《python解释器源码剖析》第4章--python中的list对象
4.0 序
python中的list对象,底层对应的则是PyListObject。如果你熟悉C++,那么会很容易和C++中的list联系起来。但实际上,这个C++中的list大相径庭,反而和STL中的vector比较类似
4.1 PyListObject对象
我们知道python里面的list对象是支持对元素进行增删改查等操作的,list对象里面存储的,底层无一例外都是PyObject * 指针。所以实际上我们可以这样看待python底层的PyListObject:vector<PyObject *>。
根据我们使用python的list的经验,我们可以得出以下两个结论。
每个PyListObject维护的元素个数可以不一样:所以这是一个变长对象可以对PyListObject维护的元素进行添加、删除等操作,所以这是一个可变对象
我们来看一下,PyListObject对象的定义。
typedef struct {
//不用解释,PyObject加上一个ob_size
PyObject_VAR_HEAD
/* ob_item就对应list对象存储的元素,ob_item[0]就是list[0]
但是我们发现这是一个二级指针,至于这里的二级指针是如何和
python中list挂上钩的,我们后面会详细介绍
*/
PyObject **ob_item;
/*
这个allocated是什么呢?其实我在最开始的那一章介绍python源码的时候就已经解释过了。
这里再来说一遍,我们知道PyObject_VAR_HEAD里面有一个ob_size,这是表示变长对象里面
已经存储了多少个元素了。而这个allocated,则表示最大能存储多少个元素,因为这是一个
变长对象,因此就意味着可以随时对其进行删除、增加等操作,如果每次添加都要malloc,那么
效率会非常低下,因此python会事先申请一大份内存,而allocated正是记录了这个一大份内存
的容量是多少。而ob_size则是目前已经存了多少个,如果你学过golang,你会发现ob_size对应
golang里面切片的len,而allocated则对应cap。假设一个能容纳10个元素的PyListObject对象
已经存了5个元素,那么ob_size就是5,allocated就是10。
从这里我们已经能够看出:
0 <= ob_size <= allocated
len(list) == ob_size 注意这里的list指的都是list的实例对象,而不是list这个类本身
ob_item == NULL 意味着 ob_size == allocated == 0
*/
Py_ssize_t allocated;
} PyListObject;
刚才说了,python事先会申请一大份内存,这个并不是指在创建的时候申请一大份内存,而是在扩容的时候,会申请更多的内存。
PyListObject有一个resize操作,不用想,这个肯定是修改列表容量的。因为allocated一开始是固定的,但是随着ob_size越来越大,肯定要申请更多的内存,即增大allocated
static int
list_resize(PyListObject *self, Py_ssize_t newsize)
{
//参数self就是PyListObject *对象本身
//参数newsize就是当前的ob_size
PyObject **items;
//既然resize,所以new_allocated就是新的最大容量
size_t new_allocated, num_allocated_bytes;
//这里的获取当前PyListObject的allocated
Py_ssize_t allocated = self->allocated;
//如果当前的容量大于newsize(ob_size),并且newsize >= 容量除以2
//基本上啥也没干直接返回,这一步不需要关心。
//因为执行这一步表示内存不需要重新分配
if (allocated >= newsize && newsize >= (allocated >> 1)) {
assert(self->ob_item != NULL || newsize == 0);
Py_SIZE(self) = newsize;
return 0;
}
/*
计算重新分配的内存的大小
这一步很重要,新分配的容量就等于newsize + newsize >> 3 + 3 if newsize < 9 else 6
*/
new_allocated = (size_t)newsize + (newsize >> 3) + (newsize < 9 ? 3 : 6);
if (new_allocated > (size_t)PY_SSIZE_T_MAX / sizeof(PyObject *)) {
PyErr_NoMemory();
return -1;
}
//如果新的ob_size是0,那么新分配的容量也是0
if (newsize == 0)
new_allocated = 0;
//所占的字节,就是new_allocated * sizeof(PyObject *)
//但是我们发现这里乘上的是一个指针的大小,这是一个很关键的问题,我们后面会详谈
num_allocated_bytes = new_allocated * sizeof(PyObject *);
//为ob_item申请内存
items = (PyObject **)PyMem_Realloc(self->ob_item, num_allocated_bytes);
if (items == NULL) {
PyErr_NoMemory();
return -1;
}
//指向新的内存块,扩展列表。
self->ob_item = items;
//将ob_size变为newsize
Py_SIZE(self) = newsize;
//将allocated变为新的new_allocated
self->allocated = new_allocated;
return 0;
}
我们来刚才说,python中的list申请容量是按照new_allocated = (size_t)newsize + (newsize >> 3) + (newsize < 9 ? 3 : 6)这样的规则来的,我们来看看。
allocated = 0
print(allocated, end=" ")
for size in range(100):
if allocated < size:
allocated = size + (size >> 3) + (3 if size < 9 else 6)
print(allocated, end=" ") # 0 4 8 16 25 35 46 58 72 88 106
我们具体来计算一下。
l = []
allocated = 0
print(allocated, end=" ")
for _ in range(100):
l.append(_)
if len(l) > allocated:
# 从变量名也能看出,这获取的是容量,但是为什么要除以8呢?
# 因为[]里面的每一个元素占8个字节啊,咦,那列表里面存"xx" * 1000,这也占8个字节?
# 没错,是的,关于为什么我们会后面说。
# 同时这也引出了一个问题:为什么python中list对象在支持存储不同类型数据的前提下,还能保证查询的时间复杂度是O(1)呢?
# 先保留这些疑问,后面会解答
allocated = (l.__sizeof__() - [].__sizeof__()) // 8
print(allocated, end=" ") # 0 4 8 16 25 35 46 58 72 88 106
可以看到我们计算的结果和官方源码给的是一样的,其实这是废话,python解释器就是按照官方源码写的。但还有一个特殊情况:
l = [1, 2, 3, 4, 5]
print((l.__sizeof__() - [].__sizeof__()) // 8) # 5
"""
结果是5,我们在之前的结果并没有看见5啊。这是因为对于初始化一个列表时,有多少元素,容量就是多少,此时allocated和ob_size是相等的
"""
l.append(6)
"""
什么时候会扩容呢?是当我们往列表进行append的时候,解释器发现容量不够。
比如此时上面的ob_size和allocated都是5,但是当append一个6的时候,解释器发现容量不够了
ob_size已经超过allocated了,于是才会扩容。按照 newsize + (newsize >> 3) + (if newsize < 9 ? 3 : 6)
"""
# 此时扩容的结果就是9,尽管里面只存储的了6个元素,但是人家内存已经分配了
# 所以计算的就是9个元素的内存,那么除以8,得到的就是9,即分配的内存能够容纳9个元素
print((l.__sizeof__() - [].__sizeof__()) // 8) # 9
在这里还想问一句,对于初始化一个列表,你认为l = []和l = list()哪个速度更快呢?首先这两者你print之后得到的都是一个[]
答案是l = []更快,因为python中的list在C语言的层面可以看做是allocated-array:过分配数组,直接使用的是底层C语言的数据结构。而l = list()相当于是python层面上的一个函数调用,既然调用肯定要创建栈帧、记录函数参数等等,会进行额外的资源消耗。
为什么list通过索引查找元素的时间复杂度是O(1)
我们之前说了,其实不说大家也知道,python里面列表通过索引定位元素的时间复杂度是O(1),可是列表里面存放的元素大小不一,是怎么做到的呢?还记的我们之前说,列表里面存储的元素都占8个字节吗?我们再来验证一下。
import sys
l = ["a" * 1000, "b" * 1000]
print(sys.getsizeof(l) - sys.getsizeof([])) # 16
print(sys.getsizeof(l[0]) - sys.getsizeof("")) # 1000
"""
由于python中的对象除了值本身,还有其他的信息
比如引用计数、ob_size等等,这些都是要占内存的。
我们把这些值减掉,比如列表的话减去一个[],字符串减去一个"",
把共同具有的那些特征那么所占的内存去掉,那么剩下来的就是值本身占的内存
"""
可以看到,加上本身的信息,l[0]占了不止1000个字节,同理l[1]也是,但是我们计算列表的时候,发现里面的值只占了16个字节,说明每一个值占了8个字节。其实任何一个对象存在列表里面都是8个字节,而我们看PyListObject的定义,里面有一个PyObject **ob_item,因此很容易猜到,python的list里面存储的实际上是指针。其实这个ob_item是一个指向指针数组的指针,这个指针指向了指针数组的首地址。因此我们可以看到,python的list、tuple,实际是哪个都是采用了元素外置的方法,元素的实际的值都存储在堆上,至于列表本身,存储的不过是这些元素的内存指针。不管你值本身占的内存有多大,但是内存地址是固定的,在64位机器上是8个字节。通过索引可以瞬间计算出指针的偏移量,从而找到对应元素的指针,打印的时候会自动打印指针所指向的内存。索引我们使用id(l[0])查看第一个元素的内存地址时,会打印一串数字,也就是内存地址,但是实际上l[0]在python的底层中,存储的就是地址。我们打印的时候,打印的也是指针,只不过我们没有权限操作指针,能有权限操作指针的只有解释器,因此当我们打印会自动打印指针的指向内存,我们可以认为尽管存储的是指针,但是最终操作的都是指针指向的内存。
4.2 PyListObject对象的创建与维护
4.2.1 创建对象
为了创建一个列表,python底层只提供了唯一的一条途径--PyList_New。这个函数接收一个size参数,从而允许我们在创建一个PyListObject对象时指定元素个数。这里仅仅是指定了元素个数,却没有指定元素是什么,我们来看看创建PyListObject对象的过程
PyObject *
PyList_New(Py_ssize_t size)
{
//声明一个PyListObject *对象
PyListObject *op;
#ifdef SHOW_ALLOC_COUNT
static int initialized = 0;
if (!initialized) {
Py_AtExit(show_alloc);
initialized = 1;
}
#endif
//如果size小于0,直接抛异常
if (size < 0) {
PyErr_BadInternalCall();
return NULL;
}
//缓冲池是否可用,如果可用
if (numfree) {
//直接使用缓冲池的空间
numfree--;
op = free_list[numfree];
_Py_NewReference((PyObject *)op);
#ifdef SHOW_ALLOC_COUNT
count_reuse++;
#endif
} else {
//不可用的时候,申请内存
op = PyObject_GC_New(PyListObject, &PyList_Type);
if (op == NULL)
return NULL;
#ifdef SHOW_ALLOC_COUNT
count_alloc++;
#endif
}
//如果size小于0,ob_item设置为NULL
if (size <= 0)
op->ob_item = NULL;
else {
//否则的话,为维护的列表申请空间
op->ob_item = (PyObject **) PyMem_Calloc(size, sizeof(PyObject *));
if (op->ob_item == NULL) {
Py_DECREF(op);
return PyErr_NoMemory();
}
}
//设置ob_size和allocated,然后返回op
Py_SIZE(op) = size;
op->allocated = size;
_PyObject_GC_TRACK(op);
return (PyObject *) op;
}
通过源码我们可以看到,python在创建列表的时候,底层实际上是分为两部分的,一部分是创建PyListObject对象,另一部分是PyListObject对象所维护的列表,这是两块分离的内存,它们通过ob_item建立了联系。咦,有人会问,维护的列表不是PyListObject结构体的一个属性吗?是的,在这里PyListObject指的是不包含其维护列表的PyListObject,当然有时我们也用PyListObject专门只指其维护的列表、或者我们有时也说PyListObject所维护的列表等等,这些说法不用刻意区分,通过上下文是可以理解的。
我们注意到源码里面有一个缓冲池,是的,创建PyListObject对象时,会先检测缓冲池free_lists里面是否有可用的对象,有的话直接拿来用,否则通过malloc在系统堆上申请。缓冲池中最多维护80个PyListObject对象。
/* Empty list reuse scheme to save calls to malloc and free */
#ifndef PyList_MAXFREELIST
#define PyList_MAXFREELIST 80
#endif
static PyListObject *free_list[PyList_MAXFREELIST];
static void
list_dealloc(PyListObject *op)
{
Py_ssize_t i;
PyObject_GC_UnTrack(op);
Py_TRASHCAN_SAFE_BEGIN(op)
if (op->ob_item != NULL) {
/* Do it backwards, for Christian Tismer.
There's a simple test case where somehow this reduces
thrashing when a *very* large list is created and
immediately deleted. */
i = Py_SIZE(op);
//释放list中的每一个元素
while (--i >= 0) {
Py_XDECREF(op->ob_item[i]);
}
PyMem_FREE(op->ob_item);
}
//然后判断缓冲池里面PyListObject对象的个数,如果没满,就添加到缓冲池,
if (numfree < PyList_MAXFREELIST && PyList_CheckExact(op))
free_list[numfree++] = op;
else
Py_TYPE(op)->tp_free((PyObject *)op);
Py_TRASHCAN_SAFE_END(op)
}
4.2.2 添加元素
在第一个PyListObject创建时,显然numfree是0,不会走缓冲池,而是直接在堆上申请,假设我们申请创建有6个元素的PyListObject对象,那么会调用PyList_New(6)来创建PyListObject对象,在对象完成之后,第一个PyListObject对象就完成了。
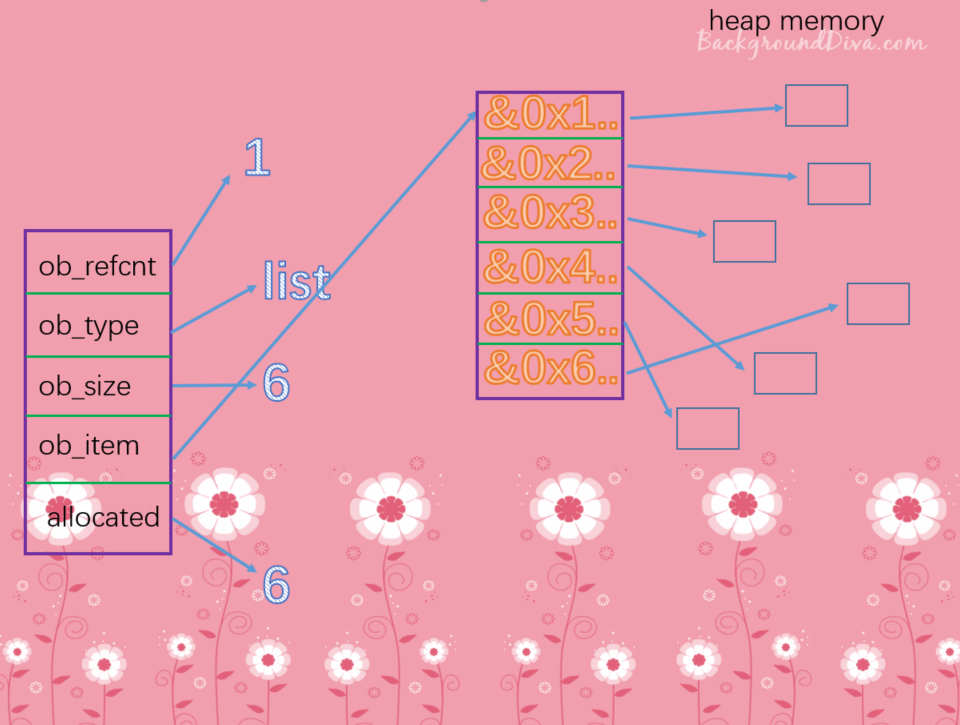
通过上图,我们可以抛出一个问题。
import pandas as pd
# 具有6个元素的列表
l = [1, "xx", int, {}, pd, ()]
print(l.__sizeof__()) # 88
print([].__sizeof__()) # 40
"""
两者相减得到48,6个元素,每个指针正好8字节。
"""
我们看到元素外置、存储指针,6个元素总共用了48个字节,但是剩下的40个字节是哪来的。还记得吗?python中的对象在底层都是一个结构体实例,我们计算的可以不仅仅是维护的值,还有其他的信息啊。首先从图中可以看出,ob_refcnt:引用计数,占八个字节、ob_type:PyTypeObject对象的一个指针,八个字节、ob_size:容纳元素的个数,八个字节、ob_item:这是一个二级指针,指向了指针数组的指针,八个字节、allocated:容量,八个字节,正好40个字节,再加上ob_item指向的指针数组里面有6和元素,再加上6*8=48,正好88个字节。
然后我们看看PyListObject对象是如何设置元素的。
int
PyList_SetItem(PyObject *op, Py_ssize_t i,
PyObject *newitem)
{ //参数为:PyObject *、索引、值
//一个二级指针
PyObject **p;
//类型检查
if (!PyList_Check(op)) {
Py_XDECREF(newitem);
PyErr_BadInternalCall();
return -1;
}
//索引检查
if (i < 0 || i >= Py_SIZE(op)) {
Py_XDECREF(newitem);
PyErr_SetString(PyExc_IndexError,
"list assignment index out of range");
return -1;
}
//ob_item表示数组的首地址
//ob_item + i直接获取数组中索引为i的元素的指针
//当然数组里面存储的本身也是一个指针,所以这里的p是一个二级指针
p = ((PyListObject *)op) -> ob_item + i;
//直接将*p,也就是数组中索引为i的指针(一级)指向的元素设置为newitem
Py_XSETREF(*p, newitem);
return 0;
}
假设我们设置l[2]=100的话,那么
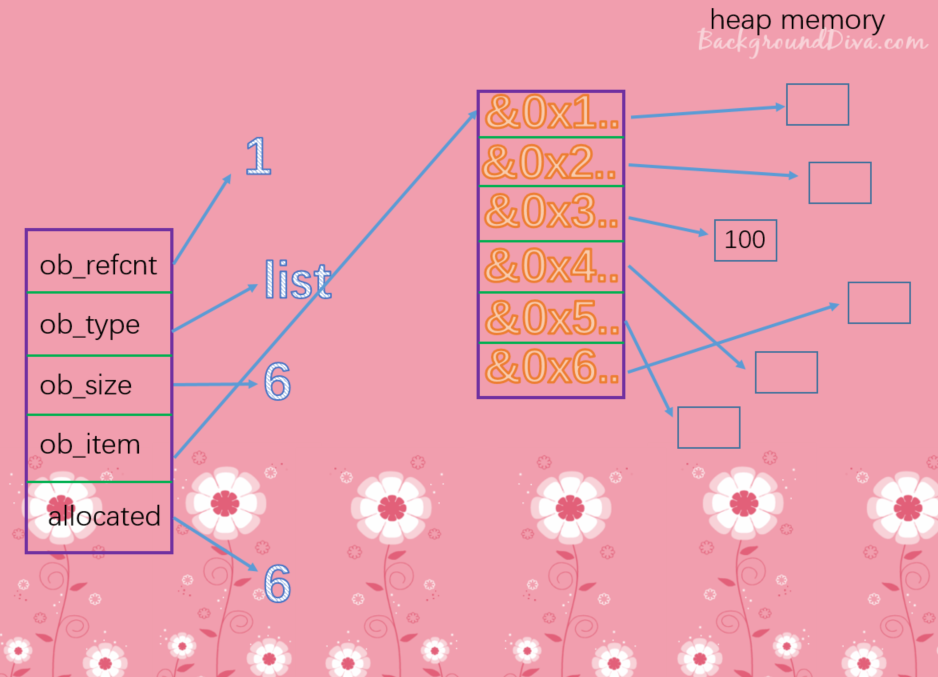
4.2.3 插入元素
设置元素和和插入元素是不同的,设置元素不会导致ob_item指向的内存发生改变,而插入元素可能会导致ob_item指向的内存发生变化
int
PyList_Insert(PyObject *op, Py_ssize_t where, PyObject *newitem)
{
//类型检查
if (!PyList_Check(op)) {
PyErr_BadInternalCall();
return -1;
}
//底层又调用ins1
return ins1((PyListObject *)op, where, newitem);
}
static int
ins1(PyListObject *self, Py_ssize_t where, PyObject *v)
{
/*参数self:PyListObject *
参数where:索引
参数v:插入的值,这是一个PyObject *指针,因为list里面存的都是指针
*/
//i:后面for循环遍历用的,n则是当前列表的元素个数
Py_ssize_t i, n = Py_SIZE(self);
//指向指针数组的二级指针
PyObject **items;
//如果v是NULL,错误的内部调用
if (v == NULL) {
PyErr_BadInternalCall();
return -1;
}
//列表的元素个数不可能无限增大,一般当你还没创建到PY_SSIZE_T_MAX个对象时
//你内存就已经玩完了,但是python仍然做了检测当达到这个PY_SSIZE_T_MAX时,会报出内存溢出错误
if (n == PY_SSIZE_T_MAX) {
PyErr_SetString(PyExc_OverflowError,
"cannot add more objects to list");
return -1;
}
//调整列表容量,既然要inert,那么就势必要多出一个元素
//这个元素还没有设置进去,但是先把这个坑给留出来
//当然如果容量够的话,是不会扩容的,只有当容量不够的时候才会扩容
if (list_resize(self, n+1) < 0)
return -1;
//确定插入点
//这里可以看到如果where小于0,那么我们就加上n,也就是当前列表的元素个数
//比如有6个元素,那么我们where=-1,加上6,就是5,显然就是insert在最后一个索引的位置上
if (where < 0) {
where += n;
//如果吃撑了,写个-100,加上元素的个数还是小于0
if (where < 0)
//那么where=0,就在开头插入
where = 0;
}
//如果where > n,那么就索引为n的位置插入,
//可元素个数为n,最大索引是n-1啊,对,所以此时就相当于append
if (where > n)
where = n;
//拿到原来的二级指针,指向一个指针数组
items = self->ob_item;
//然后让不断遍历,把索引为i的值赋值给索引为i+1,既然是在where处插入
//那么where之前的就不需要动了,到where处就停止了
for (i = n; --i >= where; )
items[i+1] = items[i];
//增加引用计数,因为它作为列表的一个元素了
Py_INCREF(v);
//将where处的值设置成v,还记得这个v吗?对,没错,这是一个PyObject *指针
//打印的话,会打印*v
items[where] = v;
return 0;
}
所以可以看到,python插入数据是非常灵活的。不管你在什么位置插入,都是合法的。因为它会自己调整位置,在确定位置之后,会将当前位置以及之后的所有元素向后挪动一个位置,空出来的地方设置为插入的值。因此熟悉C++的话,会发现这和vector是非常类似的,但是和C++中的list确实大相径庭的,尽管名字一样。
既然插入元素,那么自然少不了append直接往尾部追加元素了。这个就比较简单了,就相当于insert的where>n,直接将索引为n的地方设置为append的值即可。这里就不看源码了,比较简单。只是如果容量够的话,是不需要重新分配空间的。
4.2.4 删除元素
删除元素,对于python的列表来说,直接调用l.remove即可
l = [1, 1, 2, 3]
l.remove(1)
print(l) # [1, 2, 3]
# 会自动删除第一个出现的元素
那么底层是如何实现的呢?
static PyObject *
list_remove(PyListObject *self, PyObject *value)
{
//删除值,对于底层来说,就是删除数组中值对应的指针。
//所以value仍然是PyObject *类型
//i,for循环遍历用的
Py_ssize_t i;
//从0开始,直到不小于ob_size
for (i = 0; i < Py_SIZE(self); i++) {
//将指针数组里面的每一个元素和value进行比较
int cmp = PyObject_RichCompareBool(self->ob_item[i], value, Py_EQ);
//如果cmp大于0,表示元素和value匹配
if (cmp > 0) {
//调用list_ass_slice将其删除
if (list_ass_slice(self, i, i+1,
(PyObject *)NULL) == 0)
Py_RETURN_NONE;
return NULL;
}
else if (cmp < 0)
return NULL;
}
//否则报错,x不再list中。
PyErr_SetString(PyExc_ValueError, "list.remove(x): x not in list");
return NULL;
}
//另外这个list_ass_slice其实起到的是替换的作用,只不过也可以充当删除
//从源码中可以看出把i: i+1部分的元素给删了
/*
l = [1, 2, 3, 4]
l[0: 1] = []
print(l) # [2, 3, 4]
*/
既然是删除,那么和insert一样。全局都会进行移动,比如我把第一个元素删了,那么第二个元素要顶在第一个元素的位置,第n个元素要顶在第n-1个元素的位置上。
4.3 PyListObject对象缓冲池
还记的我们之前说的缓冲池free_lists吗?是用来缓冲PyListObject对象的,但是现在问题来了,这些缓冲的PyListObject对象从哪里获取的呢?或者说是何时创建的呢?答案其实一开始就说了,是在一个PyListObject对象销毁的时候创建的。
static void
list_dealloc(PyListObject *op)
{
//遍历用的
Py_ssize_t i;
PyObject_GC_UnTrack(op);
Py_TRASHCAN_SAFE_BEGIN(op)
//改变每一个元素的引用计数
//销毁PyListObject对象维护的元素列表
if (op->ob_item != NULL) {
/* Do it backwards, for Christian Tismer.
There's a simple test case where somehow this reduces
thrashing when a *very* large list is created and
immediately deleted. */
i = Py_SIZE(op);
while (--i >= 0) {
Py_XDECREF(op->ob_item[i]);
}
PyMem_FREE(op->ob_item);
}
//如果缓冲池未满,那么放回到缓冲池当中
if (numfree < PyList_MAXFREELIST && PyList_CheckExact(op))
free_list[numfree++] = op;
else
Py_TYPE(op)->tp_free((PyObject *)op);
Py_TRASHCAN_SAFE_END(op)
}
我们知道在创建一个新的PyListObject对象时,实际上是分为两步的,先创建PyListObject,然后创建其维护的元素列表。同理,在销毁一个PyListObject对象时,先销毁销毁维护的元素列表,然后再释放PyListObject对象自身
现在可以很清晰地明白了,原本空荡荡的缓冲池其实是被已经死去的PyListObject对象填充了,在以后创建新的PyListObject对象时,python会首先唤醒这些死去的PyListObject对象,给它们一个洗心革面、重新做人的机会。但注意的是,这里的缓冲仅仅是PyListObject对象,对于其维护的列表,已经不再指向了,引用减少,那么这些元素就大难临头各自飞了,或生存、或毁灭,不再被对应的PyListObject的那个指针所束缚。但是为什么要这么做呢?可以想一下,如果继续维护的,那么很可能会产生悬空指针的问题,因此这些元素所占的空间必须交还给系统(前提是没有指针指向了)
但是实际上,是可以将PyListObject对象维护的元素列表保留的,即只调整引用计数,并将元素都设置为NULL,但是并不释放内存空间。因此这样一来,释放的内存不会交给系统堆,那么再次分配的时候,速度会快很多。但是这样带一个问题就是,这些内存没人用也会一直占着,并且只能供PyListObject对象使用,因此python还是为避免消耗过多内存,采取将元素列表的内存交换给了系统堆这样的做法,在时间和空间上选择了空间。
我们之前的PyListObject对象的示意图,如果在缓冲池当中应该变成什么样子呢?

在下一次创建新的list对象时,这个PyListObject对象将会被重新唤醒,重新分配元素列表所占的内存,重新拥抱新的元素列表。正如我,就喜欢纸片人,不停地换老婆,每当出现新的动漫,就会拥抱新的纸片人。
《python解释器源码剖析》第4章--python中的list对象的更多相关文章
- 《python解释器源码剖析》第13章--python虚拟机中的类机制
13.0 序 这一章我们就来看看python中类是怎么实现的,我们知道C不是一个面向对象语言,而python却是一个面向对象的语言,那么在python的底层,是如何使用C来支持python实现面向对象 ...
- 《python解释器源码剖析》第12章--python虚拟机中的函数机制
12.0 序 函数是任何一门编程语言都具备的基本元素,它可以将多个动作组合起来,一个函数代表了一系列的动作.当然在调用函数时,会干什么来着.对,要在运行时栈中创建栈帧,用于函数的执行. 在python ...
- 《python解释器源码剖析》第9章--python虚拟机框架
9.0 序 下面我们就来剖析python运行字节码的原理,我们知道python虚拟机是python的核心,在源代码被编译成字节码序列之后,就将有python的虚拟机接手整个工作.python虚拟机会从 ...
- 《python解释器源码剖析》第0章--python的架构与编译python
本系列是以陈儒先生的<python源码剖析>为学习素材,所记录的学习内容.不同的是陈儒先生的<python源码剖析>所剖析的是python2.5,本系列对应的是python3. ...
- 《python解释器源码剖析》第1章--python对象初探
1.0 序 对象是python中最核心的一个概念,在python的世界中,一切都是对象,整数.字符串.甚至类型.整数类型.字符串类型,都是对象.换句话说,python中面向对象的理念观测的非常彻底,面 ...
- 《python解释器源码剖析》第11章--python虚拟机中的控制流
11.0 序 在上一章中,我们剖析了python虚拟机中的一般表达式的实现.在剖析一遍表达式是我们的流程都是从上往下顺序执行的,在执行的过程中没有任何变化.但是显然这是不够的,因为怎么能没有流程控制呢 ...
- 《python解释器源码剖析》第8章--python的字节码与pyc文件
8.0 序 我们日常会写各种各样的python脚本,在运行的时候只需要输入python xxx.py程序就执行了.那么问题就来了,一个py文件是如何被python变成一系列的机器指令并执行的呢? 8. ...
- 《python解释器源码剖析》第7章--python中的set对象
7.0 序 集合和字典一样,都是性能非常高效的数据结构,性能高效的原因就在于底层使用了哈希表.因此集合和字典的原理本质上是一样的,都是把值映射成索引,通过索引去查找. 7.1 PySetObject ...
- 《python解释器源码剖析》第2章--python中的int对象
2.0 序 在所有的python内建对象中,整数对象是最简单的对象.从对python对象机制的剖析来看,整数对象是一个非常好的切入点.那么下面就开始剖析整数对象的实现机制 2.1 初识PyLongOb ...
随机推荐
- 【并行计算-CUDA开发】GPU---并行计算利器
1 GPU是什么 如图1所示,这台PC机与普通PC机不同的是这里插了7张显卡,左下角是显卡,在中间的就是GPU芯片.显卡的处理器称为图形处理器(GPU),它是显卡的"心脏",与CP ...
- C学习笔记-多源文件的编译
多源文件的意义 为了精简代码和更好的维护代码,往往需要将一些功能实现的代码与主函数代码分开来 在使用的时候再主函数中调用 多源文件的使用 假设现有my.c和main.c两个源代码文件,现在要再main ...
- Java垃圾收集算法1
Java垃圾收集算法 由于垃圾收集算法的实现涉及大量的程序细节,而且每个平台的虚拟机操作内存的方法又各不相同,因此博客中不过多的讨论算法的实现,只是介绍几种算法的思想以及发展. 相关阅读: 1.深入理 ...
- layui checkbox , radio 清除所有选中项
方法: $(selector).prop('cjecked', false); form.render(); 使用示例: // 清除radio选中 $('input[name=ymd]').prop( ...
- nginx 增加认证
1.检查工具是否安装,如果未安装则使用yum安装 #htpasswd 有以上输出表示已经安装,如果没有按装,使用如下命令安装: #yum -y install httpd-tools 2.htpass ...
- (5.15)mysql高可用系列——MHA实践
关键词:MHA,mysql mha [1]需求 采用mysql技术,实现MHA高可用主从环境,预计未来数据量几百G MHA概念参考:MYSQL高可用技术概述 [2]环境技术架构 [2.1]MHA简介 ...
- 【转帖】Office的光荣历史(2)
Office的光荣历史(2) https://www.sohu.com/a/201411215_657550 2017-10-31 10:57 7.MS Office 2000 (Office 9.0 ...
- 【LOJ】#3087. 「GXOI / GZOI2019」旅行者
LOJ#3087. 「GXOI / GZOI2019」旅行者 正着求一遍dij,反着求一遍,然后枚举每条边,从u到v,如果到u最近的点和v能到的最近的点不同,那么可以更新答案 没了 #include ...
- Codeforces Round #586 (Div. 1 + Div. 2) D.Alex and Julian 简单证明
题意:在序列中删除最少元素使得得到的图是二分图. 其中点是整数域的点. 比如b1=2 那么a可以连b当且仅当|a-b|=2 同时这里的a,b是任意整数. 怎样判定一个序列是否合法呢?于是想到了二分 ...
- php 正则替换特殊字符 和检测是否是中文
如果是只想输入中文的话,就这么写,要注意是分gb2312和utf-8的哦: gb2312:if(!preg_match("/^[".chr(0xa1)."-". ...