Flume的概述和安装部署
一、Flume概述
Flume是一种分布式、可靠且可用的服务,用于有效的收集、聚合和移动大量日志文件数据。Flume具有基于流数据流的简单灵活的框架,具有可靠的可靠性机制和许多故障转移和恢复机制,具有强大的容错能力。Flume使用简单的的可扩展数据模型,循环在线分析应用程序。
二、Flume的作用
数据的来源大致有三类:
1.爬虫
2.日志数据 =>使用Flume进行获取传输
3.传统数据库 =>使用Sqoop进行数据迁移
三、Flume架构
1.source:数据源
接收webser端的数据,产生数据流
同时source将产生数据流传输到channel
2.channel:传输管道
用于桥接source和sinks
3.sinks:下沉
从channel接收数据,并传输到hdfs或下一个agent
4.agent:代理
一个agent中包含一组source,channel,sinks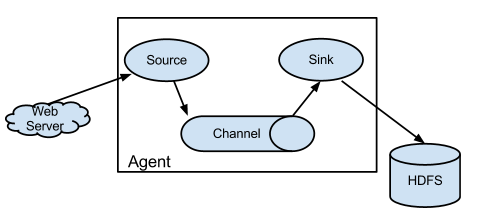
四、Flume的安装部署
1.从官网下载flume安装包(本人使用的是1.6.0版本)
2.上次到linux中解压
tar -zxvf ***.tar
3.重命名解压缩的文件夹为flume,方便以后更新维护
4.进去flume下的conf文件夹,将文件flume-env.sh.template重命名为flume-env.sh
5.进去该文件,删除java_home的注释,并修改java路径为本机的java_home路径
export JAVA_HOME=/root/hd/jdk1.8.0_102
6.保存并退出,安装完成!
Flume的概述和安装部署的更多相关文章
- HBase的概述和安装部署
一.HBase概述 1.HBase是Hadoop数据库,是一个分布式.可扩展的大数据存储. HBase是用于对大数据进行随机.实时读写访问的非关系型数据库,它的目标托管非常大的表——数十亿行N百万列. ...
- Kafka概述及安装部署
一.Kafka概述 1.Kafka是一个分布式流媒体平台,它有三个关键功能: (1)发布和订阅记录流,类似于消息队列或企业消息传递系统: (2)以容错的持久方式存储记录流: (3)记录发送时处理流. ...
- Zookeeper的概述、安装部署及选举机制
一.Zookeeper概述 1.Zookeeper是Hadoop生态的管理者,它致力于开发和维护开源服务器,实现高度可靠的分布式协调. 2.Zookeeper的两大功能: (1)存储数据 (2)监听 ...
- Spark-Unit1-spark概述与安装部署
一.Spark概述 spark官网:spark.apache.org Spark是用的大规模数据处理的统一计算引擎,它是为大数据处理而设计的快速通用的计算引擎.spark诞生于加油大学伯克利分校AMP ...
- 1.1-1.5 flume架构概述及安装使用
一.flume架构概述 1.flume简介 Flume是一种分布式,可靠且可用的服务,用于有效地收集,聚合和移动大量日志数据.它具有基于流数据流的简单灵活的架构.它具有可靠的可靠性机制和许多故障转移和 ...
- 【Hadoop离线基础总结】oozie的安装部署与使用
目录 简单介绍 概述 架构 安装部署 1.修改core-site.xml 2.上传oozie的安装包并解压 3.解压hadooplibs到与oozie平行的目录 4.创建libext目录,并拷贝依赖包 ...
- Kubernetes后台数据库etcd:安装部署etcd集群,数据备份与恢复
目录 一.系统环境 二.前言 三.etcd数据库 3.1 概述 四.安装部署etcd单节点 4.1 环境介绍 4.2 配置节点的基本环境 4.3 安装部署etcd单节点 4.4 使用客户端访问etcd ...
- 日志采集框架Flume以及Flume的安装部署(一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统)
Flume支持众多的source和sink类型,详细手册可参考官方文档,更多source和sink组件 http://flume.apache.org/FlumeUserGuide.html Flum ...
- Apache Flume简介及安装部署
概述 Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的软件. Flume 的核心是把数据从数据源(source)收集过来,再将收集到的数据送到指定的目 ...
随机推荐
- Confluence 6 匿名访问远程 API
Confluence 管理员可能希望为匿名用户禁用远程访问 API.这样能够避免恶意软件随意在网站进行批量修改. 希望禁用远程访问 API: 在屏幕的右上角单击 控制台按钮 ,然后选择 General ...
- Confluence 6 数据库表和参考
扩展下面的链接来显示主要的表格和每一个表格的外键. 单击这里来显示/隐藏表格... AO_9412A1_AOUSER ID AO_9412A1_USER_APP_LINK USER_ID fk_ao ...
- Java的动手动脑(七)
日期:2018.11.18 博客期:025 星期日 Part 1:使用 Files.walkFileTree()来找出指定文件夹下大小大于1KB的文件 package temp; import jav ...
- ionic3 更新打开apk android 8.0报错
项目中安卓强制更新,当文件下载完.在android 8.0中不能打开apk包. 引入插件报一下错误 import { FileOpener } from '@ionic-native/file-ope ...
- Nginx的进程模型及高可用方案(OpenResty)
1. Nginx 进程模型简介 Nginx默认采用多进程工作方式,Nginx启动后,会运行一个master进程和多个worker进程.其中master充当整个进程组与用户的交互接口,同时对进程进行监护 ...
- 最短路径之Floyd-warshall算法
哇咔咔,最喜欢这种算法了,算法简单,暴力解决: 可惜数据大点就解决不了问题了: 输入的数据是 第一行第一个数是city的数量n,第二个是路径数t, 接下来n行为a至b的距离 4 81 2 2 1 3 ...
- tail -f -n 0 /var/log/messages
<pre><font color="#CC0000"><b>root@kali</b></font>:<font ...
- queryset优化 。。。。。exists()与iterator()方法
exists()方法!! 判断queryset是否有值存在.exists() 只会查询一个字段 .正常会查所有!!! iterator()方法 objs = Book.objects.all() ...
- 解决:sudo: pip: command not found
1-问题:Ubuntu下执行sudo pip install package-name 出现 sudo: pip: command not found 的问题. 2-原因:编译sudo的时候加入了–w ...
- bat 获取拖放文件路径或名称
获取路径: @echo offset path=%~dp1echo %path%pause 获取路径及名称: @echo offset path=%~dp1%~nx1echo %path%pause