CDH搭建Hadoop分布式服务器集群(java新手小白)
1首先对于一个java还白的小白,先理解CDH与Hadoop的关系
一、Hadoop版本选择。
Hadoop大致可分为Apache Hadoop和第三方发行第三方发行版Hadoop,考虑到Hadoop集群部署的高效,集群的稳定性,
以及后期集中的配置管理,业界多使用Cloudera公司的发行版,简称为CDH。
下面是转载的Hadoop社区版本与第三方发行版本的比较:
Apache社区版本
优点:
- 完全开源免费。社区活跃文档、资料详实
缺点:
- 因为很活跃所以版本对应关系,各个版本层出不穷,让使用者不知所措,版本冲突兼容等。部署集群运维难度大。
第三方发行版本(如CDH,HDP,MapR等)
优点:
- 基于Apache协议,100%开源。
- 版本管理清晰。比如Cloudera,CDH1,CDH2,CDH3,CDH4等,后面加上补丁版本,如CDH4.1.0 patch level 923.142,表示在原生态Apache Hadoop 0.20.2基础上添加了1065个patch。
- 比Apache Hadoop在兼容性、安全性、稳定性上有增强。第三方发行版通常都经过了大量的测试验证,有众多部署实例,大量的运行到各种生产环境。
- 版本更新快。通常情况,比如CDH每个季度会有一个update,每一年会有一个release。
- 基于稳定版本Apache Hadoop,并应用了最新Bug修复或Feature的patch
- 提供了部署、安装、配置工具,大大提高了集群部署的效率,可以在几个小时内部署好集群。
- 运维简单。提供了管理、监控、诊断、配置修改的工具,管理配置方便,定位问题快速、准确,使运维工作简单,有效。
缺点:
- 涉及到厂商锁定的问题。(可以通过技术解决)
转自 http://itindex.net/detail/51484-自学-大数据-生产
因为要经常使用linux系统,安装虚拟机下面是地址
https://blog.csdn.net/babyxue/article/details/80970526
CDH是apache hadoop发行版
CM是集群管理工具
主从架构Master-slaves
主节点:Server一个,负责集群部署文件的分发
从节点:Agent多个,负责收集所在服务器的资源状态信息,监测进程运行状态
二、硬件检查与系统配置
1.硬件检查
1)检查内存
2)检查所有磁盘挂载。将noatime参数写入/etc/fstab,并remount所有数据盘。这一步并不知道有什么用,看一下就行,有点像是清理磁盘,提高性能,这一步最好在新机器上,没有他用的时候执行,我觉得,有错请指正
3)检查磁盘读写
4)检测网卡设置
5)检测路由
6)检查系统版本
做这些目的是,保证没问题,看看即可,因为一些小细节可能就会出现整个框架不能使用,以下也要细心操作, 另外下载的cm版本cdh版本mysql版本jdbc jar包版本要兼容
2.系统配置(centos7为例)
1)配置hostname与/etc/hosts(所有服务器)
1.设置的方法有很多 常用命令
查看 hostname
hostname cdh1 cdh1是我起的主机名
hostnamectl set-hostname cdh1
这两个命令的实质是修改 /etc/hostname 中的值
2.修改 /etc/hosts 中的值,解析所有节点主节点服务器
127.0.0.1 cdh1
172.17.6.64 cdh1
172.17.6.65 cdh2
2)所有节点安装SSH(所有服务器)/免密登录其他服务器节点
1可以选择CM server到agent通过用户名密码登录或者是公钥的方式。(推荐)
// 我认为 在cm如果检测不到管理主机,会使用用户名密码的方式
命令 ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/fdipzone/.ssh/id_rsa): 这里输入要生成的文件名 直接回车
Enter passphrase (empty for no passphrase): 这里输入密码 直接回车
Enter same passphrase again: 这里重复输入密码 直接回车生成两个文件在 /root/.ssh/ 下
id_rsa.pubid_rsa 循环复制秘钥到每个服务器节点
for num in `seq 2 2`;do ssh-copy-id -i /root/.ssh/id_rsa.pub cdh$num;done 2若使用用户名的方式,需保证所有服务器root用户名和密码一致。
3)安装Oracle JDK(所有服务器)
查看本机是否安装jdk
java -version rpm -qa|grep jdk
查看安装的java jdk 如果没有安装下面地址jdk,如果是openjdk就先卸载
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 下载linux版本64位 rpm
下载之后上传到linux(使用rz sz命令),或者直接下载
我下载的是jdk-8u201-linux-x64.rpm 对应的1.8版本,不知道对不对
安装命令 rpm -ivh jdk-8u201-linux-x64.rpm
查看jdk版本 java -version
更改环境变量
首先找到jdk安装位置 一般在/usr/java/下
vim /etc/profile //打开环境变量文件
usr/java/jdk1.8.0_131 是jdk安装路径 CLASSPATH 中找到tools.jar 与dt.jar位置不要错 也有可能在 jre/lib下,还有几点需要注意,j
ar包位置不能错,环境变量引用使用$符合 windows中是%%
JAVA_HOME=/usr/java/jdk1.8.0_131
CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/rt.jar:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
export PATH CLASSPATH JAVA_HOME
将上面4行加入profile底部
source /etc/profile //重新载入
4)关闭防火墙和SELinux(所有服务器)
查看防火墙状态
firewall-cmd --state
停止防火墙
service firewalld stop 或者 systemctl stop firewalld
禁止firewall开机启动
systemctl disable firewalld.service
关闭selinux
进入到/etc/selinux/config文件
将SELINUX=enforcing改为SELINUX=disabled
需要重启电脑
或者
sed -i 's/SELINUX=enforcing/SELINUX=disable/g' /etc/selinux/config
setenforce 0
实质一样,修改文件参数
查看防火墙与selinux状态
service firewalld status
sestatus -v
5)设置swappiness,优化交换分区(所有服务器)
RHEL6 版本系统
sysctl -w vm.swappiness=0
/etc/sysctl.conf添加以下内容:vm.swappiness = 0
RHEL7 版本系统
tuned 服务会动态调整系统参数,查找 tuned 中配置,直接将配置修改为 vm.swappiness=0
cd /usr/lib/tuned/
grep "vm.swappiness" * -R
6)设置ulimit(所有服务器)
ulimit -n 65535
/etc/security/limits.conf添加以下内容:
soft nofile 65535
hard nofile 65535
7)设置ntp服务(所有服务器节点)
[root@cdh1~]#yum -y install ntp
更改主机的节点
[root@cdh1~]## vi /etc/ntp.conf
注释掉所有server *.*.*的指向,新添加一条可连接的ntp服务器(我随便搜了个ntp测试服务器)
server cn.ntp.org.cn iburst
在其他节点上把ntp指向master服务器地址即可(/etc/ntp.conf下)
server 172.17.6.64 iburst
[root@cdh1~]## systemctl start ntpd //启动ntp服务 我习惯使用service ntpd start 这种格式的命令 实质一样
[root@cdh1~]## systemctl status ntpd //查看ntp服务状态service ntpd status
8)设置DNS(所有服务器节点)
若集群域名解析仅依赖/etc/hosts文件,建议注释掉/etc/resolv.conf,以避免不良影响。
9)关闭THP
CDH 5 所支持的大多数 Linux 平台包含名为透明大页面压缩的功能,该功能与 Hadoop 工作负载交互较差,可能会严重影响性能,因此建议关闭。
命令行执行以下命令,并写到/etc/rc.local文件中。
echo never > /sys/kernel/mm/redhat_transparent_hugepage/enabled
echo never > /sys/kernel/mm/redhat_transparent_hugepage/defrag
根据系统版本不同查看具体位置路径 也可能是下面的
echo never > /sys/kernel/mm/transparent_hugepage/defrag
echo never > /sys/kernel/mm/transparent_hugepage/enabled
启动服务命令也可以写在此文件中,例如 service cloudera-scm-server restart 等
三、数据库安装与配置
1)安装数据库
卸载自带的mariadb
[root@cdh1 /]# rpm -qa | grep mariadb
mariadb-libs-5.5.41-2.el7_0.x86_64
[root@cdh1 /]# rpm -e --nodeps mariadb-libs-5.5.41-2.el7_0.x86_64 下面安装mysql没有成功,先跳过
安装mysql 建议安装5.7版本 太高这个cdh初始化总失败 jdbc 以及一些初始化语句,我又重新安装之后可以了
https://www.mysql.com/downloads/ 可以在站点下载 或者使用yum方式安装
[root@cdh1 /]# rpm -qa | grep mariadb
mariadb-libs-5.5.41-2.el7_0.x86_64
[root@cdh1 /]# rpm -e --nodeps mariadb-libs-5.5.41-2.el7_0.x86_64
[root@cdh1 /]# tar -xvf MySQL-5.6.24-1.linux_glibc2.5.x86_64.rpm-bundle.tar //mysql rpm包拷贝到服务器上然后解压
[root@cdh1 /]# rpm -ivh MySQL-*.rpm //如果低版本不符合下面格式的用这个就可以,安装释出的全部rpm 这一步最好挨个安装,安装顺序如下,其他可以不装
rpm -ivh mysql-community-common-8.0.11-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-8.0.11-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-8.0.11-1.el7.x86_64.rpm
rpm -ivh mysql-community-server-8.0.11-1.el7.x86_64.rpm
---------------------
// warning :Header V3 DSA/SHA1 Signature 这一步我出问题了 这是由于yum安装了旧版本的GPG keys造成的 解决办法 rpm命令后 加--force --nodeps
如果使用yum命令安装软件则需要引用rpm --import /etc/pki/rpm-gpg/RPM*
[root@cdh1 /]# cp /usr/share/mysql/my-default.cnf /etc/my.cnf //如果此位置已有则不用复制
[root@cdh1 /]# vi /etc/my.cnf //在配置文件中增加以下配置并保存
[mysqld]
default-storage-engine = innodb
innodb_file_per_table
collation-server = utf8_general_ci
init-connect = 'SET NAMES utf8'
character-set-server = utf8
[root@cdh1 /]# yum install -y perl-Module-Install.noarch //CentOS7最小版本时候 MySQL的Perl依赖包
[root@cdh1 /]# mysqld --initialize --user=mysql
[root@cdh1 /]#service mysqld start//启动mysql
使用 service 启动:service mysqld stop 这两步不做,知识标记知道怎么停止
使用命令 # service mysqld status 或者 # service mysql status 命令来查看mysql 的启动状态
[root@cdh1 /]#cat /var/log/mysqld.log //查看mysql root初始化密码
[root@cdh1 /]# mysql -u root -p //登录进行去更改密码 密码就是刚才查看的初始密码
语句执行之前先选择库 use mysql
mysql>ALTER user 'root'@'localhost' IDENTIFIED BY 'Aa@111111' //mysql 5.7之后改密码语句,必须包含大写小写数字特殊符号
mysql> update user set host='%' where user='root' and host='localhost'; //允许mysql远程访问
Query OK, 1 row affected (0.05 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> flush privileges; //重新加载权限
如果是mysql 8.0 下面三个 修改密码规则
ALTER USER 'root'@'localhost' IDENTIFIED BY 'password' PASSWORD EXPIRE NEVER; #修改加密规则
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'password'; #更新一下用户的密码
FLUSH PRIVILEGES; #刷新权限
[root@cdh1 /]# chkconfig mysql on //配置开机启动 找到mysql的启动项
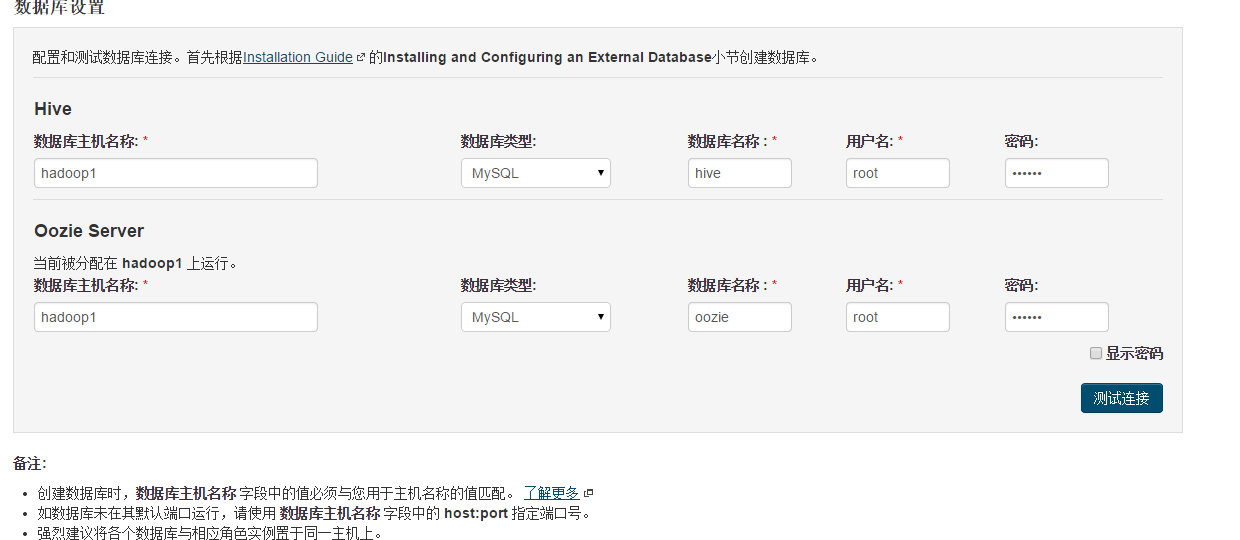
创建数据库,cdh服务启动后使用(CM安装cdh 组件相关数据库)
create database hive DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
Query OK, 1 row affected (0.00 sec)
create database amon DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
Query OK, 1 row affected (0.00 sec)
create database hue DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
Query OK, 1 row affected (0.00 sec)
create database monitor DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
Query OK, 1 row affected (0.00 sec)
create database oozie DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
Query OK, 1 row affected (0.00 sec)
grant all on *.* to root@"%" Identified by "123456"; //mysql8.0之前权限这么写
四、CM Server/Agent及CDH相关套件安装
- cloudera manager包 :5.7.2 cloudera-manager-centos7-cm5.7.2_x86_64.tar.gz
下载地址:http://archive.cloudera.com/cm5/cm/5/cloudera-manager-centos7-cm5.7.2_x86_64.tar.gz - CDH-5.7.2-1.cdh5.7.2.p0.11-el7.parcel
- CDH-5.7.2-1.cdh5.7.2.p0.11-el7.parcel.sha1
- manifest.json
以上三个下载地址在http://archive.cloudera.com/cdh5/parcels/5.7.2/,注意centos要下载el7的跟rdel版本有关系
第三方依赖包 所有节点都安装
yum install chkconfig python bind-utils psmisc libxslt zlib sqlite fuse fuse-libs redhat-lsb cyrus-sasl-plain cyrus-sasl-gssapi
下载jdbc连接包mysql-connector-java-5.1.39-bin.jar: http://dev.mysql.com/downloads/connector/j/
[root@hadoop1]# mkdir -p /usr/share/java
//将mysql-connector-java-5.1.XX-bin.jar拷贝到/usr/share/java路径下并重命名为mysql-connector-java.jar 根据数据库版本选择
重命名原因是cm使用的jdbc链接的jar包名是引用的是mysql-connector-java.jar
转字https://www.cnblogs.com/zhangleisanshi/p/7575579.html mysql-connector-java要与数据库版本匹配,或者找到cdh初始化配置文件, 没找到....
//解压cm tar包到指定目录所有服务器都要(或者在主节点解压好,然后通过scp到各个节点同一目录下)这个在cm启动后网页界面可以看到分配操作
//5.7.2这是解压缩安装cm 最新的版本用的是安装的方式自行理解,首先装cm 参考
// https://blog.csdn.net/lxbalex/article/details/83188753#CM_ServerAgentCDH_164
//和 https://blog.csdn.net/Chirs_Chen/article/details/85266251
//或者 https://blog.csdn.net/lxbalex/article/details/83188753#3CM_Web_176
[root@cdh1 ~]#mkdir /opt/cloudera-manager
[root@cdh1 ~]# tar -axvf cloudera-manager-centos7-cm5.7.2_x86_64.tar.gz -C /opt/cloudera-manager
//创建cloudera-scm用户(所有节点)
[root@cdh1 ~]# useradd --system --home=/opt/cloudera-manager/cm-5.7.2/run/cloudera-scm-server --no-create-home --shell=/bin/false --comment "Cloudera SCM User" cloudera-scm
//在主节点创建cloudera-manager-server的本地元数据保存目录 这个后来我感觉并没有什么用,可能还没有用到
[root@cdh1 ~]# mkdir /var/cloudera-scm-server
[root@cdh1 ~]# chown cloudera-scm:cloudera-scm /var/cloudera-scm-server
[root@cdh1 ~]# chown cloudera-scm:cloudera-scm /opt/cloudera-manager
//配置从节点cloudera-manger-agent指向主节点服务器
[root@cdh1 ~]# vi /opt/cloudera-manager/cm-5.7.2/etc/cloudera-scm-agent/config.ini
将server_host改为CMS所在的主机名即cdh1
vim /etc/cloudera-scm-agent/config.ini use_tls=1
//主节点中创建parcel-repo仓库目录
[root@cdh1 ~]# mkdir -p /opt/cloudera/parcel-repo
[root@cdh1 ~]# chown cloudera-scm:cloudera-scm /opt/cloudera/parcel-repo
[root@cdh1 ~]# cp CDH-5.7.2-1.cdh5.7.2.p0.18-el7.parcel CDH-5.7.2-1.cdh5.7.2.p0.18-el7.parcel.sha manifest.json /opt/cloudera/parcel-repo
注意:其中CDH-5.7.2-1.cdh5.7.2.p0.18-el5.parcel.sha1 后缀要把1去掉 或者提前改名
//所有节点创建parcels目录
[root@cdh1 ~]# mkdir -p /opt/cloudera/parcels
[root@cdh1 ~]# chown cloudera-scm:cloudera-scm /opt/cloudera/parcels
解释:Clouder-Manager将CDHs从主节点的/opt/cloudera/parcel-repo目录中抽取出来,分发解压激活到各个节点的/opt/cloudera/parcels目录中
//初始脚本配置数据库scm_prepare_database.sh(在主节点上)
[root@cdh1 ~]# /opt/cloudera-manager/cm-5.7.2/share/cmf/schema/scm_prepare_database.sh mysql -hcdh1 -uroot -p111111 --scm-host cdh1 scm root 111111
说明:这个脚本就是用来创建和配置CMS需要的数据库的脚本。各参数是指:
mysql:数据库用的是mysql,如果安装过程中用的oracle,那么该参数就应该改为oracle。
-cdh1:数据库建立在cdh1主机上面,也就是主节点上面。
-uroot:root身份运行mysql。-111111:mysql的root密码是***。
--scm-host cdh1:CMS的主机,一般是和mysql安装的主机是在同一个主机上,最后三个参数是:数据库名,数据库用户名,数据库密码。
如果报错:
Access denied for user 'root'@'cdh1'
则增加以下权限 不同数据库版本方式不一样,参考mysql安装时权限
update user set PASSWORD=PASSWORD('123456') where user='root';
GRANT ALL PRIVILEGES ON *.* TO 'root'@'cdh1' IDENTIFIED BY '123456' WITH GRANT OPTION;
FLUSH PRIVILEGES;
//启动主节点
[root@cdh1 ~]# cp /opt/cloudera-manager/cm-5.7.2/etc/init.d/cloudera-scm-server /etc/init.d/cloudera-scm-server
[root@cdh1 ~]# chkconfig cloudera-scm-server on
[root@cdh1 ~]# vi /etc/init.d/cloudera-scm-server
CMF_DEFAULTS=${CMF_DEFAULTS:-/etc/default}改为=/opt/cloudera-manager/cm-5.7.2/etc/default #你的cloudera manager安装目录,然后保存退出即可
[root@cdh1 ~]# service cloudera-scm-server start
//同时为了保证在每次服务器重启的时候都能启动cloudera-scm-server,应该在开机启动脚本/etc/rc.local中加入命令:service cloudera-scm-server restart
//启动cloudera-scm-agent所有节点
[root@cdhX ~]# mkdir /opt/cloudera-manager/cm-5.7.2/run/cloudera-scm-agent
[root@cdhX ~]# cp /opt/cloudera-manager/cm-5.7.2/etc/init.d/cloudera-scm-agent /etc/init.d/cloudera-scm-agent
[root@cdhX ~]# chkconfig cloudera-scm-agent on
[root@cdhX ~]# vi /etc/init.d/cloudera-scm-agent
CMF_DEFAULTS=${CMF_DEFAULTS:-/etc/default}改为=/opt/cloudera-manager/cm-5.7.2/etc/default
[root@cdhX ~]# service cloudera-scm-agent start
//同时为了保证在每次服务器重启的时候都能启动cloudera-scm-agent,应该在开机启动脚本/etc/rc.local中加入命令:service cloudera-scm-agent restart
服务启动之后稍等片刻 大约1-3分钟左右
使用浏览器登陆CM Web页面进行集群安装
等待主节点完成启动就在浏览器中进行操作了
进入172.17.6.64:7180 默认使用admin admin登录
//如果页面不能访问 如果服务正常,数据库scm正常,稍等片刻再进入,让子弹飞一会 再试试
以下在浏览器中使用操作安装
下一步不贴图了,在下一步
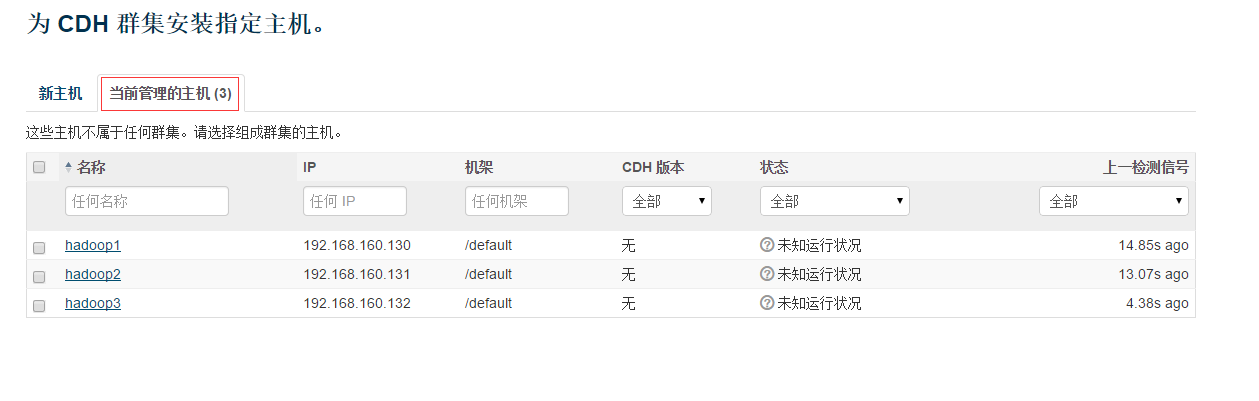
配置主机:由于我们在各个节点都安装启动了agent,并且在中各个节点都在配置文件中指向cdh1是server节点,所以这里我们可以在“当前管理的主机”中看到三个主机,全部勾选并继续.
注意:如果cloudera-scm-agent没有设为开机启动,或者ntp时间偏移,或者ip解析,不对,或者hostname不对,
如果以上有重启这里可能会检测不到其他服务器。检测到管理的服务器才说明agent正常参数正常(以下都是这个操作),否则显示的是选择新主机,筛选主机 不正常操作
然后选择选择cdh版本,选择我们下载的版本 注意 proxy settings 中设置的是分发数据源,地址位置我们之前都配置过了
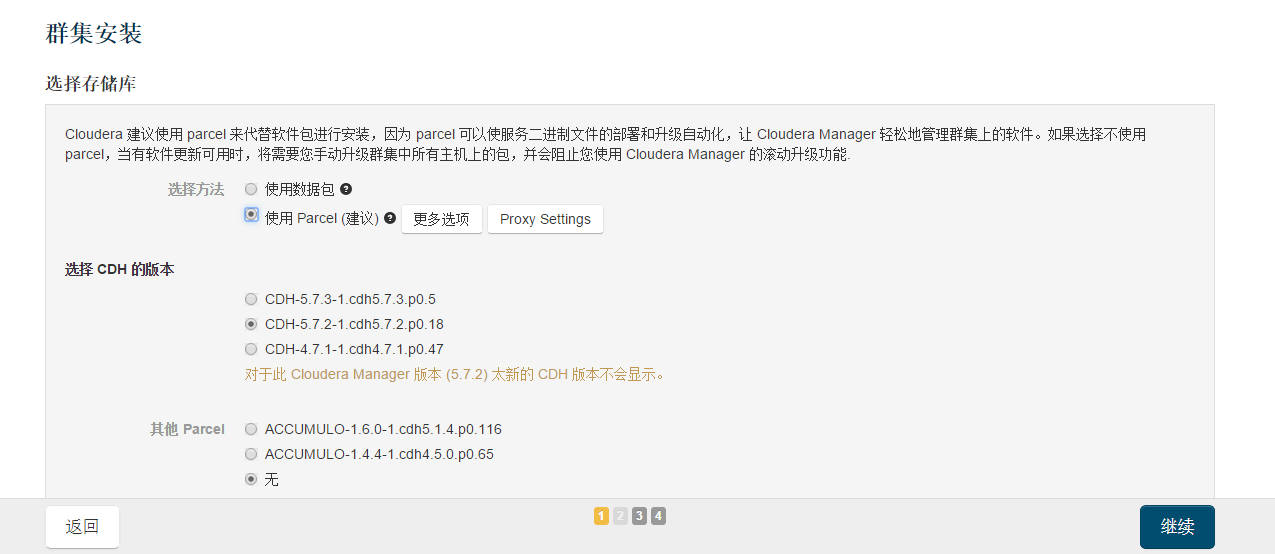
如果这里需要安装组件也可以选择包括kafka
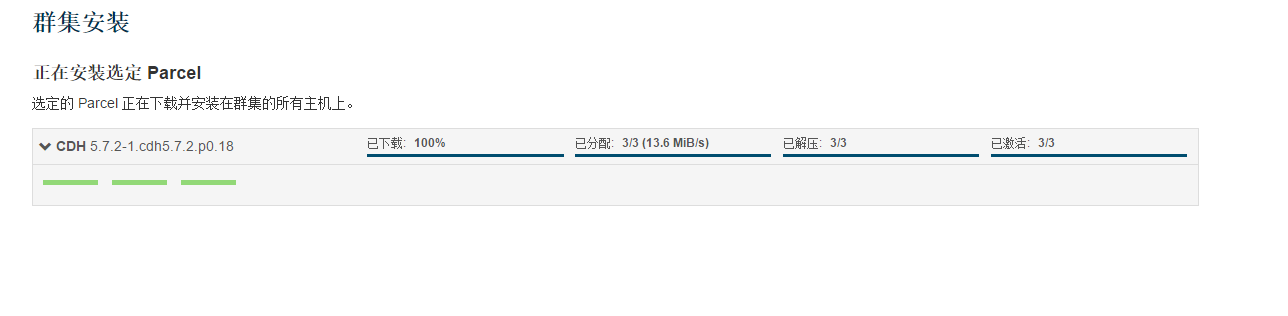
因为偶尔们是本地分发,下载直接100%,如果你勾选的有其他选项会有一个下载过程,注意,无论哪个过程,包括分发,都是有进度数据读数可查的,如果几分钟都没有动静
应该是配置有问题,不要硬装,请检查是否当前管理主机,检查agent服务是否正常

如果这个地方要注意这个地方有两项没有检查通过,可以在集群中使用以下命令
echo 0 > /proc/sys/vm/swappiness
echo never > /sys/kernel/mm/transparent_hugepage/defrag
再重新检查
在下面的我都选择默认,主要本人没有使用过,不知道怎么配置更合理
上一步安装组件,如果硬件内存不给力,会很忙,甚至死机,我分配2G虚拟机,就使用峰值
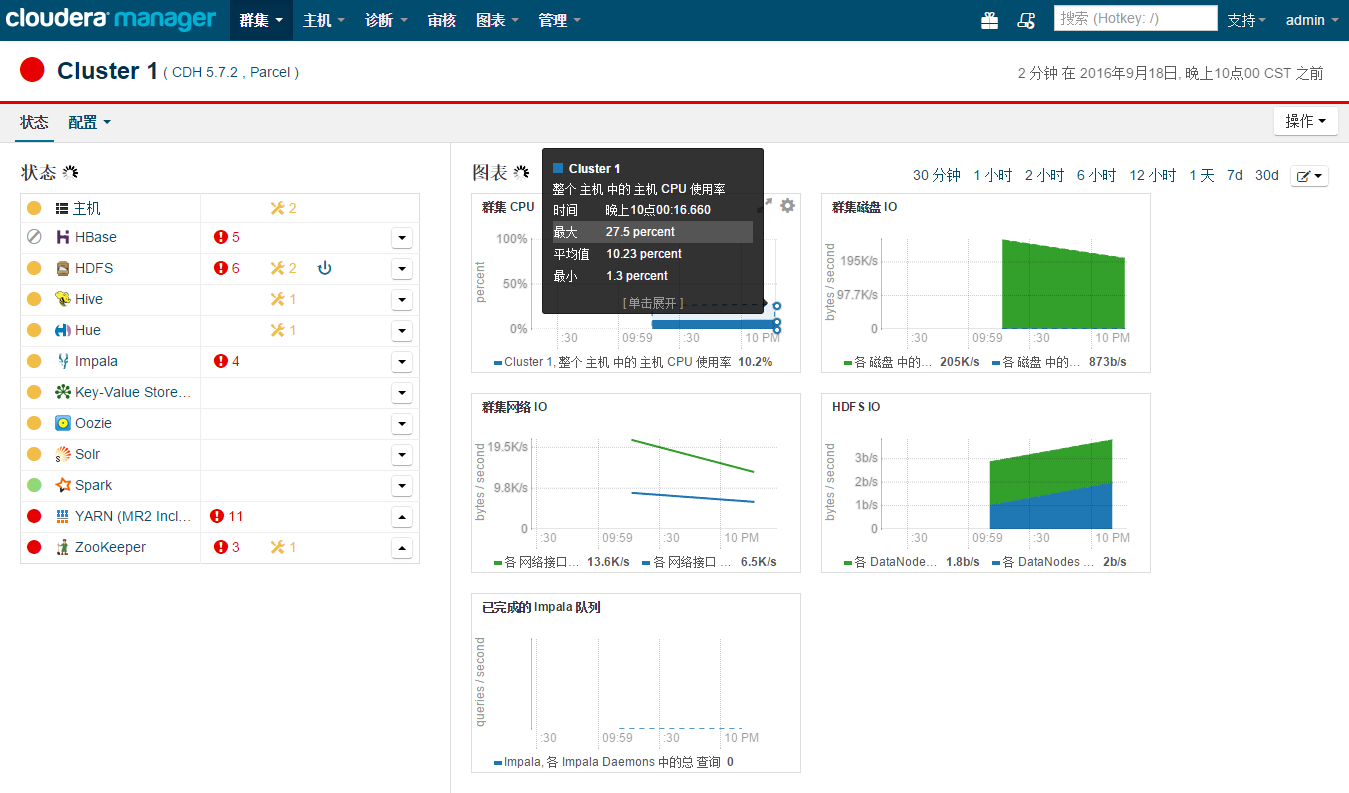
这个时候安装完成了,可以在浏览器中进入172.17.6.64:7180地址,查看集群情况,我这里有挺多报警,大概查看下基本都是内存或者存储空间使用阈值的报警,由于我们是本地虚拟机的,所以这些条件都有限
配置Yarn资源
关于Yarn内存分配与管理,主要涉及到了ResourceManage(集群资源调度协调)、ApplicationMatser(任务资源配置)、NodeManager(YARN节点代理配置)这几个概念,相关的优化也要紧紧围绕着这几方面来开展。
点击Yarn -> 资源管理:
设置ApplicationMaster Java最大堆栈:800M(AM内存默认1G)
容器内存yarn.nodemanager.resource.memory-mb
计算一个节点需要分配的容器内存方法:
主机内存-操作系统预留内存(12G) - Cloudera Manager Agent(1G) - HDFS DN(1G) – Yarn NM(1G)
= 主机内存-15G
如果安装了hive.需减掉12G左右内存.
如果安装了hbase.还需减掉12-16G内存。
如果安装impala.还需减掉至少16G内存。
例:64G内存主机,如果安装了hbase,hive,则建议分配的容器内存大约为:25~30G
容器虚拟CPU内核yarn.nodemanager.resource.cpu-vcores
计算一个节点需要分配的容器虚拟内核方法:
(主机cpu核数 – 系统预留1 – Cloudera1 – HDFS1 – Yarn NN 1) * 4
Hbase : -1
例:24核机器,为yarn分配可用cpu核数大约20核左右,按照 核数:处理任务数=1:4(比例可酌情调整),建议分配为80。由于本次集群CPU计算能力没达到官网建议的比例的要求,大约分配的比例为1:2,分配的核数为30核左右。高级配置中:mapred-site.xml 的 MapReduce 客户端高级配置代码段(安全阀)
CDH开发
安装完毕,我们还想开发提到开发,我们就想到eclipse插件,其实我们在开发过程中,插件作用就是帮助我们能够方便的看到在Linux的文件。
所以开发方式也有两种,
一种插件开发
我们如何找到eclipse插件,可以参考
cloudera CDH(5)开发方式及CDH eclipse插件编译总结
一种是无插件开发
无插件开发,也就是直接添加开发包
可以参考:hadoop开发方式总结及操作指导
主要参考资料
http://www.cnblogs.com/itboys/p/5955545.html
https://www.cnblogs.com/zhangleisanshi/p/7575579.html
https://blog.51cto.com/kaliarch/2122467
资源配置
https://blog.csdn.net/silentwolfyh/article/details/83549202
https://www.cnblogs.com/wzlbigdata/p/8277757.html 硬件配置
https://www.cnblogs.com/wangyaning/p/6131474.html yarn等资源配置测试
https://blog.csdn.net/enweitech/article/details/68945657 中间有讲到cdh开发插件化开发
cdh维护
https://blog.csdn.net/silentwolfyh/article/details/72629215
重新安装Agent 导致Server-Agent不匹配
https://blog.csdn.net/qq_21383435/article/details/87889452
另外我是个java新手麻烦问一下,这个集群装好之后都能怎么使用,怎么部署站点QQ410838107
CDH搭建Hadoop分布式服务器集群(java新手小白)的更多相关文章
- 用三台虚拟机搭建Hadoop全分布集群
用三台虚拟机搭建Hadoop全分布集群 所有的软件都装在/home/software下 虚拟机系统:centos6.5 jdk版本:1.8.0_181 zookeeper版本:3.4.7 hadoop ...
- 0基础搭建Hadoop大数据处理-集群安装
经过一系列的前期环境准备,现在可以开始Hadoop的安装了,在这里去apache官网下载2.7.3的版本 http://www.apache.org/dyn/closer.cgi/hadoop/com ...
- ZooKeeper学习之路 (九)利用ZooKeeper搭建Hadoop的HA集群
Hadoop HA 原理概述 为什么会有 hadoop HA 机制呢? HA:High Available,高可用 在Hadoop 2.0之前,在HDFS 集群中NameNode 存在单点故障 (SP ...
- 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 二.集群规划 三.前置条件 四.集群配置 五.启动集群 六.查看集群 七.集群的二次启动 一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS ...
- Hadoop 学习之路(八)—— 基于ZooKeeper搭建Hadoop高可用集群
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求 ...
- Hadoop 系列(八)—— 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求 ...
- docker应用-3(搭建hadoop以及hbase集群)
要用docker搭建集群,首先需要构造集群所需的docker镜像.构建镜像的一种方式是,利用一个已有的镜像比如简单的linux系统,运行一个容器,在容器中手动的安装集群所需要的软件并进行配置,然后co ...
- H01-Linux系统中搭建Hadoop和Spark集群
前言 1.操作系统:Centos7 2.安装时使用的是root用户.也可以用其他非root用户,非root的话要注意操作时的权限问题. 3.安装的Hadoop版本是2.6.5,Spark版本是2.2. ...
- AWS EC2 搭建 Hadoop 和 Spark 集群
前言 本篇演示如何使用 AWS EC2 云服务搭建集群.当然在只有一台计算机的情况下搭建完全分布式集群,还有另外几种方法:一种是本地搭建多台虚拟机,好处是免费易操控,坏处是虚拟机对宿主机配置要求较高, ...
随机推荐
- Layui导航、面包屑
物不在多,有用则精! 学习使用链接 导航:导航一般指页面引导性频道集合,多以菜单的形式呈现,可应用于头部和侧边,是整个网页画龙点晴般的存在.面包屑结构简单,支持自定义分隔符.千万不要忘了加载 elem ...
- [bzoj4131]并行博弈_博弈论
并行博弈 bzoj-4131 题目大意:题目链接. 注释:略. 想法:我们发现无论如何操作都会使得$(1,1)$发生改变. 所以单个$ACG$的胜利条件就是$(1,1)$是否为黑色. 如果为黑色那么可 ...
- easyui datagrid-detailview 嵌套高度自适应
实现效果 原因 异步加载,明细展开时,可能会遇到父列表不能自动适应子列表高度的变化 具体代码 $('#centerdatagrid').datagrid({ url:'${ctx}/offer/off ...
- 教程 | 使用Sqoop从MySQL导入数据到Hive和HBase
基础环境 sqoop:sqoop-1.4.5+cdh5.3.6+78, hive:hive-0.13.1+cdh5.3.6+397, hbase:hbase-0.98.6+cdh5.3.6+115 S ...
- 重置网络命令win7
开始→运行→输入:CMD 点击确定(或按回车键),打开命令提示符窗口. 在命令提示符中输入:netsh winsock reset (按回车键执行命令) 稍后,会有成功的提示:成功地重置Winsock ...
- luajit利用ffi结合C语言实现面向对象的封装库
luajit中.利用ffi能够嵌入C.眼下luajit的最新版是2.0.4,在这之前的版本号我还不清楚这个扩展库详细怎么样,只是在2.04中,真的非常爽. 既然是嵌入C代码.那么要说让lua支持 ...
- Python按行输出文件内容具体解释及延伸
下面两端測试代码分别为笔者所写,第一段为错误版本号.后者为正确版本号: #! /usr/bin/python2.7 try: filename = raw_input('please inpu ...
- 2016/2/22 1、Window.document对象
1.Window.document对象 一.找到元素: docunment.getElementById("id"):根据id找,最多找一个: var a =docunme ...
- my.os.ClickThisWindow.ClickThisPoint.py
my.os.ClickThisWindow.ClickThisPoint.py
- GraphDatabase_action
https://neo4j.com/docs/ #https://pypi.python.org/pypi/neo4j-driver/1.5.3from neo4j.v1 import GraphDa ...