049 DSL语句
1.说明

2.sql程序
package com.scala.it import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkConf, SparkContext} import scala.math.BigDecimal.RoundingMode object SparkSQLDSLDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName("dsl")
val sc = SparkContext.getOrCreate(conf)
val sqlContext = new HiveContext(sc) // =================================================
sqlContext.sql(
"""
| SELECT
| deptno as no,
| SUM(sal) as sum_sal,
| AVG(sal) as avg_sal,
| SUM(mgr) as sum_mgr,
| AVG(mgr) as avg_mgr
| FROM hadoop09.emp
| GROUP BY deptno
| ORDER BY deptno DESC
""".stripMargin).show()
}
}
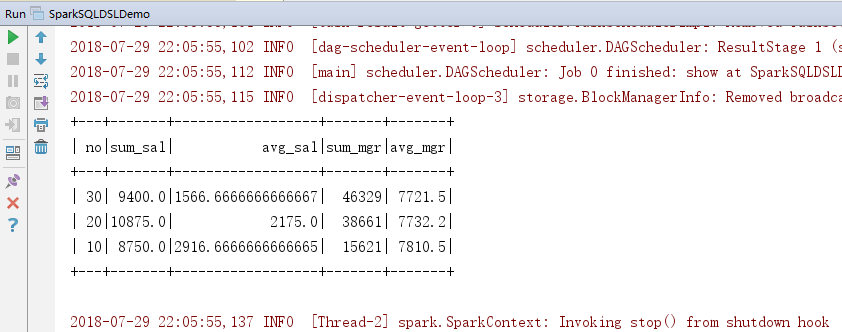
3.效果
4.DSL对上面程序重构
package com.scala.it import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkConf, SparkContext} import scala.math.BigDecimal.RoundingMode object SparkSQLDSLDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName("dsl")
val sc = SparkContext.getOrCreate(conf)
val sqlContext = new HiveContext(sc) // =================================================
sqlContext.sql(
"""
| SELECT
| deptno as no,
| SUM(sal) as sum_sal,
| AVG(sal) as avg_sal,
| SUM(mgr) as sum_mgr,
| AVG(mgr) as avg_mgr
| FROM hadoop09.emp
| GROUP BY deptno
| ORDER BY deptno DESC
""".stripMargin).show() //=================================================
// 读取数据形成DataFrame,并缓存DataFrame
val df = sqlContext.read.table("hadoop09.emp")
df.cache()
//=================================================
import sqlContext.implicits._
import org.apache.spark.sql.functions._ //=================================================对上面sql进行DSL
df.select("deptno", "sal", "mgr")
.groupBy("deptno")
.agg(
sum("sal").as("sum_sal"),
avg("sal").as("avg_sal"),
sum("mgr").as("sum_mgr"),
avg("mgr").as("avg_mgr")
)
.orderBy($"deptno".desc)
.show()
}
}
5.效果

6.Select语句
可以使用string,也可以使用col,或者$。
在Select中可以使用自定义的函数进行使用。
package com.scala.it import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkConf, SparkContext} import scala.math.BigDecimal.RoundingMode object SparkSQLDSLDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName("dsl")
val sc = SparkContext.getOrCreate(conf)
val sqlContext = new HiveContext(sc) // =================================================
sqlContext.sql(
"""
| SELECT
| deptno as no,
| SUM(sal) as sum_sal,
| AVG(sal) as avg_sal,
| SUM(mgr) as sum_mgr,
| AVG(mgr) as avg_mgr
| FROM hadoop09.emp
| GROUP BY deptno
| ORDER BY deptno DESC
""".stripMargin).show() //=================================================
// 读取数据形成DataFrame,并缓存DataFrame
val df = sqlContext.read.table("hadoop09.emp")
df.cache()
//=================================================
import sqlContext.implicits._
import org.apache.spark.sql.functions._ //=================================================Select语句
df.select("empno", "ename", "deptno").show()
df.select(col("empno").as("id"), $"ename".as("name"), df("deptno")).show()
df.select($"empno".as("id"), substring($"ename", 0, 1).as("name")).show()
df.selectExpr("empno as id", "substring(ename,0,1) as name").show() //使用自定义的函数
sqlContext.udf.register(
"doubleValueFormat", // 自定义函数名称
(value: Double, scale: Int) => {
// 自定义函数处理的代码块
BigDecimal.valueOf(value).setScale(scale, RoundingMode.HALF_DOWN).doubleValue()
})
df.selectExpr("doubleValueFormat(sal,2)").show()
}
}
7.Where语句
//=================================================Where语句
df.where("sal > 1000 and sal < 2000").show()
df.where($"sal" > 1000 && $"sal" < 2000).show()
8.groupBy语句
建议使用第三种方式,也是最常见的使用方式。
同样是支持自定义函数。
package com.scala.it import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkConf, SparkContext} import scala.math.BigDecimal.RoundingMode object SparkSQLDSLDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName("dsl")
val sc = SparkContext.getOrCreate(conf)
val sqlContext = new HiveContext(sc) // =================================================
sqlContext.sql(
"""
| SELECT
| deptno as no,
| SUM(sal) as sum_sal,
| AVG(sal) as avg_sal,
| SUM(mgr) as sum_mgr,
| AVG(mgr) as avg_mgr
| FROM hadoop09.emp
| GROUP BY deptno
| ORDER BY deptno DESC
""".stripMargin).show() //=================================================
// 读取数据形成DataFrame,并缓存DataFrame
val df = sqlContext.read.table("hadoop09.emp")
df.cache()
//=================================================
import sqlContext.implicits._
import org.apache.spark.sql.functions._ //=================================================GroupBy语句
//这种方式不推荐使用,下面也说明了问题
df.groupBy("deptno").agg(
"sal" -> "min", // 求min(sal)
"sal" -> "max", // 求max(sal) ===> 会覆盖同列的其他聚合函数,解决方案:重新命名
"mgr" -> "max" // 求max(mgr)
).show() sqlContext.udf.register("selfAvg", AvgUDAF)
df.groupBy("deptno").agg(
"sal" -> "selfAvg"
).toDF("deptno", "self_avg_sal").show() df.groupBy("deptno").agg(
min("sal").as("min_sal"),
max("sal").as("max_sal"),
max("mgr")
).where("min_sal > 1200").show() }
}
9.sort、orderBy排序
//=================================================数据排序
// sort、orderBy ==> 全局有序
// repartition ==> 局部数据有序
df.sort("sal").select("empno", "sal").show()
df.repartition(3).sort($"sal".desc).select("empno", "sal").show()
df.repartition(3).orderBy($"sal".desc).select("empno", "sal").show()
df.repartition(3).sortWithinPartitions($"sal".desc).select("empno", "sal").show()
10.窗口函数
//=================================================Hive的窗口分析函数
// 必须使用HiveContext来构建DataFrame
// 通过row_number函数来实现分组排序TopN的需求: 先按照某些字段进行数据分区,然后分区的数据在分区内进行topN的获取
val window = Window.partitionBy("deptno").orderBy($"sal".desc)
df.select(
$"empno",
$"ename",
$"deptno",
row_number().over(window).as("rnk")
).where("rnk <= 3").show()
二:总程序总览
package com.scala.it import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkConf, SparkContext} import scala.math.BigDecimal.RoundingMode object SparkSQLDSLDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[*]")
.setAppName("dsl")
val sc = SparkContext.getOrCreate(conf)
val sqlContext = new HiveContext(sc) // =================================================
sqlContext.sql(
"""
| SELECT
| deptno as no,
| SUM(sal) as sum_sal,
| AVG(sal) as avg_sal,
| SUM(mgr) as sum_mgr,
| AVG(mgr) as avg_mgr
| FROM hadoop09.emp
| GROUP BY deptno
| ORDER BY deptno DESC
""".stripMargin).show() //=================================================
// 读取数据形成DataFrame,并缓存DataFrame
val df = sqlContext.read.table("hadoop09.emp")
df.cache()
//=================================================
import sqlContext.implicits._
import org.apache.spark.sql.functions._ //=================================================对上面sql进行DSL
df.select("deptno", "sal", "mgr")
.groupBy("deptno")
.agg(
sum("sal").as("sum_sal"),
avg("sal").as("avg_sal"),
sum("mgr").as("sum_mgr"),
avg("mgr").as("avg_mgr")
)
.orderBy($"deptno".desc)
.show() //=================================================Select语句
df.select("empno", "ename", "deptno").show()
df.select(col("empno").as("id"), $"ename".as("name"), df("deptno")).show()
df.select($"empno".as("id"), substring($"ename", 0, 1).as("name")).show()
df.selectExpr("empno as id", "substring(ename,0,1) as name").show() //使用自定义的函数
sqlContext.udf.register(
"doubleValueFormat", // 自定义函数名称
(value: Double, scale: Int) => {
// 自定义函数处理的代码块
BigDecimal.valueOf(value).setScale(scale, RoundingMode.HALF_DOWN).doubleValue()
})
df.selectExpr("doubleValueFormat(sal,2)").show() //=================================================Where语句
df.where("sal > 1000 and sal < 2000").show()
df.where($"sal" > 1000 && $"sal" < 2000).show() //=================================================GroupBy语句
//这种方式不推荐使用,下面也说明了问题
df.groupBy("deptno").agg(
"sal" -> "min", // 求min(sal)
"sal" -> "max", // 求max(sal) ===> 会覆盖同列的其他聚合函数,解决方案:重新命名
"mgr" -> "max" // 求max(mgr)
).show() sqlContext.udf.register("selfAvg", AvgUDAF)
df.groupBy("deptno").agg(
"sal" -> "selfAvg"
).toDF("deptno", "self_avg_sal").show() df.groupBy("deptno").agg(
min("sal").as("min_sal"),
max("sal").as("max_sal"),
max("mgr")
).where("min_sal > 1200").show() //=================================================数据排序
// sort、orderBy ==> 全局有序
// repartition ==> 局部数据有序
df.sort("sal").select("empno", "sal").show()
df.repartition(3).sort($"sal".desc).select("empno", "sal").show()
df.repartition(3).orderBy($"sal".desc).select("empno", "sal").show()
df.repartition(3).sortWithinPartitions($"sal".desc).select("empno", "sal").show() //=================================================Hive的窗口分析函数
// 必须使用HiveContext来构建DataFrame
// 通过row_number函数来实现分组排序TopN的需求: 先按照某些字段进行数据分区,然后分区的数据在分区内进行topN的获取
val window = Window.partitionBy("deptno").orderBy($"sal".desc)
df.select(
$"empno",
$"ename",
$"deptno",
row_number().over(window).as("rnk")
).where("rnk <= 3").show()
}
}
049 DSL语句的更多相关文章
- ElasticSearch实战系列二: ElasticSearch的DSL语句使用教程---图文详解
前言 在上一篇中介绍了ElasticSearch集群和kinaba的安装教程,本篇文章就来讲解下 ElasticSearch的DSL语句使用. ElasticSearch DSL 介绍 Elastic ...
- [elk]elasticsearch dsl语句
例子1 统计1,有唱歌兴趣的 2,按年龄分组 3,求每组平均年龄 4,按平均年龄降序排序 sql转为dsl例子 # 每种型号车的颜色数 > 1的 SELECT model,COUNT(DISTI ...
- Elasticsearch DSL语句之连接查询
传统数据库支持的full join(全连接)查询方式. 这种方式在Elasticsearch中使用时非常昂贵的.因此,Elasticsearch提供两种操作可以支持水平扩展 更多内容请参考Elasti ...
- kibana常用聚合查询DSL语句记录
-------- GET winlogbeat-2017.11.*/_search { "query": { "bool": { "must" ...
- ES 20 - 查询Elasticsearch中的数据 (基于DSL查询, 包括查询校验match + bool + term)
目录 1 什么是DSL 2 DSL校验 - 定位不合法的查询语句 3 match query的使用 3.1 简单功能示例 3.1.1 查询所有文档 3.1.2 查询满足一定条件的文档 3.1.3 分页 ...
- Elasticsearch DSL 常用语法介绍
课程环境 CentOS 7.3 x64 JDK 版本:1.8(最低要求),主推:JDK 1.8.0_121 Elasticsearch 版本:5.2.0 相关软件包百度云下载地址(密码:0yzd):h ...
- ElasticSearch入门系列(三)文档,索引,搜索和聚合
一.文档 在实际使用中的对象往往拥有复杂的数据结构 Elasticsearch是面向文档的,这意味着他可以存储整个对象或文档,然而他不仅仅是存储,还会索引每个文档的内容使之可以被搜索,在Elastic ...
- Gradle学习系列之三——读懂Gradle语法
在本系列的上篇文章中,我们讲到了创建Task的多种方法,在本篇文章中,我们将学习如何读懂Gradle. 请通过以下方式下载本系列文章的Github示例代码: git clone https://git ...
- Gradle学习
Gradle是一种构建工具,它抛弃了基于XML的构建脚本,取而代之的是采用一种基于Groovy的内部领域特定语言.近期,Gradle获得了极大的关注,这也是我决定去研究Gradle的原因. 这篇文章是 ...
随机推荐
- js获取当前星期几
使用Date对象的getDay方法可以获取当前日期的星期数. getDay() 方法可返回表示星期的某一天的数字. 示例: var date = new Date(); alert(date.getD ...
- python介绍、解释器、变量及其它
python 一.python及编程语言介绍 编程语言发展:机器语言==>汇编语言==>高级语言 机器语言:由数字电路发展而来编程都是靠0101的二进制进行 汇编语言:汇编语言的实质和机器 ...
- 初步了解three.js
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8&quo ...
- 开源巨献:年度最佳 JavaScript 和 CSS 开源库推荐!
作者:编辑部的故事 < 开源巨献:年度最佳 JavaScript 和 CSS 开源库推荐! > 开源巨献:年度最佳 JavaScript 和 CSS 开源库推荐! Tutoria ...
- 用echarts写的轨迹图demo
轨迹图预览: [下载地址]:https://github.com/zhangzn3/trail-graph.git
- 【scapy】读取pcap
scapy读取pcap包 假设有pcap包test.pcap,读取其中的分层流量信息 代码: import scapy_http.http try: import scapy.all as scapy ...
- laravel 框架后台主菜单接口
后台菜单调用接口:/admin/manages ManageRepository类: 每个路由中注册: 等等: 最后后台菜单返回:
- linux更好看的top界面htop
top命令界面 性能测试时会经常用到top命令百用百顺就是样式不太美,下面介绍htop一个看起来更漂亮的top界面 安装htop yum install htop 安装完成键入htop命令,这样看起来 ...
- Java和C冒泡排序
Java 示例代码: public class test { public static void main(String[] args) { String str = "321dca5&q ...
- 20165206 实验一 Java开发环境的熟悉
20165206 实验一 Java开发环境的熟悉 一.实验内容及步骤 实验一 Java开发环境的熟悉-1 建立有自己学号的实验目录. 通过vim Hello.java编辑代码. 编译.运行Hello. ...