利用背景流量数据(contexual flow data) 识别TLS加密恶意流量
识别出加密流量中潜藏的安全威胁具有很大挑战,现已存在一些检测方法利用数据流的元数据来进行检测,包括包长度和到达间隔时间等。来自思科的研究人员扩展现有的检测方法提出一种新的思路(称之为“dataomnia”),不需要对加密的恶意流量进行解密,就能检测到采用TLS连接的恶意程序,本文就该检测方法进行简要描述,主要参照思科在AISec’16发表的文章《IdentifyingEncrypted Malware Traffic with Contextual Flow Data》[1][2][3]。
一、 主要思想
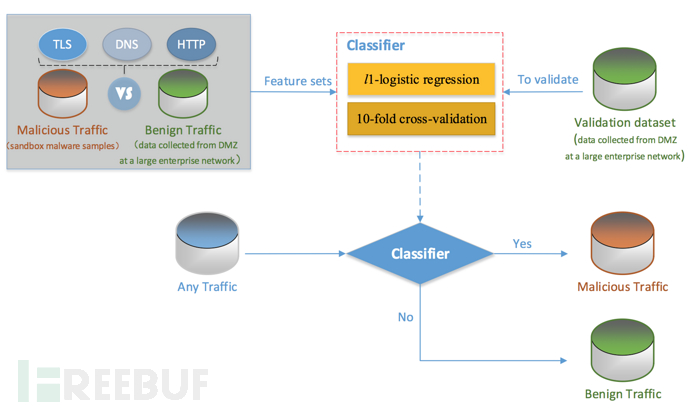
图1 TLS加密恶意流量检测流程
首先,分析百万级的正常流量和恶意流量中TLS流、DNS流和HTTP流的不同之处,具体包括未加密的TLS握手信息、TLS流中与目的IP地址相关的DNS响应信息(如图2)、相同源IP地址5min窗口内HTTP流的头部信息;然后,选取具有明显区分度的特征集作为分类器(有监督机器学习)的输入来训练检测模型,从而识别加密的恶意流量。本方法区别于已有研究方法的地方就是利用TLS流相关背景流量信息(包括DNS响应、HTTP头部等)辅助加密恶意流量检测。
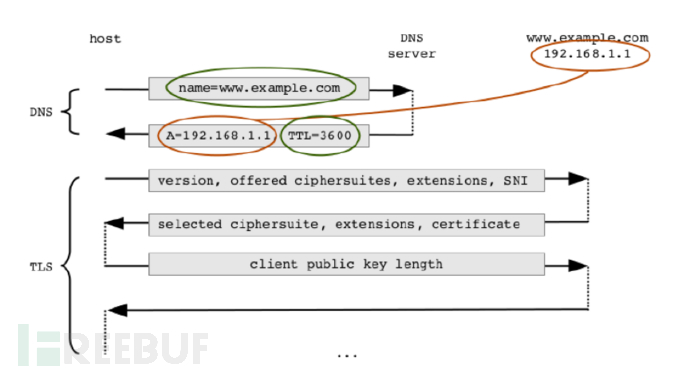
图2TLS流和背景DNS流量
(红色数据用于链接TLS流和DNS流、绿色数据表示背景信息、未标记颜色的数据表示TLS未加密的头部信息)
二、流量数据采集
思科研究人员自己写了一款基于libpcap的通用工具,用于分析并提取捕获到的数据流(恶意流量和正常流量)的数据特征,包含clientHello,serverHello, certificate和clien-tKeyExchange等信息。
1. 恶意流量
采集环境:ThreatGRID[4],一种商业的沙箱环境,提供恶意软件分析功能
采集时间:2016年1月-2016年4月
说明: 沙箱环境接受用户提交(usersubmissions),每个用户提交允许运行5min,所有的网络活动被记录用于分析。
2. 正常流量(DMZ区流量,本文认为该区域包含少量的恶意流量)
采集环境:某大型企业网络的DMZ区某5天的数据量
采集时间:2016年4月
三、流量数据特征
文中对恶意/正常流量中TLS流及背景流量信息(DNS响应信息、HTTP头部信息)进行统计分析,寻找恶意流量和正常流量中具有明显区分度的数据特征以及相应特征值的规律性。
1. TLS握手信息:
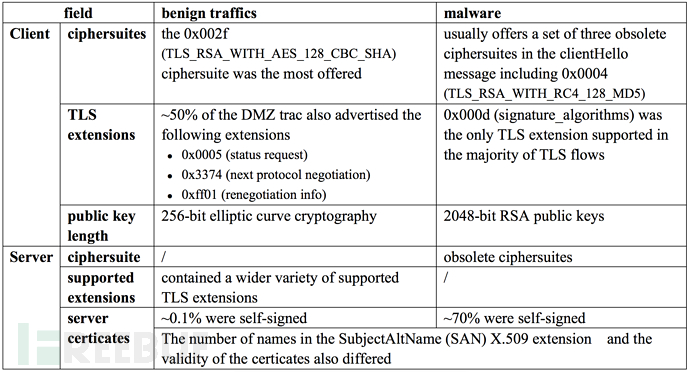
选取拥有完整TLS握手信息的TLS流作为研究对象,通过分析TLS握手信息发现,恶意流量和正常流量使用的加密套件(ciphersuites )、支持的扩展(extensions)等方面有很大不同,详见表1。
表1 恶意流量与正常流量TLS握手信息区别
2. DNS响应信息:
通过选取和目的IP地址相关的包含DNS响应信息的数据流作为研究对象,提取响应的域名信息进行分析。DNS域名信息也可以从SNI(Server NameIndication)扩展和SANs(subjectalternative names)中得知,但由于TLS版本信息等原因,这些字段有时候是不存在的。
通过分析数据发现, 恶意流量与正常流量的区别主要表现在: 域名的长度、数字字符及非数字或者字母(non-alphanumericcharacter) 的字符占比、DNS解析出的IP数量、TTL值以及域名是否收录在Alexa网站等。
域名的长度:正常流量的域名长度分布为均值为6或7的高斯分布(正态分布);而恶意流量的域名(FQDN全称域名)长度多为6(10)。
数字字符及非字母数字(non-alphanumericcharacter) 的字符占比:正常流量的DNS响应中全称域名的数字字符的占比和非字母数字字符的占比要大。
DNS解析出的IP数量:大多数恶意流量和正常流量只返回一个IP地址;其它情况,大部分正常流量返回2-8个IP地址,恶意流量返回4或者11个IP地址。
TTL值:正常流量的TTL值一般为60、300、20、30;而恶意流量多为300,大约22%的DNS响应汇总TTL为100,而这在正常流量中很罕见。
域名是否收录在Alexa网站:恶意流量域名信息很少收录在Alexatop-1,000,000中,而正常流量域名多收录在其中。
3. HTTP头部信息:
选取相同源IP地址5min窗口内的HTTP流作为研究对象,通过分析HTTP头部信息发现,恶意流量和正常流量所选用的HTTP头部字段有很大区别。详见表2。此外,正常流量HTTP头部信息汇总Content-Type值多为image/*,而恶意流量为text/*text/html、charset=UTF-8或者text/html;charset=UTF-8。
表2 恶意流量与正常流量HTTP头部信息区别

四、建模分类
1. 实验数据集
选取拥有完整TLS握手信息且有DNS响应和HTTP头部信息的数据流进行分析建模。
选取的特征值包括两部分(这里不赘述数据特征的表示方法,详见论文):
(1) 可直接观测到的元数据:包长度、包到达间隔时间以及字节分布。
(2) 第三章节提到TLS握手信息及对应的背景流量包含的数据特征,包括ciphersuites、extensions、publickey length等。
分析工具:Python 和 Scikit-learn[5]
2. 实验过程:
本文利用10折交叉验证(10-foldcross-validation)和l1正则化的逻辑回归算法(l1-logistic regression)来进行分类(即判断加密流量是否是恶意的)。文中也针对不同数据特征的组合的分类结果进行了统计(图7-Table 1),可以发现利用背景流量信息进行分类的模型不仅准确率会更高,而且参数会更少(根据交叉验证形成模型参数平均计算可得)。
图7中Table 2 列出了对判别正常流量和异常流量影响权重比较大的数据特征。这些特征很容易解释为什么网络流是恶意的或者是正常的,例如绝大多数的恶意流量样本不会和排名top-1,000,000的网站进行通信。
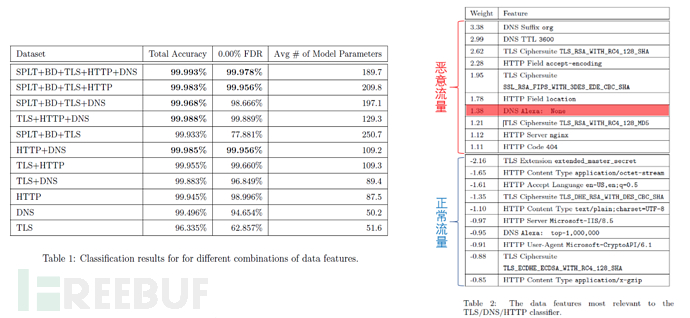
图3 实验结果分析
文中提到,使用FDR(伪发现率,FalseDiscovery Rate)作为假设检验错误率的控制指标(FDR不超过0.00%)。
我们收集的特征数据除了用于构造机器学习模型之外,还有其它的一些启示。
1. Client端的client-hello中的SNI与sever端的certificate中包含的SAN都表示服务器主机名,两者的差异性可以用于恶意流量检测;
2. HTTP流中的User-Agent和从TLS流中ciphersuites和advertisedextensions推测出的User-Agent的差异性也可以用于恶意流量检测。
3. 实验验证:
为了防止过拟合,除了上面提到的交叉验证方法之外,我们额外收集了2016年5月这个月期间相同企业网络中DMZ区的流量,用第五章节训练形成的模型来进行验证。从Table 3中可以看到,结合TLS流的背景流量信息DNS响应和HTTP头部信息进行分类的效果最好,即报警数最少。当l1-logistic regression classifier的阈值(Probabilityof malicious)为0.95时,该分类器只有86个报警(包括29个独立目的IP地址和47个独立的源IP地址),其中有42个报警看似是“误报”。经过分析发现,这些“误报”中,主机是一直和Goolge和Akamai服务器通信,但是从该TLS流的背景流量HTTP流(contexualHTTP)中发现,其与可疑域名进行通信(HTTP中的Host字段),经VirusTotal确认,有50%的反病毒引擎认为和该域名相关的可执行程序是恶意的,这也进一步说明了该模型的有效性。
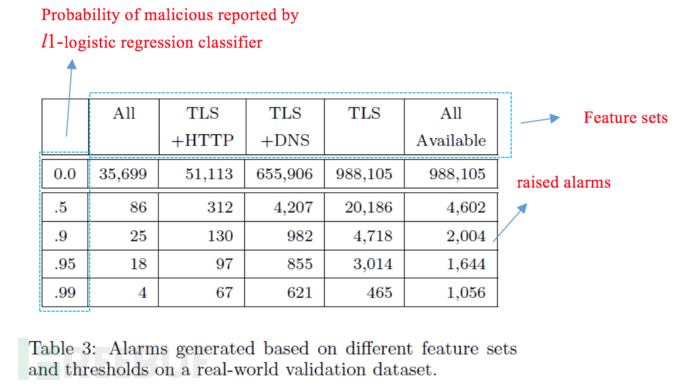
图4 实验数据验证
五、参考文章
[1] Identifying Encrypted Malware Traffic withContextual Flow Data http://dl.acm.org/citation.cfm?id=2996768
[2] 不解密数据竟也能识别TLS加密的恶意流量?http://www.freebuf.com/news/108628.html
[3] 传输层安全协议抓包分析SSL/TLS http://www.freebuf.com/articles/network/116497.html
[4] Cisco AMP Threat Grid http://www.threatgrid.com , 2016.
[5] F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B.Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J.Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay.Scikit-learn: Machine Learning in Python. JMLR,12:2825-2830, 2011.
利用背景流量数据(contexual flow data) 识别TLS加密恶意流量的更多相关文章
- 识别TLS加密恶意流量
利用背景流量数据(contexual flow data)识别TLS加密恶意流量 识别出加密流量中潜藏的安全威胁具有很大挑战,现已存在一些检测方法利用数据流的元数据来进行检测,包括包长度和到达间隔时间 ...
- 抓取“矢量”的实时交通流量数据
1. 引言 最近老师有一个需求,就是想要抓取实时的矢量交通流量数据来做分析,类似于百度地图,高德地图的"实时路况"那种.平时的网络抓取工作一般是抓取网页上现成的数据,但是交通流量数 ...
- java利用poi导出数据到excel
背景: 上一篇写到利用jtds连接数据库获取对应的数据,本篇写怎样用poi将数据到处到excel中,此程序为Application 正文: 第三方poi jar包:poi驱动包下载 代码片段: /** ...
- 利用fputcsv导出数据备份数据
今天,分享一个利用fputcsv导出数据备份数据的方法,我也时看到些零零散散的代码,想着拼起来,所以我只提供些思路,以及简单的代码,至于怎么组合能够让它更强大,尽情去探索吧 讲之前先上一段获取数据库里 ...
- EF Core下利用Mysql进行数据存储在并发访问下的数据同步问题
小故事 在开始讲这篇文章之前,我们来说一个小故事,纯素虚构(真实的存钱逻辑并非如此) 小刘发工资后,赶忙拿着现金去银行,准备把钱存起来,而与此同时,小刘的老婆刘嫂知道小刘的品性,知道他发工资的日子,也 ...
- 【Python】利用豆瓣短评数据生成词云
在之前的文章中,我们获得了豆瓣爬取的短评内容,汇总到了一个文件中,但是,没有被利用起来的数据是没有意义的. 前文提到,有一篇微信推文的关于词云制作的一个实践记录,准备照此试验一下. 思路分析 读文件 ...
- 【菜鸟学习jquery源码】数据缓存与data()
前言 最近比较烦,深圳的工作还没着落,论文不想弄,烦.....今天看了下jquery的数据缓存的代码,参考着Aaron的源码分析,自己有点理解了,和大家分享下.以后也打算把自己的jquery的学习心得 ...
- 基于MVC4+EasyUI的Web开发框架经验总结(12)--利用Jquery处理数据交互的几种方式
在基于MVC4+EasyUI的Web开发框架里面,大量采用了Jquery的方法,对数据进行请求或者提交,方便页面和服务器后端进行数据的交互处理.本文主要介绍利用Jquery处理数据交互的几种方式,包括 ...
- 机器学习实战 - 读书笔记(14) - 利用SVD简化数据
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第14章 - 利用SVD简化数据. 这里介绍,机器学习中的降维技术,可简化样品数据. 基 ...
随机推荐
- mysql中常用函数简介(不定时更新)
常用函数version() 显示当前数据库版本database() 返回当前数据库名称user() 返回当前登录用户名inet_aton(IP) 返回IP地址的数值形式,为IP地址的数学计算做准备in ...
- Apache安装错误 APR not found解决方法
在配置Apache的时候,出现错误 原因是缺少一些依赖包,安装这些依赖包就行了 下载依赖包,注意我这里下载的与参考链接上的有些不同,安装上也有不一样 wget http://archive.apach ...
- Linux下基于LVM调整分区容量大小的方法
Linux下调整分区容量大小的方法(适用于centos6-7) 说明:以下方法均使用centos6.9和centos7.4进行测试. Centos6分区容量调整方法 1.web分区空间不足,新添加一块 ...
- laravel模型关联与列表展示
上面这个是一个模型关联的图,其实我们很容易去理解 比如说,一对一,也就是说一个用户对应的是一个手机号. 一对多,比如说一篇文章可以有多条评论 一对多反向:如一篇文章可以有多条评论,但对应每条评论也只针 ...
- 《嵌入式linux应用程序开发标准教程》笔记——8.进程间通信
, 8.1 概述 linux里使用较多的进程间通信方式: 管道,pipe和fifo,管道pipe没有实体文件,只能用于具有亲缘关系的进程间通信:有名管道 named pipe,也叫fifo,还允许无亲 ...
- python列表的增删改查用法
列表,元组 查 索引(下标) ,都是从0开始 切片 .count 查某个元素的出现次数 .index 根据内容找其对应的位置 "haidilao ge" in a 增加 a.app ...
- MySQL学习点滴
MySQL学习点滴 --分区表 概述: 分区功能并不是在存储引擎层完成的,因此很多存储引擎包括InnoDB, MyISAM, NDB等都支持分区功能.但也并不是所有的存储引擎都支持分区.在使用分区前, ...
- 前端,基础选择器,嵌套关系.display属性,盒模型
基础选择器 1.统配选择器 控制html,body及body内跟显示相关的标签 *{ width:80px; height:80px; background-color:red; } 2.类选择器 以 ...
- 我的Python分析成长之路5
一.装饰器: 本质是函数,装饰其他函数,为其他函数添加附加功能. 原则: 1.不能修改被装饰函数的源代码. 2.不能修改被装饰函数的调用方式. 装饰器用到的知识: 1.函数即变量 (把函数体赋值给 ...
- MIP启发式求解:局部搜索 (local search)
*本文主要记录和分享学习到的知识,算不上原创. *参考文献见链接. 本文讲述的是求解MIP问题的启发式算法. 启发式算法的目的在于短时间内获得较优解. 个人认为局部搜索(local search)几乎 ...