MySQL分页查询性能优化
当需要从数据库查询的表有上万条记录的时候,一次性查询所有结果会变得很慢,特别是随着数据量的增加特别明显,这时需要使用分页查询。对于数据库分页查询,也有很多种方法和优化的点。下面简单说一下我知道的一些方法。
准备工作
为了对下面列举的一些优化进行测试,下面针对已有的一张表进行说明。
- 表名:order_history
- 描述:某个业务的订单历史表
- 主要字段:unsigned int id,tinyint(4) int type
- 字段情况:该表一共37个字段,不包含text等大型数组,最大为varchar(500),id字段为索引,且为递增。
- 数据量:5709294
- MySQL版本:5.7.16
线下找一张百万级的测试表可不容易,如果需要自己测试的话,可以写shell脚本什么的插入数据进行测试。
以下的 sql 所有语句执行的环境没有发生改变,下面是基本测试结果:
select count(*) from orders_history;返回结果:5709294
三次查询时间分别为:
- 8903 ms
- 8323 ms
- 8401 ms
一般分页查询
一般的分页查询使用简单的 limit 子句就可以实现。limit 子句声明如下:
SELECT * FROM table LIMIT [offset,] rows | rows OFFSET offsetLIMIT 子句可以被用于指定 SELECT 语句返回的记录数。需注意以下几点:
- 第一个参数指定第一个返回记录行的偏移量
- 第二个参数指定返回记录行的最大数目
- 如果只给定一个参数:它表示返回最大的记录行数目
- 第二个参数为 -1 表示检索从某一个偏移量到记录集的结束所有的记录行
- 初始记录行的偏移量是 0(而不是 1)
下面是一个应用实例:
select * from orders_history where type=8 limit 1000,10;该条语句将会从表 orders_history 中查询第1000条数据之后的10条数据,也就是第1001条到第10010条数据。
数据表中的记录默认使用主键(一般为id)排序,上面的结果相当于:
select * from orders_history where type=8 order by id limit 10000,10;三次查询时间分别为:
- 3040 ms
- 3063 ms
- 3018 ms
针对这种查询方式,下面测试查询记录量对时间的影响:
select * from orders_history where type=8 limit 10000,1;
select * from orders_history where type=8 limit 10000,10;
select * from orders_history where type=8 limit 10000,100;
select * from orders_history where type=8 limit 10000,1000;
select * from orders_history where type=8 limit 10000,10000;三次查询时间如下:
- 查询1条记录:3072ms 3092ms 3002ms
- 查询10条记录:3081ms 3077ms 3032ms
- 查询100条记录:3118ms 3200ms 3128ms
- 查询1000条记录:3412ms 3468ms 3394ms
- 查询10000条记录:3749ms 3802ms 3696ms
另外我还做了十来次查询,从查询时间来看,基本可以确定,在查询记录量低于100时,查询时间基本没有差距,随着查询记录量越来越大,所花费的时间也会越来越多。
针对查询偏移量的测试:
select * from orders_history where type=8 limit 100,100;
select * from orders_history where type=8 limit 1000,100;
select * from orders_history where type=8 limit 10000,100;
select * from orders_history where type=8 limit 100000,100;
select * from orders_history where type=8 limit 1000000,100;三次查询时间如下:
- 查询100偏移:25ms 24ms 24ms
- 查询1000偏移:78ms 76ms 77ms
- 查询10000偏移:3092ms 3212ms 3128ms
- 查询100000偏移:3878ms 3812ms 3798ms
- 查询1000000偏移:14608ms 14062ms 14700ms
随着查询偏移的增大,尤其查询偏移大于10万以后,查询时间急剧增加。
这种分页查询方式会从数据库第一条记录开始扫描,所以越往后,查询速度越慢,而且查询的数据越多,也会拖慢总查询速度。
使用子查询优化
这种方式先定位偏移位置的 id,然后往后查询,这种方式适用于 id 递增的情况。
select * from orders_history where type=8 limit 100000,1;
select id from orders_history where type=8 limit 100000,1;
select * from orders_history where type=8 and
id>=(select id from orders_history where type=8 limit 100000,1)
limit 100;
select * from orders_history where type=8 limit 100000,100;4条语句的查询时间如下:
- 第1条语句:3674ms
- 第2条语句:1315ms
- 第3条语句:1327ms
- 第4条语句:3710ms
针对上面的查询需要注意:
- 比较第1条语句和第2条语句:使用 select id 代替 select * 速度增加了3倍
- 比较第2条语句和第3条语句:速度相差几十毫秒
- 比较第3条语句和第4条语句:得益于 select id 速度增加,第3条语句查询速度增加了3倍
这种方式相较于原始一般的查询方法,将会增快数倍。
使用 id 限定优化
这种方式假设数据表的id是连续递增的,则我们根据查询的页数和查询的记录数可以算出查询的id的范围,可以使用 id between and 来查询:
select * from orders_history where type=2
and id between 1000000 and 1000100 limit 100;查询时间:15ms 12ms 9ms
这种查询方式能够极大地优化查询速度,基本能够在几十毫秒之内完成。限制是只能使用于明确知道id的情况,不过一般建立表的时候,都会添加基本的id字段,这为分页查询带来很多遍历。
还可以有另外一种写法:
select * from orders_history where id >= 1000001 limit 100;当然还可以使用 in 的方式来进行查询,这种方式经常用在多表关联的时候进行查询,使用其他表查询的id集合,来进行查询:
select * from orders_history where id in
(select order_id from trade_2 where goods = 'pen')
limit 100;这种 in 查询的方式要注意:某些 mysql 版本不支持在 in 子句中使用 limit。
使用临时表优化
这种方式已经不属于查询优化,这儿附带提一下。
对于使用 id 限定优化中的问题,需要 id 是连续递增的,但是在一些场景下,比如使用历史表的时候,或者出现过数据缺失问题时,可以考虑使用临时存储的表来记录分页的id,使用分页的id来进行 in 查询。这样能够极大的提高传统的分页查询速度,尤其是数据量上千万的时候。
关于数据表的id说明
一般情况下,在数据库中建立表的时候,强制为每一张表添加 id 递增字段,这样方便查询。
如果像是订单库等数据量非常庞大,一般会进行分库分表。这个时候不建议使用数据库的 id 作为唯一标识,而应该使用分布式的高并发唯一 id 生成器来生成,并在数据表中使用另外的字段来存储这个唯一标识。
使用先使用范围查询定位 id (或者索引),然后再使用索引进行定位数据,能够提高好几倍查询速度。即先 select id,然后再 select *;
练习一下:
表 t_hovertreenote:
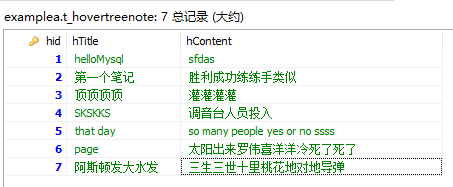
查询语句:
select hid,hTitle,hContent from t_hovertreenote order by hid asc limit 3,2;
返回数据:

查询语句:
select hid,hTitle,hContent from t_hovertreenote order by hid desc limit 4,2;
结果:

MySQL分页查询性能优化的更多相关文章
- MySQL之查询性能优化(四)
优化特定类型的查询 COUNT()的作用 COUNT()是一个特殊函数,有两个非常不同的作用:它可以统计某个列值的数量,也可以统计行数.在统计列值时要求列值是非空的(不统计NULL). 如果在COUN ...
- 使用聚集索引和非聚集索引对MySQL分页查询的优化
内容摘录来源:MSSQL123 ,lujun9972.github.io/blog/2018/03/13/如何编写bash-completion-script/ 一.先公布下结论: 1.如果分页排序字 ...
- MySql学习—— 查询性能优化 深入理解MySql如何执行查询
本篇深入了解查询优化和服务器的内部机制,了解MySql如何执行特定查询,从中也可以知道如何更改查询执行计划,当我们深入理解MySql如何真正地执行查询,明白高效和低效的真正含义,在实际应用中就能扬长避 ...
- MySQL之查询性能优化(三)
MySQL查询优化器的局限性 MySQL的万能“嵌套循环”并不是对每种查询都是最优的.不过还好,MySQL查询优化只对少部分查询不适用,而且我们往往可以通过改写查询让MySQL高效地完成工作. 关联子 ...
- MySQL之查询性能优化(二)
查询执行的基础 当希望MySQL能够以更高的性能运行查询时,最好的办法就是弄清楚MySQL是如何优化和执行查询的.MySQL执行一个查询的过程,根据图1-1,我们可以看到当向MySQL发送一个请求时, ...
- MySQL之查询性能优化(一)
为什么查询速度会慢 通常来说,查询的生命周期大致可以按照顺序来看:从客户端,到服务器,然后在服务器上进行解析,生成执行计划,执行,并返回结果给客户端.其中“执行”可以认为是整个生命周期中最重要的阶段, ...
- mysql 分页查询及优化
1.分页查询 select * from table limit startNum,pageSize 或者 select * from table limit pageSize offset star ...
- Mysql分页查询性能分析
[PS:原文手打,转载说明出处,博客园] 前言 看过一堆的百度,最终还是自己做了一次实验,本文基于Mysql5.7.17版本,Mysql引擎为InnoDB,编码为utf8,排序规则为utf8_gene ...
- mysql中百万级别分页查询性能优化
前提条件: 1.表的唯一索引 2.百万级数据 SQL语句: select c.* FROM ( SELECT a.logid FROM tableA a where 1 = 1 <#if pho ...
随机推荐
- Python之路【第一篇】Linux常见命令语句
查看当前目录: pwd 查看文件具体大小: ls -l 返回上一级: cd.. 返回根目录: cd / 创建一个隐藏文件: vim .test 显示隐藏文件: l ...
- Python中用random产生随机数的用法
>>>random.randomrandom.random()用于生成一个0到1的随机符点数: 0 <= n < 1.0 >>>random.unifo ...
- TIME_WAIT状态过多的排查
一.概述 (一)现象 服务器有两个现象,第一是tcp连接数不多,不超过10个,但是time_wait状态的2000.第二个按照以往的性质,在很少用户访问的情况下,服务器的资源几乎没有使用,比如CPU, ...
- Apache Sentry部署
三台hadoop集群,分别是master.slave1和slave2.下面是这三台机器的软件分布: master:NameNode.ZK.HiveMetaSotre.HiveServer2.Sentr ...
- NAT详解:基本原理、穿越技术(P2P打洞)、端口老化等
这是一篇介绍NAT技术要点的精华文章,来自华3通信官方资料库,文中对NAT技术原理的介绍很全面也很权威,对网络应用的应用层开发人员而言有很高的参考价值. 学习交流 移动端即时通讯学习交流: 21589 ...
- 封装一个简易版的ajax操作对象
/** * 发送ajax请求 * @type {Object} * 使用方法如下: * $ajax.request( * method: "post", //请求方式 * url: ...
- IDEA新手使用教程(详解)
IDEA从下载安装到使用,手把手教你 一.IDEA的下载 IDEA下载地址:https://www.jetbrains.com/idea/download/#section=windows IDEA ...
- springboot2.0jar包启动异常
今天碰到一个异常: 08:44:07.214 [main] ERROR org.springframework.boot.SpringApplication - Application run fai ...
- 排除Transformation Errors
当运行session时,会产生大量的Transformation Errors,这些Error会导致性能变慢 1 Transformation Errors导致性能降低的原因 当有大量记录有Trans ...
- Go Slice 使用中的小陷阱
go中的切片有两个特性: 底层的数据结构是数组 type slice struct { array unsafe.Pointer len int cap int } 包括从切片和数组派生出来的切片都是 ...