
continue;
}
var sUrl = this.oUrl.fix(url,aUrls[i]);
/*if(sUrl.indexOf(this.domain) === -1){ //只抓取站点内的 这里判断会过滤掉静态资源
continue;
}*/
if(aNewUrlQueue.indexOf(sUrl) > -1){
continue;
}
if(aGotUrlQueue.indexOf(sUrl) > -1){
continue;
}
aNewUrlQueue.push(sUrl);
}
}
//内容存文件
var sPath = this.oUrl.getUrlPath(url);
var self = this;
var oTmp = urlUtil.parse(url);
if(oTmp["hostname"]){//路径包含域名 防止文件保存时因文件名相同被覆盖
sPath = sPath.replace(/^\/+/,'');
sPath = oTmp["hostname"]+pathUtil.sep+sPath;
}
if(sPath){
if(this.debug){
this.oFile.save("_log/urlFileSave.log",url+"--------"+sPath+"\n","utf8",function(){},true);
}
if(sPath.length > sPathMaxSize){ //可能有问题的路径 打监控日志
this.oFile.save("_log/sPathMaxSizeOverLoad.log",url+"--------"+sPath+"\n","utf8",function(){},true);
return ;
}
if(aType[2] != "binary"){//只支持UTF8编码
aType[2] = "utf8";
}
this.oFile.save(sPath,str,aType[2] ? aType[2] : "utf8",function(err){
if(err){
self.debug && console.log("Path:"+sPath+"存文件失败");
} else {
oCnt.fSucc++;
}
});
}
oCnt.succ++;
this.crawl();//继续抓取
};
/**
* @desc 抓取页面失败调用的回调函数
*
* @return void
*/
Robot.prototype.handlerFailure = function(){
this.crawl();
};
/**
* @desc 外部引用
*/
module.exports = Robot;
调用
var Robot = require("./robot.js");
var oOptions = {
domain:'baidu.com', //抓取网站的域名
firstUrl:'http://www.baidu.com/', //抓取的初始URL地址
saveDir:"E:\\wwwroot/baidu/", //抓取内容保存目录
debug:true, //是否开启调试模式
};
var o = new Robot(oOptions);
o.crawl(); //开始抓取
后记
还有些地方需要完善
1.处理302跳转
2.处理COOKIE登陆
3.大文件偶尔会非正常退出
4.使用多进程
5.完善URL队列管理
6.异常退出之后处理
实现过程中碰到了一些问题,最后还是解决了,
爬虫原理很简单,只有真正实现过,才会对它更加理解,
原来实现不是那么简单,也是需要花时间的。
7.下载地址: https://codeload.github.com/wadeyu/nodejsrobot/zip/master
参考资料
[1]NodeJS
https://nodejs.org/
[2]Nodejs抓取非utf8字符编码的页面
http://www.cnblogs.com/fengmk2/archive/2011/05/15/2047109.html
[3]iconv-lite编码解码
https://www.npmjs.com/package/iconv-lite
一次使用NodeJS实现网页爬虫记的更多相关文章
- 基于NodeJs的网页爬虫的构建(二)
好久没写博客了,这段时间已经忙成狗,半年时间就这么没了,必须得做一下总结否则白忙.接下去可能会有一系列的总结,都是关于定向爬虫(干了好几个月后才知道这个名词)的构建方法,实现平台是Node.JS. 背 ...
- 基于NodeJs的网页爬虫的构建(一)
好久没写博客了,这段时间已经忙成狗,半年时间就这么没了,必须得做一下总结否则白忙.接下去可能会有一系列的总结,都是关于定向爬虫(干了好几个月后才知道这个名词)的构建方法,实现平台是Node.JS. 背 ...
- nodeJS实现简单网页爬虫功能
前面的话 本文将使用nodeJS实现一个简单的网页爬虫功能 网页源码 使用http.get()方法获取网页源码,以hao123网站的头条页面为例 http://tuijian.hao123.com/h ...
- nodejs 快要变成爬虫界的王者
nodejs 快要变成爬虫界的王者 爬虫这东西是很多数据采集必须要的东西. 但是现在随着网页不断发展,已经出现了出单纯的网页,到 ajax 网页, 再到 spa , 再到 websocket 应用,一 ...
- cURL 学习笔记与总结(2)网页爬虫、天气预报
例1.一个简单的 curl 获取百度 html 的爬虫程序(crawler): spider.php <?php /* 获取百度html的简单网页爬虫 */ $curl = curl_init( ...
- c#网页爬虫初探
一个简单的网页爬虫例子! html代码: <head runat="server"> <title>c#爬网</title> </head ...
- 网页爬虫--scrapy入门
本篇从实际出发,展示如何用网页爬虫.并介绍一个流行的爬虫框架~ 1. 网页爬虫的过程 所谓网页爬虫,就是模拟浏览器的行为访问网站,从而获得网页信息的程序.正因为是程序,所以获得网页的速度可以轻易超过单 ...
- 网页爬虫的设计与实现(Java版)
网页爬虫的设计与实现(Java版) 最近为了练手而且对网页爬虫也挺感兴趣,决定自己写一个网页爬虫程序. 首先看看爬虫都应该有哪些功能. 内容来自(http://www.ibm.com/deve ...
- Python 网页爬虫 & 文本处理 & 科学计算 & 机器学习 & 数据挖掘兵器谱(转)
原文:http://www.52nlp.cn/python-网页爬虫-文本处理-科学计算-机器学习-数据挖掘 曾经因为NLTK的缘故开始学习Python,之后渐渐成为我工作中的第一辅助脚本语言,虽然开 ...
随机推荐
- rmdir
rmdir——删除空目录 remove empty directories 命令所在路径:bin/rmdir 示例: # rmdir /tmp/japan/longze 删除/tmp/japan/目录 ...
- # Transition:添加弹出过渡效果
# Transition:添加弹出过渡效果 通过鼠标的单击.获得焦点,被点击或对元素任何改变中触发,并平滑地以动画效果改变CSS的属性值. W3C-transition MDN-transition ...
- TensorFlow中屏蔽warning的方法
问题 使用sudo pip3 install tensorflow安装完CPU版tensorflow后,运行简单的测试程序,出现如下警告: I tensorflow/core/platform/cpu ...
- Python3简明教程(九)—— 文件处理
文件是保存在计算机存储设备上的一些信息或数据.你已经知道了一些不同的文件类型,比如你的音乐文件,视频文件,文本文件.Linux 有一个思想是“一切皆文件”,这在实验最后的 lscpu 的实现中得到了体 ...
- vue 自定义组件 v-model双向绑定、 父子组件同步通信【转】
父子组件通信,都是单项的,很多时候需要双向通信.方法如下: 1.父组件使用:msg.sync="aa" 子组件使用$emit('update:msg', 'msg改变后的值xxx ...
- 洛谷 P1518 两只塔姆沃斯牛
P1518 两只塔姆沃斯牛 The Tamworth Two 简单的模拟题,代码量不大. 他们走的路线取决于障碍物,可以把边界也看成障碍物,遇到就转,枚举次,因为100 * 100 * 4,只有4个可 ...
- [LOJ] #2363「NOIP2016」愤怒的小鸟
精度卡了一个点,别人自带大常数,我自带大浮点误差qwq. 听了好几遍,一直没动手写一写. f[S]表示S集合中的猪被打死的最少抛物线数,转移时考虑枚举两个点,最低位的0为第一个点,枚举第二个点,构造一 ...
- NFS和DHCP服务
1. NFS NFS,Network File System的简写,即网络文件系统.网络文件系统是FreeBSD支持的文件系统中的一种,也被称为NFS: NFS允许一个系统在网络上与他人共享目录和文件 ...
- 第二天,学习if,变量,注释
zz_age = 31guss_age=int(input("input your answer:"))if guss_age == zz_age: print ("Yo ...
- LeetCode(65) Valid Number
题目 Validate if a given string is numeric. Some examples: "0" => true " 0.1 " ...