如何丧心病狂的使用python爬虫读小说

写在前边
其实一直想入门python很久了,慕课网啊,菜鸟教程啊python的基础的知识被我翻了很多遍了,但是一直没有什么实践。刚好,这两天被别人一直安利一本小说《我可能修的是假仙》,还在连载中的,我等屌丝,打钱是不可能打钱的,只好先去网上找一下资源了,基本笔趣阁啊,什么的提供很多在线的资源给我们。好吧,就看这个就行了,可是看也看得不爽啊,,浏览器上下部分都被什么 美女荷官在线发牌,一夜不射提升半小时之类你懂的画面遮盖了,还经常误触,如果是在电脑上看,我们可以用ADBLOCK之类的广告插件屏蔽,可是手机浏览器貌似没有插件啊,那怎么办呢?我可是程序员啊,程序员怎么能向这种问题低头呢?
解决方案
我们把在线网页上的章节名和章节内容都保存下来,造一个离线的版本不就没这个问题了么?
那怎么保存呢,这就需要我们的主角出场了,铛铛铛,python scrapy爬虫框架
关于scrapy
向大家推荐 一个好玩的有趣的牛逼的网站**scrapy中文教程**
这个作者写的很有趣,摘录一下:
本scrapy文档,主要是给诸君介绍一下神马是scrapy,scrapy能干神马,提提大伙的学习热情!scrapy是一个网页爬虫框架,神马叫做爬虫,如果没听说过,那就:内事不知问度娘,外事不决问谷歌,百度或谷歌一下吧!……(这里的省略号代表scrapy很牛逼,基本神马都能爬,包括你喜欢的苍老师……这里就不翻译了)
爬虫代码
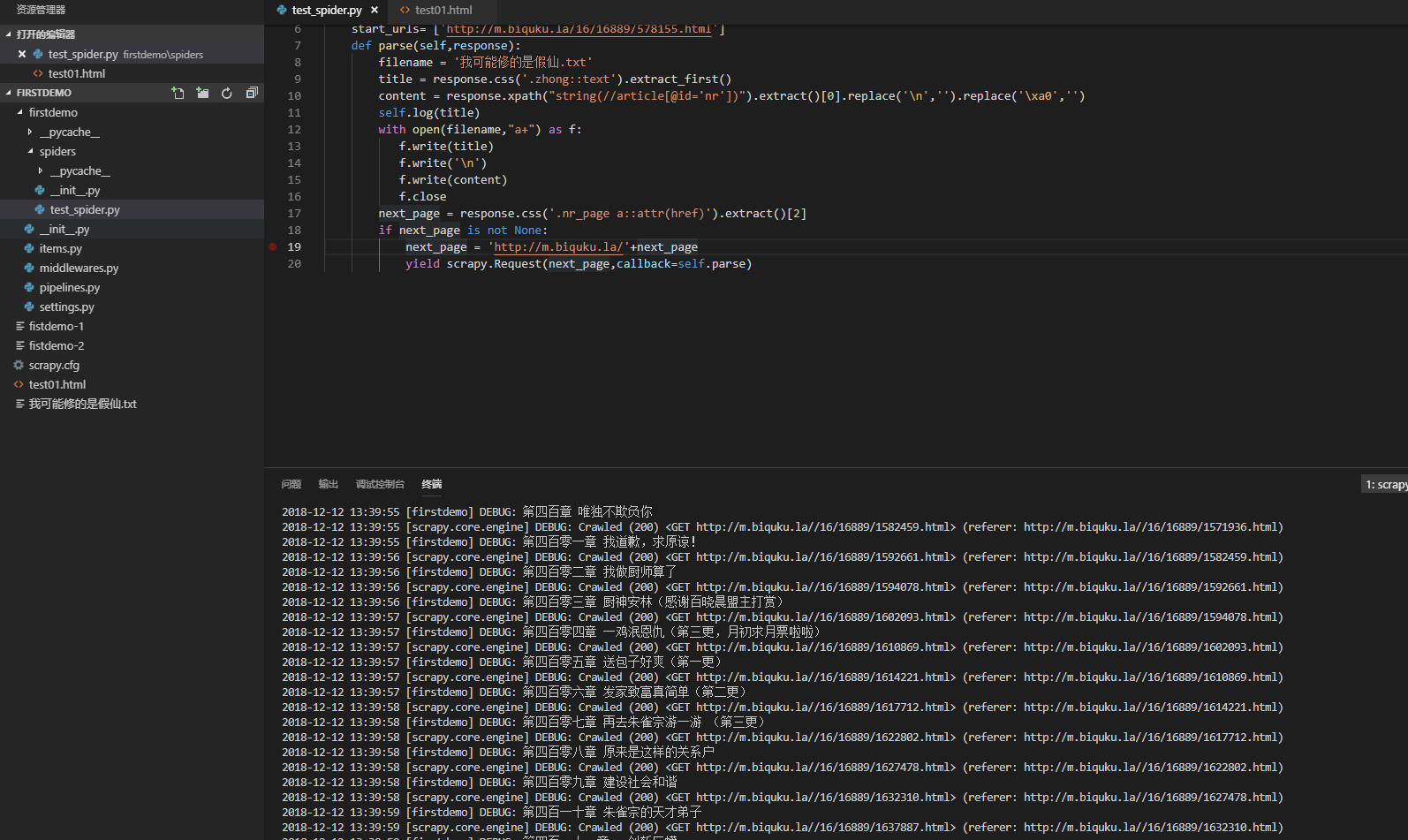
import scrapy
class firstdemo(scrapy.Spider):
# 爬虫名称
name = 'firstdemo'
# 第一页
start_urls= ['http://m.biquku.la/16/16889/578155.html']
def parse(self,response):
filename = '我可能修的是假仙.txt'
# 章节名
title = response.css('.zhong::text').extract_first()
# 章节内容
content = response.xpath("string(//article[@id='nr'])").extract()[0].replace('\n','').replace('\xa0','')
self.log(title)
with open(filename,"a+",encoding='utf-8') as f:
f.write(title)
# 添加章节目录
f.write('\n')
# 添加换行(\n)是为了让txt阅读器识别章节目录
f.write(content)
f.write('\n')
f.close
next_page = response.css('.nr_page a::attr(href)').extract()[2]
if next_page is not None:
next_page = 'http://m.biquku.la'+next_page
yield scrapy.Request(next_page,callback=self.parse)
else:
self.log('已到最终章节')
没想到吧,代码就这么多,具体的教程可以参见向大家推荐的那个网站。最后我们执行scrapy crawl firstdemo就开始爬取了。
最后
最后?哪里有什么最后?都下载下来了,还不抓紧去看一下我们的战斗成果?
当然还是要提醒诸位,学习为主,不要玩物丧志。
如何丧心病狂的使用python爬虫读小说的更多相关文章
- python爬虫之小说网站--下载小说(正则表达式)
python爬虫之小说网站--下载小说(正则表达式) 思路: 1.找到要下载的小说首页,打开网页源代码进行分析(例:https://www.kanunu8.com/files/old/2011/244 ...
- Python爬虫-爬小说
用途 用来爬小说网站的小说默认是这本御天邪神,虽然我并没有看小说,但是丝毫不妨碍我用爬虫来爬小说啊. 如果下载不到txt,那不如自己把txt爬下来好了. 功能 将小说取回,去除HTML标签 记录已爬过 ...
- Python爬虫中文小说网点查找小说并且保存到txt(含中文乱码处理方法)
从某些网站看小说的时候经常出现垃圾广告,一气之下写个爬虫,把小说链接抓取下来保存到txt,用requests_html全部搞定,代码简单,容易上手. 中间遇到最大的问题就是编码问题,第一抓取下来的小说 ...
- 使用Python爬虫整理小说网资源-自学
第一次接触python,原本C语言的习惯使得我还不是很适应python的语法风格.希望读者能够给出建议. 相关的入门指导来自以下的网址:https://blog.csdn.net/c406495762 ...
- python爬虫之小说爬取
废话不多说,直接进入正题. 今天我要爬取的网站是起点中文网,内容是一部小说. 首先是引入库 from urllib.request import urlopen from bs4 import Bea ...
- python爬虫爬小说网站涉及到(js加密,CSS加密)
我是对于xxxx小说网进行爬取只讲思路不展示代码请见谅 一.涉及到的反爬 js加密 css加密 请求头中的User-Agent以及 cookie 二.思路 1.对于js加密 对于有js加密信息,我们一 ...
- python|爬虫东宫小说
2k小说网爬取最近大火的<东宫>小说,借鉴之前看过的一段代码,修改之后,进行简单爬取. from urllib import requestfrom bs4 import Beautifu ...
- python爬虫下载小说
1. from urllib.request import urlopen from urllib import request from bs4 import BeautifulSoup from ...
- 批量下载小说网站上的小说(python爬虫)
随便说点什么 因为在学python,所有自然而然的就掉进了爬虫这个坑里,好吧,主要是因为我觉得爬虫比较酷,才入坑的. 想想看,你可以批量自动的采集互联网上海量的资料数据,是多么令人激动啊! 所以我就被 ...
随机推荐
- Templates/Code Combinations
Queries: Templates/Code Combinations sql>select * from gl_dynamic_summ_combinations where CODE_ ...
- hadoop之yarn详解(命令篇)
本篇主要对yarn命令进行阐述 一.yarn命令概述 [root@lgh ~]# yarn -help Usage: yarn [--config confdir] COMMAND where COM ...
- 清除keil编译中间文件的脚本
清除keil编译生成的中间文件,减小项目体积. keykill.bat del *.bak /s del *.ddk /s del *.edk /s del *.lst /s del *.lnp /s ...
- CentOS 7 根目录分区扩容
查看现有磁盘信息,可以看出根分区有96G [root@localhost ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/mappe ...
- linux iptables理论学习
近来回顾系统知识,想写个基于iptables安全防御的脚本,实现系统自动防护. 参考文档:http://blog.chinaunix.net/uid-26495963-id-3279216.html ...
- 两个linux服务器之间免密登录
服务器A(假设为10.64.104.11) 免密登录服务器B(10.64.104.22) 1.登录服务器A 2.生成公私钥 ssh-keygen -t rsa 3.将生成的.pub文件发送到服务器B上 ...
- 作业十一——LL(1)文法的判断
1. 文法 G(S): (1)S -> AB (2)A ->Da|ε (3)B -> cC (4)C -> aADC |ε (5)D -> b|ε 验证文法 G(S)是不 ...
- tp5 左连接
db('detainform')->alias('d')->join("information i",'i.z_id=d.z_id','LEFT')->where ...
- Java基础 TreeSet()来实现数组的【定制排序】 : Comparable接口(自然排序) 或者 Comparator接口 (定制排序)
笔记: //排序真麻烦!没有C++里的好用又方便!ORZ!ORZ!数组排序还还自己写个TreeSet()和( Comparable接口(自然排序) 或者 Comparator接口 (定制排序))imp ...
- 访问php界面访问不到,会下载文件
背景 某台服务器上有java跟php俩套环境,之前php默认用nginx80端口访问php项目.java项目上线后,80端口被占用,导致php项目页访问报错:404 报错 404, 原因一: ...