(2)Java数据结构--二叉树 -和排序算法实现
=== 注释:此人博客对很多个数据结构类都有讲解-并加以实例
Java API —— ArrayList类 & Vector类 & LinkList类
Java API —— BigDecimal类
Java API —— BigInteger类
Java API —— Calendar类
Java API —— DateFormat类
Java API —— Date类
Java API —— HashMap类 & LinkedHashMap类
Java API —— JDK5新特性
Java API —— List接口&ListIterator接口
Java API —— Map接口
Java API —— Math类
Java API —— Pattern类
Java API —— Random类
Java API —— Set接口 & HashSet类 & LinkedHashSet类
Java API —— System类
Java API —— TreeMap类
Java API —— TreeSet类
Java API —— 泛型
Java API ——Collection集合类 & Iterator接口
List应用举例
==========================
转:面试常考的数据结构Java实现 - 我是一名老菜鸟 - 博客园--其实是讲二叉树和排序--如果原文还在请调整到原文看
http://www.cnblogs.com/yangyquin/p/4921664.html
=========以下是文字复制,很长 请耐心看
1、线性表
2、线性链表
3、栈
4、队列
5、串
6、数组
7、广义表
8、树和二叉树
二叉树:每个结点至多只有两棵子树(即二叉树中不存在度大于2的结点),并且,二叉树的子树有左右之分,其次序不能任意颠倒。
二叉树的性质:
性质1:在二叉树的第 i 层上至多有2i-1个结点。
性质2:深度为k的二叉树至多有2k-1个结点(k>=1)。
性质3:对任何一颗二叉树T,如果其终端结点数为n0,度为2的结点数为n2,则n0=n2+1。
| 设n1为二叉树T中度为1的节点数,因为二叉树中所有结点的度均小于或等于2,所以其结点总数为:n=n0+n1+n2;再看二叉树中的分支数,除了根节点外,其余结点都有一个分支进入,设B为分支数,则n=B+1;由于这些分支是由度为1或2的结点射出的,所以有B=n1+2*n2,于是得n=n1+2n2+1,所以n0=n2+1 |
满二叉树:一棵深度为k且有2k-1个结点的二叉树。每一层上的结点数都是最大结点数。
完全二叉树:如果对满二叉树的结点进行连续编号,约定编号从根结点起,自上而下,自左至右。深度为k的,有n个结点的二叉树,当且仅当其每一个结点都与深度为k的满二叉树中编号从1至n的结点一一对应。
特点:(1)叶子结点只可能在层次最大的两层上出现;(2)对任一结点,若其右分支下的子孙的最大层次为h,则其左分支下的子孙的最大层次必为lh+1。
性质4:具有n个结点的完全二叉树的深度为log2n+1(2为下标,取log2n最小整数)。
性质5:如果对一棵有n个结点的完全二叉树(其深度为log2n+1)(取log2n最小整数)的结点按层序编号(从第1层到第log2n+1层,每层从左到右),则对任一结点i(1<=i<=n),有:
(1)如果i=1,则结点i是二叉树的根,无双亲;如果i>1,则其双亲PARENT(i)是结点i/2(取最小整数)。
(2)如果2i>n,则结点i无左孩子(结点i为叶子结点);否则其左孩子LCHILD(i)是结点2i。
(3)如果2i+1>n,则结点i无右孩子;否则其右孩子RCHILD(i)是结点2i+1。
最优二叉树(赫夫曼树):从树中一个结点到另一个结点之间的分支构成这两个结点之间的路径,路径上的分支数目称为路径长度。树的路径长度是从树根到每一个结点的路径长度之和。结点的带权路径长度为从该结点到树根之间的路径长度与结点上权的乘积。树的带权路径长度为树中所有叶子结点的带权路径长度之和。
二叉排序树:或者是一棵空树;或者是具有下列性质的二叉树:(1)若它的左子树不空,则左子树上所有结点的值均小于它的根节点的值;(2)若它的右子树上所有结点的值均大于它的根节点的值;(3)它的左、右子树也分别为二叉排序树。
平衡二叉树:又称AVL树。它或者是一棵空树,或者是具有下列性质的二叉树。它的左子树和右子树都是平衡二叉树,且左子树和右子树的深度只差的绝对值不超过1。若将二叉树上结点的平衡因子BF定义为该结点的左子树的深度减去它的右子树的深度,则平衡二叉树上所有结点的平衡因子只可能是-1、0和1。
红黑树:红黑树是一种自平衡排序二叉树,树中每个节点的值,都大于或等于在它的左子树中的所有节点的值,并且小于或等于在它的右子树中的所有节点的值,这确保红黑树运行时可以快速地在树中查找和定位的所需节点。
- 性质 1:每个节点要么是红色,要么是黑色。
- 性质 2:根节点永远是黑色的。
- 性质 3:所有的叶节点都是空节点(即 null),并且是黑色的。
- 性质 4:每个红色节点的两个子节点都是黑色。(从每个叶子到根的路径上不会有两个连续的红色节点)
- 性质 5:从任一节点到其子树中每个叶子节点的路径都包含相同数量的黑色节点。
Java 中实现的红黑树可能有如图所示结构:
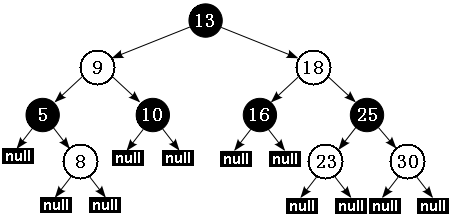
备注:本文中所有关于红黑树中的示意图采用白色代表红色。黑色节点还是采用了黑色表示。
根据性质 5:红黑树从根节点到每个叶子节点的路径都包含相同数量的黑色节点,因此从根节点到叶子节点的路径中包含的黑色节点数被称为树的“黑色高度(black-height)”。
性质 4 则保证了从根节点到叶子节点的最长路径的长度不会超过任何其他路径的两倍。假如有一棵黑色高度为 3 的红黑树:从根节点到叶节点的最短路径长度是 2,该路径上全是黑色节点(黑节点 - 黑节点 - 黑节点)。最长路径也只可能为 4,在每个黑色节点之间插入一个红色节点(黑节点 - 红节点 - 黑节点 - 红节点 - 黑节点),性质 4 保证绝不可能插入更多的红色节点。由此可见,红黑树中最长路径就是一条红黑交替的路径。
B-树:B-数是一种平衡的多路查找树,一棵m阶B-树,或为空树,或为满足下列特性的m叉树:(m≥3)
(1)根结点只有1个,关键字字数的范围[1,m-1],分支数量范围[2,m];
(2)除根以外的非叶结点,每个结点包含分支数范围[[m/2],m],即关键字字数的范围是[[m/2]-1,m-1],其中[m/2]表示取大于m/2的最小整数;
(3)非叶结点是由叶结点分裂而来的,所以叶结点关键字个数也满足[[m/2]-1,m-1];
(4)所有的非终端结点包含信息:(n,P0,K1,P1,K2,P2,……,Kn,Pn),
其中Ki为关键字,Pi为指向子树根结点的指针,并且Pi-1所指子树中的关键字均小于Ki,而Pi所指的关键字均大于Ki(i=1,2,……,n),n+1表示B-树的阶,n表示关键字个数,即[ceil(m / 2)-1]<= n <= m-1;
(5)所有叶子结点都在同一层,并且指针域为空,具有如下性质:
根据B-树定义,第一层为根有一个结点,至少两个分支,第二层至少2个结点,i≥3时,每一层至少有2乘以([m/2])的i-2次方个结点([m/2]表示取大于m/2的最小整数)。若m阶树中共有N个结点,那么可以推导出N必然满足N≥2*(([m/2])的h-1次方)-1 (h≥1),因此若查找成功,则高度h≤1+log[m/2](N+1)/2,h也是磁盘访问次数(h≥1),保证了查找算法的高效率。
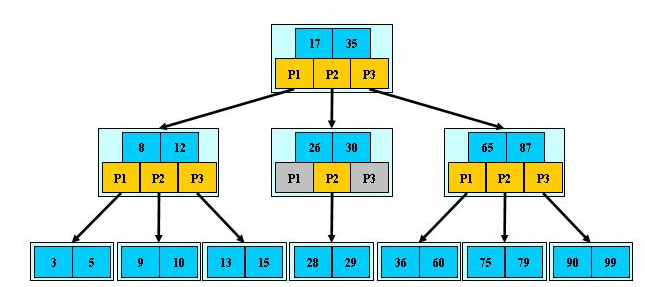
1)非叶子结点的子树指针与关键字个数相同;
2)非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间);
3)为所有叶子结点增加一个链指针;
4)所有关键字都在叶子结点出现;
9、图
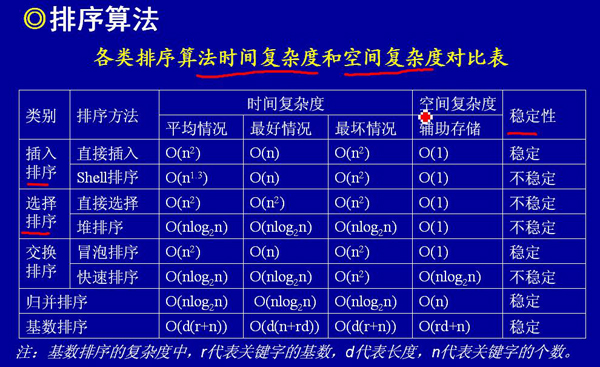
各种排序算法的比较:
一、插入排序
1、直接插入
稳定,平均和最坏都是O(n2)。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
2、Shell排序
不稳定,平均O(n3/2),最坏O(n2)。它的基本思想是先取一个小于n的整数d1作为第一个增量,把文件的全部记录分成d1个组。所有距离为dl的倍数的记录放在同一个组中。先在各组内进行直接插人排序;然后,取第二个增量d2<d1重复上述的分组和排序,直至所取的增量dt=1(dt<dt-l<…<d2<d1),即所有记录放在同一组中进行直接插入排序为止。该方法实质上是一种分组插入方法。
代码实现:
package com.yyq; import java.util.Arrays; /**
* Created by Administrator on 2015/9/9.
*/
public class InsertSort {
public static void insertDirectlySort(int a[]) {
if (a == null) return;
int len = a.length;
try {
for (int i = 0; i < len; i++) {
for (int j = i + 1; j < len && j > 0; j--) {
if (a[j] < a[j - 1]) {
int temp = a[j];
a[j] = a[j - 1];
a[j - 1] = temp;
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
} public static void shellSort(int data[]) {
if (data == null) return;
int j = 0;
int temp = 0;
int len = data.length / 2;
for (int increment = len; increment > 0; increment /= 2) {
for (int i = increment; i < data.length; i++) {
temp = data[i];
for (j = i; j >= increment; j -= increment) {
if(temp < data[j - increment]){
data[j] = data[j - increment];
}else{
break;
}
}
data[j] = temp;
}
}
} public static void Test(int a[],int b[]) {
System.out.println("The Source Secquence:");
if (a == null) return;
System.out.println(Arrays.toString(a)); insertDirectlySort(a);
System.out.println("InsertDirectlySort Result: ");
System.out.println(Arrays.toString(a)); shellSort(b);
System.out.println("ShellSort Result:");
System.out.println(Arrays.toString(b));
System.out.println();
}
public static void main(String[] args){
int a1[] = null;
int a2[] = {1};
int a3[] = {3, 6, 1, 8, 2, 9, 4};
int a4[] = {1, 3, 5, 7, 9};
int a5[] = {6, 9, 4, 8, -1};
int a6[] = {9, 5, 4, 2, 1};
int b1[] = null;
int b2[] = {1};
int b3[] = {3, 6, 1, 8, 2, 9, 4};
int b4[] = {1, 3, 5, 7, 9};
int b5[] = {6, 9, 4, 8, -1};
int b6[] = {9, 5, 4, 2, 1};
Test(a1,b1);
Test(a2,b2);
Test(a3,b3);
Test(a4,b4);
Test(a5,b5);
Test(a6,b6);
}
}

输出结果:
|
The Source Secquence: The Source Secquence: [1] InsertDirectlySort Result: [1] ShellSort Result: [1] The Source Secquence: [3, 6, 1, 8, 2, 9, 4] InsertDirectlySort Result: [1, 2, 3, 4, 6, 8, 9] ShellSort Result: [1, 2, 3, 4, 6, 8, 9] The Source Secquence: [1, 3, 5, 7, 9] InsertDirectlySort Result: [1, 3, 5, 7, 9] ShellSort Result: [1, 3, 5, 7, 9] The Source Secquence: [6, 9, 4, 8, -1] InsertDirectlySort Result: [-1, 4, 6, 8, 9] ShellSort Result: [-1, 4, 6, 8, 9] The Source Secquence: [9, 5, 4, 2, 1] InsertDirectlySort Result: [1, 2, 4, 5, 9] ShellSort Result: [1, 2, 4, 5, 9] |
二、选择排序
1、直接选择
不稳定,平均和最坏都是O(n2)。是一种简单直观的排序算法。它的工作原理如下。首先在未排序序列中找到最小元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小元素,然后放到排序序列末尾(目前已被排序的序列)。以此类推,直到所有元素均排序完毕。
2、堆排序
不稳定,平均和最坏都是O(nlogn),辅助存储O(1)。利用堆这种数据结构所设计的一种排序算法。堆是一个近似完全二叉树的结构,并同时满足堆性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
package com.yyq; import java.util.Arrays; /**
* Created by Administrator on 2015/9/9.
*/
public class SelectSort {
public static void selectDirectlySort(int[] a) {
if (a == null) return;
int min = 0;
int i = 0;
int j = 0;
int index = 0;
int len = a.length;
for (i = 0; i < len - 1; i++) {
min = a[i];
index = i;
for (j = i + 1; j < len; j++) {
if (a[j] < min) {
min = a[j];
index = j;
}
}
a[index] = a[i];
a[i] = min;
}
} public static void heapSort(int[] array) {
if (array == null) return;
buildHeap(array);//构建堆
int n = array.length;
int i = 0;
for (i = n - 1; i >= 1; i--) {
swap(array, 0, i);
heapify(array, 0, i);
}
}
//构建
public static void buildHeap(int[] array) {
int n = array.length;//数组中元素的个数
for (int i = n / 2 - 1; i >= 0; i--)
heapify(array, i, n);
}
public static void heapify(int[] A, int idx, int max) {
int left = 2 * idx + 1;// 左孩子的下标(如果存在的话)
int right = 2 * idx + 2;// 左孩子的下标(如果存在的话)
int largest = 0;//寻找3个节点中最大值节点的下标
if (left < max && A[left] > A[idx])
largest = left;
else
largest = idx;
if (right < max && A[right] > A[largest])
largest = right;
if (largest != idx) {
swap(A, largest, idx);
heapify(A, largest, max);
}
}
public static void swap(int[] array, int i, int j) {
int temp = 0;
temp = array[i];
array[i] = array[j];
array[j] = temp;
} public static void Test(int a[], int b[]) {
System.out.println("The Source Secquence:");
if (a == null) return;
System.out.println(Arrays.toString(a)); selectDirectlySort(a);
System.out.println("BubbleSort Result: ");
System.out.println(Arrays.toString(a)); heapSort(b);
System.out.println("QuickSort Result:");
System.out.println(Arrays.toString(b));
System.out.println();
} public static void main(String[] args) {
int a1[] = null;
int a2[] = {1};
int a3[] = {3, 6, 1, 8, 2, 9, 4};
int a4[] = {1, 3, 5, 7, 9};
int a5[] = {6, 9, 4, 8, -1};
int a6[] = {9, 5, 4, 2, 1};
int b1[] = null;
int b2[] = {1};
int b3[] = {3, 6, 1, 8, 2, 9, 4};
int b4[] = {1, 3, 5, 7, 9};
int b5[] = {6, 9, 4, 8, -1};
int b6[] = {9, 5, 4, 2, 1};
Test(a1, b1);
Test(a2, b2);
Test(a3, b3);
Test(a4, b4);
Test(a5, b5);
Test(a6, b6);
}
}
输出结果:
|
The Source Secquence: The Source Secquence: [1] BubbleSort Result: [1] QuickSort Result: [1] The Source Secquence: [3, 6, 1, 8, 2, 9, 4] BubbleSort Result: [1, 2, 3, 4, 6, 8, 9] QuickSort Result: [1, 2, 3, 4, 6, 8, 9] The Source Secquence: [1, 3, 5, 7, 9] BubbleSort Result: [1, 3, 5, 7, 9] QuickSort Result: [1, 3, 5, 7, 9] The Source Secquence: [6, 9, 4, 8, -1] BubbleSort Result: [-1, 4, 6, 8, 9] QuickSort Result: [-1, 4, 6, 8, 9] The Source Secquence: [9, 5, 4, 2, 1] BubbleSort Result: [1, 2, 4, 5, 9] QuickSort Result: [1, 2, 4, 5, 9] |
三、交换排序
1、冒泡排序
稳定,平均和最坏都是O(n2)。是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
2、快速排序
不稳定,平均O(nlogn),最坏O(n2),辅助存储O(logn)。基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
package com.yyq; import java.util.Arrays; /**
* Created by Administrator on 2015/9/10.
*/
public class ChangeSort {
public static void swap(int[] array, int i, int j){
int temp = array[i];
array[i] = array[j];
array[j] = temp;
}
public static void bubbleSort(int[] array){
if (array == null) return;
int len = array.length;;
for(int i = 0; i < len-1; i++){
for (int j = len-1; j > i; j--){
if (array[j] < array[j-1] ){
swap(array,j,j-1);
}
}
}
}
public static void quickSort(int[] array, int low, int high){
if (array == null || low < 0 || high < 0 || low >= array.length) return;
int pivotloc = partition(array, low, high);
if(low < high){
quickSort(array, low, pivotloc-1);
quickSort(array,pivotloc+1,high);
}
}
public static int partition(int[] array, int low, int high){
int pivokey = array[low];
while(low < high){
while(low < high && array[high] >= pivokey)
{
high--;
}
array[low] = array[high];
while(low < high && array[low] <= pivokey)
{
low++;
}
array[high] = array[low];
}
array[low] = pivokey;
return low;
}
public static void Test(int a[],int b[]) {
System.out.println("The Source Secquence:");
if (a == null) return;
System.out.println(Arrays.toString(a)); bubbleSort(a);
System.out.println("BubbleSort Result: ");
System.out.println(Arrays.toString(a)); quickSort(b, 0, b.length-1);
System.out.println("QuickSort Result:");
System.out.println(Arrays.toString(b));
System.out.println();
}
public static void main(String[] args){
int a1[] = null;
int a2[] = {1};
int a3[] = {3, 6, 1, 8, 2, 9, 4};
int a4[] = {1, 3, 5, 7, 9};
int a5[] = {6, 9, 4, 8, -1};
int a6[] = {9, 5, 4, 2, 1};
int b1[] = null;
int b2[] = {1};
int b3[] = {3, 6, 1, 8, 2, 9, 4};
int b4[] = {1, 3, 5, 7, 9};
int b5[] = {6, 9, 4, 8, -1};
int b6[] = {9, 5, 4, 2, 1};
Test(a1,b1);
Test(a2,b2);
Test(a3,b3);
Test(a4,b4);
Test(a5,b5);
Test(a6,b6);
}
}
输出结果:
|
The Source Secquence: The Source Secquence: [1] BubbleSort Result: [1] QuickSort Result: [1] The Source Secquence: [3, 6, 1, 8, 2, 9, 4] BubbleSort Result: [1, 2, 3, 4, 6, 8, 9] QuickSort Result: [1, 2, 3, 4, 6, 8, 9] The Source Secquence: [1, 3, 5, 7, 9] BubbleSort Result: [1, 3, 5, 7, 9] QuickSort Result: [1, 3, 5, 7, 9] The Source Secquence: [6, 9, 4, 8, -1] BubbleSort Result: [-1, 4, 6, 8, 9] QuickSort Result: [-1, 4, 6, 8, 9] The Source Secquence: [9, 5, 4, 2, 1] BubbleSort Result: [1, 2, 4, 5, 9] QuickSort Result: [1, 2, 4, 5, 9] |
四、归并排序(台湾译作:合并排序):
稳定,平均和最坏都是O(nlogn),辅助存储O(n)。是建立在归并操作上的一种有效的排序算法。将两个(或两个以上)有序表合并成一个新的有序表 即把待排序序列分为若干个子序列,每个子序列是有序的。然后再把有序子序列合并为整体有序序列。
package com.yyq; import java.util.Arrays; /**
* Created by Administrator on 2015/9/10.
*/
public class MergingSort { public static void Test(int a[]) {
System.out.println("The Source Secquence:");
if (a == null) return;
System.out.println(Arrays.toString(a)); mergeSort(a,0,a.length-1);
System.out.println("MergeSort Result: ");
System.out.println(Arrays.toString(a));
System.out.println();
}
public static void main(String[] args){
int a1[] = null;
int a2[] = {1};
int a3[] = {3, 6, 1, 8, 2, 9, 4};
int a4[] = {1, 3, 5, 7, 9};
int a5[] = {6, 9, 4, 8, -1};
int a6[] = {9, 5, 4, 2, 1};
Test(a1);
Test(a2);
Test(a3);
Test(a4);
Test(a5);
Test(a6);
}
public static int[] mergeSort(int[] nums, int low, int high) {
if (nums == null || low < 0 || low > nums.length-1 || high < 0) return nums;
int mid = (low + high) / 2;
if (low < high) {
// 左边
mergeSort(nums, low, mid);
// 右边
mergeSort(nums, mid + 1, high);
// 左右归并
merge(nums, low, mid, high);
}
return nums;
}
public static void merge(int[] nums, int low, int mid, int high) {
int[] temp = new int[high - low + 1];
int i = low;// 左指针
int j = mid + 1;// 右指针
int k = 0;
// 把较小的数先移到新数组中
while (i <= mid && j <= high) {
if (nums[i] < nums[j]) {
temp[k++] = nums[i++];
} else {
temp[k++] = nums[j++];
}
}
// 把左边剩余的数移入数组
while (i <= mid) {
temp[k++] = nums[i++];
}
// 把右边边剩余的数移入数组
while (j <= high) {
temp[k++] = nums[j++];
}
// 把新数组中的数覆盖nums数组
for (int k2 = 0; k2 < temp.length; k2++) {
nums[k2 + low] = temp[k2];
}
}
}
输出结果:
|
The Source Secquence: The Source Secquence: [1] MergeSort Result: [1] The Source Secquence: [3, 6, 1, 8, 2, 9, 4] MergeSort Result: [1, 2, 3, 4, 6, 8, 9] The Source Secquence: [1, 3, 5, 7, 9] MergeSort Result: [1, 3, 5, 7, 9] The Source Secquence: [6, 9, 4, 8, -1] MergeSort Result: [-1, 4, 6, 8, 9] The Source Secquence: [9, 5, 4, 2, 1] MergeSort Result: [1, 2, 4, 5, 9] |
五、基数排序又称“桶子法”:
稳定,平均和最坏都是O(d(n+rd)),对于n个记录,每个记录含d个关键字(即位数),每个关键字的取值范围为rd个值。它是透过键值的部份资讯,将要排序的元素分配至某些“桶”中,藉以达到排序的作用。
package com.yyq; import java.util.Arrays; /**
* Created by Administrator on 2015/9/10.
*/
public class RadixSort {
public static void radixSort(int[] array, int num, int radix) {
if (array == null) return;
int k = 0;
int n = 1;
int index = 1;
int len = array.length;
//分成nums.length个桶
int[][] radixArray = new int[radix][radix];
//每个桶放的个数组成的数组
int[] tempArray = new int[radix];
for (int i = 0; i < tempArray.length; i++){
tempArray[i] = 0;
}
//还在位数内
while (index <= num) {
for (int i = 0; i < len; i++) {
//个,十,百,千...
int temp = (array[i] / n) % 10;
//存入特定桶的特定位置
radixArray[temp][tempArray[temp]] = array[i];
tempArray[temp] = tempArray[temp] + 1;
}
for (int i = 0; i < radix; i++) {
if (tempArray[i] != 0) {
for (int j = 0; j < tempArray[i]; j++) {
//数组重组
array[k] = radixArray[i][j];
k++;
}
//重置,以防下次循环时数据出错
tempArray[i] = 0;
}
}
//重置,以防下次循环时数据出错
k = 0;
//进位
n *= 10;
index++;
}
} // 基数排序的实现
public static void Test(int a[]) {
System.out.println("The Source Secquence:");
if (a == null) return;
System.out.println(Arrays.toString(a));
int num = 0;
int max_num = num;
for (int i = 0; i < a.length; i++){
int temp = a[i];
while(temp != 0){
num++;
temp = temp / 10;
}
if (num > max_num){
max_num = num;
}
num = 0;
}
System.out.println("The largest number'length is:"+max_num);
radixSort(a, max_num,10);
System.out.println("RadixSort Result: ");
System.out.println(Arrays.toString(a));
System.out.println();
} public static void main(String[] args) {
int a1[] = null;
int a2[] = {1};
int a3[] = {3, 6, 1, 8, 2, 9, 4};
int a4[] = {110, 35, 4855, 2726,562599};
int a5[] = {278, 109, 930, 184, 505, 269, 800, 831};
int a6[] = {9, 35, 4, 2, 1};
Test(a1);
Test(a2);
Test(a3);
Test(a4);
Test(a5);
Test(a6);
}
}
输出结果:
|
The Source Secquence: The Source Secquence: [1] The largest number'length is:1 RadixSort Result: [1] The Source Secquence: [3, 6, 1, 8, 2, 9, 4] The largest number'length is:1 RadixSort Result: [1, 2, 3, 4, 6, 8, 9] The Source Secquence: [110, 35, 4855, 2726, 562599] The largest number'length is:6 RadixSort Result: [35, 110, 2726, 4855, 562599] The Source Secquence: [278, 109, 930, 184, 505, 269, 800, 831] The largest number'length is:3 RadixSort Result: [109, 184, 269, 278, 505, 800, 831, 930] The Source Secquence: [9, 35, 4, 2, 1] The largest number'length is:2 RadixSort Result: [1, 2, 4, 9, 35] |
(2)Java数据结构--二叉树 -和排序算法实现的更多相关文章
- java数据结构之常用排序算法
冒泡排序 private void maopao(int arr[]) { for (int i = 0; i < arr.length; i++) { for (int j = 0; j &l ...
- Java实现八种排序算法(代码详细解释)
经过一个多星期的学习.收集.整理,又对数据结构的八大排序算法进行了一个回顾,在测试过程中也遇到了很多问题,解决了很多问题.代码全都是经过小弟运行的,如果有问题,希望能给小弟提出来,共同进步. 参考:数 ...
- Java 的八种排序算法
Java 的八种排序算法 这个世界,需要遗忘的太多. 背景:工作三年,算法一问三不知. 一.八种排序算法 直接插入排序.希尔排序.简单选择排序.堆排序.冒泡排序.快速排序.归并排序和基数排序. 二.算 ...
- 数据结构(三) 用java实现七种排序算法。
很多时候,听别人在讨论快速排序,选择排序,冒泡排序等,都觉得很牛逼,心想,卧槽,排序也分那么多种,就觉得别人很牛逼呀,其实不然,当我们自己去了解学习后发现,并没有想象中那么难,今天就一起总结一下各种排 ...
- JAVA十大经典排序算法最强总结(含JAVA代码实现)
十大经典排序算法最强总结(含JAVA代码实现) 最近几天在研究排序算法,看了很多博客,发现网上有的文章中对排序算法解释的并不是很透彻,而且有很多代码都是错误的,例如有的文章中在“桶排序”算法中对每 ...
- Java实现十个经典排序算法(带动态效果图)
前言 排序算法是老生常谈的了,但是在面试中也有会被问到,例如有时候,在考察算法能力的时候,不让你写算法,就让你描述一下,某个排序算法的思想以及时间复杂度或空间复杂度.我就遇到过,直接问快排的,所以这次 ...
- java SE 常用的排序算法
java程序员会用到的经典排序算法实现 常用的排序算法(以下代码包含的)有以下五类: A.插入排序(直接插入排序.希尔排序) B.交换排序(冒泡排序.快速排序) C.选择排序(直接选择排序.堆排序) ...
- [转载]图解程序员必须掌握的Java常用8大排序算法
这篇文章主要介绍了Java如何实现八个常用的排序算法:插入排序.冒泡排序.选择排序.希尔排序 .快速排序.归并排序.堆排序和LST基数排序,分享给大家一起学习. 分类1)插入排序(直接插入排序.希尔排 ...
- Java实现常见的排序算法
一.排序算法 常见的排序算法主要分为下面几类: 选择排序 堆排序 冒泡排序 快速排序 插入排序 希尔排序 归并排序 桶式排序 基数排序 本文主要介绍选择排序.堆排序.冒泡排序.快速排序和归并排序的原理 ...
随机推荐
- 第八节、图片分割之GrabCut算法、分水岭算法
所谓图像分割指的是根据灰度.颜色.纹理和形状等特征把图像划分成若干互不交迭的区域,并使这些特征在同一区域内呈现出相似性,而在不同区域间呈现出明显的差异性.我们先对目前主要的图像分割方法做个概述,后面再 ...
- Adapter的getView
http://blog.csdn.net/yelbosh/article/details/7831812 BaseAdapter就Android应用程序中经常用到的基础数据适配器,它的主要用途是将一组 ...
- JS学习笔记Day7
一.ES5扩展方法 1.严格模式"use strict" 1)必须加在作用域的开头 2.数组扩展方法 1)indexOf(元素,从哪个下标开始查找) 作用:在数组中查找指定的元素第 ...
- CactiEZ中文解决方案和使用教程
CactiEZ中文版是最简单有效的Cacti中文解决方案,整合Spine,RRDTool和美化字体.集成Thold,Monitor,Syslog,Weathermap,Realtime,Errorim ...
- delphi架构
概要介绍:Object Pascal语言的结构比较特殊,跟C有很大的不同,但是它秉承PASCAL语言的一贯结构化的传统,相信大家很容易就可以了解. 一:Program 单元 一个object ...
- python自动化开发-[第十四天]-javascript(续)
今日概要: 1.数据类型 2.函数function 3.BOM 4.DOM 1.运算符 算术运算符: + - * / % ++ -- 比较运算符: > >= < <= != = ...
- 图论分支-倍增Tarjan求LCA
LCA,最近公共祖先,这是树上最常用的算法之一,因为它可以求距离,也可以求路径等等 LCA有两种写法,一种是倍增思想,另一种是Tarjan求法,我们可以通过一道题来看一看, 题目描述 欢乐岛上有个非常 ...
- 关于Django启动创建测试库的问题
最近项目迁移到别的机器上进行开发,启动Django的时候,有如下提示: Creating test database for alias 'default' 其实这个可能是在Django启动按钮的设置 ...
- H5新属性FileReader实现选择图片后立即显示在页面上
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- netty的HelloWorld演示
pom <dependency> <groupId>io.netty</groupId> <artifactId>netty-all</artif ...