吴恩达课后作业学习1-week2-homework-logistic
参考:https://blog.csdn.net/u013733326/article/details/79639509
希望大家直接到上面的网址去查看代码,下面是本人的笔记
搭建一个能够 “识别猫”的简单神经网络——实现logistic回归,即单层神经网络
1.首先下载数据
总代码lr_utils.py为:
import numpy as np
import h5py def load_dataset():
train_dataset = h5py.File('datasets/train_catvnoncat.h5', "r")
train_set_x_orig = np.array(train_dataset["train_set_x"][:]) # your train set features
train_set_y_orig = np.array(train_dataset["train_set_y"][:]) # your train set labels test_dataset = h5py.File('datasets/test_catvnoncat.h5', "r")
test_set_x_orig = np.array(test_dataset["test_set_x"][:]) # your test set features
test_set_y_orig = np.array(test_dataset["test_set_y"][:]) # your test set labels classes = np.array(test_dataset["list_classes"][:]) # the list of classes train_set_y_orig = train_set_y_orig.reshape((, train_set_y_orig.shape[]))
test_set_y_orig = test_set_y_orig.reshape((, test_set_y_orig.shape[])) return train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classes
解释以下上面的load_dataset() 返回的值的含义:
train_set_x_orig :保存的是训练集里面的图像数据(本训练集有209张64x64的图像)。
train_set_y_orig :保存的是训练集的图像对应的分类值(【0 | 1】,0表示不是猫,1表示是猫)。
test_set_x_orig :保存的是测试集里面的图像数据(本训练集有50张64x64的图像)。
test_set_y_orig : 保存的是测试集的图像对应的分类值(【0 | 1】,0表示不是猫,1表示是猫)。
classes : 保存的是以bytes类型保存的两个字符串数据,数据为:[b’non-cat’ b’cat’]
在jupyter中运行查看结果:
1)查看第一张图的数据集和所有图的分类值,以及获取图像的宽度、高度等信息
train_dataset = h5py.File('datasets/train_catvnoncat.h5', "r")
train_set_x_orig = np.array(train_dataset["train_set_x"][:]) #只查看其中一张图的数据集
train_set_y_orig = np.array(train_dataset["train_set_y"][:]) #查看所有图的分类值
print(train_set_x_orig)
print(train_set_y_orig)
返回:
[[[[ ]
[ ]
[ ]
...
[ ]
[ ]
[ ]] [[ ]
[ ]
[ ]
...
[ ]
[ ]
[ ]] [[ ]
[ ]
[ ]
...
[ ]
[ ]
[ ]] ... [[ ]
[ ]
[ ]
...
[ ]
[ ]
[ ]] [[ ]
[ ]
[ ]
...
[ ]
[ ]
[ ]] [[ ]
[ ]
[ ]
...
[ ]
[ ]
[ ]]]]
[ ]
然后获取图像的宽度、高度等信息:
print(train_set_x_orig.shape[]) #照片总数
print(train_set_x_orig.shape[]) #照片宽度
print(train_set_x_orig.shape[]) #照片宽度
print(train_set_x_orig.shape[]) #彩色相片
返回:
2)查看类型列表:
test_dataset = h5py.File('datasets/test_catvnoncat.h5', "r")
test_set_x_orig = np.array(test_dataset["test_set_x"][:]) # your test set features
test_set_y_orig = np.array(test_dataset["test_set_y"][:]) # your test set labels
classes = np.array(test_dataset["list_classes"][:]) # the list of classes
print(classes)
返回:
[b'non-cat' b'cat']
3)随意打印一张图片,如第25张图和第26张图
plt.imshow(train_set_x_orig[])
返回:

和

4)转换数据形状shape
train_set_y_orig.shape
返回:
(,)
如数据一开始是(209,),其不是行向量也不是列向量,如下:
[
]
进行转换:
train_set_y_orig = train_set_y_orig.reshape((,train_set_y_orig.shape[]))
print(train_set_y_orig)
转换后变成(1,209)行向量,即:
[[
]]
2.运行代码
总代码test.py为:
# -*- coding: utf- -*-
"""
Created on Wed Mar :: 博客地址 :http://blog.csdn.net/u013733326/article/details/79639509 @author: Oscar
""" import numpy as np
import matplotlib.pyplot as plt
import h5py
from lr_utils import load_dataset train_set_x_orig , train_set_y , test_set_x_orig , test_set_y , classes = load_dataset() m_train = train_set_y.shape[] #训练集里图片的数量。
m_test = test_set_y.shape[] #测试集里图片的数量。
num_px = train_set_x_orig.shape[] #训练、测试集里面的图片的宽度和高度(均为64x64)。 #现在看一看我们加载的东西的具体情况
print ("训练集的数量: m_train = " + str(m_train))
print ("测试集的数量 : m_test = " + str(m_test))
print ("每张图片的宽/高 : num_px = " + str(num_px))
print ("每张图片的大小 : (" + str(num_px) + ", " + str(num_px) + ", 3)")
print ("训练集_图片的维数 : " + str(train_set_x_orig.shape))
print ("训练集_标签的维数 : " + str(train_set_y.shape))
print ("测试集_图片的维数: " + str(test_set_x_orig.shape))
print ("测试集_标签的维数: " + str(test_set_y.shape)) #将训练集的维度降低并转置。
train_set_x_flatten = train_set_x_orig.reshape(train_set_x_orig.shape[],-).T
#将测试集的维度降低并转置。
test_set_x_flatten = test_set_x_orig.reshape(test_set_x_orig.shape[], -).T print ("训练集降维最后的维度: " + str(train_set_x_flatten.shape))
print ("训练集_标签的维数 : " + str(train_set_y.shape))
print ("测试集降维之后的维度: " + str(test_set_x_flatten.shape))
print ("测试集_标签的维数 : " + str(test_set_y.shape)) train_set_x = train_set_x_flatten /
test_set_x = test_set_x_flatten /
#二分类,所以使用的是sigmoid函数
def sigmoid(z):
"""
参数:
z - 任何大小的标量或numpy数组。 返回:
s - sigmoid(z)
"""
s = / ( + np.exp(-z))
return s def initialize_with_zeros(dim):
"""
此函数为w创建一个维度为(dim,)的0向量,并将b初始化为0。 参数:
dim - 我们想要的w矢量的大小(或者这种情况下的参数数量) 返回:
w - 维度为(dim,)的初始化向量。
b - 初始化的标量(对应于偏差)
"""
w = np.zeros(shape = (dim,))
b =
#使用断言来确保我要的数据是正确的
assert(w.shape == (dim, )) #w的维度是(dim,)
assert(isinstance(b, float) or isinstance(b, int)) #b的类型是float或者是int return (w , b) def propagate(w, b, X, Y):
"""
实现前向和后向传播的成本函数及其梯度。
参数:
w - 权重,大小不等的数组(num_px * num_px * ,)
b - 偏差,一个标量
X - 矩阵类型为(num_px * num_px * ,训练数量)
Y - 真正的“标签”矢量(如果非猫则为0,如果是猫则为1),矩阵维度为(,训练数据数量) 返回:
cost- 逻辑回归的负对数似然成本
dw - 相对于w的损失梯度,因此与w相同的形状
db - 相对于b的损失梯度,因此与b的形状相同
"""
m = X.shape[] #正向传播
A = sigmoid(np.dot(w.T,X) + b) #计算激活值,请参考公式2。
cost = (- / m) * np.sum(Y * np.log(A) + ( - Y) * (np.log( - A))) #计算成本,请参考公式3和4。 #反向传播
dw = ( / m) * np.dot(X, (A - Y).T) #请参考视频中的偏导公式。
db = ( / m) * np.sum(A - Y) #请参考视频中的偏导公式。 #使用断言确保我的数据是正确的
assert(dw.shape == w.shape)
assert(db.dtype == float)
cost = np.squeeze(cost)
assert(cost.shape == ()) #创建一个字典,把dw和db保存起来。
grads = {
"dw": dw,
"db": db
}
return (grads , cost) def optimize(w , b , X , Y , num_iterations , learning_rate , print_cost = False):
"""
此函数通过运行梯度下降算法来优化w和b 参数:
w - 权重,大小不等的数组(num_px * num_px * ,)
b - 偏差,一个标量
X - 维度为(num_px * num_px * ,训练数据的数量)的数组。
Y - 真正的“标签”矢量(如果非猫则为0,如果是猫则为1),矩阵维度为(,训练数据的数量)
num_iterations - 优化循环的迭代次数
learning_rate - 梯度下降更新规则的学习率
print_cost - 每100步打印一次损失值 返回:
params - 包含权重w和偏差b的字典
grads - 包含权重和偏差相对于成本函数的梯度的字典
成本 - 优化期间计算的所有成本列表,将用于绘制学习曲线。 提示:
我们需要写下两个步骤并遍历它们:
)计算当前参数的成本和梯度,使用propagate()。
)使用w和b的梯度下降法则更新参数。
""" costs = [] for i in range(num_iterations): grads, cost = propagate(w, b, X, Y) dw = grads["dw"]
db = grads["db"] w = w - learning_rate * dw
b = b - learning_rate * db #记录成本
if i % == :
costs.append(cost)
#打印成本数据
if (print_cost) and (i % == ):
print("迭代的次数: %i , 误差值: %f" % (i,cost)) params = {
"w" : w,
"b" : b }
grads = {
"dw": dw,
"db": db }
return (params , grads , costs) def predict(w , b , X ):
"""
使用学习逻辑回归参数logistic (w,b)预测标签是0还是1, 参数:
w - 权重,大小不等的数组(num_px * num_px * ,)
b - 偏差,一个标量
X - 维度为(num_px * num_px * ,训练数据的数量)的数据 返回:
Y_prediction - 包含X中所有图片的所有预测【 | 】的一个numpy数组(向量) """ m = X.shape[] #图片的数量
Y_prediction = np.zeros((,m))
w = w.reshape(X.shape[],) #计预测猫在图片中出现的概率
A = sigmoid(np.dot(w.T , X) + b)
for i in range(A.shape[]):
#将概率a [,i]转换为实际预测p [,i]
Y_prediction[,i] = if A[,i] > 0.5 else
#使用断言
assert(Y_prediction.shape == (,m)) return Y_prediction def model(X_train , Y_train , X_test , Y_test , num_iterations = , learning_rate = 0.5 , print_cost = False):
"""
通过调用之前实现的函数来构建逻辑回归模型 参数:
X_train - numpy的数组,维度为(num_px * num_px * ,m_train)的训练集
Y_train - numpy的数组,维度为(,m_train)(矢量)的训练标签集
X_test - numpy的数组,维度为(num_px * num_px * ,m_test)的测试集
Y_test - numpy的数组,维度为(,m_test)的(向量)的测试标签集
num_iterations - 表示用于优化参数的迭代次数的超参数
learning_rate - 表示optimize()更新规则中使用的学习速率的超参数
print_cost - 设置为true以每100次迭代打印成本 返回:
d - 包含有关模型信息的字典。
"""
w , b = initialize_with_zeros(X_train.shape[]) parameters , grads , costs = optimize(w , b , X_train , Y_train,num_iterations , learning_rate , print_cost) #从字典“参数”中检索参数w和b
w , b = parameters["w"] , parameters["b"] #预测测试/训练集的例子
Y_prediction_test = predict(w , b, X_test)
Y_prediction_train = predict(w , b, X_train) #打印训练后的准确性
print("训练集准确性:" , format( - np.mean(np.abs(Y_prediction_train - Y_train)) * ) ,"%")
print("测试集准确性:" , format( - np.mean(np.abs(Y_prediction_test - Y_test)) * ) ,"%") d = {
"costs" : costs,
"Y_prediction_test" : Y_prediction_test,
"Y_prediciton_train" : Y_prediction_train,
"w" : w,
"b" : b,
"learning_rate" : learning_rate,
"num_iterations" : num_iterations }
return d d = model(train_set_x, train_set_y, test_set_x, test_set_y, num_iterations = , learning_rate = 0.005, print_cost = True)
print(d['w'])
print(d['b'])
print(d['Y_prediciton_train'])
print(train_set_y)
print()
print(d['Y_prediction_test'])
print(test_set_y) #绘制图
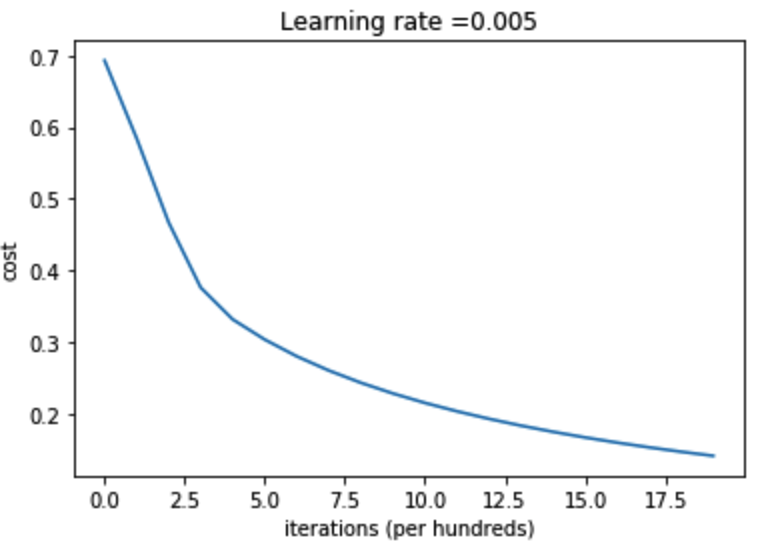
costs = np.squeeze(d['costs'])
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('iterations (per hundreds)')
plt.title("Learning rate =" + str(d["learning_rate"]))
plt.show()
返回:
训练集的数量: m_train =
测试集的数量 : m_test =
每张图片的宽/高 : num_px =
每张图片的大小 : (, , )
训练集_图片的维数 : (, , , )
训练集_标签的维数 : (, )
测试集_图片的维数: (, , , )
测试集_标签的维数: (, )
训练集降维最后的维度: (, )
训练集_标签的维数 : (, )
测试集降维之后的维度: (, )
测试集_标签的维数 : (, )
迭代的次数: , 误差值: 0.693147
迭代的次数: , 误差值: 0.584508
迭代的次数: , 误差值: 0.466949
迭代的次数: , 误差值: 0.376007
迭代的次数: , 误差值: 0.331463
迭代的次数: , 误差值: 0.303273
迭代的次数: , 误差值: 0.279880
迭代的次数: , 误差值: 0.260042
迭代的次数: , 误差值: 0.242941
迭代的次数: , 误差值: 0.228004
迭代的次数: , 误差值: 0.214820
迭代的次数: , 误差值: 0.203078
迭代的次数: , 误差值: 0.192544
迭代的次数: , 误差值: 0.183033
迭代的次数: , 误差值: 0.174399
迭代的次数: , 误差值: 0.166521
迭代的次数: , 误差值: 0.159305
迭代的次数: , 误差值: 0.152667
迭代的次数: , 误差值: 0.146542
迭代的次数: , 误差值: 0.140872
训练集准确性: 99.04306220095694 %
测试集准确性: 70.0 %
[[ 0.00961402]
[-0.0264683 ]
[-0.01226513]
...
[-0.01144453]
[-0.02944783]
[ 0.02378106]]
-0.015906243999692992
[[. . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . .]]
[[ ]] [[. . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . .
. .]]
[[
]]
图为:
解释代码:
1)激活函数sigmoid(),jupyter测试其是否符合条件:
def sigmoid(z):
"""
参数:
z - 任何大小的标量或numpy数组。 返回:
s - sigmoid(z)
"""
s = / ( + np.exp(-z))
return s
#测试sigmoid()
print("====================测试sigmoid====================")
print ("sigmoid(0) = " + str(sigmoid()))
print ("sigmoid(9.2) = " + str(sigmoid(9.2)))
返回:
====================测试sigmoid====================
sigmoid() = 0.5
sigmoid(9.2) = 0.9998989708060922
2)初始化参数w,b
测试:
def initialize_with_zeros(dim):
"""
此函数为w创建一个维度为(dim,)的0向量,并将b初始化为0。 参数:
dim - 我们想要的w矢量的大小(或者这种情况下的参数数量) 返回:
w - 维度为(dim,)的初始化向量。
b - 初始化的标量(对应于偏差)
"""
w = np.zeros(shape = (dim,))
b =
#使用断言来确保我要的数据是正确的
assert(w.shape == (dim, )) #w的维度是(dim,)
assert(isinstance(b, float) or isinstance(b, int)) #b的类型是float或者是int return (w , b)
w, b = initialize_with_zeros()
print(w)
print(w.shape)
print(b)
返回:
[[.]
[.]
[.]
...
[.]
[.]
[.]]
(, )
3)前后向传播
np.squeeze()函数可以删除数组形状中的单维度条目,即把shape中为1的维度去掉,但是对非单维的维度不起作用。
如之前转成行向量(1,209)的train_set_y_orig就能够通过这个函数再转回(209,)类型的值:
train_set_y_orig = train_set_y_orig.reshape((,train_set_y_orig.shape[]))
print(train_set_y_orig.shape)
train_set_y_orig_squeeze = np.squeeze(train_set_y_orig)
print(train_set_y_orig_squeeze.shape)
返回:
(, )
(,)
测试前后向传播:
def propagate(w, b, X, Y):
"""
实现前向和后向传播的成本函数及其梯度。
参数:
w - 权重,大小不等的数组(num_px * num_px * ,)
b - 偏差,一个标量
X - 矩阵类型为(num_px * num_px * ,训练数量)
Y - 真正的“标签”矢量(如果非猫则为0,如果是猫则为1),矩阵维度为(,训练数据数量) 返回:
cost- 逻辑回归的负对数似然成本
dw - 相对于w的损失梯度,因此与w相同的形状
db - 相对于b的损失梯度,因此与b的形状相同
"""
m = X.shape[] #正向传播
A = sigmoid(np.dot(w.T,X) + b) #计算激活值,请参考公式2。
cost = (- / m) * np.sum(Y * np.log(A) + ( - Y) * (np.log( - A))) #计算成本,请参考公式3和4。 #反向传播
dw = ( / m) * np.dot(X, (A - Y).T) #请参考视频中的偏导公式。
db = ( / m) * np.sum(A - Y) #请参考视频中的偏导公式。 #使用断言确保我的数据是正确的
assert(dw.shape == w.shape)
assert(db.dtype == float)
cost = np.squeeze(cost)
assert(cost.shape == ()) #创建一个字典,把dw和db保存起来。
grads = {
"dw": dw,
"db": db
}
return (grads , cost)
#测试一下propagate
print("====================测试propagate====================")
#初始化一些参数
w, b, X, Y = np.array([[], []]), , np.array([[,], [,]]), np.array([[, ]])
grads, cost = propagate(w, b, X, Y)
print ("dw = " + str(grads["dw"]))
print ("db = " + str(grads["db"]))
print ("cost = " + str(cost))
返回:
====================测试propagate====================
dw = [[0.99993216]
[1.99980262]]
db = 0.49993523062470574
cost = 6.000064773192205
4)优化模型
通过最小化成本函数来学习w和b,使用梯度下降法得到使成本函数最小的w,b。
测试:
def optimize(w , b , X , Y , num_iterations , learning_rate , print_cost = False):
"""
此函数通过运行梯度下降算法来优化w和b 参数:
w - 权重,大小不等的数组(num_px * num_px * ,)
b - 偏差,一个标量
X - 维度为(num_px * num_px * ,训练数据的数量)的数组。
Y - 真正的“标签”矢量(如果非猫则为0,如果是猫则为1),矩阵维度为(,训练数据的数量)
num_iterations - 优化循环的迭代次数
learning_rate - 梯度下降更新规则的学习率
print_cost - 每100步打印一次损失值 返回:
params - 包含权重w和偏差b的字典
grads - 包含权重和偏差相对于成本函数的梯度的字典
成本 - 优化期间计算的所有成本列表,将用于绘制学习曲线。 提示:
我们需要写下两个步骤并遍历它们:
)计算当前参数的成本和梯度,使用propagate()。
)使用w和b的梯度下降法则更新参数。
""" costs = [] for i in range(num_iterations): grads, cost = propagate(w, b, X, Y) dw = grads["dw"]
db = grads["db"] w = w - learning_rate * dw
b = b - learning_rate * db #记录成本
if i % == :
costs.append(cost)
#打印成本数据
if (print_cost) and (i % == ):
print("迭代的次数: %i , 误差值: %f" % (i,cost)) params = {
"w" : w,
"b" : b }
grads = {
"dw": dw,
"db": db }
return (params , grads , costs)
#测试optimize
print("====================测试optimize====================")
w, b, X, Y = np.array([[], []]), , np.array([[,], [,]]), np.array([[, ]])
params , grads , costs = optimize(w , b , X , Y , num_iterations= , learning_rate = 0.009 , print_cost = False)
print ("w = " + str(params["w"]))
print ("b = " + str(params["b"]))
print ("dw = " + str(grads["dw"]))
print ("db = " + str(grads["db"]))
print(costs) #因为这里只迭代了第一个100次,所以只有一个成本值
返回:
====================测试optimize====================
w = [[0.1124579 ]
[0.23106775]]
b = 1.5593049248448891
dw = [[0.90158428]
[1.76250842]]
db = 0.4304620716786828
[6.000064773192205]
5)使用上面的函数进行训练后得到了最好的w,b参数,下面就可以使用这些参数值来预测测试集数据是不是猫:
def predict(w , b , X ):
"""
使用学习逻辑回归参数logistic (w,b)预测标签是0还是1, 参数:
w - 权重,大小不等的数组(num_px * num_px * ,)
b - 偏差,一个标量
X - 维度为(num_px * num_px * ,训练数据的数量)的数据 返回:
Y_prediction - 包含X中所有图片的所有预测【 | 】的一个numpy数组(向量) """ m = X.shape[] #图片的数量
Y_prediction = np.zeros((,m))
w = w.reshape(X.shape[],) #计预测猫在图片中出现的概率,得到50张图片是否为猫的概率
A = sigmoid(np.dot(w.T , X) + b)
for i in range(A.shape[]):
#将概率a [,i]转换为实际预测p [,i]
Y_prediction[,i] = if A[,i] > 0.5 else
#使用断言
assert(Y_prediction.shape == (,m)) return Y_prediction
3.优化——为什么上面的学习率设置为0.005
学习率α 决定了我们更新参数的速度。如果学习率过高,我们可能会“超过”最优值。同样,如果它太小,我们将需要太多迭代才能收敛到最佳值
learning_rates = [0.01, 0.001, 0.0001]
models = {}
for i in learning_rates:
print ("learning rate is: " + str(i))
models[str(i)] = model(train_set_x, train_set_y, test_set_x, test_set_y, num_iterations = , learning_rate = i, print_cost = False)
print ('\n' + "-------------------------------------------------------" + '\n') for i in learning_rates:
plt.plot(np.squeeze(models[str(i)]["costs"]), label= str(models[str(i)]["learning_rate"])) plt.ylabel('cost')
plt.xlabel('iterations') legend = plt.legend(loc='upper center', shadow=True)
frame = legend.get_frame()
frame.set_facecolor('0.90')
plt.show()
返回:
learning rate is: 0.01
训练集准确性: 99.52153110047847 %
测试集准确性: 68.0 % ------------------------------------------------------- learning rate is: 0.001
训练集准确性: 88.99521531100478 %
测试集准确性: 64.0 % ------------------------------------------------------- learning rate is: 0.0001
训练集准确性: 68.42105263157895 %
测试集准确性: 36.0 % -------------------------------------------------------
图为:
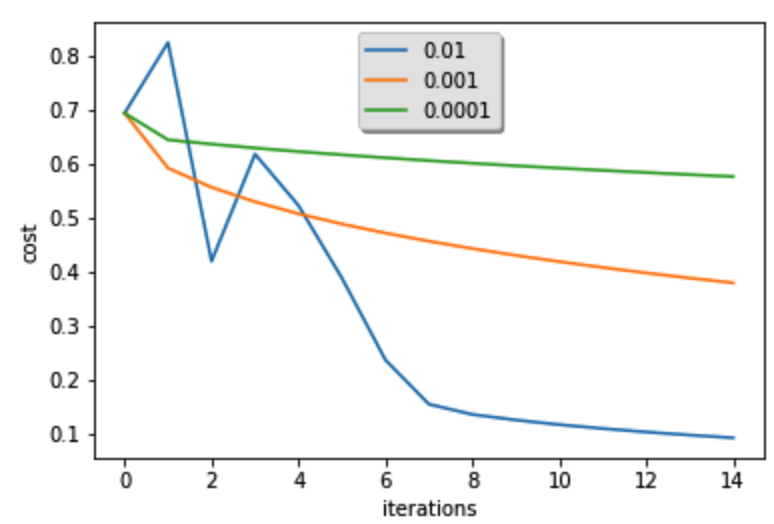
可见在范围(0.01,0.001)之间的学习率效果好,再更加细化学习率:
learning_rates = [0.009, 0.008, 0.007, 0.006, 0.005, 0.004, 0.003, 0.002, 0.001]
返回:
learning rate is: 0.009
训练集准确性: 99.52153110047847 %
测试集准确性: 68.0 % ------------------------------------------------------- learning rate is: 0.008
训练集准确性: 99.52153110047847 %
测试集准确性: 68.0 % ------------------------------------------------------- learning rate is: 0.007
训练集准确性: 99.04306220095694 %
测试集准确性: 70.0 % ------------------------------------------------------- learning rate is: 0.006
训练集准确性: 98.56459330143541 %
测试集准确性: 70.0 % ------------------------------------------------------- learning rate is: 0.005
训练集准确性: 97.60765550239235 %
测试集准确性: 70.0 % ------------------------------------------------------- learning rate is: 0.004
训练集准确性: 97.12918660287082 %
测试集准确性: 70.0 % ------------------------------------------------------- learning rate is: 0.003
训练集准确性: 96.17224880382776 %
测试集准确性: 74.0 % ------------------------------------------------------- learning rate is: 0.002
训练集准确性: 93.77990430622009 %
测试集准确性: 74.0 % ------------------------------------------------------- learning rate is: 0.001
训练集准确性: 88.99521531100478 %
测试集准确性: 64.0 % -------------------------------------------------------
图为:
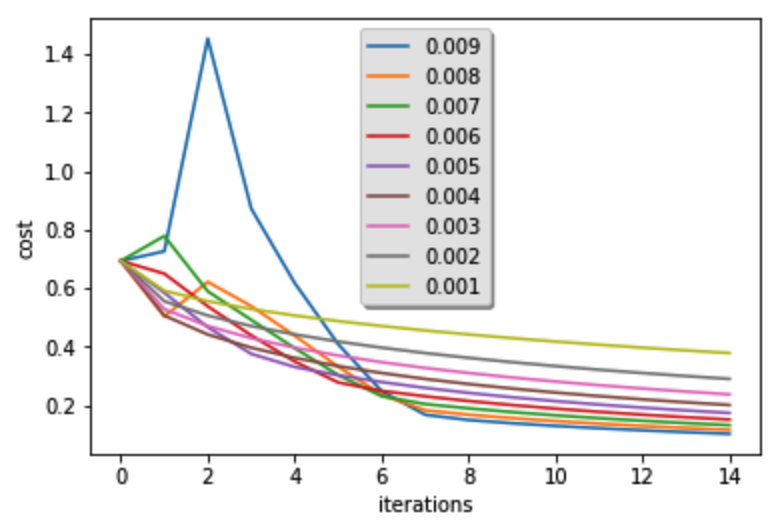
如图可见当学习率为0.005时成本函数下降的效果最好,因此上面的例子中学习率设置为了0.05
吴恩达课后作业学习1-week2-homework-logistic的更多相关文章
- 吴恩达课后作业学习1-week4-homework-two-hidden-layer -1
参考:https://blog.csdn.net/u013733326/article/details/79767169 希望大家直接到上面的网址去查看代码,下面是本人的笔记 两层神经网络,和吴恩达课 ...
- 吴恩达课后作业学习1-week4-homework-multi-hidden-layer -2
参考:https://blog.csdn.net/u013733326/article/details/79767169 希望大家直接到上面的网址去查看代码,下面是本人的笔记 实现多层神经网络 1.准 ...
- 吴恩达课后作业学习2-week1-1 初始化
参考:https://blog.csdn.net/u013733326/article/details/79847918 希望大家直接到上面的网址去查看代码,下面是本人的笔记 初始化.正则化.梯度校验 ...
- 吴恩达课后作业学习2-week1-2正则化
参考:https://blog.csdn.net/u013733326/article/details/79847918 希望大家直接到上面的网址去查看代码,下面是本人的笔记 4.正则化 1)加载数据 ...
- 吴恩达课后作业学习2-week2-优化算法
参考:https://blog.csdn.net/u013733326/article/details/79907419 希望大家直接到上面的网址去查看代码,下面是本人的笔记 我们需要做以下几件事: ...
- 吴恩达课后作业学习1-week3-homework-one-hidden-layer
参考:https://blog.csdn.net/u013733326/article/details/79702148 希望大家直接到上面的网址去查看代码,下面是本人的笔记 建立一个带有隐藏层的神经 ...
- 吴恩达课后作业学习2-week3-tensorflow learning-1-基本概念
参考:https://blog.csdn.net/u013733326/article/details/79971488 希望大家直接到上面的网址去查看代码,下面是本人的笔记 到目前为止,我们一直在 ...
- 吴恩达课后作业学习2-week3-tensorflow learning-1-例子学习
参考:https://blog.csdn.net/u013733326/article/details/79971488 使用TensorFlow构建你的第一个神经网络 我们将会使用TensorFlo ...
- 吴恩达课后作业学习2-week1-3梯度校验
参考:https://blog.csdn.net/u013733326/article/details/79847918 希望大家直接到上面的网址去查看代码,下面是本人的笔记 5.梯度校验 在我们执行 ...
随机推荐
- js 随机点名
1.对象构造函数 设置节点与人名 constructor({ printElement, startElement, stopElement , person }) { this.list = per ...
- 2; HTML 基本结构
1. HTML 的基本结构 2. HTML 控制标记的格式 3. 最常用的控制标记 本章讲解最基本的 HTML 元素,也就是创建文档结构所需的元素.例如:标题.段落. 页面分隔.注释等等. 2.1 H ...
- #WEB安全基础 : HTML/CSS | 0x2初识a标签
教你点厉害玩意,尝尝HTML的厉害! 我为了这节课写了一些东西,你来看看
- markdown 语法指南
说明:左边是markdown的语法 右边是预览.(我这里用了黑色的背景,一般白色较多) 1. 标题 2.列表 3.引用 (1)一层引用 (2)多层引用 4.图片(如果是本地:按照语法写图片路径:如果是 ...
- K8S 部署 ingress-nginx (一) 原理及搭建
Kubernetes 暴露服务的有三种方式,分别为 LoadBlancer Service.NodePort Service.Ingress.官网对 Ingress 的定义为管理对外服务到集群内服务之 ...
- 腾讯的产品思维 VS 阿里的终局思维
从成立到借壳上市,有赞用了5年多时间.这期间,它有好几次机会死掉,有很多的理由活不到今天,白鸦曾经说,每一次度过难关最关键都是靠团队的力量.谢天谢地,它活了下来. 那么,这个在To B领域敢打敢拼的团 ...
- Android为TV端助力 布局、绘制、内存泄露、响应速度、listview和bitmap、线程优化以及一些优化的建议!
1.布局优化 首先删除布局中无用的控件和层级,其次有选择地使用性能较低的viewgroup,比如布局中既可以使用RelativeLayout和LinearLayout,那我们就采用LinearLayo ...
- android常犯错误记录(一)
错误:Error:Error: Found item Attr/border_width more than one time 这个容易,属性相同了,按照提示查询一下找出来删了就行了,注意大小写很容易 ...
- 布局优化之ViewStub源码分析
源码分析 @RemoteView public final class ViewStub extends View { private int mInflatedId; private int mLa ...
- 转载:python生成以及打开json、csv和txt文件
原文地址:https://blog.csdn.net/weixin_42555131/article/details/82012642 生成txt文件: mesg = "hello worl ...