ELM:ELM实现鸢尾花种类测试集预测识别正确率(better)结果对比—Jason niu
load iris_data.mat P_train = [];
T_train = [];
P_test = [];
T_test = [];
for i = 1:3
temp_input = features((i-1)*50+1:i*50,:);
temp_output = classes((i-1)*50+1:i*50,:);
n = randperm(50); P_train = [P_train temp_input(n(1:40),:)'];
T_train = [T_train temp_output(n(1:40),:)']; P_test = [P_test temp_input(n(41:50),:)'];
T_test = [T_test temp_output(n(41:50),:)'];
end [IW,B,LW,TF,TYPE] = elmtrain(P_train,T_train,20,'sig',1); T_sim_1 = elmpredict(P_train,IW,B,LW,TF,TYPE);
T_sim_2 = elmpredict(P_test,IW,B,LW,TF,TYPE); result_1 = [T_train' T_sim_1'];
result_2 = [T_test' T_sim_2']; k1 = length(find(T_train == T_sim_1));
n1 = length(T_train);
Accuracy_1 = k1 / n1 * 100;
disp(['训练集正确率Accuracy = ' num2str(Accuracy_1) '%(' num2str(k1) '/' num2str(n1) ')']) k2 = length(find(T_test == T_sim_2));
n2 = length(T_test);
Accuracy_2 = k2 / n2 * 100;
disp(['测试集正确率Accuracy = ' num2str(Accuracy_2) '%(' num2str(k2) '/' num2str(n2) ')']) figure(2)
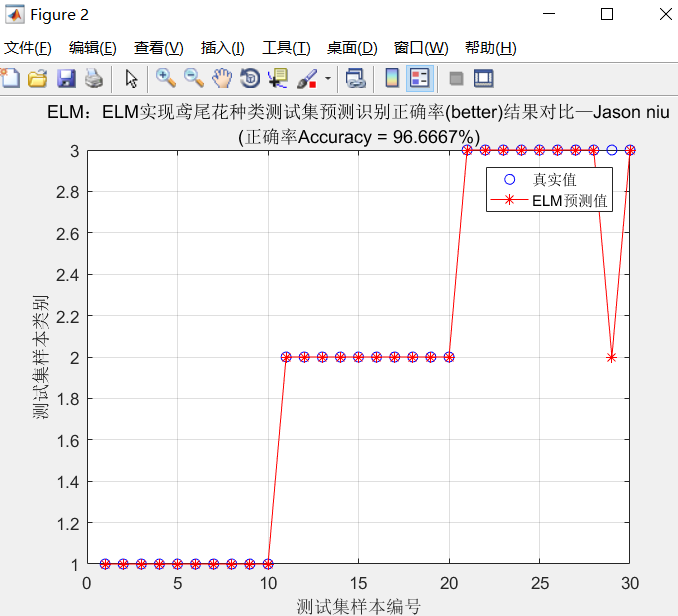
plot(1:30,T_test,'bo',1:30,T_sim_2,'r-*')
grid on
xlabel('测试集样本编号')
ylabel('测试集样本类别')
string = {'ELM:ELM实现鸢尾花种类测试集预测识别正确率(better)结果对比—Jason niu';['(正确率Accuracy = ' num2str(Accuracy_2) '%)' ]};
title(string)
legend('真实值','ELM预测值')
ELM:ELM实现鸢尾花种类测试集预测识别正确率(better)结果对比—Jason niu的更多相关文章
- ELM:ELM基于近红外光谱的汽油测试集辛烷值含量预测结果对比—Jason niu
%ELM:ELM基于近红外光谱的汽油测试集辛烷值含量预测结果对比—Jason niu load spectra_data.mat temp = randperm(size(NIR,1)); P_tra ...
- RBF:RBF基于近红外光谱的汽油辛烷值含量预测结果对比—Jason niu
load spectra_data.mat temp = randperm(size(NIR,1)); P_train = NIR(temp(1:50),:)'; T_train = octane(t ...
- GRNN/PNN:基于GRNN、PNN两神经网络实现并比较鸢尾花种类识别正确率、各个模型运行时间对比—Jason niu
load iris_data.mat P_train = []; T_train = []; P_test = []; T_test = []; for i = 1:3 temp_input = fe ...
- NN:实现BP神经网络的回归拟合,基于近红外光谱的汽油辛烷值含量预测结果对比—Jason niu
load spectra_data.mat plot(NIR') title('Near infrared spectrum curve—Jason niu') temp = randperm(siz ...
- TF之AE:AE实现TF自带数据集数字真实值对比AE先encoder后decoder预测数字的精确对比—Jason niu
import tensorflow as tf import numpy as np import matplotlib.pyplot as plt #Import MNIST data from t ...
- PCA:利用PCA(四个主成分的贡献率就才达100%)降维提高测试集辛烷值含量预测准确度并《测试集辛烷值含量预测结果对比》—Jason niu
load spectra; temp = randperm(size(NIR, 1)); P_train = NIR(temp(1:50),:); T_train = octane(temp(1:50 ...
- Tensorflow&CNN:验证集预测与模型评价
版权声明:本文为博主原创文章,转载 请注明出处:https://blog.csdn.net/sc2079/article/details/90480140 - 写在前面 本科毕业设计终于告一段落了.特 ...
- SVM—PK—BP:SVR(better)和BP两种方法比较且实现建筑物钢筋混凝土抗压强度预测—Jason niu
load concrete_data.mat n = randperm(size(attributes,2)); p_train = attributes(:,n(1:80))'; t_train = ...
- 使用sklearn进行数据挖掘-房价预测(2)—划分测试集
使用sklearn进行数据挖掘系列文章: 1.使用sklearn进行数据挖掘-房价预测(1) 2.使用sklearn进行数据挖掘-房价预测(2)-划分测试集 3.使用sklearn进行数据挖掘-房价预 ...
随机推荐
- respberry2b + android5.1
链接: http://pan.baidu.com/s/1kUf6UtL 密码: xz4g 安装教程:http://tieba.baidu.com/p/3963061007 如果安装后打开相册崩溃,则下 ...
- Cpython支持的进程与线程
一.multiprocessing模块介绍 python中的多线程无法利用CPU资源,在python中大部分情况使用多进程.python中提供了非常好的多进程包multiprocessing. mul ...
- 官方版sublime Text3汉化和激活注册码
转载:https://www.cnblogs.com/chaonuanxi/p/9371837.html sublimeText3 很不错,前面几天下了vscore学习Node.js,感觉有点懵,今天 ...
- mysql一列相同另一列相加
select name, sum(number) total from test group by name;
- java读取.txt文件工具类FileUtiles
public class FileUtils { private static final String ENCODING = "UTF-8";//编码方式 /** * 获取文件的 ...
- python函数之各种器
一: 装饰器 1:装饰器模板 def wrapper(func): def inner(*args,**kwargs): ret =func(*args,**kwargs) return ret re ...
- Android之Error: 'L' is not a valid file-based resource name character解决办法
1.问题 Error:Execution failed for task ':mergeBYODReleaseResources'.> /home/chenyu/Android_dev/sang ...
- javascript 对象(四)
一.对象概述 对象中包含一系列的属性,这些属性是无序的.每个属性都有一个字符串key和对应的value. var obj={x:1,y:2}; obj.x; obj.y; 1.为什么属性的key必须是 ...
- error: Unable to find vcvarsall.bat
http://www.crifan.com/python_mmseg_error_unable_to_find_vcvarsall_bat/ [已解决]安装Python模块mmseg出错:error: ...
- SQLALCHEMY_TRACK_MODIFICATIONS adds significant异常的解决方法