教你阅读 Cpython 的源码(一)
目录
第一部分-介绍 Cpython
源代码中有什么?
如何编译 Cpython 代码
编译器能做什么?
为什么 Cpython 是用 C 语言而是 Python 编写的?
Python 语言的规范
Cpython 中的内存管理机制
结论
第二部分-Python 解释器进程
建立运行时配置
读取文件/输入
词法解析和句法解析
抽象语法树
结论
第三部分- Cpython 的编译器和执行循环
编译
执行
结论
第四部分-Cpython 中的对象
基础对象类型
Bool 和 Long Integer 类型
回顾 Generator 类型
结论
第五部分 Cpython 标准库
Python 模块
Pyhton 和 C 模块
Cpython 回归测试套件
安装用户自定 C 义版本
最后-Cpython 源代码:结论
···-------------------------正文开始----------------------------···
第一部分 介绍 Cpython
前言
在使用 Python 的过程中你是否有这些疑惑,使用字典查找内容,为什么比遍历一个列表要快得多?生成器如何在每次生成值时记住变量的状态?为什么使用 Python 时我们不用像其他语言那样分配内存?事实证明,CPython,是最流行的 Python 版本,运行时是用人类可读的 C 和 Python 代码编写的。
这篇文主要就是围绕着 Cpython 展开的,文章涵盖 CPython 内部原理背后的所有概念、它们的工作原理以及可视化的解释。
你将会学到的内容有:
- 学会阅读源码
- 从源代码编译 CPython
- 理解列表、字典和生成器等概念以及内部工作原理
- 运行测试套件
- 修改或升级 CPython 库的组件,或许在未来可以贡献 新的 Python 版本
这篇文章很长但是很有用,如果你决定要学习 Cpython,那么希望你能看下去,你会发现这是一份不错的学习资料。
这篇文章总共分为 5 部分,你可以根据自己的时候合理的安排阅读时间。每一部分都要花一定的时间,通过自己去研究这里面的一些案例,你会感到一种成就感,因为你掌握了 Python 的核心概念,这使得你成为一名更好的 Python 程序员。
我们平时说的 Python,其实大多都是指的 Cpython,CPython 是众多 Python 中的其中一种,除此之外还有 Pypy,Jpython 等。CPython 同样的作为官方使用的 Python 版本,以及网上的众多案例。所以,这里我们主要说的是 Cpython。
注意:本文是针对 CPython 源代码的 3.8.0b3 版编写的。
源代码中有什么?
CPython 源代码分发包含各种工具,库和组件。我们将在本文中探讨这些内容。
首先,我们将重点关注编译器。先从 git 上下载 Cpython 源代码.
git clone https://github.com/python/cpython
cd cpython
git checkout v3.8.0b3 #切换我们需要的分支
注意:如果你没有 Git,可以直接从 GitHub 网站下载 ZIP 文件中的源代码。
解压我们下载的文件,其目录结构如下:
cpython/
│
├── Doc ← 源代码文档说明
├── Grammar ← 计算机可读的语言定义
├── Include ← C 语言头文件(头文件中一般放一些重复使用的代码)
├── Lib ← Python 写的标准库文件
├── Mac ← Mac 支持的文件
├── Misc ← 杂项
├── Modules ← C 写的标准库文件
├── Objects ← 核心类型和对象模块
├── Parser ← Python 解析器源码
├── PC ← Windows 编译支持的文件
├── PCbuild ← 老版本的 Windows 系统 编译支持的文件
├── Programs ← Python 可执行文件和其他二进制文件的源代码
├── Python ← CPython 解析器源码
└── Tools ← 用于构建或扩展 Python 的独立工具
接下来,我们将从源代码编译 CPython。
此步骤需要 C 编译器和一些构建工具。不同的系统编译方法也不同,这里我用的是 mac 系统。
在 macOS 上编译 CPython 非常简单。在终端内,运行以下命令即可安装 C 编译器和工具包:
$ xcode-select --install
此命令将弹出一个提示,下载并安装一组工具,包括 Git,Make 和 GNU C 编译器。
你还需要一个 OpenSSL 的工作副本,用于从 PyPi.org 网站获取包。
如果你以后计划使用此版本来安装其他软件包,则需要进行 SSL 验证。
在 macOS 上安装 OpenSSL 的最简单方法是使用 HomeBrew。
如果已经安装了 HomeBrew,则可以使用 brew install 命令安装 CPython 的依赖项。
$ brew install openssl xz zlib
现在你已拥有依赖项,你可以运行 Cpython 目录下的 configure 脚本:
$ CPPFLAGS="-I$(brew --prefix zlib)/include" \
LDFLAGS="-L$(brew --prefix zlib)/lib" \
./configure --with-openssl=$(brew --prefix openssl) --with-pydebug
上面的安装命令中,
CPPFLAGS 是 c 和 c++ 编译器的选项,这里指定了 zlib 头文件的位置,
LDFLAGS 是 gcc 等编译器会用到的一些优化参数,这里是指定了 zlib 库文件的位置,
(brew --prefix openssl) 这一部分的意思是在终端里执行括号里的命令,显示 openssl 的安装路径,可以事先执行括号里的命令,用返回的结果替换 (brew --prefix openssl),效果是一样的,每一行行尾的反斜杠可以使换行时先不执行命令,而是把这三行内容当作一条命令执行。
运行完上面命令以后在存储库的根目录中会生成一个 Makefile,你可以使用它来自动化构建过程。./configure步骤只需要运行一次。
你可以通过运行以下命令来构建 CPython 二进制文件。
$ make -j2 -s
-j2 标志允许 make 同时运行 2 个作业。如果你有 4 个内核,则可以将其更改为 4. -s 标志会阻止 Makefile 将其运行的每个命令打印到控制台。你可以删除它,输出的东西太多了。在构建期间,你可能会收到一些错误,在摘要中,它会通知你并非所有包都可以构建。
例如,_dbm,_sqlite3,_uuid,nis,ossaudiodev,spwd 和_tkinter 将无法使用这组指令构建。如果你不打算针对这些软件包进行开发,这个错误没什么影响。如果你实在需要可以参考:https://devguide.python.org/。
构建将花费几分钟并生成一个名为 python.exe 的二进制文件。每次改动源代码,都需要重新运行 make 进行编译。
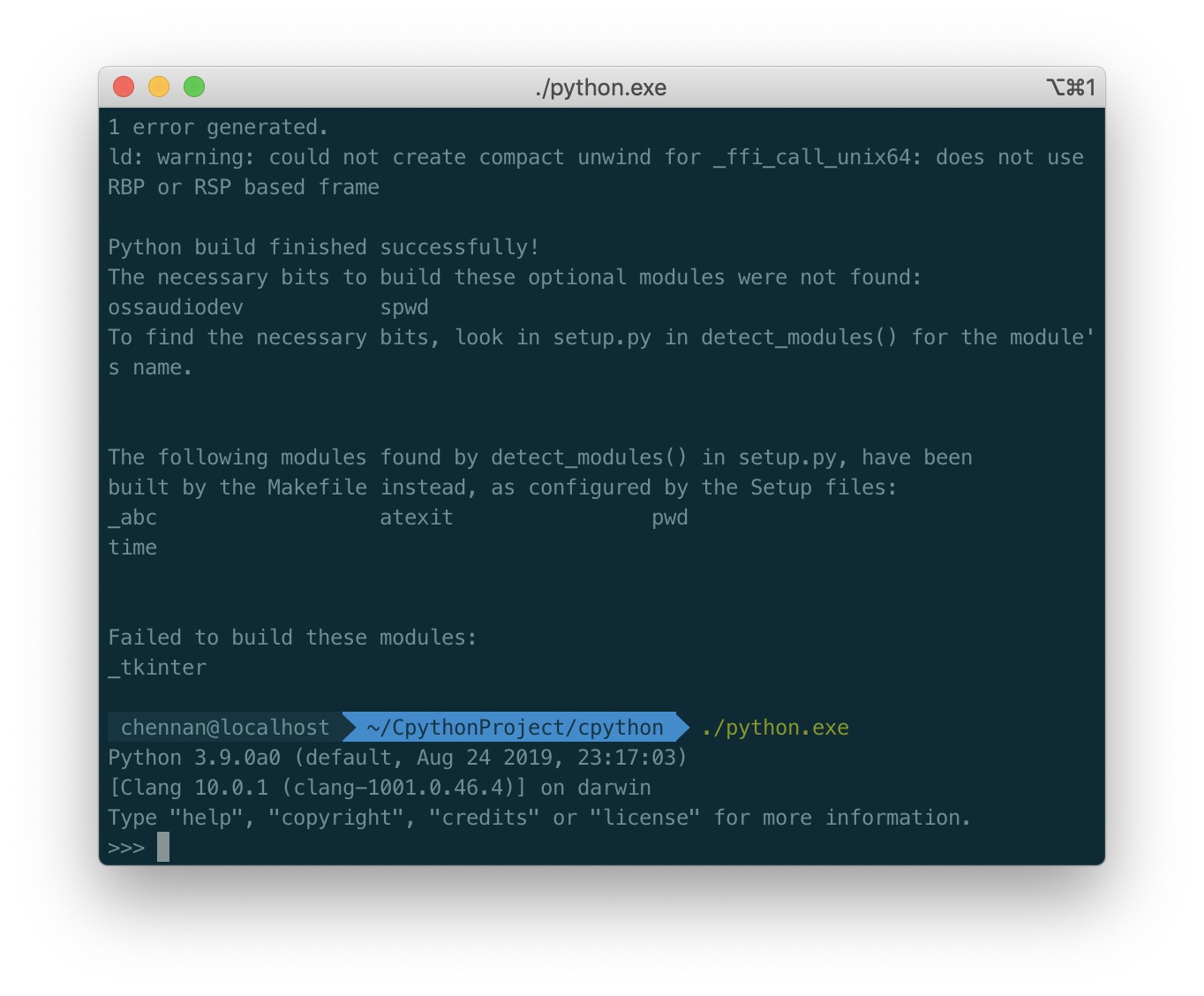
python.exe 二进制文件是 CPython 的调试二进制文件。执行下面命令可以看到 Python 的运行版本。
$ ./python.exe
Python 3.8.0b3 (tags/v3.8.0b3:4336222407, Aug 21 2019, 10:00:03)
[Clang 10.0.1 (clang-1001.0.46.4)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>>
(其实最新的已经到 Python3.9 了,我编译了一下效果如下)
编译器做了什么?
编译器的目的就是将一种语言转为另外一种语言。可以把编译的过程比作翻译,把英语里的“Hello”,翻译成中文的「你好」。
一些编译器将代码编译成只有机器看懂的机器代码,可以直接在系统上进行执行。其他编译器将编译成中间语言,由虚拟机执行。
选择编译器时做出的一个重要决定是系统可移植性要求。Java 和.NET CLR 将编译成中间语言,以便编译的代码可适配其他系统类型。C,Go,C ++和 Pascal 将编译成一个低级可执行文件,只能在类似于编译的系统上运行。
我们一般会直接发布 Python 的源代码,然后直接通过 Python 命令即可运行,其实在内部,运行时 CPython 会编译你的代码。大多数认为 Python 是一种解释性语言。
严格来说其实它实际上是编译类型。
Python 代码不会编译成机器代码。
它被编译成一种特殊的低级中间语言,只有 CPython 才能理解的字节码。在 Python3 中字节码就存储在隐藏目录中的.pyc 文件中,提供了缓存以供下次快速执行。所以,如果在不更改源代码的情况下运行相同的 Python 应用程序两次,第二次总是会快得多。原因就是第二次的时候直接加载了字节码然后运行了程序,不像第一次还需要编译。
为什么 CPython 是用 C 而不是 Python 编写的?
CPython 中的 C 是对 C 编程语言的引用,暗示这个 Python 发行版是用 C 语言编写的。
CPython 中的编译器是用纯 C 编写的。但是,许多标准库模块都是用纯 Python 或 C 和 Python 的组合编写的。
那么为什么 CPython 是用 C 而不是 Python 编写的?
答案就在于编译器的工作原理。
编译器有两种类型:
自托管编译器是用它们编译的语言编写的编译器,例如 Go 编译器。源到源编译器是用另一种已经有编译器的语言编写的编译器。
这也就意味着如果从头开始编写新的编程语言,则需要一个可执行的应用程序来编译你的编译器!你就需要一个编译器来执行任何操作,因此在开发新语言时,它们通常首先用较旧的,更成熟的语言编写。同时节省时间和学习成本。
一个很好的例子就是 Go 语言。
第一个 Go 编译器是用 C 编写的,然后 Go 可以编译,编译器就在 Go 中重写了。
CPython 保留了它的 C 的特性:许多标准库模块(如 ssl 模块或 sockets 模块)都是用 C 语言编写的,用于访问低级操作系统 API。
用于创建网络套接字,与文件系统一起工作或与显示器交互的 Windows 和 Linux 内核中的 API 都是用 C 语言编写的。所以将 Python 的可扩展性层专注于 C 语言是有意义的。在本文的后面部分,我们将介绍 Python 标准库和 C 模块。除此
之外,有一个用 Python 编写的 Python 编译器叫做 PyPy。
PyPy 的徽标是一个 Ouroboros,代表编译器的自托管特性。另一个 Python 交叉编译器的例子是 Jython。
还有一个就是 Jython。Jython 是用 Java 编写的,从 Python 源代码编译成 Java 字节码。与 CPython 可以轻松导入 C 库并从 Python 中使用它们一样,Jython 使得导入和引用 Java 模块和类变得容易。
Python 语言规范
CPython 源代码中包含的是 Python 语言的定义。这是所有 Python 解释器使用的参考规范。该规范采用人类可读和机器可读的格式。文档内部详细说明了 Python 语言,允许的内容以及每个语句的行为方式。
文档
位于Doc/reference目录内的是reStructuredText文件解释了 Python 语言中每个功能属性。这构成了docs.python.org上的官方 Python 参考指南。
在目录中是你需要了解整个语言,结构和关键字的文件:
cpython/Doc/reference
|
├── compound_stmts.rst
├── datamodel.rst
├── executionmodel.rst
├── expressions.rst
├── grammar.rst
├── import.rst
├── index.rst
├── introduction.rst
├── lexical_analysis.rst
├── simple_stmts.rst
└── toplevel_components.rst
在compound_stmts.rst文件中,你可以看到一个定义 with 语句的简单示例。with 语句可以在 Python 中以多种方式使用,最简单的是上下文管理器的实例化和嵌套的代码块:
with x():
...
你可以使用 as 进行重命名
with x() as y:
...
你还可以链式的同时定义多个
with x() as y, z() as jk:
...
接下来,我们将探索 Python 语言的计算机可读文档。
Grammar
该文档包含人类可读规范和存放在单个文件Grammar/Grammar中的机器可读规范。
Grammar 文件是使用称为 Backus-Naur Form(BNF)的上下文表示法进行编写的。
BNF 不是特定于 Python 的,并且通常用作许多其他语言中语法的符号。
编程语言中的语法结构概念是从 20 世纪 50 年代Noam Chomsky’s work on Syntactic Structures 中受到启发的。
Python 的语法文件使用具有正则表达式语法的 Extended-BNF(EBNF)规范。
所以,在语法文件中你可以使用:
- *重复
- +至少重复一次
- []为可选部分
- |任选一个
- ()用于分组
如果在语法文件中搜索 with 语句,你将看到 with 语句的定义:
.. productionlist::
with_stmt: "with" `with_item` ("," `with_item`)* ":" `suite`
with_item: `expression` ["as" `target`]
引号中的内容都是字符串,这是一中关键字的定义方式。所以 with_stmt 指定为:
1.with单词开头
2.接下来是 with_item,它是一个test和(可选)as 表达式。
3.多个项目之间使用逗号进行间隔
4.以字符:结尾
5.其次是 suite。
这两行中提到了一些其他定义:
suite是指具有一个或多个语句的代码块。test是指一个被评估的简单语句。expr指的是一个简单的表达式
如果你想详细探索这些内容,可以在此文件中定义整个 Python 语法。
如果你想看一个最近如何使用语法的例子,例如在 PEP572 中,:=运算符被添加到语法文件中。
ATEQUAL '@='
RARROW '->'
ELLIPSIS '...'
+ COLONEQUAL ':='
OP
ERRORTOKEN
使用 pgen
Grammar 文件本身不会被 Python 编译器使用。
是使用一个名为 pgen 的工具,来创建的解析器表。pgen 会读取语法文件并将其转换为解析器表。如果你对语法文件进行了更改,则必须重新生成解析器表并重新编译 Python。
注意:pgen 应用程序在 Python 3.8 中从 C 重写为纯 Python。
为了查看 pgen 的运行情况,让我们改变 Python 语法的一部分。并重新编译运行 Python。
在 Grammar 路径下看到两个文件 Grammar 和 Tokens,我们在 Grammar 搜索 pass_stmt,然后看到下面这样
pass_stmt: 'pass'
我们修改一下,改为下面这样
pass_stmt: 'pass' | 'proceed'
在 Cpython 的根目录使用 make regen-grammar命令来运行pgen重新编译 Grammar 文件。
应该看到类似于此的输出,表明已生成新的Include/graminit.h和Python/graminit.c文件:
下面是部分输出内容
# Regenerate Include/graminit.h and Python/graminit.c
# from Grammar/Grammar using pgen
PYTHONPATH=. python3 -m Parser.pgen ./Grammar/Grammar \
./Grammar/Tokens \
./Include/graminit.h.new \
./Python/graminit.c.new
python3 ./Tools/scripts/update_file.py ./Include/graminit.h ./Include/graminit.h.new
python3 ./Tools/scripts/update_file.py ./Python/graminit.c ./Python/graminit.c.new
使用重新生成的解析器表,需要重新编译 CPython 才能查看新语法。使用之前用于操作系统的相同编译步骤。
make -j4 -s
如果代码编译成功,执行新的 CPython 二进制文件并启动 REPL。
./python.exe
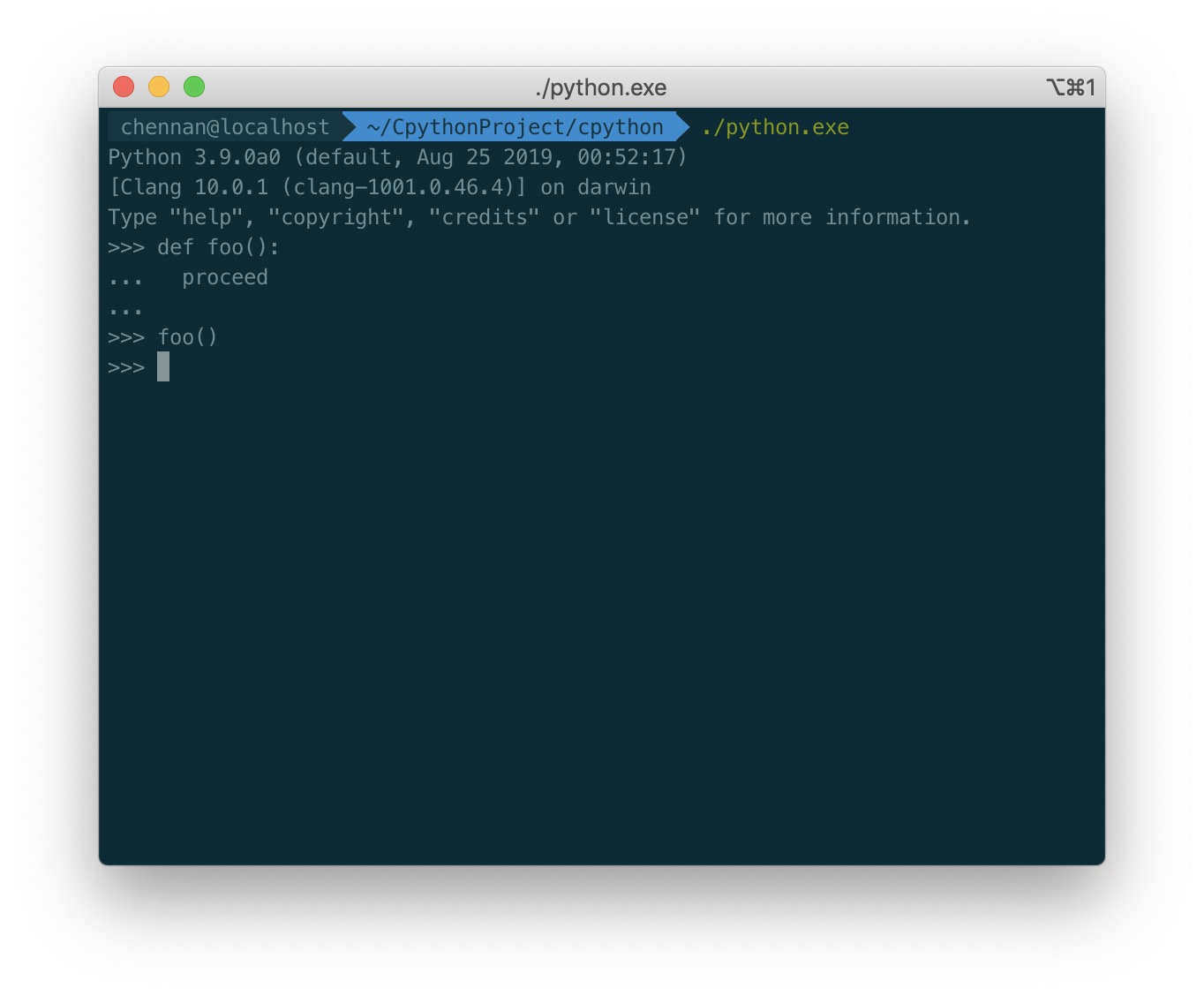
在 REPL 中,现在可以尝试定义一个函数,使用编译为 Python 语法的 proceed 关键字替代 pass 语句。
Python 3.8.0b3 (tags/v3.8.0b3:4336222407, Aug 21 2019, 10:00:03)
[Clang 10.0.1 (clang-1001.0.46.4)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> def example():
... proceed
...
>>> example()
下面是我运行结果,很有意思居然没有出错。
接下来,我们将探讨 Tokens 文件及其与 Grammar 的关系。
Tokens
与 Grammar 文件夹中的语法文件一起是一个 Tokens 文件,它包含在解析树中作为叶节点找到的每个唯一类型,稍后我们将深入介绍解析器树。每个 token 还具有名称和生成的唯一 ID,这些名称用于简化在 tokenizer 中引用。
注意:Tokens 文件是 Python 3.8 中的一项新功能。
例如,左括号称为 LPAR,分号称为 SEMI。
你将在本文后面看到这些标记:
LPAR '('
RPAR ')'
LSQB '['
RSQB ']'
COLON ':'
COMMA ','
SEMI ';'
与语法文件一样,如果更改 Tokens 文件,则需要再次运行 pgen。
要查看操作中的 tokens,可以在 CPython 中使用 tokenize 模块。创建一个名为 test_tokens.py 的简单 Python 脚本:
# Hello world!
def my_function():
proceed
然后通过名为 tokenize 的标准库中内置的模块传递此文件。你将按行和字符查看令牌列表。使用-e 标志输出确切的令牌名称:
0,0-0,0: ENCODING 'utf-8'
1,0-1,14: COMMENT '# Hello world!'
1,14-1,15: NL '\n'
2,0-2,3: NAME 'def'
2,4-2,15: NAME 'my_function'
2,15-2,16: LPAR '('
2,16-2,17: RPAR ')'
2,17-2,18: COLON ':'
2,18-2,19: NEWLINE '\n'
3,0-3,3: INDENT ' '
3,3-3,7: NAME 'proceed'
3,7-3,8: NEWLINE '\n'
4,0-4,0: DEDENT ''
4,0-4,0: ENDMARKER ''
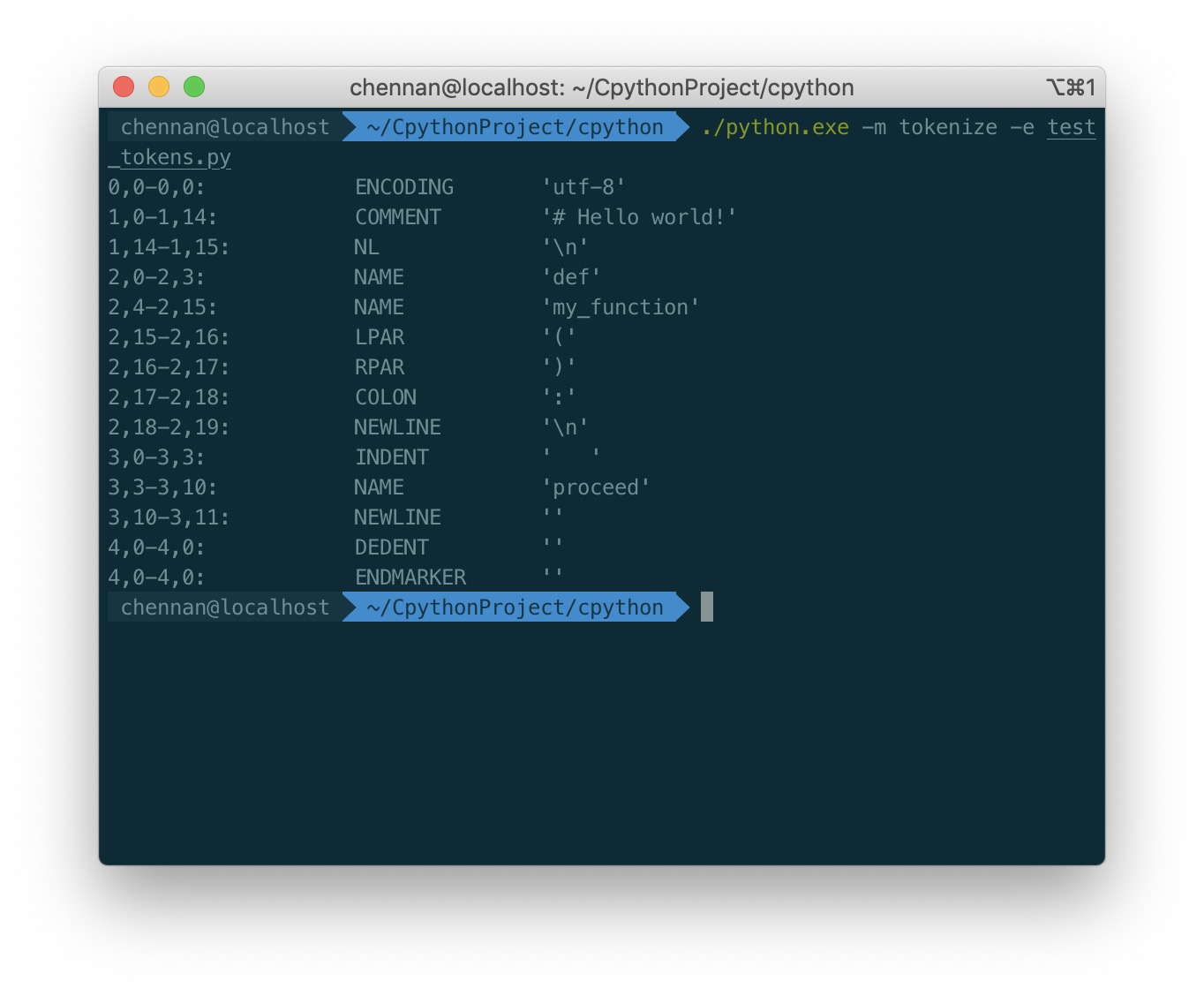
在输出中,第一列是行/列坐标的范围,第二列是令牌的名称,最后一列是令牌的值。
在输出中,tokenize 模块隐含了一些不在文件中的标记。
utf-8 的 ENCODING 标记,末尾有一个空行,DEDENT 关闭函数声明,ENDMARKER 结束文件。tokenize 模块是用纯 Python 编写的,位于 CPython 源代码中的Lib/tokenize.py中。
重要提示:CPython 源代码中有两个 tokenizers:一个用 Python 编写,上面演示的这个,另一个是用 C 语言编写的。用 Python 编写的被用作实用程序,而用 C 编写的被用于 Python 编译器。但是,它们具有相同的输出和行为。用 C 语言编写的版本是为性能而设计的,Python 中的模块是为调试而设计的。
要查看 C 语言的的 tokenizer 的详细内容,可以使用-d 标志运行 Python。
使用之前创建的 test_tokens.py 脚本,使用以下命令运行它:
./python.exe -d test_tokens.py
得到如下结果
Token NAME/'def' ... It's a keyword
DFA 'file_input', state 0: Push 'stmt'
DFA 'stmt', state 0: Push 'compound_stmt'
DFA 'compound_stmt', state 0: Push 'funcdef'
DFA 'funcdef', state 0: Shift.
Token NAME/'my_function' ... It's a token we know
DFA 'funcdef', state 1: Shift.
Token LPAR/'(' ... It's a token we know
DFA 'funcdef', state 2: Push 'parameters'
DFA 'parameters', state 0: Shift.
Token RPAR/')' ... It's a token we know
DFA 'parameters', state 1: Shift.
DFA 'parameters', state 2: Direct pop.
Token COLON/':' ... It's a token we know
DFA 'funcdef', state 3: Shift.
Token NEWLINE/'' ... It's a token we know
DFA 'funcdef', state 5: [switch func_body_suite to suite] Push 'suite'
DFA 'suite', state 0: Shift.
Token INDENT/'' ... It's a token we know
DFA 'suite', state 1: Shift.
Token NAME/'proceed' ... It's a keyword
DFA 'suite', state 3: Push 'stmt'
...
ACCEPT.
在输出中,您可以看到它突出显示为关键字。在下一章中,我们将看到如何执行 Python 二进制文件到达 tokenizer 以及从那里执行代码会发生什么。现在您已经概述了 Python 语法以及 tokens 和语句之间的关系,有一种方法可以将 pgen 输出转换为交互式图形。
以下是 Python 3.8a2 语法的屏幕截图:
 看不清没关系,用于生成此图的 Python 包(instaviz)将在后面的章节中介绍。这里先做了解。
看不清没关系,用于生成此图的 Python 包(instaviz)将在后面的章节中介绍。这里先做了解。
Python 中的内存管理
在本文中,你将看到对 PyArena 对象的引用。
arena是 CPython 的内存管理结构之一。代码在Python/pyarena.c中其中包含了 C 的内存分配和解除分配的方法。
在编写的 C 程序中,开发人员应在写入数据之前为数据结构分配内存。此分配将内存标记为属于操作系统的进程。当不再使用已分配的内存并将其返回到操作系统的可用内存块表时,开发人员也可以解除分配或“释放”它们。如果进程为一个变量分配内存,比如在函数或循环中,当该函数完成时,内存不会自动返回给 C 中的操作系统。因此,如果它未在 C 代码中显式释放,则会导致内存泄漏。每次该函数运行时,该过程将继续占用更多内存,直到最终,系统耗尽内存并崩溃!Python 将这一责任从程序员手中夺走,并使用两种算法:引用计数器和垃圾收集器。每当解释器被实例化时,PyArena方法创建并附加解释器中的一块内存区域。在 CPython 解释器的生命周期中,arenas可以被分配。它们与链表相关联。
arenas将 Python 对象的指针列表存储为PyListObject方法。每当创建一个新的 Python 对象时,都会使用PyArena_AddPyObject方法添加指向它的指针。
此函数调用将指针存储在arenas列表 a_objects 中。PyArena方法提供第二个功能,即分配和引用原始内存块列表。例如,如果添加了数千个附加值,C 代码中PyList将需要额外的内存。但是PyList不直接分配内存。该对象通过从PyObject调用具有所需内存大小的PyArena_Malloc从PyArena获取原始内存块。此任务在Objects/oballoc.c中的完成。在对象分配模块中,可以为 Python 对象分配,释放和重新分配内存。已分配块的链接列表存储在arenas内,因此当解释器停止时,可以使用PyArena_Free一次解除所有托管内存块的释放。
以PyListObject为例,如果你使用.append()一将个对象放到 Python 列表的末尾,就不需要重新分配内存了,而是使用现有列表中内存。
.append()方法调用list_resize()来处理列表的内存分配。每个列表对象都保留已分配内存量的列表。如果要追加的项目将适合现有的可用内存,则只需添加即可。如果列表需要更多内存空间,则会进行扩展。列表的长度扩展为 0,4,8,16,25,35,46,58,72,88。
调用PyMem_Realloc可以扩展列表中分配的内存。
PyMem_Realloc是pymalloc_realloc的 API 包装器。Python 还有一个 C 调用malloc的特殊包装器,它设置内存分配的最大大小以帮助防止缓冲区溢出错误(参见 PyMem_RawMalloc)。
综上所述:
- 原始内存块的分配是通过
PyMem_RawAlloc完成的。 - Python 对象的指针存储在
PyArena中。 PyArena还存储了已分配内存块的链表。
有关 API 的更多信息,请参阅 CPython 文档。
引用计数
要在 Python 中创建变量并赋值,变量名必须为一。
my_variable = 180392
只要在 Python 中为变量赋值,就会在 locals 和 globals 范围内检查变量的名称,以查看它是否已存在。因为 my_variable 不在 locals()或 globals()字典中,所以创建了这个新对象,并将该值指定为数字常量 180392。现在有一个对 my_variable 的引用,因此 my_variable 的引用计数器增加 1。
你可以在 CPython 的 C 源代码中看到函数Py_INCREF和Py_DECREF。
这两个函数分别是对该对象的递增和递减做引用计数。当变量超出声明范围时,对对象的引用会递减。Python 中的范围可以指代函数或方法,生成式或 lambda 函数。这些是一些更直观的范围,但还有许多其他隐式范围,比如将变量传递给函数调用。递增和递减引用的处理在 CPython 编译器和核心执行循环ceval.c文件中。我们将在本文后面详细介绍。
每当调用Py_DECREF并且计数器变为 0 时,就会调用PyObject_Free函数。对于该对象,会为所有已分配的内存调用PyArena_Free。
垃圾收集
CPython 的垃圾收集器默认启用,发生在后台,用于释放已不再使用的对象的内存。
因为垃圾收集算法比引用计数器复杂得多,所以它不会一直发生,否则会消耗大量的 CPU 资源。经过一定数量的操作后,它会定期发生。CPython 的标准库附带了一个 Python 模块,用于与arena 和垃圾收集器 gc 模块连接。
以下是在调试模式下使用 gc 模块的方法:
>>> import gc
>>> gc.set_debug(gc.DEBUG_STATS)
这将在运行垃圾收集器时打印统计信息。
可以通过调用get_threshold来获取运行垃圾收集器的阈值:
>>> gc.get_threshold()
(700, 10, 10)
还可以获取当前阈值计数:
>>> gc.get_count()
(688, 1, 1)
最后,你可以手动运行收集算法:
>>> gc.collect()
24
这将调用Modules/gcmodule.c文件中的collect(),该文件包含垃圾收集器算法的实现。
结论
在第 1 部分中,我们介绍了源代码库的结构,如何从源代码编译以及 Python 语言规范。
当你深入了解 Python 解释器过程时,这些核心概念在第 2 部分中将是至关重要的。
教你阅读 Cpython 的源码(一)的更多相关文章
- 教你阅读 Cpython 的源码(二)
第二部分:Python解释器进程 在上节教你阅读 Cpython 的源码(一)中,我们从编写Python到执行代码的过程中看到Python语法和其内存管理机制. 在本节,我们将从代码层面去讨论 ,Py ...
- daily news新闻阅读客户端应用源码(兼容iPhone和iPad)
daily news新闻阅读客户端应用源码(兼容iPhone和iPad),也是一款兼容性较好的应用,可以支iphone和ipad的阅读阅读器源码,设计风格和排列效果很不错,现在做新闻资讯客户端的朋友可 ...
- 如何阅读Android系统源码-收藏必备
对于任何一个对Android开发感兴趣的人而言,对于android系统的学习必不可少.而学习系统最佳的方法就如linus所言:"RTFSC"(Read The Fucking So ...
- android新闻项目、饮食助手、下拉刷新、自定义View进度条、ReactNative阅读器等源码
Android精选源码 Android仿照36Kr官方新闻项目课程源码 一个优雅美观的下拉刷新布局,众多样式可选 安卓版本的VegaScroll滚动布局 android物流详情的弹框 健身饮食记录助手 ...
- android选择器汇总、仿最美应用、通用课程表、卡片动画、智能厨房、阅读客户端等源码
Android精选源码 android各种 选择器 汇总源码 高仿最美应用项目源码 android通用型课程表效果源码 android实现关键字变色 Android ViewPager卡片视差.拖拽及 ...
- android五子棋游戏、资讯阅读、大学课程表、地图拖拽检测、小说搜索阅读app等源码
Android精选源码 Android 自动生成添加控件 android旋转动画.圆形进度条组合效果源码 一款很强的手机五子棋app源码 android地图拖拽区域检测效果源码 实现Android大学 ...
- android优化中国风应用、完整NBA客户端、动态积分效果、文件传输、小说阅读器等源码
Android精选源码 android拖拽下拉关闭效果源码 一款优雅的中国风Android App源码 EasySignSeekBar一个漂亮而强大的自定义view15 android仿蘑菇街,蜜芽宝 ...
- 新手阅读 Nebula Graph 源码的姿势
摘要:在本文中,我们将通过数据流快速学习 Nebula Graph,以用户在客户端输入一条 nGQL 语句 SHOW SPACES 为例,使用 GDB 追踪语句输入时 Nebula Graph 是怎么 ...
- 如何通过eclipse查看、阅读hadoop2.4源码
问题导读:1.官网src包下载包,能否直接使用?2.如何跟踪和查看hadoop源码? 此篇是从零教你如何获取hadoop2.4源码并使用eclipse关联hadoop2.4源码基础上的一个继续,上文其 ...
随机推荐
- ios下按钮click事件点击穿透问题
和app进行混合开发的时候,一个页面使用h5写的,按钮上绑定click事件会触发下面图片上的a链接导致跳转,页面如图 顶部是一个banner,分vr.视频.图片三部分,红框处的三个nav按钮绑定cli ...
- js入门之内置对象Math
一. 复习数据类型 简单数据类型, 基本数据类型/值类型 Number String Boolean Null Undefined 复杂数据类型 引用类型 Object 数组 数据在内存中是如何存储的 ...
- Installation Manager1.8安装
1.下载地址: https://www-01.ibm.com/marketing/iwm/iwm/web/download.do?S_PKG=500005026&source=swerpws- ...
- Mysql踩坑 自动更新的时间只允许有一个
执行如下SQL创建表: CREATE TABLE aa ( a INT, b TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, c TIMESTAMP DEFAULT CU ...
- jenkins中的流水线( pipeline)的理解(未完)
目录 一.理论概述 Jenkins流水线的发展历程 什么是Jenkins流水线 一.理论概述 pipeline是流水线的英文释义,文档中统一称为流水线 Jenkins流水线的发展历程 在Jenki ...
- 【OF框架】在Visual Studio中发布Docker镜像,推送镜像到Azure容器注册表
准备 拥有Azure账号,已经创建 Azure容器注册表,获得注册表地址.账号.密码 本地已经在Visual Studio登录Azure账号. 本地已经拥有Docker环境 注意:首次发布Docker ...
- css详解2
1.伪类选择器 1.1.a标签的爱恨准则 LoVe HAte .一个冒号连接 1.2.a标签的示例 给a标签设置个颜色,生效了 <html lang="en"> < ...
- Kubernetes日志采集
Kubernetes日志打印方式 标准输出 docker标准输出日志stdout和stderr,使用docker logs或者kubectl logs查看最新的日志(tail). 如果想看到更多的日志 ...
- mybatis3.0-[topic10-14] -全局配置文件_plugins插件简介/ typeHandlers_类型处理器简介 /enviroments_运行环境 /多数据库支持/mappers_sql映射注册
mybatis3.0-全局配置文件_ 下面为中文官网解释 全局配置文件的标签需要按如下定义的顺序: <!ELEMENT configuration (properties?, setting ...
- 突然萌发关于 redis 的想法(1)
本来昨天就打算写这篇了,但是熬到忘了,至于为什么要写这个是因为我昨天在写 redis 的时候突然想到的 注:此篇文章并没有讲解 redis 内部的使用 或 如何使用redis写代码,等等..仅仅只是突 ...