kafka_2.11-0.8.2.2.tgz的3节点集群的下载、安装和配置(图文详解)
kafka_2.10-0.8.1.1.tgz的1或3节点集群的下载、安装和配置(图文详细教程)绝对干货
一、安装前准备
1.1 示例机器

二、 JDK7 安装
1.1 下载地址
下载地址: http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html
[hadoop@hadoop1 ~]$ cd
[hadoop@hadoop1 ~]$ rz
-bash: rz: command not found
[hadoop@hadoop1 ~]$ su root
Password:
[root@hadoop1 hadoop]# yum -y install lrzsz
hadoop2和hadoop3操作一样,不多赘述。
在安装jdk之前,先要卸载自带的openjdk。
Centos 6.5下的OPENJDK卸载和SUN的JDK安装、环境变量配置


[hadoop@hadoop1 ~]$ pwd
/home/hadoop
[hadoop@hadoop1 ~]$ ll
total 0
[hadoop@hadoop1 ~]$ rz [hadoop@hadoop1 ~]$ ll
total 149920
-rw-r--r--. 1 hadoop hadoop 153512879 Oct 23 2015 jdk-7u79-linux-x64.tar.gz
[hadoop@hadoop1 ~]$
hadoop2和hadoop3操作一样,不多赘述。
1.2 安装
解压缩
cd /home/hadoop
tar zxvf jdk-7u79-linux-x64.gz
[hadoop@hadoop1 ~]$ pwd
/home/hadoop
[hadoop@hadoop1 ~]$ ll
total 149920
-rw-r--r--. 1 hadoop hadoop 153512879 Oct 23 2015 jdk-7u79-linux-x64.tar.gz
[hadoop@hadoop1 ~]$ tar -zxvf jdk-7u79-linux-x64.tar.gz
hadoop2和hadoop3操作一样,不多赘述。
建立软连接
ln -s jdk1.7.0_79 jdk

[hadoop@hadoop1 ~]$ ll
total 4
drwxr-xr-x. 8 hadoop hadoop 4096 Apr 11 2015 jdk1.7.0_79
[hadoop@hadoop1 ~]$ ln -s jdk1.7.0_79/ jdk
[hadoop@hadoop1 ~]$ ll
total 4
lrwxrwxrwx. 1 hadoop hadoop 12 Apr 22 22:27 jdk -> jdk1.7.0_79/
drwxr-xr-x. 8 hadoop hadoop 4096 Apr 11 2015 jdk1.7.0_79
[hadoop@hadoop1 ~]$
hadoop2和hadoop3操作一样,不多赘述。
设置环境变量
vim /etc/profile

hadoop2和hadoop3操作一样,不多赘述。
添加如下:
#jdk
export JAVA_HOME=/home/hadoop/jdk
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH

hadoop2和hadoop3操作一样,不多赘述。
设置环境变量
source /etc/profile

hadoop2和hadoop3操作一样,不多赘述。
执行 java -version, 如果有版本显示则说明安装成功

三、安装 zookeeper
1、安装 zookeeper

[hadoop@hadoop1 ~]$ pwd
/home/hadoop
[hadoop@hadoop1 ~]$ ll
total 4
lrwxrwxrwx. 1 hadoop hadoop 12 Apr 22 22:27 jdk -> jdk1.7.0_79/
drwxr-xr-x. 8 hadoop hadoop 4096 Apr 11 2015 jdk1.7.0_79
[hadoop@hadoop1 ~]$ rz [hadoop@hadoop1 ~]$ ll
total 27408
lrwxrwxrwx. 1 hadoop hadoop 12 Apr 22 22:27 jdk -> jdk1.7.0_79/
drwxr-xr-x. 8 hadoop hadoop 4096 Apr 11 2015 jdk1.7.0_79
-rw-r--r--. 1 hadoop hadoop 28060242 Mar 20 10:24 zookeeper-3.4.5-cdh5.5.4.gz
[hadoop@hadoop1 ~]$
hadoop2和hadoop3都去操作,这里不多赘述。
1.1 安装
解压
cd /home/hadoop
tar zxvf zookeeper-3.4.5-cdh5.5.4.gz
[hadoop@hadoop1 ~]$ ll
total 27408
lrwxrwxrwx. 1 hadoop hadoop 12 Apr 22 22:34 jdk -> jdk1.7.0_79/
drwxr-xr-x. 8 hadoop hadoop 4096 Apr 11 2015 jdk1.7.0_79
-rw-r--r--. 1 hadoop hadoop 28060242 Mar 20 10:24 zookeeper-3.4.5-cdh5.5.4.gz
[hadoop@hadoop1 ~]$ tar -zxvf zookeeper-3.4.5-cdh5.5.4.gz
hadoop2和hadoop3都去操作,这里不多赘述。
1.2 建立软连接

[hadoop@hadoop1 ~]$ pwd
/home/hadoop
[hadoop@hadoop1 ~]$ ll
total 8
lrwxrwxrwx. 1 hadoop hadoop 12 Apr 22 22:27 jdk -> jdk1.7.0_79/
drwxr-xr-x. 8 hadoop hadoop 4096 Apr 11 2015 jdk1.7.0_79
drwxr-xr-x. 14 hadoop hadoop 4096 Apr 26 2016 zookeeper-3.4.5-cdh5.5.4
[hadoop@hadoop1 ~]$ ln -s zookeeper-3.4.5-cdh5.5.4/ zookeeper
[hadoop@hadoop1 ~]$ ll
total 8
lrwxrwxrwx. 1 hadoop hadoop 12 Apr 22 22:27 jdk -> jdk1.7.0_79/
drwxr-xr-x. 8 hadoop hadoop 4096 Apr 11 2015 jdk1.7.0_79
lrwxrwxrwx. 1 hadoop hadoop 25 Apr 22 22:49 zookeeper -> zookeeper-3.4.5-cdh5.5.4/
drwxr-xr-x. 14 hadoop hadoop 4096 Apr 26 2016 zookeeper-3.4.5-cdh5.5.4
[hadoop@hadoop1 ~]$
hadoop2和hadoop3都去操作,这里不多赘述。
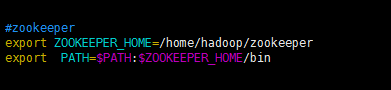
#zookeeper
export ZOOKEEPER_HOME=/home/hadoop/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
hadoop2和hadoop3都去操作,这里不多赘述。

[root@hadoop1 hadoop]# vim /etc/profile
[root@hadoop1 hadoop]# source /etc/profile
hadoop2和hadoop3都去操作,这里不多赘述。
1.3 修改配置文件
复制配置文件
cd /home/hadoop/zookeeper/conf
cp zoo_sample.cfg zoo.cfg

[hadoop@hadoop1 ~]$ ll
total 8
lrwxrwxrwx. 1 hadoop hadoop 12 Apr 22 22:27 jdk -> jdk1.7.0_79/
drwxr-xr-x. 8 hadoop hadoop 4096 Apr 11 2015 jdk1.7.0_79
lrwxrwxrwx. 1 hadoop hadoop 25 Apr 22 22:49 zookeeper -> zookeeper-3.4.5-cdh5.5.4/
drwxr-xr-x. 14 hadoop hadoop 4096 Apr 26 2016 zookeeper-3.4.5-cdh5.5.4
[hadoop@hadoop1 ~]$ cd zookeeper
[hadoop@hadoop1 zookeeper]$ cd conf/
[hadoop@hadoop1 conf]$ pwd
/home/hadoop/zookeeper/conf
[hadoop@hadoop1 conf]$ ll
total 12
-rw-rw-r--. 1 hadoop hadoop 535 Apr 26 2016 configuration.xsl
-rw-rw-r--. 1 hadoop hadoop 2693 Apr 26 2016 log4j.properties
-rw-rw-r--. 1 hadoop hadoop 808 Apr 26 2016 zoo_sample.cfg
[hadoop@hadoop1 conf]$ cp zoo_sample.cfg zoo.cfg
[hadoop@hadoop1 conf]$ ll
total 16
-rw-rw-r--. 1 hadoop hadoop 535 Apr 26 2016 configuration.xsl
-rw-rw-r--. 1 hadoop hadoop 2693 Apr 26 2016 log4j.properties
-rw-rw-r-- 1 hadoop hadoop 808 Apr 23 08:45 zoo.cfg
-rw-rw-r--. 1 hadoop hadoop 808 Apr 26 2016 zoo_sample.cfg
[hadoop@hadoop1 conf]$
hadoop2和hadoop3都去操作,这里不多赘述。

[hadoop@hadoop1 conf]$ pwd
/home/hadoop/zookeeper/conf
[hadoop@hadoop1 conf]$ ll
total 16
-rw-rw-r--. 1 hadoop hadoop 535 Apr 26 2016 configuration.xsl
-rw-rw-r--. 1 hadoop hadoop 2693 Apr 26 2016 log4j.properties
-rw-rw-r-- 1 hadoop hadoop 808 Apr 23 08:45 zoo.cfg
-rw-rw-r--. 1 hadoop hadoop 808 Apr 26 2016 zoo_sample.cfg
[hadoop@hadoop1 conf]$ vim zoo.cfg
hadoop2和hadoop3都去操作,这里不多赘述。
修改参数
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/home/hadoop/zookeeper/data
dataLogDir=/home/hadoop/zookeeper/logs
clientPort=2181
server.1=hadoop1:2888:3888
server.2=hadoop2:2888:3888
server.3=hadoop3:2888:3888

tickTime 时长单位为毫秒, 为 zk 使用的基本时间度量单位。 例如, 1 * tickTime 是客户端与 zk 服务端的心跳时间, 2 * tickTime 是客户端会话的超时时间。 tickTime 的默认值为2000 毫秒, 更低的 tickTime 值可以更快地发现超时问题, 但也会导致更高的网络流量(心跳消息)和更高的 CPU 使用率(会话的跟踪处理) 。
clientPort zk 服务进程监听的 TCP 端口, 默认情况下, 服务端会监听 2181 端口。dataDir 无默认配置, 必须配置, 用于配置存储快照文件的目录。 如果没有配置dataLogDir, 那么事务日志也会存储在此目录。
hadoop2和hadoop3都去操作,这里不多赘述。
创建目录
mkdir -p /home/hadoop/zookeeper/data
mkdir -p /home/hadoop/zookeeper/logs

hadoop2和hadoop3都去操作,这里不多赘述。
1.3 创建 ID 文件
在 dataDir 目录下(即/home/hadoop/zookeeper/data下)添加 myid 文件, 并把 server.x 中的 x 数字写入文件中

[hadoop@hadoop1 data]$ pwd
/home/hadoop/zookeeper/data
[hadoop@hadoop1 data]$ ll
total 0
[hadoop@hadoop1 data]$ vim myid 1
hadoop2和hadoop3都去操作,这里不多赘述。
2 启动 zookeeper
2.1 启动
cd /home/hadoop/zookeeper/bin
./zkServer.sh start
启动 ZK 服务: ./zkServer.sh start
查看 ZK 服务状态: ./zkServer.sh status
停止 ZK 服务: ./zkServer.sh stop
重启 ZK 服务: ./zkServer.sh restart

hadoop2和hadoop3都去操作,这里不多赘述。
2.1 测试
在 hadoop1 机器上的 zookeeper 中创建节点
cd /home/hadoop/zookeeper/bin
./zkCli.sh
create /hello hehe
这里不演示
在 hadoop2 机器上查看节点
cd /home/hadoop/zookeeper/bin
./zkCli.sh
这里不演示
get /hello //如果有值则说明 zookeeper 运行正常
2.1 进程的意义
这里不多赘述。
四、kafka的安装
4.1 安装
在 hadoop1、hadoop2和hadoop3 机器上安装
cd /home/hadoop
tar zxvf kafka_2.11-0.8.2.2.tgz
ln -s kafka_2.11-0.8.2.2 kafka

[hadoop@hadoop1 ~]$ ll
total 28
drwxr-xr-x 8 hadoop hadoop 4096 Apr 26 2016 apache-flume-1.6.0-cdh5.5.4-bin
drwxrwxr-x 5 hadoop hadoop 4096 Apr 23 18:34 data
lrwxrwxrwx 1 hadoop hadoop 32 Apr 23 18:14 flume -> apache-flume-1.6.0-cdh5.5.4-bin/
lrwxrwxrwx 1 hadoop hadoop 22 Apr 23 09:08 hadoop -> hadoop-2.6.0-cdh5.5.4/
drwxr-xr-x 18 hadoop hadoop 4096 Apr 23 09:50 hadoop-2.6.0-cdh5.5.4
lrwxrwxrwx 1 hadoop hadoop 21 Apr 23 16:55 hbase -> hbase-1.0.0-cdh5.5.4/
drwxr-xr-x 27 hadoop hadoop 4096 Apr 23 17:27 hbase-1.0.0-cdh5.5.4
lrwxrwxrwx 1 hadoop hadoop 20 Apr 23 15:27 hive -> hive-1.1.0-cdh5.5.4/
drwxr-xr-x 10 hadoop hadoop 4096 Apr 26 2016 hive-1.1.0-cdh5.5.4
lrwxrwxrwx. 1 hadoop hadoop 12 Apr 22 22:27 jdk -> jdk1.7.0_79/
drwxr-xr-x. 8 hadoop hadoop 4096 Apr 11 2015 jdk1.7.0_79
lrwxrwxrwx. 1 hadoop hadoop 25 Apr 22 22:49 zookeeper -> zookeeper-3.4.5-cdh5.5.4/
drwxr-xr-x. 16 hadoop hadoop 4096 Apr 23 08:57 zookeeper-3.4.5-cdh5.5.4
[hadoop@hadoop1 ~]$ rz [hadoop@hadoop1 ~]$ ll
total 15436
drwxr-xr-x 8 hadoop hadoop 4096 Apr 26 2016 apache-flume-1.6.0-cdh5.5.4-bin
drwxrwxr-x 5 hadoop hadoop 4096 Apr 23 18:34 data
lrwxrwxrwx 1 hadoop hadoop 32 Apr 23 18:14 flume -> apache-flume-1.6.0-cdh5.5.4-bin/
lrwxrwxrwx 1 hadoop hadoop 22 Apr 23 09:08 hadoop -> hadoop-2.6.0-cdh5.5.4/
drwxr-xr-x 18 hadoop hadoop 4096 Apr 23 09:50 hadoop-2.6.0-cdh5.5.4
lrwxrwxrwx 1 hadoop hadoop 21 Apr 23 16:55 hbase -> hbase-1.0.0-cdh5.5.4/
drwxr-xr-x 27 hadoop hadoop 4096 Apr 23 17:27 hbase-1.0.0-cdh5.5.4
lrwxrwxrwx 1 hadoop hadoop 20 Apr 23 15:27 hive -> hive-1.1.0-cdh5.5.4/
drwxr-xr-x 10 hadoop hadoop 4096 Apr 26 2016 hive-1.1.0-cdh5.5.4
lrwxrwxrwx. 1 hadoop hadoop 12 Apr 22 22:27 jdk -> jdk1.7.0_79/
drwxr-xr-x. 8 hadoop hadoop 4096 Apr 11 2015 jdk1.7.0_79
-rw-r--r-- 1 hadoop hadoop 15773865 Mar 20 10:24 kafka_2.11-0.8.2.2.tgz
lrwxrwxrwx. 1 hadoop hadoop 25 Apr 22 22:49 zookeeper -> zookeeper-3.4.5-cdh5.5.4/
drwxr-xr-x. 16 hadoop hadoop 4096 Apr 23 08:57 zookeeper-3.4.5-cdh5.5.4
[hadoop@hadoop1 ~]$
hadoop2和hadoop3操作,不多赘述。
[hadoop@hadoop1 ~]$ ll
total 15436
drwxr-xr-x 8 hadoop hadoop 4096 Apr 26 2016 apache-flume-1.6.0-cdh5.5.4-bin
drwxrwxr-x 5 hadoop hadoop 4096 Apr 23 18:34 data
lrwxrwxrwx 1 hadoop hadoop 32 Apr 23 18:14 flume -> apache-flume-1.6.0-cdh5.5.4-bin/
lrwxrwxrwx 1 hadoop hadoop 22 Apr 23 09:08 hadoop -> hadoop-2.6.0-cdh5.5.4/
drwxr-xr-x 18 hadoop hadoop 4096 Apr 23 09:50 hadoop-2.6.0-cdh5.5.4
lrwxrwxrwx 1 hadoop hadoop 21 Apr 23 16:55 hbase -> hbase-1.0.0-cdh5.5.4/
drwxr-xr-x 27 hadoop hadoop 4096 Apr 23 17:27 hbase-1.0.0-cdh5.5.4
lrwxrwxrwx 1 hadoop hadoop 20 Apr 23 15:27 hive -> hive-1.1.0-cdh5.5.4/
drwxr-xr-x 10 hadoop hadoop 4096 Apr 26 2016 hive-1.1.0-cdh5.5.4
lrwxrwxrwx. 1 hadoop hadoop 12 Apr 22 22:27 jdk -> jdk1.7.0_79/
drwxr-xr-x. 8 hadoop hadoop 4096 Apr 11 2015 jdk1.7.0_79
-rw-r--r-- 1 hadoop hadoop 15773865 Mar 20 10:24 kafka_2.11-0.8.2.2.tgz
lrwxrwxrwx. 1 hadoop hadoop 25 Apr 22 22:49 zookeeper -> zookeeper-3.4.5-cdh5.5.4/
drwxr-xr-x. 16 hadoop hadoop 4096 Apr 23 08:57 zookeeper-3.4.5-cdh5.5.4
[hadoop@hadoop1 ~]$ tar -zxvf kafka_2.11-0.8.2.2.tgz
hadoop2和hadoop3操作,不多赘述。

[hadoop@hadoop1 ~]$ ll
total 32
drwxr-xr-x 8 hadoop hadoop 4096 Apr 26 2016 apache-flume-1.6.0-cdh5.5.4-bin
drwxrwxr-x 5 hadoop hadoop 4096 Apr 23 18:34 data
lrwxrwxrwx 1 hadoop hadoop 32 Apr 23 18:14 flume -> apache-flume-1.6.0-cdh5.5.4-bin/
lrwxrwxrwx 1 hadoop hadoop 22 Apr 23 09:08 hadoop -> hadoop-2.6.0-cdh5.5.4/
drwxr-xr-x 18 hadoop hadoop 4096 Apr 23 09:50 hadoop-2.6.0-cdh5.5.4
lrwxrwxrwx 1 hadoop hadoop 21 Apr 23 16:55 hbase -> hbase-1.0.0-cdh5.5.4/
drwxr-xr-x 27 hadoop hadoop 4096 Apr 23 17:27 hbase-1.0.0-cdh5.5.4
lrwxrwxrwx 1 hadoop hadoop 20 Apr 23 15:27 hive -> hive-1.1.0-cdh5.5.4/
drwxr-xr-x 10 hadoop hadoop 4096 Apr 26 2016 hive-1.1.0-cdh5.5.4
lrwxrwxrwx. 1 hadoop hadoop 12 Apr 22 22:27 jdk -> jdk1.7.0_79/
drwxr-xr-x. 8 hadoop hadoop 4096 Apr 11 2015 jdk1.7.0_79
drwxr-xr-x 5 hadoop hadoop 4096 Sep 3 2015 kafka_2.11-0.8.2.2
lrwxrwxrwx. 1 hadoop hadoop 25 Apr 22 22:49 zookeeper -> zookeeper-3.4.5-cdh5.5.4/
drwxr-xr-x. 16 hadoop hadoop 4096 Apr 23 08:57 zookeeper-3.4.5-cdh5.5.4
[hadoop@hadoop1 ~]$ ln -s kafka_2.11-0.8.2.2/ kafka
[hadoop@hadoop1 ~]$ ll
total 32
drwxr-xr-x 8 hadoop hadoop 4096 Apr 26 2016 apache-flume-1.6.0-cdh5.5.4-bin
drwxrwxr-x 5 hadoop hadoop 4096 Apr 23 18:34 data
lrwxrwxrwx 1 hadoop hadoop 32 Apr 23 18:14 flume -> apache-flume-1.6.0-cdh5.5.4-bin/
lrwxrwxrwx 1 hadoop hadoop 22 Apr 23 09:08 hadoop -> hadoop-2.6.0-cdh5.5.4/
drwxr-xr-x 18 hadoop hadoop 4096 Apr 23 09:50 hadoop-2.6.0-cdh5.5.4
lrwxrwxrwx 1 hadoop hadoop 21 Apr 23 16:55 hbase -> hbase-1.0.0-cdh5.5.4/
drwxr-xr-x 27 hadoop hadoop 4096 Apr 23 17:27 hbase-1.0.0-cdh5.5.4
lrwxrwxrwx 1 hadoop hadoop 20 Apr 23 15:27 hive -> hive-1.1.0-cdh5.5.4/
drwxr-xr-x 10 hadoop hadoop 4096 Apr 26 2016 hive-1.1.0-cdh5.5.4
lrwxrwxrwx. 1 hadoop hadoop 12 Apr 22 22:27 jdk -> jdk1.7.0_79/
drwxr-xr-x. 8 hadoop hadoop 4096 Apr 11 2015 jdk1.7.0_79
lrwxrwxrwx 1 hadoop hadoop 19 Apr 23 18:41 kafka -> kafka_2.11-0.8.2.2/
drwxr-xr-x 5 hadoop hadoop 4096 Sep 3 2015 kafka_2.11-0.8.2.2
lrwxrwxrwx. 1 hadoop hadoop 25 Apr 22 22:49 zookeeper -> zookeeper-3.4.5-cdh5.5.4/
drwxr-xr-x. 16 hadoop hadoop 4096 Apr 23 08:57 zookeeper-3.4.5-cdh5.5.4
[hadoop@hadoop1 ~]$
hadoop2和hadoop3操作,不多赘述。
环境变量

[hadoop@hadoop1 ~]$ su root
Password:
[root@hadoop1 hadoop]# vim /etc/profile
hadoop2和hadoop3操作,不多赘述。

#kafka
export KAFKA_HOME=/home/hadoop/kafka
export PATH=$PATH:$KAFKA_HOME/bin
hadoop2和hadoop3操作,不多赘述。

[hadoop@hadoop1 ~]$ su root
Password:
[root@hadoop1 hadoop]# vim /etc/profile
[root@hadoop1 hadoop]# source /etc/profile
[root@hadoop1 hadoop]#
hadoop2和hadoop3操作,不多赘述。
4.1 修改配置文件
1. hadoop1 上修改 config/server.properties
export HBASE_MANAGES_ZK=false
broker.id=1
port=9092
host.name=hadoop1
log.dirs=/home/kafka-logs
num.partitions=5
log.cleaner.enable=false
offsets.storage=kafka
dual.commit.enabled=true
delete.topic.enable=true
zookeeper.connect=hadoop1:2181,hadoop2:2181,hadoop3:2181

2. hadoop2 上修改 config/server.properties
export HBASE_MANAGES_ZK=false
broker.id=2
port=9092
host.name=hadoop2
log.dirs=/home/kafka-logs
num.partitions=5
log.cleaner.enable=false
offsets.storage=kafka
dual.commit.enabled=true
delete.topic.enable=true
zookeeper.connect=hadoop1:2181,hadoop2:2181,hadoop3:2181
3. hadoop3 上修改 config/server.properties
export HBASE_MANAGES_ZK=false
broker.id=3
port=9092
host.name=hadoop3
log.dirs=/home/kafka-logs
num.partitions=5
log.cleaner.enable=false
offsets.storage=kafka
dual.commit.enabled=true
delete.topic.enable=true
zookeeper.connect=hadoop1:2181,hadoop2:2181,hadoop3:2181
创建目录
mkdir -p /home/kafka-logs
hadoop1、hadoop2和hadoop3都执行。

[hadoop@hadoop1 kafka]$ mkdir -p /home/kafka-logs
mkdir: cannot create directory `/home/kafka-logs': Permission denied
[hadoop@hadoop1 kafka]$ su root
Password:
[root@hadoop1 kafka]# mkdir -p /home/kafka-logs
[root@hadoop1 kafka]# chown -R hadoop:hadoop /home/kafka-logs
[root@hadoop1 kafka]# cd /home/
[root@hadoop1 home]# ll
total 8
drwx------. 26 hadoop hadoop 4096 Apr 23 21:18 hadoop
drwxr-xr-x 2 hadoop hadoop 4096 Apr 23 21:18 kafka-logs
[root@hadoop1 home]#
注意:在CDH版本的,发行者已经帮我们解决了这个问题。Apache版本,需要解决
首先解决kafka Unrecognized VM option ‘UseCompressedOops’问题
vi /home/hadoop/kafka/bin/kafka-run-class.sh
if [ -z "$KAFKA_JVM_PERFORMANCE_OPTS" ]; then
KAFKA_JVM_PERFORMANCE_OPTS="-server -XX:+UseCompressedOops -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+CMSClassUnloadingEnabled -XX:+CMSScavengeBeforeRemark -XX:+DisableExplicitGC -Djava.awt.headless=true"
fi
去掉-XX:+UseCompressedOops即可

[hadoop@hadoop1 bin]$ pwd
/home/hadoop/kafka/bin
[hadoop@hadoop1 bin]$ ll
total 80
-rwxr-xr-x 1 hadoop hadoop 943 Sep 3 2015 kafka-console-consumer.sh
-rwxr-xr-x 1 hadoop hadoop 942 Sep 3 2015 kafka-console-producer.sh
-rwxr-xr-x 1 hadoop hadoop 870 Sep 3 2015 kafka-consumer-offset-checker.sh
-rwxr-xr-x 1 hadoop hadoop 946 Sep 3 2015 kafka-consumer-perf-test.sh
-rwxr-xr-x 1 hadoop hadoop 860 Sep 3 2015 kafka-mirror-maker.sh
-rwxr-xr-x 1 hadoop hadoop 884 Sep 3 2015 kafka-preferred-replica-election.sh
-rwxr-xr-x 1 hadoop hadoop 946 Sep 3 2015 kafka-producer-perf-test.sh
-rwxr-xr-x 1 hadoop hadoop 872 Sep 3 2015 kafka-reassign-partitions.sh
-rwxr-xr-x 1 hadoop hadoop 866 Sep 3 2015 kafka-replay-log-producer.sh
-rwxr-xr-x 1 hadoop hadoop 872 Sep 3 2015 kafka-replica-verification.sh
-rwxr-xr-x 1 hadoop hadoop 4185 Sep 3 2015 kafka-run-class.sh
-rwxr-xr-x 1 hadoop hadoop 1333 Sep 3 2015 kafka-server-start.sh
-rwxr-xr-x 1 hadoop hadoop 891 Sep 3 2015 kafka-server-stop.sh
-rwxr-xr-x 1 hadoop hadoop 868 Sep 3 2015 kafka-simple-consumer-shell.sh
-rwxr-xr-x 1 hadoop hadoop 861 Sep 3 2015 kafka-topics.sh
drwxr-xr-x 2 hadoop hadoop 4096 Sep 3 2015 windows
-rwxr-xr-x 1 hadoop hadoop 1370 Sep 3 2015 zookeeper-server-start.sh
-rwxr-xr-x 1 hadoop hadoop 875 Sep 3 2015 zookeeper-server-stop.sh
-rwxr-xr-x 1 hadoop hadoop 968 Sep 3 2015 zookeeper-shell.sh
[hadoop@hadoop1 bin]$ vim kafka-run-class.sh
这里,不需自己去解决。
在三台机器上的kafka目录下,分别执行以下命令
nohup bin/kafka-server-start.sh config/server.properties &
[hadoop@hadoop1 kafka]$ pwd
/home/hadoop/kafka
[hadoop@hadoop1 kafka]$ nohup bin/kafka-server-start.sh config/server.properties &
[1] 15091
[hadoop@hadoop1 kafka]$ nohup: ignoring input and appending output to `nohup.out' [1]+ Exit 1 nohup bin/kafka-server-start.sh config/server.properties
[hadoop@hadoop1 kafka]$
出现以下提示后回车即可。
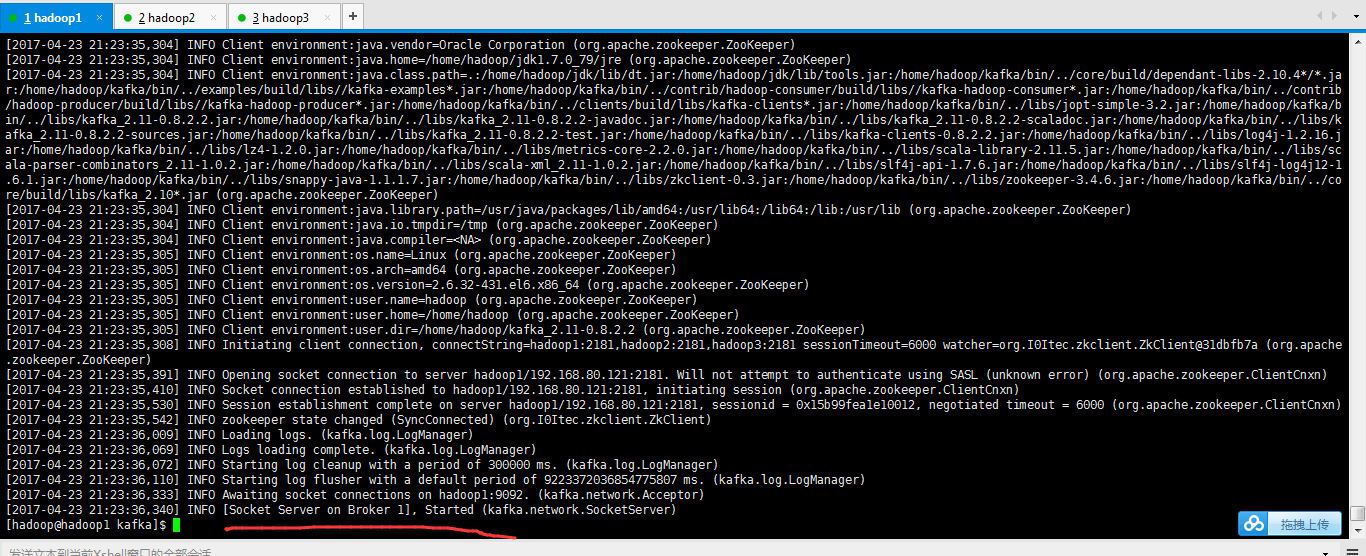
查看状态
cat nohup.out
[2017-04-23 21:23:35,304] INFO Client environment:java.vendor=Oracle Corporation (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:23:35,304] INFO Client environment:java.home=/home/hadoop/jdk1.7.0_79/jre (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:23:35,304] INFO Client environment:java.class.path=.:/home/hadoop/jdk/lib/dt.jar:/home/hadoop/jdk/lib/tools.jar:/home/hadoop/kafka/bin/../core/build/dependant-libs-2.10.4*/*.jar:/home/hadoop/kafka/bin/../examples/build/libs//kafka-examples*.jar:/home/hadoop/kafka/bin/../contrib/hadoop-consumer/build/libs//kafka-hadoop-consumer*.jar:/home/hadoop/kafka/bin/../contrib/hadoop-producer/build/libs//kafka-hadoop-producer*.jar:/home/hadoop/kafka/bin/../clients/build/libs/kafka-clients*.jar:/home/hadoop/kafka/bin/../libs/jopt-simple-3.2.jar:/home/hadoop/kafka/bin/../libs/kafka_2.11-0.8.2.2.jar:/home/hadoop/kafka/bin/../libs/kafka_2.11-0.8.2.2-javadoc.jar:/home/hadoop/kafka/bin/../libs/kafka_2.11-0.8.2.2-scaladoc.jar:/home/hadoop/kafka/bin/../libs/kafka_2.11-0.8.2.2-sources.jar:/home/hadoop/kafka/bin/../libs/kafka_2.11-0.8.2.2-test.jar:/home/hadoop/kafka/bin/../libs/kafka-clients-0.8.2.2.jar:/home/hadoop/kafka/bin/../libs/log4j-1.2.16.jar:/home/hadoop/kafka/bin/../libs/lz4-1.2.0.jar:/home/hadoop/kafka/bin/../libs/metrics-core-2.2.0.jar:/home/hadoop/kafka/bin/../libs/scala-library-2.11.5.jar:/home/hadoop/kafka/bin/../libs/scala-parser-combinators_2.11-1.0.2.jar:/home/hadoop/kafka/bin/../libs/scala-xml_2.11-1.0.2.jar:/home/hadoop/kafka/bin/../libs/slf4j-api-1.7.6.jar:/home/hadoop/kafka/bin/../libs/slf4j-log4j12-1.6.1.jar:/home/hadoop/kafka/bin/../libs/snappy-java-1.1.1.7.jar:/home/hadoop/kafka/bin/../libs/zkclient-0.3.jar:/home/hadoop/kafka/bin/../libs/zookeeper-3.4.6.jar:/home/hadoop/kafka/bin/../core/build/libs/kafka_2.10*.jar (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:23:35,304] INFO Client environment:java.library.path=/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:23:35,304] INFO Client environment:java.io.tmpdir=/tmp (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:23:35,304] INFO Client environment:java.compiler=<NA> (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:23:35,305] INFO Client environment:os.name=Linux (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:23:35,305] INFO Client environment:os.arch=amd64 (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:23:35,305] INFO Client environment:os.version=2.6.32-431.el6.x86_64 (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:23:35,305] INFO Client environment:user.name=hadoop (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:23:35,305] INFO Client environment:user.home=/home/hadoop (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:23:35,305] INFO Client environment:user.dir=/home/hadoop/kafka_2.11-0.8.2.2 (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:23:35,308] INFO Initiating client connection, connectString=hadoop1:2181,hadoop2:2181,hadoop3:2181 sessionTimeout=6000 watcher=org.I0Itec.zkclient.ZkClient@31dbfb7a (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:23:35,391] INFO Opening socket connection to server hadoop1/192.168.80.121:2181. Will not attempt to authenticate using SASL (unknown error) (org.apache.zookeeper.ClientCnxn)
[2017-04-23 21:23:35,410] INFO Socket connection established to hadoop1/192.168.80.121:2181, initiating session (org.apache.zookeeper.ClientCnxn)
[2017-04-23 21:23:35,530] INFO Session establishment complete on server hadoop1/192.168.80.121:2181, sessionid = 0x15b99fea1e10012, negotiated timeout = 6000 (org.apache.zookeeper.ClientCnxn)
[2017-04-23 21:23:35,542] INFO zookeeper state changed (SyncConnected) (org.I0Itec.zkclient.ZkClient)
[2017-04-23 21:23:36,009] INFO Loading logs. (kafka.log.LogManager)
[2017-04-23 21:23:36,069] INFO Logs loading complete. (kafka.log.LogManager)
[2017-04-23 21:23:36,072] INFO Starting log cleanup with a period of 300000 ms. (kafka.log.LogManager)
[2017-04-23 21:23:36,110] INFO Starting log flusher with a default period of 9223372036854775807 ms. (kafka.log.LogManager)
[2017-04-23 21:23:36,333] INFO Awaiting socket connections on hadoop1:9092. (kafka.network.Acceptor)
[2017-04-23 21:23:36,340] INFO [Socket Server on Broker 1], Started (kafka.network.SocketServer)
[hadoop@hadoop1 kafka]$

r:/home/hadoop/kafka/bin/../examples/build/libs//kafka-examples*.jar:/home/hadoop/kafka/bin/../contrib/hadoop-consumer/build/libs//kafka-hadoop-consumer*.jar:/home/hadoop/kafka/bin/../contrib/hadoop-producer/build/libs//kafka-hadoop-producer*.jar:/home/hadoop/kafka/bin/../clients/build/libs/kafka-clients*.jar:/home/hadoop/kafka/bin/../libs/jopt-simple-3.2.jar:/home/hadoop/kafka/bin/../libs/kafka_2.11-0.8.2.2.jar:/home/hadoop/kafka/bin/../libs/kafka_2.11-0.8.2.2-javadoc.jar:/home/hadoop/kafka/bin/../libs/kafka_2.11-0.8.2.2-scaladoc.jar:/home/hadoop/kafka/bin/../libs/kafka_2.11-0.8.2.2-sources.jar:/home/hadoop/kafka/bin/../libs/kafka_2.11-0.8.2.2-test.jar:/home/hadoop/kafka/bin/../libs/kafka-clients-0.8.2.2.jar:/home/hadoop/kafka/bin/../libs/log4j-1.2.16.jar:/home/hadoop/kafka/bin/../libs/lz4-1.2.0.jar:/home/hadoop/kafka/bin/../libs/metrics-core-2.2.0.jar:/home/hadoop/kafka/bin/../libs/scala-library-2.11.5.jar:/home/hadoop/kafka/bin/../libs/scala-parser-combinators_2.11-1.0.2.jar:/home/hadoop/kafka/bin/../libs/scala-xml_2.11-1.0.2.jar:/home/hadoop/kafka/bin/../libs/slf4j-api-1.7.6.jar:/home/hadoop/kafka/bin/../libs/slf4j-log4j12-1.6.1.jar:/home/hadoop/kafka/bin/../libs/snappy-java-1.1.1.7.jar:/home/hadoop/kafka/bin/../libs/zkclient-0.3.jar:/home/hadoop/kafka/bin/../libs/zookeeper-3.4.6.jar:/home/hadoop/kafka/bin/../core/build/libs/kafka_2.10*.jar (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:25:34,857] INFO Client environment:java.library.path=/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:25:34,857] INFO Client environment:java.io.tmpdir=/tmp (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:25:34,857] INFO Client environment:java.compiler=<NA> (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:25:34,858] INFO Client environment:os.name=Linux (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:25:34,858] INFO Client environment:os.arch=amd64 (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:25:34,858] INFO Client environment:os.version=2.6.32-431.el6.x86_64 (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:25:34,858] INFO Client environment:user.name=hadoop (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:25:34,858] INFO Client environment:user.home=/home/hadoop (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:25:34,858] INFO Client environment:user.dir=/home/hadoop/kafka_2.11-0.8.2.2 (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:25:34,862] INFO Initiating client connection, connectString=hadoop1:2181,hadoop2:2181,hadoop3:2181 sessionTimeout=6000 watcher=org.I0Itec.zkclient.ZkClient@3764253e (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:25:35,713] INFO Opening socket connection to server hadoop3/192.168.80.123:2181. Will not attempt to authenticate using SASL (unknown error) (org.apache.zookeeper.ClientCnxn)
[2017-04-23 21:25:35,811] INFO Socket connection established to hadoop3/192.168.80.123:2181, initiating session (org.apache.zookeeper.ClientCnxn)
[2017-04-23 21:25:35,884] INFO Session establishment complete on server hadoop3/192.168.80.123:2181, sessionid = 0x35b99ff49bf0012, negotiated timeout = 6000 (org.apache.zookeeper.ClientCnxn)
[2017-04-23 21:25:35,890] INFO zookeeper state changed (SyncConnected) (org.I0Itec.zkclient.ZkClient)
[2017-04-23 21:25:37,146] INFO Loading logs. (kafka.log.LogManager)
[2017-04-23 21:25:37,243] INFO Logs loading complete. (kafka.log.LogManager)
[2017-04-23 21:25:37,245] INFO Starting log cleanup with a period of 300000 ms. (kafka.log.LogManager)
[2017-04-23 21:25:37,300] INFO Starting log flusher with a default period of 9223372036854775807 ms. (kafka.log.LogManager)
[2017-04-23 21:25:37,798] INFO Awaiting socket connections on hadoop2:9092. (kafka.network.Acceptor)
[2017-04-23 21:25:37,803] INFO [Socket Server on Broker 2], Started (kafka.network.SocketServer)
[2017-04-23 21:25:39,744] INFO Will not load MX4J, mx4j-tools.jar is not in the classpath (kafka.utils.Mx4jLoader$)
[2017-04-23 21:25:42,084] INFO Registered broker 2 at path /brokers/ids/2 with address hadoop2:9092. (kafka.utils.ZkUtils$)
[2017-04-23 21:25:42,520] INFO [Kafka Server 2], started (kafka.server.KafkaServer)
[hadoop@hadoop2 kafka]$

r:/home/hadoop/kafka/bin/../examples/build/libs//kafka-examples*.jar:/home/hadoop/kafka/bin/../contrib/hadoop-consumer/build/libs//kafka-hadoop-consumer*.jar:/home/hadoop/kafka/bin/../contrib/hadoop-producer/build/libs//kafka-hadoop-producer*.jar:/home/hadoop/kafka/bin/../clients/build/libs/kafka-clients*.jar:/home/hadoop/kafka/bin/../libs/jopt-simple-3.2.jar:/home/hadoop/kafka/bin/../libs/kafka_2.11-0.8.2.2.jar:/home/hadoop/kafka/bin/../libs/kafka_2.11-0.8.2.2-javadoc.jar:/home/hadoop/kafka/bin/../libs/kafka_2.11-0.8.2.2-scaladoc.jar:/home/hadoop/kafka/bin/../libs/kafka_2.11-0.8.2.2-sources.jar:/home/hadoop/kafka/bin/../libs/kafka_2.11-0.8.2.2-test.jar:/home/hadoop/kafka/bin/../libs/kafka-clients-0.8.2.2.jar:/home/hadoop/kafka/bin/../libs/log4j-1.2.16.jar:/home/hadoop/kafka/bin/../libs/lz4-1.2.0.jar:/home/hadoop/kafka/bin/../libs/metrics-core-2.2.0.jar:/home/hadoop/kafka/bin/../libs/scala-library-2.11.5.jar:/home/hadoop/kafka/bin/../libs/scala-parser-combinators_2.11-1.0.2.jar:/home/hadoop/kafka/bin/../libs/scala-xml_2.11-1.0.2.jar:/home/hadoop/kafka/bin/../libs/slf4j-api-1.7.6.jar:/home/hadoop/kafka/bin/../libs/slf4j-log4j12-1.6.1.jar:/home/hadoop/kafka/bin/../libs/snappy-java-1.1.1.7.jar:/home/hadoop/kafka/bin/../libs/zkclient-0.3.jar:/home/hadoop/kafka/bin/../libs/zookeeper-3.4.6.jar:/home/hadoop/kafka/bin/../core/build/libs/kafka_2.10*.jar (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:26:10,239] INFO Client environment:java.library.path=/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:26:10,240] INFO Client environment:java.io.tmpdir=/tmp (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:26:10,240] INFO Client environment:java.compiler=<NA> (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:26:10,241] INFO Client environment:os.name=Linux (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:26:10,241] INFO Client environment:os.arch=amd64 (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:26:10,241] INFO Client environment:os.version=2.6.32-431.el6.x86_64 (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:26:10,241] INFO Client environment:user.name=hadoop (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:26:10,241] INFO Client environment:user.home=/home/hadoop (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:26:10,241] INFO Client environment:user.dir=/home/hadoop/kafka_2.11-0.8.2.2 (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:26:10,244] INFO Initiating client connection, connectString=hadoop1:2181,hadoop2:2181,hadoop3:2181 sessionTimeout=6000 watcher=org.I0Itec.zkclient.ZkClient@3764253e (org.apache.zookeeper.ZooKeeper)
[2017-04-23 21:26:11,052] INFO Opening socket connection to server hadoop3/192.168.80.123:2181. Will not attempt to authenticate using SASL (unknown error) (org.apache.zookeeper.ClientCnxn)
[2017-04-23 21:26:11,080] INFO Socket connection established to hadoop3/192.168.80.123:2181, initiating session (org.apache.zookeeper.ClientCnxn)
[2017-04-23 21:26:11,370] INFO Session establishment complete on server hadoop3/192.168.80.123:2181, sessionid = 0x35b99ff49bf0013, negotiated timeout = 6000 (org.apache.zookeeper.ClientCnxn)
[2017-04-23 21:26:11,505] INFO zookeeper state changed (SyncConnected) (org.I0Itec.zkclient.ZkClient)
[2017-04-23 21:26:12,561] INFO Loading logs. (kafka.log.LogManager)
[2017-04-23 21:26:12,698] INFO Logs loading complete. (kafka.log.LogManager)
[2017-04-23 21:26:12,702] INFO Starting log cleanup with a period of 300000 ms. (kafka.log.LogManager)
[2017-04-23 21:26:12,918] INFO Starting log flusher with a default period of 9223372036854775807 ms. (kafka.log.LogManager)
[2017-04-23 21:26:14,277] INFO Awaiting socket connections on hadoop3:9092. (kafka.network.Acceptor)
[2017-04-23 21:26:14,623] INFO [Socket Server on Broker 3], Started (kafka.network.SocketServer)
[2017-04-23 21:26:17,519] INFO Will not load MX4J, mx4j-tools.jar is not in the classpath (kafka.utils.Mx4jLoader$)
[2017-04-23 21:26:19,961] INFO Registered broker 3 at path /brokers/ids/3 with address hadoop3:9092. (kafka.utils.ZkUtils$)
[2017-04-23 21:26:20,172] INFO [Kafka Server 3], started (kafka.server.KafkaServer)
[hadoop@hadoop3 kafka]$
至此,kafka_2.11-0.8.2.2.tgz的3节点集群的搭建完成!
扩展补充
kafka的server.properties配置文件参考示范(图文详解)(多种方式)
kafka_2.11-0.8.2.2.tgz的3节点集群的下载、安装和配置(图文详解)的更多相关文章
- kafka_2.10-0.8.1.1.tgz的1或3节点集群的下载、安装和配置(图文详细教程)绝对干货
运行kafka ,需要依赖 zookeeper,你可以使用已有的 zookeeper 集群或者利用 kafka自带的zookeeper. 单机模式,用的是kafka自带的zookeeper, 分布式模 ...
- Hyperledger Fabric 1.0 从零开始(九)——Fabric多节点集群生产启动
7:Fabric多节点集群生产启动 7.1.多节点服务器配置 在生产环境上,我们沿用4.1.配置说明中的服务器各节点配置方案. 我们申请了五台生产服务器,其中四台服务器运行peer节点,另外一台服务器 ...
- redis3.0 集群实战1 -- 安装和配置
本文主要是在centos7上安装和配置redis集群实战 参考: http://hot66hot.iteye.com/blog/2050676 集群教程: http://redisdoc.com/to ...
- ansys19.0安装破解教程(图文详解)
ansys19.0是一款非常著名的大型通用有限元分析(FEA)软件.该软件能够与多数计算机辅助设计软件接口,比如Creo, NASTRAN.Algor.I-DEAS.AutoCAD等,并能实现数据的共 ...
- creo2.0安装方法和图文详解教程
Creo2.0是由PTC公司2012年8月底推出的全新CAD设计软件包,整合了PTC公司的三个软件Pro/Engineer的参数化技术.CoCreate的直接建模技术和ProductView的三维可视 ...
- Hyperledger Fabric 1.0 从零开始(八)——Fabric多节点集群生产部署
6.1.平台特定使用的二进制文件配置 该方案与Hyperledger Fabric 1.0 从零开始(五)--运行测试e2e类似,根据企业需要,可以控制各节点的域名,及联盟链的统一域名.可以指定单独节 ...
- hadoop-2.6.0.tar.gz + spark-1.6.1-bin-hadoop2.6.tgz + zeppelin-0.5.6-incubating-bin-all.tgz(master、slave1和slave2)(博主推荐)(图文详解)
不多说,直接上干货! 我这里,采取的是CentOS6.5,当然大家也可以在ubuntu 16.04系统里,这些都是小事 CentOS 6.5的安装详解 hadoop-2.6.0.tar.gz + sp ...
- hadoop-2.7.3.tar.gz + spark-2.0.2-bin-hadoop2.7.tgz + zeppelin-0.6.2-incubating-bin-all.tgz(master、slave1和slave2)(博主推荐)(图文详解)
不多说,直接上干货! 我这里,采取的是ubuntu 16.04系统,当然大家也可以在CentOS6.5里,这些都是小事 CentOS 6.5的安装详解 hadoop-2.6.0.tar.gz + sp ...
- 基于Web的Kafka管理器工具之Kafka-manager的编译部署详细安装 (支持kafka0.8、0.9和0.10以后版本)(图文详解)(默认端口或任意自定义端口)
不多说,直接上干货! 至于为什么,要写这篇博客以及安装Kafka-manager? 问题详情 无奈于,在kafka里没有一个较好自带的web ui.启动后无法观看,并且不友好.所以,需安装一个第三方的 ...
随机推荐
- poj 3233 Matrix Power Series 矩阵求和
http://poj.org/problem?id=3233 题解 矩阵快速幂+二分等比数列求和 AC代码 #include <stdio.h> #include <math.h&g ...
- nyoj_758_分苹果
分苹果 时间限制:1000 ms | 内存限制:65535 KB 难度:2 描述 把M个同样的苹果放在N个同样的盘子里,允许有的盘子空着不放,问共有多少种不同的分法? (注意:假如有3个盘子7 ...
- [bzoj2287][poj Challenge]消失之物_背包dp_容斥原理
消失之物 bzoj-2287 Poj Challenge 题目大意:给定$n$个物品,第$i$个物品的权值为$W_i$.记$Count(x,i)$为第$i$个物品不允许使用的情况下拿到重量为$x$的方 ...
- URL传递多个参数遇到的bug
bug所在: 通过URL传递多个参数的时候,其一是中文出现乱码,其二是空格被“%20”替代: 原因分析:原理暂时还不清楚,后续再研究下原理,只知道有中文的时候就会出现乱码:%20是url空格的编码: ...
- IOS程序崩溃报告管理解决方案(Crashlytics 在2014-09-24)
预研Crashlytics 在2014-09-241:实现原理在原理上,Crashlytics通过以下2步完成崩溃日志的上传和分析:(1)提供应用SDK,你需要在应用启动时调用其SDK来设置你的应用 ...
- A* Pathfinding Project (Unity A*寻路插件) 使用教程
Unity4.6 兴许版本号都已经内置了寻路AI了.之前的文章有介绍 Unity3d 寻路功能 介绍及项目演示 然而两年来项目中一直使用的是 A* Pathfinding 这个插件的.所以抽时间来写下 ...
- 爸爸和儿子的故事带你理解java线程
今天回想线程方面的知识,发现一个非常有意思的小程序.是用来说明多线程的以下贴出来分享下,对刚開始学习的人理解线程有非常大的帮助 爸爸和儿子的故事 <span style="font-f ...
- Loadrunner&Jemeter进行手机APP压力测试
一.loadrunner通过代理录制app脚本 随着手机APP的广泛应用,手机应用的使用已占据了大量的市场份额,尤其是优秀的手机APP,动辄用户过千万过亿,对于如此庞大的用户量,我们在开发APP时,也 ...
- 复制class文件到as中出现非法字符,须要class,interface货enum
问题如题,出现此情况是在导入eclipse项目到Android Studio出现这种错误, 非法字符: '\ufeff' 解决方式|错误: 须要class, interface或enum,查阅后了解到 ...
- Linux/Android——输入子系统input_event传递 (二)【转】
本文转载自:http://blog.csdn.net/jscese/article/details/42099381 在前文Linux/Android——usb触摸屏驱动 - usbtouchscre ...