kafka 介绍与使用
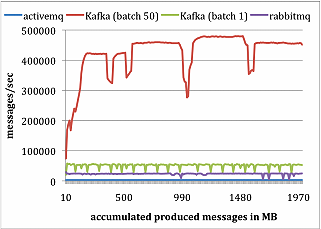
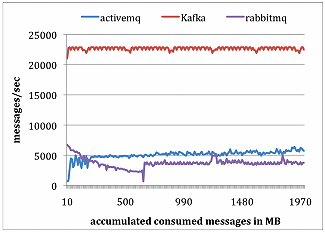
原文:https://blog.csdn.net/SJF0115/article/details/78480433
kafka 介绍与使用的更多相关文章
- Apache Kafka - 介绍
原文地址地址: http://blogxinxiucan.sh1.newtouch.com/2017/07/12/Apache-Kafka-介绍/ Apache Kafka教程 之 Apache Ka ...
- 1、Kafka介绍
1.Kafka介绍 1)在流式计算中,Kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算. 2)Kafka是一个分布式消息队列. 3)Kafka对消息保存时根据Topic进行归类, ...
- [转]kafka介绍
转自 https://www.cnblogs.com/hei12138/p/7805475.html kafka介绍 1.1. 主要功能 根据官网的介绍,ApacheKafka®是一个分布式流媒体平台 ...
- Kafka介绍及安装部署
本节内容: 消息中间件 消息中间件特点 消息中间件的传递模型 Kafka介绍 安装部署Kafka集群 安装Yahoo kafka manager kafka-manager添加kafka cluste ...
- kafka介绍与搭建(单机版)
一.kafka介绍 1.1 主要功能 根据官网的介绍,ApacheKafka®是一个分布式流媒体平台,它主要有3种功能: 1:It lets you publish and subscribe to ...
- kafka介绍及安装配置(windows)
Kafka介绍 Kafka是分布式的发布—订阅消息系统.它最初由LinkedIn(领英)公司发布,使用Scala和Java语言编写,与2010年12月份开源,成为Apache的顶级项目.Kafka是一 ...
- 一、kafka 介绍 && kafka-client
一.kafka 介绍 1.1.kafka 介绍 Kafka 是一个分布式消息引擎与流处理平台,经常用做企业的消息总线.实时数据管道,有的还把它当做存储系统来使用. 早期 Kafka 的定位是一个高吞吐 ...
- 3 kafka介绍
本博文的主要内容有 .kafka的官网介绍 http://kafka.apache.org/ 来,用官网上的教程,快速入门. http://kafka.apache.org/documentatio ...
- Kafka介绍
本文介绍LinkedIn开源的Kafka,久仰大名了,依照其官方文档做些翻译和二次创作.相应能够查看整份官方文档. 基本术语 topics,维护的消息源种类(更像是业务上的数据种类/分类) produ ...
- 漫游Kafka介绍章节简介
原文地址:http://blog.csdn.net/honglei915/article/details/37564521 介绍 Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了普通消息 ...
随机推荐
- (八)shiro之jdbcRealm
pom.xml <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w ...
- C#操作DOS命令,并获取处理返回值
// /*---------------- // // 文件名:Method // // 文件功能描述: // // 使用 ADB 来进行安卓设备与PC端之间的文件交互,具体adb命令操作请百度 ...
- SqlServer 多服务器管理配置报错:Ensure the agent startup account for 'x.x.x.x' has rights to login as target server, Access is denied.
SQL Server 2012配置多服务器管理时,SSMS设置一直报错,配置失败: 解决方法: 1. 为SQL Server Agent单独创建一个账号,主服务器和目标服务器都创建一样的账号 2. 把 ...
- VS App_Code文件夹下的类文件不能直接被调用的解决方法
如下图所示,新建的类不能直接使用,会显示报错,检查命名空间什么的,未果 通过百度搜索,发现这么一篇文章:https://blog.csdn.net/younghaiqing/article/detai ...
- sftp配置多个用户权限的问题
groupadd group1 chmod 0755 /test/useradd -g group1 -d /test/backend/ -M test_backendusermod -s /sbin ...
- vue+scss动态改变主题颜色
1.新建.scss后缀公用文件,放在assets或者其他地方都可以 /*需要切换的颜色变量*/ $color-primary1:#1776E1; /* 更换的颜色 */ $color-primary2 ...
- Java 之 Collections 工具类
一.Collections 概述 java.utils.Collections 是集合工具类,用来对集合进行操作. 二.常用方法 public static <T> boolean add ...
- 串口工具kermit(ubuntu)
安装 # sudo apt-get install ckermit 配置 kermit启动时,会首先查找~/.kermrc,然后再遍历/etc/kermit/kermrc # vi /etc/kerm ...
- Input system (输入子系统)
Input system (输入子系统) 以前写一些输入设备(键盘,鼠标等)的驱动都是字符设备,混杂设备处理的,linux开源社区的大神门看到了这大量的输入设备如此分散不堪,就想有木有一种机制,可以对 ...
- http上传txt文件
http通过post方式上传txt文件 可以参考 https://www.cnblogs.com/s0611163/p/4071210.html /// <summary> /// Htt ...