Hadoop_09_HDFS 的 NameNode工作机制
理解NameNode的工作机制尤其是元数据管理机制,以增强对HDFS工作原理的理解,及培养hadoop集群运营中“性能调优”
“NameNode”故障问题的分析解决能力
1.NameNode职责:
Hadoop集群中有两种节点,一种是NameNode,还有一种是DataNode;其中DataNode主要负责数据的存储,NameNode主
要负责三个功能,分别是;(1)管理元数据 (2)维护目录树 (3)响应客户请求
2.元数据管理:
NameNode对数据的管理采用了三种存储形式:
1.内存元数据(NameSystem)
2.磁盘元数据镜像文件(fsImage)
3.数据操作日志文件(可通过日志运算出元数据)
3.NameNode元数据管理机制
首先介绍下,元数据格式:

hdfs在外界看来就是普通的文件系统,可以通过路径进行数据的访问等操作,但在实际过程存储中,却是分布在各个节点上。
如上图所示的是一条元数据,/test/a.log 是在hdfs文件系统中的路径,3是这个文件的副本数(副本数可以通过在配置文件中的
配置来修改的)。在hdfs中,文件是进行分块存储的,如果文件过大,就要分成多块存储,每个块在文件系统中存储3个副本,以
上图为例,就是分成blk_1和blk_2两个块,每个块在实际的节点中有3个副本,比如blk_1的3个副本分别存储在h0,h1,h3中
现在由此引出一个问题,Namenode中的元数据是存储在哪里的?首先,我们假设如果存储在Namenode节点的磁盘中,因为经
常需要进行随机访问,还有响应客户请求,必然是效率过低。因此,元数据需要存放在内存中。但如果只存在内存中,一旦断点,
元数据丢失,整个集群就无法工作了!!!因此必须在磁盘中有备份,在磁盘中的备份就是fsImage,存放在Namenode节点对应的
磁盘中。当在内存中的元数据更新时,如果同时更新fsImage镜像文件(文件的随机读写),会导致效率过低,但如果不更新,就会
发生一致性问题,一旦Namenode节点断电,就会产生数据丢失。因此,引入操作日志文件edits.log(只进行追加操作,效率很高)。
每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到edits.log中。这样,一旦Namenode节点断电,可以通过镜像
文件fsImage和edits.log的合并,合成元数据。但是,如果长时间添加数据到edit.log中,会导致该文件数据过大,效率降低且一
旦断电,恢复元数据需要的时间过长。因此,需要定期进行fsImage和edits.log的合并,如果这个操作由Namenode节点完成,又会
效率过低。因此,引入一个新的节点secondaryNamenode,专门用于fsImage和edits.log的合并。
元数据的Checkpoint:每隔一段时间,由secondaryNamenode将Namenode上积累的所有edits和一个最新的fsimage下载到本地,
并加载到内存进行merge(这个过程称为checkpoint)
元数据的Checkpoint处理过程的具体步骤如下:
1)Namenode节点每隔一定时间请求secondaryNamenode合并操作(满足触发条件)
2)secondaryNamenode请求Namenode进行edits.log的滚动,这样新的编辑操作就能够进入新的文件中
3)secondaryNamenode从namenode中下载fsImage和edits.log
4)secondaryNamenode进行fsImage和edits.log的合并,成为fsImage.checkpoint文件
5)namenode下载合并后的fsImage.checkpoin文件
6)将fsImage.checkpoint和edits.new命名为原来的文件名(这样之后fsImage和内存中的元数据只差edits.new
元数据的Checkpoint机制流程图:

4.CheckPoint操作的触发条件配置参数
dfs.namenode.checkpoint.check.period=60 #检查触发条件是否满足的频率,60秒
dfs.namenode.checkpoint.dir=file://${hadoop.tmp.dir}/dfs/namesecondary
#以上两个参数做checkpoint操作时,secondary namenode的本地工作目录
dfs.namenode.checkpoint.edits.dir=${dfs.namenode.checkpoint.dir} dfs.namenode.checkpoint.max-retries=3 #最大重试次数
dfs.namenode.checkpoint.period=3600 #两次checkpoint之间的时间间隔3600秒
dfs.namenode.checkpoint.txns=1000000 #两次checkpoint之间最大的操作记录
5.总结:
5.1.元数据存储机制
A、内存中有一份完整的元数据(内存metadata)
B、磁盘有一个“准完整”的元数据镜像(fsimage)文件(在namenode的工作目录中)
C、用于衔接内存metadata和持久化元数据镜像fsimage之间的操作日志(edits文件)
注:当客户端对hdfs中的文件进行新增或者修改操作,操作记录首先被记入edits日志文件中,当客户端操作成功后,相应的元数据
会更新到内存metadata中
5.2.如果NameNode的硬盘损坏,元数据是否还能恢复,如果能恢复,该如何恢复?
:可恢复绝大部分数据,NameNode和secondaryNamenode的工作目录存储结构完全相同,所以,当Namenode故障退出需要重新恢复时,
可以将SecondaryNamenode的工作目录拷贝到namenode的工作目录,以恢复namenode的元数据

5.3.如果NameNode宕机,hdfs服务能否正常提供?
:不能,虽然SecondaryNamenode有元数据信息,但不能更新元数据,不能充当NameNode使用;
5.4.通过以上思考,我们在配置NameNode工作目录参数时,应该注意什么?
:NameNode的工作目录应该配置在多块磁盘上,同时往多块磁盘上写日志,数据时相同的;
:修改NameNode的配置文件:vi /usr/local/src/hadoop-2.6.4/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.name.dir</name>
<value>/disk1/name1,/disk2/name2</value>
</property>
:然后重新对NameNode format :hadoop namenode -format,会重新生成两个name1和name2目录
:dfs.name.dir属性可以配置多个目录,各个目录存储的文件结构和内容完全相同,相当于备份,这样做的好处就是当其中
一个目录损坏了,也不会影响到Hadoop的元数据,
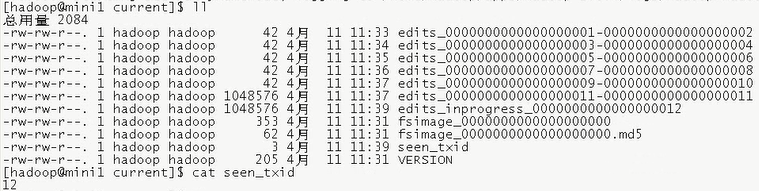
5.5.补充:该hdpdata/dfs/name/current/目录下的seen_txid文件:
:该文件中记录的是edits滚动的序号,每次重启NnmeNode时,NnmeNode就知道该加载哪些edits(序号小的)
Hadoop_09_HDFS 的 NameNode工作机制的更多相关文章
- NameNode工作机制
NameNode工作机制
- NameNode && Secondary NameNode工作机制
NameNode && Secondary NameNode工作机制 1)工作流程 2) fsimage和edits NameNode是HDFS的大脑,它维护着整个文件系统的目录树, ...
- HDFS中NameNode和Secondary NameNode工作机制
NameNode工作机制 0)启动概述 Namenode启动时,首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作.一旦在内存中成功建立文件系统元数据的映像,则创建一个 ...
- NameNode&Secondary NameNode 工作机制
NameNode&Secondary NameNode 工作机制 NameNode: 1.启动时,加载编辑日志和镜像文件到内存 2.当客户端对元数据进行增删改,请求NameNode 3.Nam ...
- HDFS中NameNode工作机制
引言 NameNode: 存储元数据 管理整个HDFS集群 DataNode: 存储数据的block SecondaryNameNode: 辅助HDFS完成一些事情 NameNode和Secondar ...
- Hadoop框架:NameNode工作机制详解
本文源码:GitHub·点这里 || GitEE·点这里 一.存储机制 1.基础描述 NameNode运行时元数据需要存放在内存中,同时在磁盘中备份元数据的fsImage,当元数据有更新或者添加元数据 ...
- Hadoop HDFS NameNode工作机制
Secondary namenode 首先,我们假设如果存储在Namenode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低.因此,元数据需要存放在内存中.但如果只存在内存中 ...
- NameNode 与 SecondaryNameNode 的工作机制
一.NameNode.Fsimage .Edits 和 SecondaryNameNode 概述 NameNode:在内存中储存 HDFS 文件的元数据信息(目录) 如果节点故障或断电,存在内存中的数 ...
- hdfs namenode/datanode工作机制
一. namenode工作机制 1. 客户端上传文件时,namenode先检查有没有同名的文件,如果有,则直接返回错误信息.如果没有,则根据要上传文件的大小以及block的大小,算出需要分成几个blo ...
随机推荐
- React Native初始化项目后执行react-native run-ios,构建失败
今天是肿么了......一上班创建React Native项目,react-native run-ios运行就报错,运行不了...呜呜...... 一开始以为自己react-native run-io ...
- k8s中ipvs和iptables选择
k8s 1.11.0在 centos7上不行 1.11.1之后就可以了
- [Http] Difference between POST and GET?
What is the difference between POST and GET HTTP requests? GET and POST are two different types of H ...
- 微信表情js代码
var list = [], face_list = { "[微笑]": 1, "[撇嘴]": 2, "[色]": 3, "[发呆 ...
- 这可能是你少有的能get到测试用例编写精髓的机会!
自动化测试用例的编写是实现项目自动化的核心,合理的用例设计是保证自动化效益和实用性的关键,也直接决定了自动化脚本是否具备可扩展和可维护性.由此,本篇文章主要为大家介绍了测试用例编写的规范和注意事项. ...
- Eslint常用命令
Eslint常用命令 自动修复(针对整个项目) npm run lint -- --fix 运行如上命令,eslint 会自动修复一些简单的错误. 全局安装 npm install -g eslint ...
- Autoit安装及启动
1.Autoit下载: 官网下载地址:https://www.autoitscript.com/site/autoit/downloads/ 提供百度网盘下载:https://pan.baidu.co ...
- windows ping命令
ping -a 192.168.xxx.xxx 解析计算机NetBios名 ping -n 数字 192.168.xxx.xxx 发送指定数量的echo数据包数,默认是四个 ping -l 192 ...
- Ruby Rails学习中:调试信息和 Rails 的三种环境,Users 资源,调试器,Gravatar 头像和侧边栏
注册 一.调试信息和 Rails 环境 现在咱们要实现的用户资料页面是我们这个应用中第一个真正意义上的动态页面.虽然视图的代码不会动态改变, 不过每个用户资料页面显示的内容却是从数据库中读取的.添加动 ...
- C Looooops
看了半天的同余 扩展欧几里得 练练手 C Looooops Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 27079 A ...