HDFS的NameNode与SecondaryNameNode的工作原理
原文:https://blog.51cto.com/xpleaf/2147375
看完之后确实对nameNode的工作更加清晰一些
在Hadoop中,有一些命名不好的模块,Secondary NameNode是其中之一。
从它的名字上看,它给人的感觉就像是NameNode的备份。但它实际上却不是。很多Hadoop的初学者都很疑惑,Secondary NameNode究竟是做什么的,而且它为什么会出现在HDFS中。本文将解释下SecondaryNameNode在HDFS中所扮演的角色。
从它的名字来看,你可能认为它跟NameNode有点关系。没错,你猜对了。因此在我们深入了解SecondaryNameNode之前,我们先来看看NameNode是做什么的。
NameNode
NameNode主要是用来保存HDFS的元数据信息,比如命名空间信息,块信息等。当它运行的时候,这些信息是存在内存中的。但是这些信息也可以持久化到磁盘上。
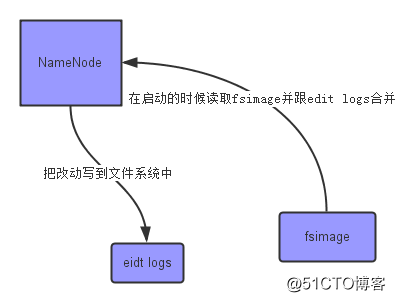
上面的这张图片展示了NameNode怎么把元数据保存到磁盘上的。这里有两个不同的文件:
- fsimage - 它是在NameNode启动时对整个文件系统的快照
- edit logs - 它是在NameNode启动后,对文件系统的改动序列
只有在NameNode重启时,edit logs才会合并到fsimage文件中,从而得到一个文件系统的最新快照。但是在产品集群中NameNode是很少重启的,这也意味着当NameNode运行了很长时间后,edit logs文件会变得很大。在这种情况下就会出现下面一些问题:
- edit logs文件会变的很大,怎么去管理这个文件是一个挑战。
- NameNode的重启会花费很长时间,因为有很多改动[在edit logs中]要合并到fsimage文件上。
- 如果NameNode挂掉了,那我们就丢失了很多改动因为此时的fsimage文件非常旧。[在这个情况下丢失的改动不会很多, 因为丢失的改动应该是还在内存中但是没有写到edit logs的这部分。]
因此为了克服这个问题,我们需要一个易于管理的机制来帮助我们减小edit logs文件的大小和得到一个最新的fsimage文件,这样也会减小在NameNode上的压力。
现在我们明白了NameNode的功能和所面临的挑战 - 保持文件系统最新的元数据。那么,这些跟SecondaryNameNode又有什么关系呢?
[
叶子备注:
那么从上面的分析以及后面的文档可以知道,或者说,很容易产生一个疑问,既然fsimage要在nameNode重启以后才能更新,即便后面有了secondaryNameNode之后也要一定的时间后才会去同步这些文件,那么为什么每次上传一个文件后,就可以马上通过命令行方式获取到这个文件呢,我的元数据信息可是保存在fsimage中的呀!不要忘记了,fsimage和edit的存在只是为了持久化这些数据信息,这意味着,nameNode启动之后,内存当中肯定也是保存着这些信息的,而添加删除文件等操作所产生的信息,肯定也是有保存到nameNode的内存当中的(不然怎么可能马上就读取到这些数据呢),同步fsimage,合并edit,只是为了持久化这些数据,防止nameNode出现异常时元数据信息的丢失。
]
Secondary NameNode
SecondaryNameNode就是来帮助解决上述问题的,它的职责是合并NameNode的edit logs到fsimage文件中。
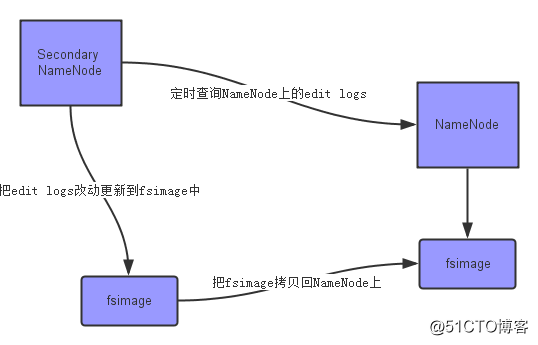
上面的图片展示了SecondaryNameNode是怎么工作的。
首先,它定时到NameNode去获取edit logs,并更新到fsimage上。[Secondary NameNode自己的fsimage]
一旦它有了新的fsimage文件,它将其拷贝回NameNode中。
NameNode在下次重启时会使用这个新的fsimage文件,从而减少重启的时间。
Secondary NameNode的整个目的是在HDFS中提供一个检查点。它只是NameNode的一个助手节点。
现在,我们明白了Secondary NameNode所做的不过是在文件系统中设置一个检查点来帮助NameNode更好的工作。它不是要取代掉NameNode也不是NameNode的备份。所以一般也称呼它为checkpoint node吧。
二者的工作机制
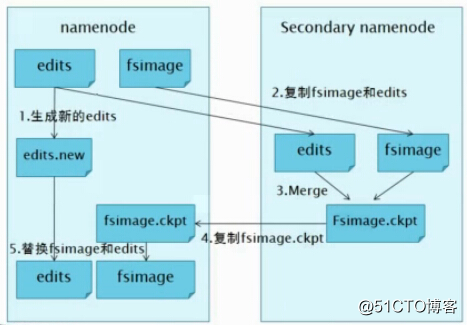
1.NameNode管理着元数据信息,元数据信息会定期的刷到磁盘中,其中的两个文件是edits即操作日志文件和fsimage即元数据镜像文件,新的操作日志不会立即与fsimage进行合并,也不会刷到NameNode的内存中,而是会先写到edits中(因为合并需要消耗大量的资源)。当edits文件的大小达到一个临界值(默认是64MB)或者间隔一段时间(默认是1小时)的时候checkpoint会触发SecondaryNameNode进行工作。
2.当触发一个checkpoint操作时,NameNode会生成一个新的edits即上图中的edits.new文件,同时SecondaryNameNode会将edits文件和fsimage复制到本地。
3.SecondaryNameNode将本地的fsimage文件加载到内存中,然后再与edits文件进行合并生成一个新的fsimage文件即上图中的Fsimage.ckpt文件。
4.SecondaryNameNode将新生成的Fsimage.ckpt文件复制到NameNode节点。
5.在NameNode结点的edits.new文件和Fsimage.ckpt文件会替换掉原来的edits文件和fsimage文件,至此,刚好是一个轮回即在NameNode中又是edits和fsimage文件了。
6.等待下一次checkpoint触发SecondaryNameNode进行工作,一直这样循环操作。
注:checkpoint触发的条件可以在hdfs-site.xml文件中进行配置,如下:
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
<description>
The number of seconds between two periodic checkpoints.
</description>
</property> HDFS的NameNode与SecondaryNameNode的工作原理的更多相关文章
- NameNode与DataNode的工作原理剖析
NameNode与DataNode的工作原理剖析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HDFS写数据流程 >.客户端通过Distributed FileSyst ...
- hadoop平台上HDFS和MAPREDUCE的功能、工作原理和工作过程
作业要求来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319 1.用自己的话阐明Hadoop平台上HDFS和MapReduce ...
- HDFS【Namenode、SecondaryNamenode、Datanode】
目录 一. NameNode和SecondaryNameNode 1.NN和2NN 工作机制 2. NN和2NN中的fsimage.edits分析 3.checkpoint设置 4.namenode故 ...
- NameNode 与 SecondaryNameNode 的工作机制
一.NameNode.Fsimage .Edits 和 SecondaryNameNode 概述 NameNode:在内存中储存 HDFS 文件的元数据信息(目录) 如果节点故障或断电,存在内存中的数 ...
- NameNode和SecondaryNameNode的工作机制
NameNode&Secondary NameNode 工作机制 NameNode: 1.启动时,加载编辑日志和镜像文件到内存 2.当客户端对元数据进行增删改,请求NameNode 3.Nam ...
- Hadoop(9)-HDFS的NameNode和SecondaryNameNode详解
1.NN和2NN工作机制 首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低.因此,元数据需要存放在内存中.但如果只存在内存中,一旦 ...
- HDSF主要节点解说(二)工作原理
HDFS(Hadoop Distributed File System )Hadoop分布式文件系统. 是依据google发表的论文翻版的.论文为GFS(Google File System)Goog ...
- NameNode和SecondaryNameNode工作原理剖析
NameNode和SecondaryNameNode工作原理剖析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.NameNode中的元数据是存储在那里的? 1>.首先,我 ...
- HADOOP1.X中HDFS工作原理
转载自:http://www.daniubiji.cn/archives/596 HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.是根据googl ...
随机推荐
- Jmeter练习
首页 新随笔 管理 Jmeter接口测试实例-牛刀小试 本次测试的是基于HTTP协议的接口,主要是通过Jmeter来完成接口测试,借此熟悉Jmeter的基本操作. 本次实战,我是从网上找的接口 ...
- 更改jupyter notebook的单元格宽度和主题颜色(theme)
一.单元格宽度 这个命令: jt -t gruvboxl -f roboto -fs 12 -cellw 100% -T -N 它将宽度设置为100% 二.主题颜色 在用jupyter noteboo ...
- Beyond Compare 4提示已经过了30天试用期
打开Beyond Compare 4,提示已经超出30天试用期限制,解决方法:1.修改C:\Program Files\Beyond Compare 4\BCUnrar.dll ,这个文件重命名或者直 ...
- ubuntu下编辑文本命令
常见的基于控制台的文本编辑器有以下几种: emacs 综合性的GNU emacs 编辑环境 nano 一个类似于经典的pico的文本编辑器,内置了一个pi ...
- SQLCommand命令、DbTransaction事务
一.SqlDataReader SqlConnection conn = new SqlConnection("server=10.126.64.11;user=it_oper;pwd=IT ...
- springboot2.0入门(七)-- 自定义配置文件+xml配置文件引入
一.加载自定义配置文件: 1.新建一个family.yam文件,将上application.yml对象复制进入family family: family-name: dad: name: levi a ...
- JQuery实践--Ajax
Ajax概览无需刷新用户页面而发起服务器请求的技术.创建一个XHR实例: var xhr if(window.XMLHttpRequest) { xhr = new XML ...
- About IndexDB
http://blog.csdn.net/bd_zengxinxin/article/details/7758317 HTML5 - Storage 客户端存储 http://html5demos.t ...
- [Luogu] 兽径管理
题面:https://www.luogu.org/problemnew/show/P1340 题解:https://www.zybuluo.com/wsndy-xx/note/1153773
- Gym - 101955K Let the Flames Begin 约瑟夫环
Gym - 101955KLet the Flames Begin 说实话,没怎么搞懂,直接挂两博客. 小飞_Xiaofei的约瑟夫问题(Josephus Problem)3:谁最后一个出列 小飞_ ...