Sentinel 快速入门
Sentinel 简介
什么是 Sentinel?
『Sentinel』是阿里中间件团队开源的,面向分布式服务架构的轻量级高可用流量控制组件,主要以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度来帮助用户保护服务的稳定性。
Sentinel 具有以下特征:
丰富的应用场景:Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用应用等。
完备的实时监控:Sentinel 同时提供实时的监控功能。您可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况。
广泛的开源生态:Sentinel 提供开箱即用的与其它开源框架/库的整合模块,例如与 Spring Cloud、Dubbo、gRPC 的整合。您只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel。
完善的 SPI 扩展点:Sentinel 提供简单易用、完善的 SPI 扩展接口。您可以通过实现扩展接口来快速地定制逻辑。例如定制规则管理、适配动态数据源等。
Sentinel 的主要特性:

Sentinel 分为两个部分:
「核心库(Java 客户端)」不依赖任何框架/库,能够运行于所有 Java 运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持。
「控制台(Dashboard)」基于 Spring Boot 开发,打包后可以直接运行,不需要额外的 Tomcat 等应用容器。
Sentinel 基础概念
资源
『资源』是 Sentinel 的关键概念,只要通过 Sentinel API 定义的代码,就是资源,能够被 Sentinel 保护起来。
它可以是 Java 应用程序中的任何内容,例如,由应用程序提供的服务,或由应用程序调用的其它应用提供的服务,甚至可以是一段代码。
规则
围绕资源的实时状态设定的规则,可以包括「流量控制规则」、「熔断降级规则」以及「系统保护规则」。我们通过规则定义如何程序保护资源,所有规则可以动态实时调整。
Sentinel 入门 demo
使用 Sentinel 来进行资源保护,主要分为几个步骤:
定义资源
定义规则
检验规则是否生效
先把可能需要保护的资源定义好,之后再配置规则。也可以理解为,只要有了资源,我们就可以在任何时候灵活地定义各种流量控制规则。在编码的时候,只需要考虑这个代码是否需要保护,如果需要保护,就将之定义为一个资源。
这里我们按照官网上的示例给出 Sentinel 的一个简单demo
1. 引入 Sentinel 依赖
如果您的应用使用了 Maven,则在 pom.xml 文件中加入以下代码即可:
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-core</artifactId>
<version>1.6.3</version>
</dependency>
2. 定义资源
一般我们会将 Java 中的方法定义为资源,我们也可以更灵活地对资源进行定义。
在下面的例子中,我们定义了一个名为「HelloWorld」的资源,我们将System.out.println("hello world");这个语句作为被保护的逻辑,把它用Sentinel API SphU.entry("HelloWorld")和entry.exit()包围起来即可。参考代码如下:
public static void main(String[] args) {
// 配置规则.
initFlowRules();
while (true) {
// 1.5.0 版本开始可以直接利用 try-with-resources 特性
// 资源名可使用任意有业务语义的字符串,比如方法名、接口名或其它可唯一标识的字符串。
try (Entry entry = SphU.entry("HelloWorld")) {
// 被保护的逻辑
System.out.println("hello world");
} catch (BlockException ex) {
// 处理被流控的逻辑
System.out.println("blocked!");
}
}
}
3. 定义规则
接下来,我们通过流控规则来指定允许该资源通过的请求次数,例如下面的代码定义了我们资源「HelloWorld」每秒最多只能通过 20 个请求(即将 QPS 设为 20)。
private static void initFlowRules(){
List<FlowRule> rules = new ArrayList<>();
FlowRule rule = new FlowRule();
rule.setResource("HelloWorld");
rule.setGrade(RuleConstant.FLOW_GRADE_QPS);
// Set limit QPS to 20.
rule.setCount(20);
rules.add(rule);
FlowRuleManager.loadRules(rules);
}
4. 检查效果
Demo 运行之后,我们可以在日志~/logs/csp/${appName}-metrics.log.xxx里看到下面的输出:
|--timestamp-|------date time----|--resource-|p |block|s |e|rt
1529998904000|2018-06-26 15:41:44|hello world|20|0 |20|0|0
1529998905000|2018-06-26 15:41:45|hello world|20|5579 |20|0|728
1529998906000|2018-06-26 15:41:46|hello world|20|15698|20|0|0
1529998907000|2018-06-26 15:41:47|hello world|20|19262|20|0|0
1529998908000|2018-06-26 15:41:48|hello world|20|19502|20|0|0
1529998909000|2018-06-26 15:41:49|hello world|20|18386|20|0|0
其中p代表通过的请求,block代表被阻止的请求,s代表成功执行完成的请求个数,e代表用户自定义的异常,rt代表平均响应时长。
可以看到,这个程序每秒稳定输出 "hello world" 20 次,和规则中预先设定的阈值是一样的。
Sentinel 规则
Sentinel 的功能也就是其各种规则。其所有规则都可以在内存态中动态地查询及修改,修改之后立即生效。同时 Sentinel 也提供相关 API,供使用者来定制自己的规则策略。
Sentinel 支持以下几种规则:流量控制规则、熔断降级规则、系统保护规则、来源访问控制规则和热点参数规则。
流量控制规则 (FlowRule)
什么是流量控制
『流量控制』在网络传输中是一个常用的概念,它用于调整网络包的发送数据。然而,从系统稳定性角度考虑,在处理请求的速度上,也有非常多的讲究。任意时间到来的请求往往是随机不可控的,而系统单位时间的处理能力是有限的。我们需要根据系统的处理能力对流量进行控制。
Sentinel 流量控制原理
Sentinel 作为一个调配器,可以根据需要把随机的请求调整成合适的形状,如下图所示:
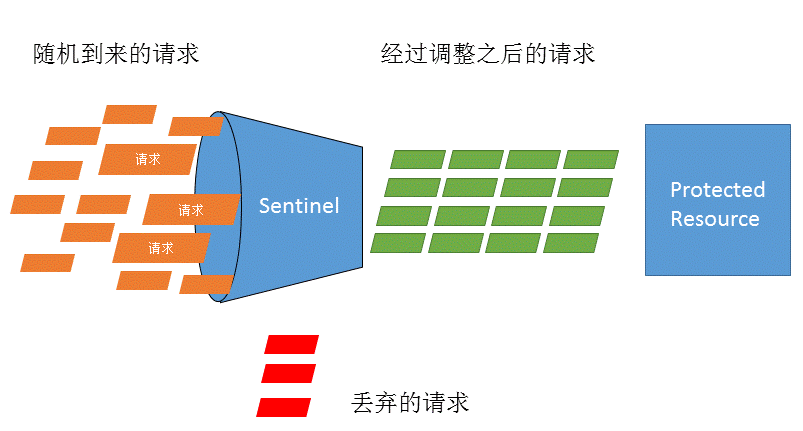
Sentinel 如何实现流量控制
我们可以通过以下的几个角度实现流量控制:
资源的调用关系:如资源的调用链路,资源和资源之间的关系
运行指标:例如 QPS、线程池、系统负载等;
控制的效果:例如直接限流、冷启动、排队等。
Sentinel 的「设计理念」是让编码人员自由选择控制的角度,并进行灵活组合,从而达到想要的效果。
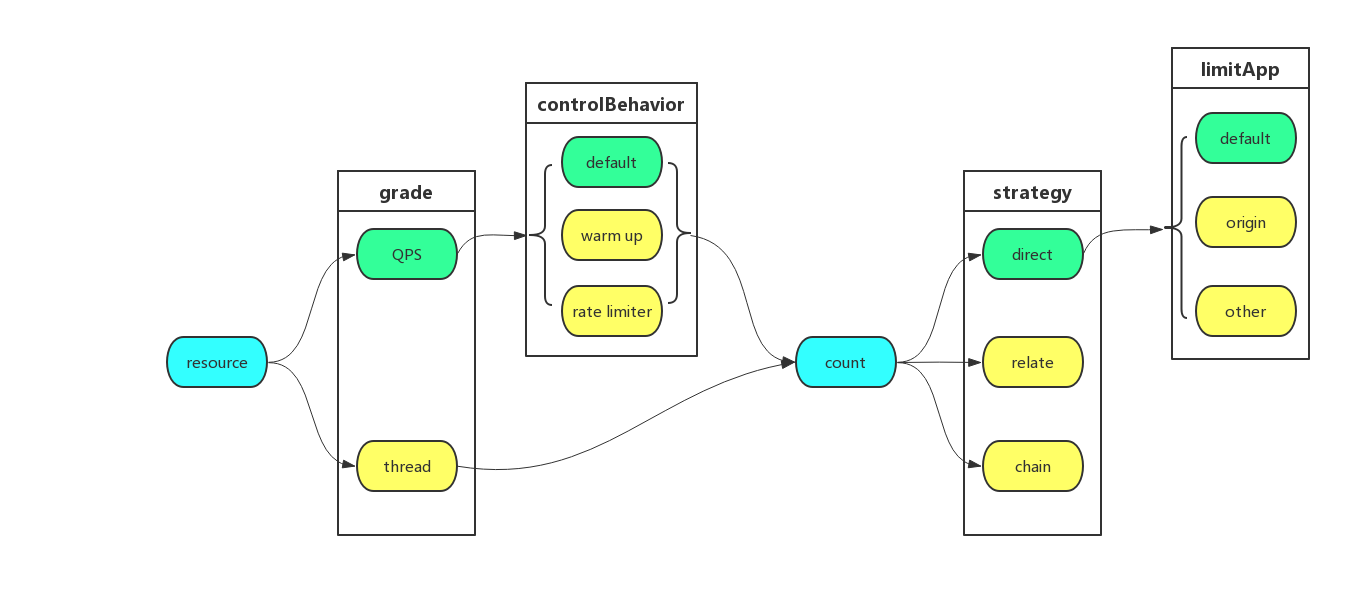
Sentinel 的流量控制规则由下面的关键属性组成:
| Field | 说明 | 默认值 |
|---|---|---|
| resource | 资源名,资源名是限流规则的作用对象 | |
| count | 限流阈值 | |
| grade | 限流阈值类型,QPS 或线程数模式 | QPS 模式 |
| limitApp | 流控针对的调用来源 | default,代表不区分调用来源 |
| strategy | 判断的根据是资源自身,还是根据其它关联资源 (refResource),还是根据链路入口 |
根据资源本身 |
| controlBehavior | 流控效果(直接拒绝 / 排队等待 / 慢启动模式) | 直接拒绝 |
限流的直接表现是在执行Entry nodeA = SphU.entry(resourceName)的时候抛出FlowException异常。FlowException是BlockException的子类,您可以捕捉BlockException来自定义被限流之后的处理逻辑。
同一个资源可以创建多条限流规则。FlowSlot 会对该资源的所有限流规则依次遍历,直到有规则触发限流或者所有规则遍历完毕。
基于QPS/并发数的流量控制
流量控制主要有两种统计类型,一种是统计并发线程数,另外一种则是统计 QPS。类型由 FlowRule 的 grade 字段来定义。其中,0 代表根据并发数量来限流,1 代表根据 QPS 来进行流量控制。其中线程数、QPS 值,都是由 StatisticSlot 实时统计获取的。
并发线程数流量控制
并发线程数限流用于保护业务线程数不被耗尽。例如,当应用所依赖的下游应用由于某种原因导致服务不稳定、响应延迟增加,对于调用者来说,意味着吞吐量下降和更多的线程数占用,极端情况下甚至导致线程池耗尽。为应对太多线程占用的情况,业内有使用隔离的方案,比如「Hystrix」通过不同业务逻辑使用不同线程池来隔离业务自身之间的资源争抢(线程池隔离)。这种隔离方案虽然隔离性比较好,但是代价就是线程数目太多,线程上下文切换的 overhead 比较大,特别是对低延时的调用有比较大的影响。
Sentinel 并发线程数限流不负责创建和管理线程池,而是简单统计当前请求上下文的线程数目,如果超出阈值,新的请求会被立即拒绝,效果类似于信号量隔离。例子参见:ThreadDemo
QPS流量控制
当 QPS 超过某个阈值的时候,则采取措施进行流量控制。流量控制的手段包括以下几种:「直接拒绝」、「Warm Up」、「匀速排队」。对应FlowRule中的controlBehavior字段。
1. 直接拒绝
「直接拒绝RuleConstant.CONTROL_BEHAVIOR_DEFAULT」是默认的流量控制方式,当QPS超过任意规则的阈值后,新的请求就会被立即拒绝,拒绝方式为抛出FlowException。具体的例子参见 FlowQpsDemo。
这种方式适用于对系统处理能力确切已知的情况下,比如通过压测确定了系统的准确水位时。
2. Warm Up
「Warm UpRuleConstant.CONTROL_BEHAVIOR_WARM_UP」,即预热/冷启动方式。
当系统长期处于低水位的情况下,当流量突然增加时,直接把系统拉升到高水位可能瞬间把系统压垮。通过"冷启动",让通过的流量缓慢增加,在一定时间内逐渐增加到阈值上限(即给定的count),给冷系统一个预热的时间,避免冷系统被压垮。详细文档可以参考 流量控制 - Warm Up 文档,具体的例子可以参见 WarmUpFlowDemo。
下面我们构建一个使用冷启动规则的流控规则:
FlowRule rule = new FlowRule();
rule.setResource(resourceName);
rule.setCount(480);
rule.setGrade(RuleConstant.GRADE_QPS);
rule.setLimitApp("default");
rule.setControlBehavior(RuleConstant.CONTROL_BEHAVIOR_WARM_UP); // 流控效果:冷启动模式
rule.setWarmUpPeriodSec(10); // 预热时长
其中,CONTROL_BEHAVIOR_WARM_UP表示启用冷启动模式,warmUpPeriodSec代表期待系统进入稳定状态的时间(即预热时长)。
下图为将 QPS 设为480的冷启动示例图,可以看到在冷启动后系统是逐渐将 QPS 增加到480的:
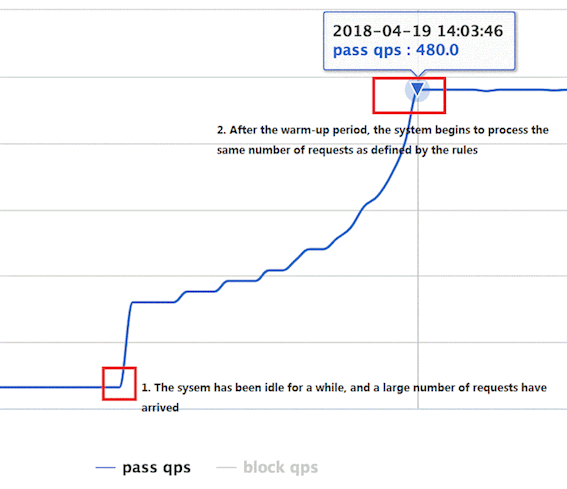
3. 匀速排队
「匀速排队RuleConstant.CONTROL_BEHAVIOR_RATE_LIMITER」会严格控制请求通过的间隔时间,也即是让请求以均匀的速度通过,对应的是漏桶算法。详细文档可以参考流量控制 - 匀速器模式,具体的例子可以参见 PaceFlowDemo。
漏桶算法
Leaky Bucket 对应 流量整形 中的匀速器。它的中心思想是,以固定的间隔时间让请求通过。当请求到来的时候,如果当前请求距离上个通过的请求通过的时间间隔不小于预设值,则让当前请求通过;否则,计算当前请求的预期通过时间,如果该请求的预期通过时间小于规则预设的 timeout 时间,则该请求会等待直到预设时间到来通过(排队等待处理);若预期的通过时间超出最大排队时长,则直接拒接这个请求。
下面我们构建一个使用匀速排队规则的流控规则:
rule.setGrade(RuleConstant.GRADE_QPS);
rule.setControlBehavior(RuleConstant.CONTROL_BEHAVIOR_RATE_LIMITER); // 流控效果:匀速排队模式
rule.setCount(10);
rule.setMaxQueueingTimeMs(20 * 1000); // 最长排队等待时间:20s
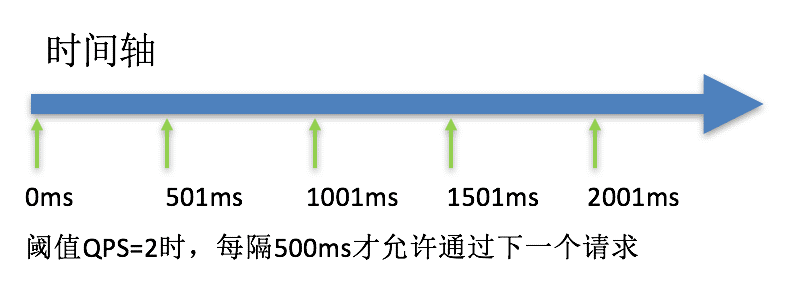
count 设为 10 ,代表一秒匀速的通过 10 个请求,也就是每个请求平均间隔恒定为 1000 / 10 = 100 ms,每一个请求的最长等待时间maxQueueingTimeMs为 20 * 1000ms = 20s。
下图为 QPS 为2时,匀速排队规则的示例图:
和之前的两种规则相比,「匀速排队」对于超过当前阈值的请求不会立刻丢弃,而是允许其保留maxQueueingTimeMs的最长等待时间。它主要用于处理间隔性突发的流量,例如消息队列。想象一下这样的场景,在某一秒有大量的请求到来,而接下来的几秒则处于空闲状态,我们希望系统能够在接下来的空闲期间逐渐处理这些请求,而不是在第一秒直接拒绝多余的请求。
基于调用关系的流量控制
「调用关系」包括调用方、被调用方;一个方法又可能会调用其它方法,形成一个调用链路的层次关系,这里主要基于 strategy 和 limitApp 两个属性完成基于调用关系的限流。
根据调用方限流
这种流控规则要求strategy 选择 DIRECT(strategy 默认值就是 DIRECT),以及根据限流规则中的 limitApp 字段根据调用方在不同的场景中进行流量控制
流控规则中的 limitApp 字段用于根据调用来源进行流量控制。该字段的值有以下三种选项,分别对应不同的场景:
default
表示「不区分调用者」,来自任何调用者的请求都将进行限流统计。如果这个资源名的调用总和超过了这条规则定义的阈值,则触发限流。
{some_origin_name}
表示「针对特定的调用者」,只有来自这个调用者的请求才会进行流量控制。
例如
NodeA配置了一条针对调用者caller1的规则,那么当且仅当来自caller1对NodeA的请求才会触发流量控制。other
表示「针对除
{some_origin_name}以外的其余调用方」的流量进行流量控制。例如,资源
NodeA配置了一条针对调用者caller1的限流规则,同时又配置了一条调用者为other的规则,那么任意来自非caller1对NodeA的调用,都不能超过other这条规则定义的阈值。
使用和调用来源相关规则时,「调用方信息」通过 ContextUtil.enter(resourceName, origin) 方法中的 origin 参数传入。
同一个资源名可以配置多条规则,规则的生效顺序为:{some_origin_name} > other > default
根据调用链路入口限流:链路限流
NodeSelectorSlot 中记录了资源之间的调用链路,这些资源通过调用关系,相互之间构成一棵调用树。这棵树的根节点是一个名字为「machine-root」的虚拟节点,调用链的入口都是这个虚节点的子节点。
一棵典型的调用树如下图所示:
machine-root
/ \
/ \
Entrance1 Entrance2
/ \
/ \
DefaultNode(nodeA) DefaultNode(nodeA)
上图中来自入口 Entrance1 和 Entrance2 的请求都调用到了资源 NodeA,Sentinel 允许根据特定入口的统计信息对资源限流。
比如我们可以设置 FlowRule.strategy 为 RuleConstant.CHAIN,同时设置 FlowRule.ref_identity 为 Entrance1 来表示只有从入口「Entrance1」的调用才会记录到 NodeA 的限流统计当中,而不关心经 Entrance2 到来的调用。
调用链的入口(上下文)是通过 API 方法 ContextUtil.enter(contextName) 定义的,其中 contextName 即对应调用链路入口名称。详情可以参考 ContextUtil 文档。
具有关系的资源流量控制:关联流量控制
当两个资源之间具有「资源争抢」或者「依赖关系」的时候,这两个资源便具有了关联。
比如对数据库同一个字段的读操作和写操作存在争抢,读的速度过高会影响写得速度,写的速度过高会影响读的速度。如果放任读写操作争抢资源,则争抢本身带来的开销会降低整体的吞吐量。可使用关联限流来避免具有关联关系的资源之间过度的争抢。
举例来说,「read_db」和「write_db」这两个资源分别代表数据库读写,我们可以给「read_db」设置限流规则来达到写优先的目的:设置 FlowRule.strategy 为 RuleConstant.RELATE 同时设置 FlowRule.ref_identity 为 write_db。这样当写库操作过于频繁时,读数据的请求会被限流。
可以注意到,上面根据 『strategy』属性的不同对流控采取不同的策略,下面我们对「strategy」属性进行以下概括:
strategy 属性
流控规则中的srategy字段用于根据调用关系进行流量控制。该字段的值同样有以下三种选项,分别对应不同的场景:
STRATEGY_DIRECT(默认属性)
根据「调用方」进行限流。
ContextUtil.enter(resourceName, origin)方法中的origin参数标明了调用方的身份。如果
strategy选择了DIRECT ,则还需要根据限流规则中的limitApp字段根据调用方在不同的场景中进行流量控制,包括有:「所有调用方default」、「特定调用方origin」、「除特定调用方origin之外的调用方」。STRATEGY_RELATE
根据「关联流量」限流。可使用关联限流来避免具有关联关系的资源之间过度的争抢。
例如相关联的「a」操作和「b」操作,在「a」操作过于频繁时对「b」操作进行限流以避免两种操作之间的资源过度争抢,以保证「b」操作的优先执行。
STRATEGY_CHAIN
根据「调用链路入口」限流。限定 Sentinel 允许根据某个特定入口的统计信息对资源进行限流。
最后放一张 Sentinel 的具体 FlowRule 表示图:
熔断降级规则 (DegradeRule)
为什么要熔断降级
除了流量控制以外,降低调用链路中的不稳定资源也是 Sentinel 的使命之一。由于调用关系的复杂性,如果调用链路中的某个资源出现了不稳定,最终会导致请求发生堆积。

Sentinel 熔断降级原理
对于熔断降级,之前还有一个广泛使用的框架「Hystrix」。Sentinel 和 Hystrix 的原则是一致的: 当检测到调用链路中某个资源出现不稳定的表现,例如请求响应时间长或异常比例升高的时候,则对这个不稳定资源的调用进行限制,让请求快速失败,避免影响到其它的资源而导致级联故障。
Sentinel 如何实现熔断降级
在限制的手段上,Sentinel 和 Hystrix 采取了完全不一样的方法。
Hystrix 通过 线程池隔离 的方式,来对依赖(在 Sentinel 的概念中对应 资源)进行了隔离。这样做的「好处」是资源和资源之间做到了最彻底的隔离。「缺点」是除了增加了线程切换的成本(过多的线程池导致线程数目过多),还需要预先给各个资源做线程池大小的分配。
Sentinel 对这个问题采取了两种手段:
通过并发线程数进行限制
和资源池隔离的方法不同,Sentinel 通过限制资源并发线程的数量,来减少不稳定资源对其它资源的影响。这样不但没有线程切换的损耗,也不需要预先分配线程池的大小。
当某个资源出现不稳定的情况下,例如响应时间变长,对资源的直接影响就是会造成线程数的逐步堆积。当线程数在特定资源上堆积到一定的数量之后,对该资源的新请求就会被拒绝。堆积的线程完成任务后才开始继续接收请求。
通过响应时间对资源进行降级
除了对并发线程数进行控制以外,Sentinel 还可以通过响应时间来快速降级不稳定的资源。
当依赖的资源出现响应时间过长后,所有对该资源的访问都会被直接拒绝,直到过了指定的时间窗口之后才重新恢复。
Sentinel 的熔断降级规则包含下面几个重要的属性:
| Field | 说明 | 默认值 |
|---|---|---|
| resource | 资源名,即限流规则的作用对象 | |
| count | 阈值 | |
| grade | 降级模式,根据 RT 降级还是根据异常比例降级 | RT |
| timeWindow | 降级的时间,单位为 s |
当资源被降级后,在接下来的降级时间窗口之内,对该资源的调用都自动熔断(默认行为是抛出 DegradeException)。
类似于流量控制规则,同一个资源也可以同时有多个降级规则。
降级判断标准
Sentinel 通过设置规则的grade属性,用以下几种方式来衡量资源是否处于稳定的状态:
1. 平均响应时间 DEGRADE_GRADE_RT
当 1s 内持续进入 5 个请求,且对应时刻的平均响应时间rt(秒级)均超过阈值(count,以 ms 为单位),那么在接下的时间窗口(DegradeRule 中的 timeWindow,以 s 为单位)之内,对这个方法的调用都会自动地熔断(抛出 DegradeException)。
下面代码即是将平均响应时间设为 10ms 的一个示例代码:
rule.setResource(KEY);
// set threshold rt, 10 ms
rule.setCount(10);
rule.setGrade(RuleConstant.DEGRADE_GRADE_RT); // 设置降级模式为 rt
rule.setTimeWindow(10);
注意 Sentinel 默认统计的 RT 上限是 4900 ms,超出此阈值的都会算作 4900 ms,若需要变更此上限可以通过启动配置项 -Dcsp.sentinel.statistic.max.rt=xxx 来配置。
2. 异常比例 DEGRADE_GRADE_EXCEPTION_RATIO
当资源的每秒请求量 >= 5,并且每秒异常总数占通过量的比值超过阈值(DegradeRule 中的 count)之后,资源进入降级状态,即在接下的时间窗口(DegradeRule 中的 timeWindow,以 s 为单位)之内,对这个方法的调用都会自动地返回。
异常比率的阈值范围是 [0.0, 1.0],代表 0% - 100%。
3. 异常数 DEGRADE_GRADE_EXCEPTION_COUNT
当资源近 1 分钟的异常数目超过阈值之后会进行熔断。
由于统计时间窗口是分钟级别的,若 timeWindow 小于 60s,则结束熔断状态后仍可能再进入熔断状态。
需要特别注意的是,异常数降级仅针对业务异常,对 Sentinel 限流降级本身的异常(BlockException)不生效。为了统计异常比例或异常数,需要通过 Tracer.trace(ex) 记录业务异常。示例:
Entry entry = null;
try {
entry = SphU.entry(key, EntryType.IN, key);
// Write your biz code here.
// <<BIZ CODE>>
} catch (Throwable t) {
if (!BlockException.isBlockException(t)) {
Tracer.trace(t);
}
} finally {
if (entry != null) {
entry.exit();
}
}
如果我们使用 Sentinel 的「开源整合模块」时,如 Sentinel Dubbo Adapter, Sentinel Web Servlet Filter 或 @SentinelResource 注解,它们能够自动统计业务异常,无需手动调用Tracer.trace(ex)。
熔断降级示例 demo
在 RT Degrade demo 中,我们将 rt 的阈值设为 10ms,时间窗口长度设为 10s:
private static void initDegradeRule() {
List<DegradeRule> rules = new ArrayList<DegradeRule>();
DegradeRule rule = new DegradeRule();
rule.setResource(KEY);
// set threshold rt, 10 ms
rule.setCount(10); // rt 阈值
rule.setGrade(RuleConstant.DEGRADE_GRADE_RT);
rule.setTimeWindow(10); // 时间窗口长度
rules.add(rule);
DegradeRuleManager.loadRules(rules);
}
模拟每个请求的实际 rt 为 600ms:
Entry entry = null;
try {
TimeUnit.MILLISECONDS.sleep(5);
entry = SphU.entry(KEY);
// token acquired
pass.incrementAndGet();
// sleep 600 ms, as rt
TimeUnit.MILLISECONDS.sleep(600);
} catch (Exception e) {
block.incrementAndGet();
} finally {
total.incrementAndGet();
if (entry != null) {
entry.exit();
}
}
运行 Demo,将可以看到:
1529399827825,total:0, pass:0, block:0
1529399828825,total:4263, pass:100, block:4164 // 第一秒的平均RT都还比较小
1529399829825,total:19179, pass:4, block:19176
1529399830824,total:19806, pass:0, block:19806 // 开始被降级
1529399831825,total:19198, pass:0, block:19198
1529399832824,total:19481, pass:0, block:19481
1529399833826,total:19241, pass:0, block:19241
1529399834826,total:17276, pass:0, block:17276
1529399835826,total:18722, pass:0, block:18722
1529399836826,total:19490, pass:0, block:19492
1529399837828,total:19355, pass:0, block:19355
1529399838827,total:11388, pass:0, block:11388
1529399839829,total:14494, pass:104, block:14390 // 10秒之后恢复,然而又迅速地被降级
1529399840854,total:18505, pass:0, block:18505
1529399841854,total:19673, pass:0, block:19676
系统保护规则 (SystemRule)
为什么要进行系统保护
当系统负载较高的时候,如果还持续让请求进入,可能会导致系统崩溃,无法响应。
在集群环境下,网络负载均衡会把本应这台机器承载的流量转发到其它的机器上去。如果这个时候其它的机器也处在一个边缘状态的时候,这个增加的流量就会导致这台机器也崩溃,最后导致整个集群不可用。
这样我们便知道了系统自适应限流的目的:
- 保证系统不被拖垮
- 在系统稳定的前提下,保持系统的吞吐量
我们希望让系统的入口流量和系统的负载达到一个平衡,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。
Sentinel 如何实现系统保护
长期以来,系统自适应保护的思路是根据硬指标,即系统的负载 (load1) 来做系统过载保护。当系统负载高于某个阈值,就禁止或者减少流量的进入;当 load 开始好转,则恢复流量的进入。
这个传统思路给我们带来了不可避免的两个问题:
- load 是一个「果」,如果根据 load 的情况来调节流量的通过率,那么就始终有延迟性。也就意味着通过率的任何调整,都会过一段时间才能看到效果。当前通过率是使 load 恶化的一个动作,那么也至少要过 1 秒之后才能观测到;同理,如果当前通过率调整是让 load 好转的一个动作,也需要 1 秒之后才能继续调整,这样就浪费了系统的处理能力。所以我们看到的曲线,总是会有抖动。
- 恢复慢。想象一下这样的一个场景(真实),出现了这样一个问题,下游应用不可靠,导致应用 RT 很高,从而 load 到了一个很高的点。过了一段时间之后下游应用恢复了,应用 RT 也相应减少。这个时候,其实应该大幅度增大流量的通过率;但是由于这个时候 load 仍然很高,通过率的恢复仍然不高。
如果我们还是按照固有的思维,超过特定的 load 就禁止流量进入,系统 load 恢复就放开流量,这样做的结果是无论我们怎么调参数,调比例,都是按照「果」来调节「因」,都无法取得良好的效果。
『Sentinel 』在系统自适应保护的做法是,用 load1 作为启动控制流量的值,而允许通过的流量由处理请求的能力,即请求的响应时间以及当前系统正在处理的请求速率来决定。
我们需要额外注意,这种系统自适应算法对于低 load 的请求,它的效果是一个「兜底」的角色。对于不是应用本身造成的 load 高的情况(如其它进程导致的不稳定的情况),效果不明显。
Sentinel 的系统保护规则包含下面几个重要的属性:
| Field | 说明 | 默认值 |
|---|---|---|
| highestSystemLoad | 最大的 load1,参考值(仅对 Linux/Unix-like 机器生效) |
-1 (不生效) |
| avgRt | 所有入口流量的平均响应时间 | -1 (不生效) |
| maxThread | 入口流量的最大并发数 | -1 (不生效) |
| qps | 所有入口资源的 QPS | -1 (不生效) |
上述四个属性是 Sentinel 对于是否需要启动系统保护的四种触发标准,一个系统保护规则可以同时设置多种触发条件。系统防护启动之后 Sentinel 便会自动地对系统进行自适应防护。
系统保护原理
对于 Sentinel 的系统防护规则,四个属性都是是否启动的触发标准,因此我们需要充分理解四种属性的关联,才能够灵活使用 Sentinel 的系统自适应保护。
看下面这样的一张图:

我们把系统处理请求的过程想象为一个水管,到来的请求是往这个水管灌水:当系统处理顺畅的时候,请求不需要排队,直接从水管中穿过,这个请求的RT是最短的;反之,当请求堆积的时候,那么处理请求的时间则会变为:排队时间 + 最短处理时间。
- 推论一: 如果我们能够保证水管里的水量,能够让水顺畅的流动,则不会增加排队的请求;也就是说,这个时候的系统负载不会进一步恶化。
我们用「T」来表示入口流量的最大并发数(水管内部的水量),用「RT」来表示请求的处理时间,用「P」来表示进来的请求数,那么一个请求从进入水管道到从水管出来,这个水管会存在 P * RT 个请求。换一句话来说,当 T ≈ QPS * Avg(RT) 的时候,我们可以认为系统的处理能力和允许进入的请求个数达到了平衡,系统的负载不会进一步恶化。
接下来的问题是,水管的水位是可以达到了一个平衡点,但是这个平衡点只能保证水管的水位不再继续增高,但是还面临一个问题,就是在达到平衡点之前,这个水管里已经堆积了多少水。如果之前水管的水已经在一个量级了,那么这个时候系统允许通过的水量可能只能缓慢通过,RT 会大,之前堆积在水管里的水会滞留;反之,如果之前的水管水位偏低,那么又会浪费了系统的处理能力。
- 推论二: 当保持入口的流量是水管出口流量的最大值的时候,可以最大利用水管的处理能力。
上面的两个推论实际上就是 Sentinel 帮助我们做的事,可以看到其实只出现了三个属性,以 maxThread ≈ qps * avgRt 的联系出现。然而,对于 Sentinel,我们还需要用一个系统负载的值(load1)来激发这套机制启动,也就是第四个属性 highestSystemLod,我们需要注意这个属性仅在 Unix-like 系统上有效。
这里给出一个配置系统保护规则的示例代码:
private static void initSystemRule() {
List<SystemRule> rules = new ArrayList<SystemRule>();
SystemRule rule = new SystemRule();
// max load is 3
rule.setHighestSystemLoad(3.0);
// max cpu usage is 60%
rule.setHighestCpuUsage(0.6);
// max avg rt of all request is 10 ms
rule.setAvgRt(10);
// max total qps is 20
rule.setQps(20);
// max parallel working thread is 10
rule.setMaxThread(10);
rules.add(rule);
SystemRuleManager.loadRules(Collections.singletonList(rule));
}
黑白名单规则 (AuthorityRule)
很多时候,我们需要根据调用方来限制资源是否通过,这时候可以使用 Sentinel 的黑白名单控制的功能。
「黑白名单」根据资源的请求来源(origin)限制资源是否通过,若配置白名单则只有请求来源位于白名单内时才可通过;若配置黑名单则请求来源位于黑名单时不通过,其余的请求通过。之前我们还接触了「流量控制规则」中类似的根据调用方限流,不过流控规则仅是作出限流,而黑白名单规则是直接限定资源能否通过,
授权规则,即黑白名单规则(AuthorityRule)非常简单,仅有以下配置项:
resource:资源名,即限流规则的作用对象limitApp:对应的黑名单/白名单,不同 origin 用,分隔,如appA,appBstrategy:限制模式,AUTHORITY_WHITE为白名单模式,AUTHORITY_BLACK为黑名单模式,默认为白名单模式
黑白名单规则示例
比如我们希望控制对资源 test 的访问设置白名单,只有来源为 appA 和 appB 的请求才可通过,则可以配置如下白名单规则:
AuthorityRule rule = new AuthorityRule();
rule.setResource("test");
rule.setStrategy(RuleConstant.AUTHORITY_WHITE);
rule.setLimitApp("appA,appB");
AuthorityRuleManager.loadRules(Collections.singletonList(rule));
和流控规则中一样,使用黑白名单规则时,「调用方信息」通过 ContextUtil.enter(resourceName, origin) 方法中的 origin 参数传入。
需要特别注意的是,如果对一个「AuthorityRuleManager」同时配置了多个黑白名单规则,只有第一个规则会生效。
详细示例请参考 AuthorityDemo.
热点规则 (ParamFlowRule)
什么是热点限流
何为热点?热点即经常访问的数据。很多时候我们希望统计某个热点数据中访问频次最高的 Top K 数据,并对其访问进行限制。比如:
商品 ID 为参数,统计一段时间内最常购买的商品 ID 并进行限制
用户 ID 为参数,针对一段时间内频繁访问的用户 ID 进行限制
热点参数限流会统计传入参数中的热点参数,并根据配置的限流阈值与模式,对包含热点参数的资源调用进行限流。热点参数限流可以看做是一种特殊的流量控制,仅对包含热点参数的资源调用生效。
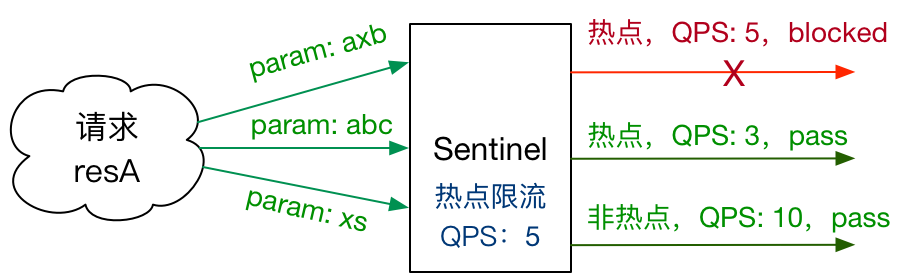
Sentinel 如何实现热点限流
Sentinel 利用「LRU 策略」统计最近最常访问的热点参数,结合「令牌桶算法」来进行参数级别的流控。
热点参数规则配置
热点参数规则(ParamFlowRule)类似于流量控制规则(FlowRule):
| 属性 | 说明 | 默认值 |
|---|---|---|
| resource | 资源名,必填 | |
| count | 限流阈值,必填 | |
| grade | 限流模式 | QPS 模式 |
| durationInSec | 统计窗口时间长度(单位为秒),1.6.0 版本开始支持 | 1s |
| controlBehavior | 流控效果(支持快速失败和匀速排队模式),1.6.0 版本开始支持 | 快速失败 |
| maxQueueingTimeMs | 最大排队等待时长(仅在匀速排队模式生效),1.6.0 版本开始支持 | 0ms |
| paramIdx | 热点参数的索引,必填,对应 SphU.entry(xxx, args)中的参数索引位置 |
|
| paramFlowItemList | 参数例外项,可以针对指定的参数值单独设置限流阈值,不受前面 count 阈值的限制。仅支持基本类型和字符串类型 |
|
| clusterMode | 是否是集群参数流控规则 | false |
| clusterConfig | 集群流控相关配置 |
我们可以通过 ParamFlowRuleManager 的 loadRules 方法更新热点参数规则,下面是一个示例:
ParamFlowRule rule = new ParamFlowRule(resourceName)
.setParamIdx(0)
.setCount(5);
// 针对 int 类型的参数 PARAM_B,单独设置限流 QPS 阈值为 10,而不是全局的阈值 5.
ParamFlowItem item = new ParamFlowItem().setObject(String.valueOf(PARAM_B))
.setClassType(int.class.getName())
.setCount(10);
rule.setParamFlowItemList(Collections.singletonList(item));
ParamFlowRuleManager.loadRules(Collections.singletonList(rule));
示例
示例可参见 sentinel-demo-parameter-flow-control。
Sentinel 快速入门的更多相关文章
- 替代 Hystrix,Spring Cloud Alibaba Sentinel 快速入门
提起 Spring Cloud 的限流降级组件,一般首先想到的是 Netflix 的 Hystrix. 不过就在2018年底,Netflix 宣布不再积极开发 Hystrix,该项目将处于维护模式.官 ...
- sentinel快速入门
转载:https://blog.csdn.net/noaman_wgs/article/details/103328793 https://github.com/alibaba/Sentinel/wi ...
- 二:Redis快速入门及应用
Redis的使用难吗?不难,Redis用好容易吗?不容易.Redis的使用虽然不难,但与业务结合的应用场景特别多.特别紧,用好并不容易.我们希望通过一篇文章及Demo,即可轻松.快速入门并学会应用. ...
- Redis快速入门及应用
Redis的使用难吗?不难,Redis用好容易吗?不容易.Redis的使用虽然不难,但与业务结合的应用场景特别多.特别紧,用好并不容易.我们希望通过一篇文章及Demo,即可轻松.快速入门并学会应用.一 ...
- 中小型研发团队架构实践五:Redis快速入门及应用
Redis的使用难吗?不难,Redis用好容易吗?不容易.Redis的使用虽然不难,但与业务结合的应用场景特别多.特别紧,用好并不容易.我们希望通过一篇文章及Demo,即可轻松.快速入门并学会应用. ...
- 中小型研发团队架构实践:Redis快速入门及应用
Redis的使用难吗?不难,Redis用好容易吗?不容易.Redis的使用虽然不难,但与业务结合的应用场景特别多.特别紧,用好并不容易.我们希望通过一篇文章及Demo,即可轻松.快速入门并学会应用. ...
- Web Api 入门实战 (快速入门+工具使用+不依赖IIS)
平台之大势何人能挡? 带着你的Net飞奔吧!:http://www.cnblogs.com/dunitian/p/4822808.html 屁话我也就不多说了,什么简介的也省了,直接简单概括+demo ...
- SignalR快速入门 ~ 仿QQ即时聊天,消息推送,单聊,群聊,多群公聊(基础=》提升)
SignalR快速入门 ~ 仿QQ即时聊天,消息推送,单聊,群聊,多群公聊(基础=>提升,5个Demo贯彻全篇,感兴趣的玩才是真的学) 官方demo:http://www.asp.net/si ...
- 前端开发小白必学技能—非关系数据库又像关系数据库的MongoDB快速入门命令(2)
今天给大家道个歉,没有及时更新MongoDB快速入门的下篇,最近有点小忙,在此向博友们致歉.下面我将简单地说一下mongdb的一些基本命令以及我们日常开发过程中的一些问题.mongodb可以为我们提供 ...
随机推荐
- Redis系列之-—内存淘汰策略(笔记)
一.Redis ---获取设置的Redis能使用的最大内存大小 []> config get maxmemory ) "maxmemory" ) " --获取当前内 ...
- [Python]pip install offline 如何离线pip安装包
痛点:目标机器无法连接公网,但是能使用rz.sz传输文件 思路:在能上网的机器是使用pip下载相关依赖包,然后传输至目标机器,进行安装 0. Install pip: http://pip-cn.re ...
- 3.Git 命令行操作
1.Git 命令行操作(本地库操作): 1.1. 创建本地库(本地库初始化): 第一步:首先在D盘建了个名为git空文件夹,命令行中cd到这个文件夹: 第二步:通过git init命令把这个目录变成G ...
- java.lang.AbstractMethodError: org.powermock.api.mockito.internal.mockmaker.PowerMockMaker.isTypeMockable
[转]https://stackoverflow.com/questions/53539930/java-lang-abstractmethoderror-org-powermock-api-mock ...
- webpack中如何编写一个plugin
loader和plugin有什么区别呢?什么是loader,什么是plugin. 当我们在源代码里面去引入一个新的js文件或者一个其他格式的文件的时候,这个时候,我们可以借助loader去帮我们处理引 ...
- CentOS阿里仓库停止openstack mitaka源服务报错------“No package centos-release-openstack-mitaka available.”
之前学习了一个月的openstack的mitaka版本,部署完后放置一段时间,最近准备正式部署突然发现“No package centos-release-openstack-mitaka avail ...
- linux网络编程之posix线程(一)
今天继续学习posix IPC相关的东东,消息队列和共享内存已经学习过,接下来学习线程相关的知识,下面开始: [注意]:创建失败这时会返回错误码,而通常函数创建失败都会返回-1,然后错误码会保存在er ...
- 七、Linq To XML:XElement、XDocument
一.概述 LINQ to XMLLINQ to XML 是一种启用了 LINQ 的内存 XML 编程接口,使用它,可以在 .NET Framework.NET Framework 编程语言中处理 XM ...
- 遇见zTree和chrome的俩坑
今天后台系统发现一bug,就是前几天用zTree做的树形结构,今下午突然不好使了,然后就查问题.我自己电脑装的是chrome浏览器,后台debug一看传的json数据,没毛病,想当然的断定不是数据的问 ...
- 【NOI2019集训题2】 序列 后缀树+splay+dfs序
题目大意:给你一个长度为$n$的序列$a_i$,还有一个数字$m$,有$q$次询问 每次给出一个$d$和$k$,问你对所有的$a_i$都在模$m$意义下加了$d$后,第$k$小的后缀的起点编号. 数据 ...