Greenplum 调优--数据倾斜排查(一)
对于分布式数据库来说,QUERY的运行效率取决于最慢的那个节点。

当数据出现倾斜时,某些节点的运算量可能比其他节点大。除了带来运行慢的问题,还有其他的问题,例如导致OOM,或者DISK FULL等问题。
如何监控倾斜
1、监控数据库级别倾斜
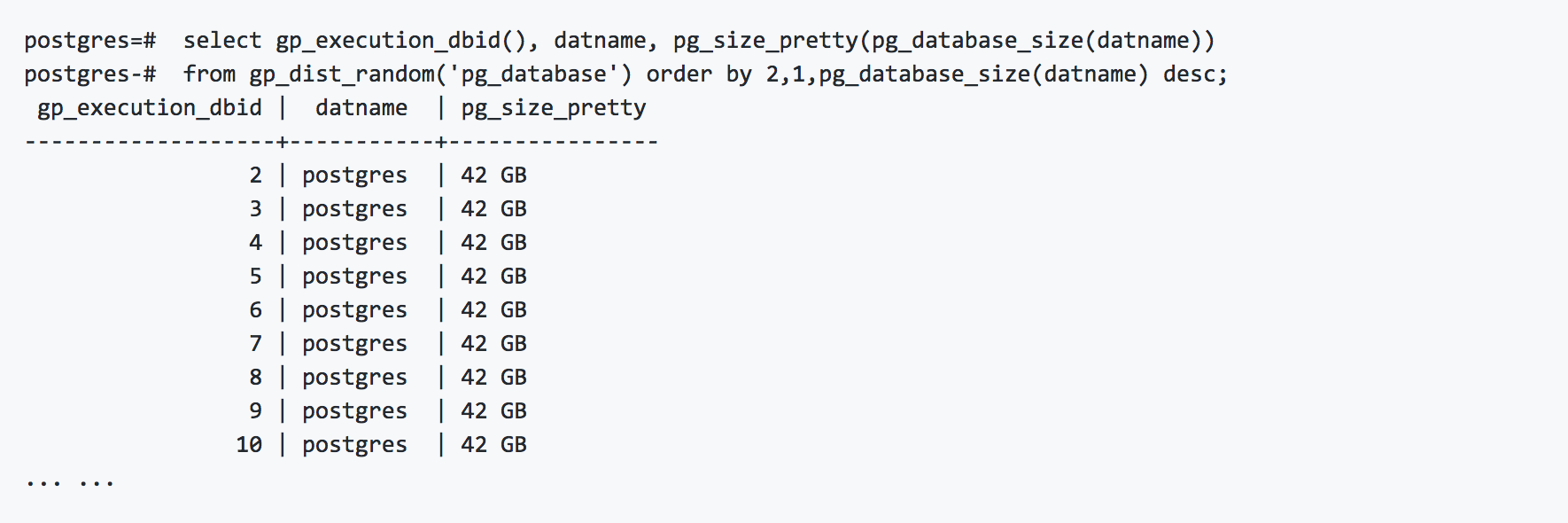
2、监控表级倾斜

出现数据倾斜的原因和解决办法
1.分布键选择不正确,导致数据存储分布不均。
例如选择的字段某些值特别多,由于数据是按分布键VALUE的HASH进行分布的,导致这些值所在的SEGMENT的数据可能比而其他SEGMENT多很多。
分布键的选择详见:
《Greenplum 最佳实践 - 数据分布黄金法则 - 分布列与分区的选择》
2.查询导致的数据重分布,数据重分布后,数据不均。
例如group by的字段不是分布键,那么运算时就需要重分布数据。
解决办法1:
由于查询带来的数据倾斜的可能性非常大,所以Greenplum在内核层面做了优化,做法是:
先在segment本地聚合产生少量记录,将聚合结果再次重分布,重分布后再次在segment聚合,最后将结果发到master节点,
有必要的话在master节点调用聚合函数的final func(已经是很少的记录数和运算量)。
例子:
tblaocol表是c1的分布键,但是我们group by使用了c398字段,因此看看它是怎么做的呢?请看执行计划的解释。
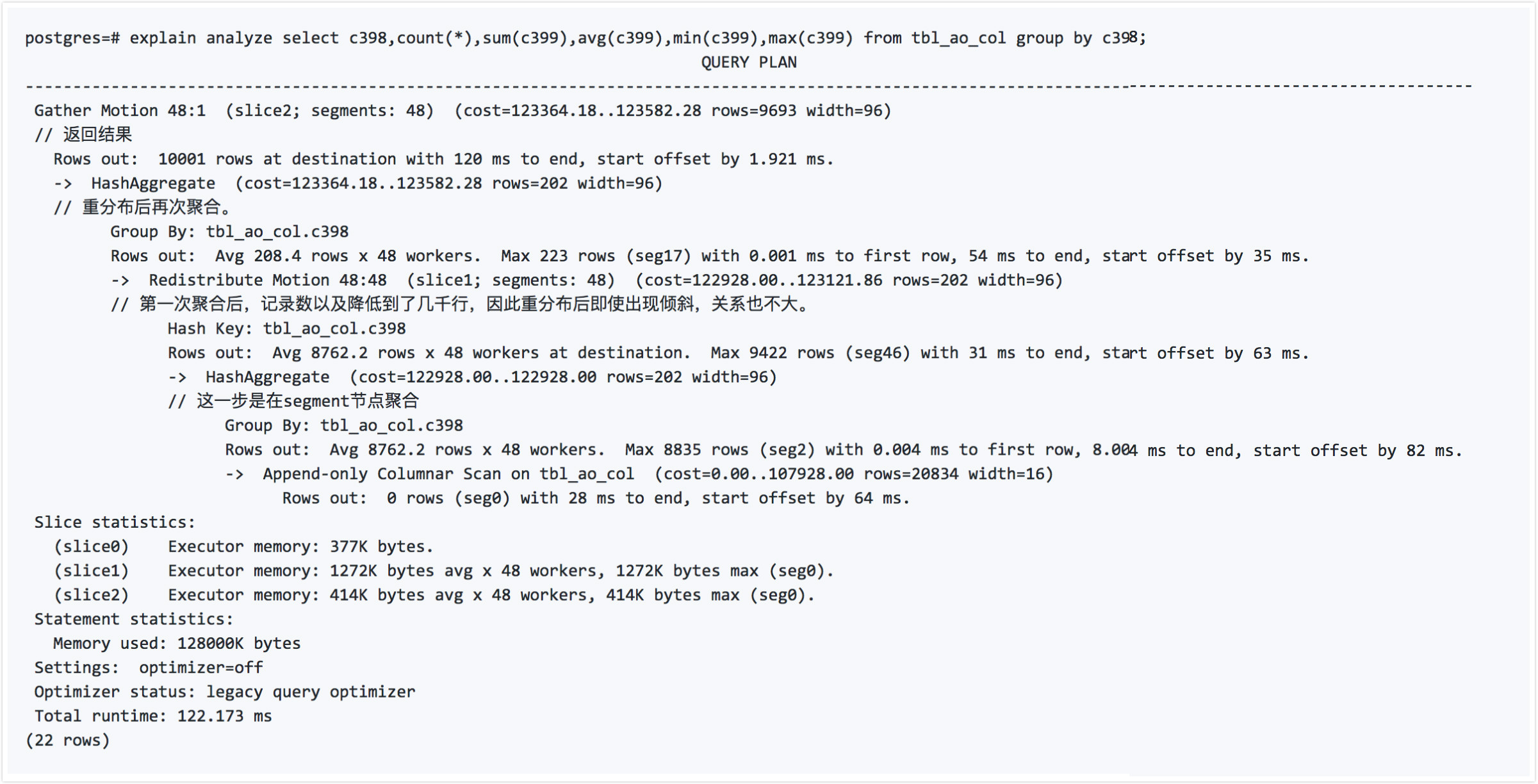
对于非分布键的分组聚合请求,Greenplum采用了多阶段聚合如下:
- 第一阶段,在SEGMENT本地聚合。(需要扫描所有数据,这里不同存储,前面的列和后面的列的差别就体现出来了,行存储的deform开销,
在对后面的列进行统计时性能影响很明显。) - 第二阶段,根据分组字段,将结果数据重分布。(重分布需要用到的字段,此时结果很小。)
- 第三阶段,再次在SEGMENT本地聚合。(需要对重分布后的数据进行聚合。)
- 第四阶段,返回结果给master,有必要的话master节点调用聚合函数的final func(已经是很少的记录数和运算量)。
3.内核只能解决一部分查询引入的数据重分布倾斜问题,还有一部分问题内核没法解决。例如窗口查询。
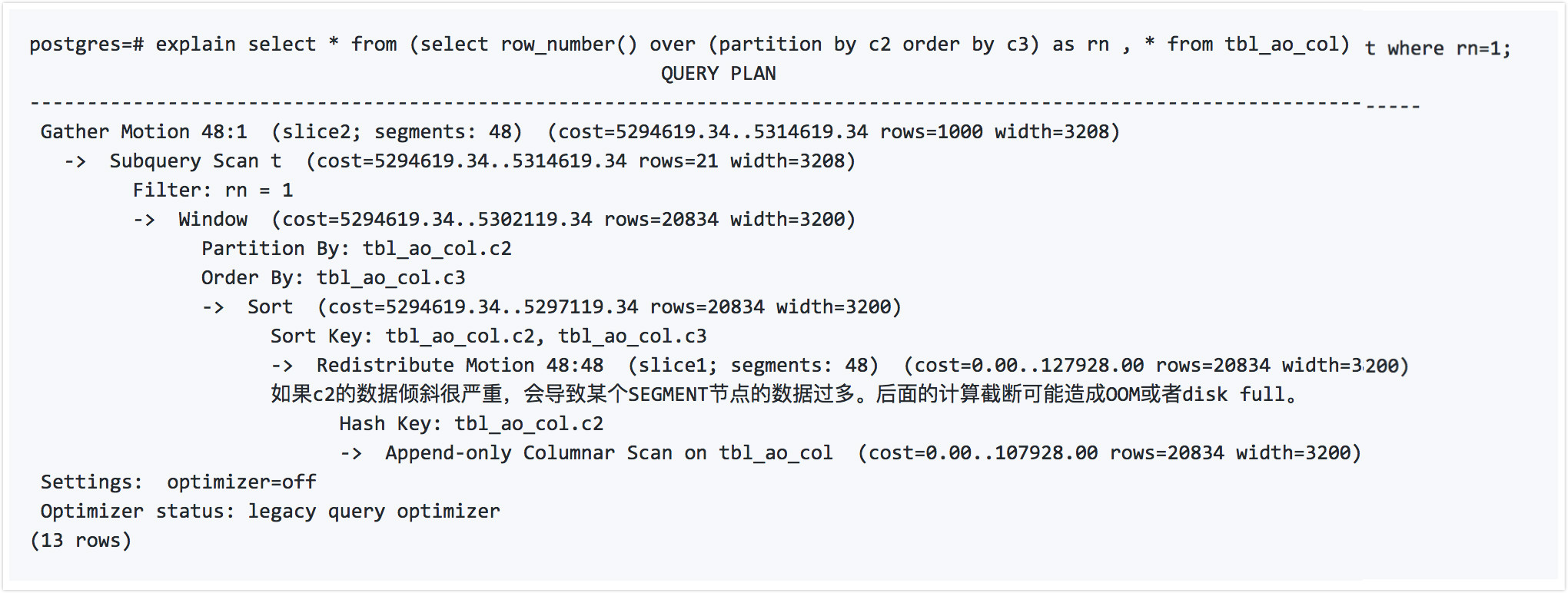
使用窗口函数时,Greenplum需要先按窗口中的分组对数据进行重分布,这一次重分布就可能导致严重的倾斜。实际上内核层优化才是最好的解决办法,例如以上窗口函数,由于我们只需要取c2分组中c3最小的一条记录。因此也可以在每个节点先取得一条,再重分布,再算。
不通过修改内核,还有什么方法呢?
3.1 Mapreduce任务就很好解决,Greenplum的mapreduce接口调用方法如下:
http://greenplum.org/docs/refguide/yamlspec.html
3.2 通过写PL函数也能解决。例如

小结
数据倾斜的原因可能是数据存储的倾斜,QUERY执行过程中数据重分布的倾斜。
数据倾斜可能引入以下后果:
- 计算短板
- oom
- disk full
数据倾斜的解决办法:
- 如果是存储的倾斜,通过调整更加均匀的分布键来解决。(也可以选择使用随机分布,或者使用多列作为分布键)。
- 如果是QUERY造成的倾斜,Greenplum内核对group by已经做了优化,即使分组字段不是分布键,通过多阶段聚合,可以消除影响。
- 如果是窗口函数QUERY造成的倾斜,目前内核没有对这部分优化,首先会对窗口函数的分组字段所有数据进行重分布,如果这个分组字段数据有严重倾斜,那么会造成重分布后的某些节点数据量过大。解决办法有mapreduce或pl函数。
参考
《Greenplum 内存与负载管理最佳实践》
《Greenplum 最佳实践 - 数据分布黄金法则 - 分布列与分区的选择》
Greenplum 调优--数据倾斜排查(一)的更多相关文章
- Greenplum 调优--数据倾斜排查(二)
上次有个朋友咨询我一个GP数据倾斜的问题,他说查看gp_toolkit.gp_skew_coefficients表时花费了20-30分钟左右才出来结果,后来指导他分析原因并给出其他方案来查看数据倾斜. ...
- Spark调优 数据倾斜
1. Spark数据倾斜问题 Spark中的数据倾斜问题主要指shuffle过程中出现的数据倾斜问题,是由于不同的key对应的数据量不同导致的不同task所处理的数据量不同的问题. 例如,reduce ...
- spark性能调优 数据倾斜 内存不足 oom解决办法
[重要] Spark性能调优——扩展篇 : http://blog.csdn.net/zdy0_2004/article/details/51705043
- spark调优——数据倾斜
Spark中的数据倾斜问题主要指shuffle过程中出现的数据倾斜问题,是由于不同的key对应的数据量不同导致的不同task所处理的数据量不同的问题. 例如,reduce点一共要处理100万条数据,第 ...
- 1-Spark-1-性能调优-数据倾斜1-特征/常见原因/后果/常见调优方案
数据倾斜特征:个别Task处理大部分数据 后果:1.OOM;2.速度变慢,甚至变得慢的不可接受 常见原因: 数据倾斜的定位: 1.WebUI(查看Task运行的数据量的大小). 2.Log,查看log ...
- 2-Spark-1-性能调优-数据倾斜2-Join/Broadcast的使用场景
技术点:RDD的join操作可能产生数据倾斜,当两个RDD不是非常大的情况下,可以通过Broadcast的方式在reduce端进行类似(Join)的操作: broadcast是进程级别的,只读的. b ...
- Greenplum 调优--VACUUM系统表
Greenplum 调优--VACUUM系统表 1.VACUUM系统表原因 Greenplum是基于MVCC版本控制的,所有的delete并没有删除数据,而是将这一行数据标记为删除, 而且update ...
- [redis]复制机制,调优,故障排查
在redis的安装目录下首先启动一个redis服务,使用默认的配置文件,作为主服务 ubuntu@slave1:~/redis2$ ./redis-server ./redis.conf & ...
- 专访周金可:我们更倾向于Greenplum来解决数据倾斜的问题
周金可,就职于听云,维护MySQL和GreenPlum的正常运行,以及调研适合听云业务场景的数据库技术方案. 听云周金可 9月24日,周金可将参加在北京举办的线下活动,并做主题为<GreenPl ...
随机推荐
- [tomcat] 连接池参数maxActive、maxIdle 、maxWait 等
maxActive 连接池支持的最大连接数,这里取值为20,表示同时最多有20个数据库连接.设 0 为没有限制.maxIdle 连接池中最多可空闲maxIdle个连接 ,这里取值为20,表示即使没有数 ...
- linux安装imagemagick,centos安装imagemagick方法
1.安装文件格式支持库 yum install tcl-devel libpng-devel libjpeg-devel ghostscript-devel bzip2-devel freetype- ...
- jacascript Ajax 学习之 JQuery-Ajax
jQuery 对 ajax 操作进行了封装,在 jQuery 中 $.ajax() 属性最底层的方法,第2层是 load().$.get() 和 $.post() 方法,第3层是 $.getScrip ...
- Jenkins 发邮件的Job
Jenkins要做到构建失败的时候发送邮件,常规做法是加个全局的post failure,类似这样的代码 pipeline { agent any stages { stage('deploy') { ...
- 我自己用C++写了个GMM(Gaussian mixture model)模型
我自己用C++写了个GMM(Gaussian mixture model)模型 Written for an assignment 之前粗粗了解了GMM的原理,但是没有细看,现在有个Assignmen ...
- R_数据视觉化处理_初阶_02
通过数据创建一幅简单的图像, #Crate a easy photopdf("mygraph.pdf") attach(mtcars) plot(wt,mpg) abline(lm ...
- 关于微信小程序iOS端时间格式兼容问题
经过测试发现,当时间格式为 2018-08-08 08:00 ,需要将时间转为其他格式时,Android端转换成功,iOS端报错或是转为NaN 这是因为iOS端对符号‘ - ’不支持,也就是说iOS端 ...
- iOS-CGContextRef
图形上下文(Graphics Context)---绘制目标 需要在iOS应用程序的屏幕上进行绘制时,需要先定义一个UIView类,并实现它的drawRect:方法,当启动程序时,会先调用loadVi ...
- java一些基本算法
本文主要介绍一些常用的算法: 冒泡排序:两两相互之间进行比较,如果符合条件就相互兑换. //冒泡排序升序 public static int[] bubblingSortAsc(int[] array ...
- c# 定制处理未处理异常