爬虫 之Requests库的详细使用
1、什么是Requests?
Requests是用Python语言编写的,基于urllib3来改写的,采用Apache2 Licensed 来源协议的HTTP库。
它比urllib更加方便,可以节约我们大量的工作,完全满足HTTP测试需求。
一句话---Python实现的简单易用的HTTP库。
1.1基本用法
安装Requests
pip3 install requests
#各种请求方式:常用的就是requests.get()和requests.post()
>>> import requests
>>> r = requests.get('https://api.github.com/events')
>>> r = requests.post('http://httpbin.org/post', data = {'key':'value'})
>>> r = requests.put('http://httpbin.org/put', data = {'key':'value'})
>>> r = requests.delete('http://httpbin.org/delete')
>>> r = requests.head('http://httpbin.org/get')
>>> r = requests.options('http://httpbin.org/get')
1.3 GET 请求
首先,构建一个最简单的GET请求,请求的链接为http://httpbin.org/get,该网站会判断如果客户端发起的是GET 请求的话,他返回相应的请求信息:
import requests
r = requests.get('http://httpbin.org/get')
print(r.text)
带参数GET请求
可以发现,我们成功发起了GET请求,返回结果中包含请求头,URL,IP等信息。
那么,对于GET 请求,如果要附加额外的信息,一般怎么添加呢?在URL后面拼接,用一个?来分割一下,参数传过来然后用&的符号来进行分割,比如现在想添加两个参数,其中name是germery,age是22.哟构造这个请求链接,是不是可以直接写成:
r = requests.get('http://httpbin.org/get?name=germery&age=22')
这样也可以,但是一般情况下,这种信息数据会用字典来存储。那么怎么构造这个链接呢?---->利用params这个参数就好了,示例如下:
import requests
data = {
'name':'germary',
'age':22
}
r = requests.get('http://httpbin.org/get',params=data)
print(r.text)
通过运行结果可以判断,请求的链接自动被构成了:http://httpbin.org/get?name=germery&age=22。
解析json
另外,网页的返回类型实际上是str类型,但是他很特殊,是JSON格式的。所以,如果想直接解析返回结果,得到一个字典格式的话,可以直接调用json()方法,示例如下:
import requests
r = requests.get('http://httpbin.org/get')
print(type(r.text))
print(r.json())
print(type(r.json()))
可以发现,调用json()方法,就可以将返回结果是JSON格式的字符串转化为字典。
但需要注意的是,如果返回的结果不是JSON 格式,便会出现解析错误,抛出json.decoder.JSONDecoderError异常。
#如果查询关键词是中文或者有其他特殊符号,则不得不进行url编码
from urllib.parse import urlencode
wb = "haiyan海燕"
encode_res = urlencode({"k":wb},encoding="utf-8")
print(encode_res) #k=haiyan%E6%B5%B7%E7%87%95
keywords = encode_res.split("=")[1] #haiyan%E6%B5%B7%E7%87%95
url = "https://www.baidu.com/s?wd=%s&pn=1"%(keywords)
# url = "https://www.baidu.com/s?"+encode_res
print(url)
# 然后拼接成url
response = requests.get(
url,
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36",
}
抓取网页
上面的请求链接返回的是JSON形式的字符串,那么如果请求普通的网页,则肯定能获得相应的内容了。下面以‘’知乎‘’----->‘’发现‘’页面为例来看一下:
import requests
import re
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/72.0.3626.121 Safari/537.36'
}
r = requests.get('https://www.zhihu.com/explore',headers=headers)
pattern = re.compile('explore-feed.*?question_link.*?>(.*?)</a>',re.S)
titles = re.findall(pattern,r.text)
print(titles)
这里我们加入headers信息,其中包含了User-Agent字段信息,也就是浏览器标识信息。如果不加这个,知乎会禁止抓取。
接下来我们用到了最基础的正则表达式来匹配出所有的问题内容。关于正则表达式的内容我会单独写篇博客,这里作为实例来配合讲解。
运行结果如下:
['\n如何进行完备而高效的法律检索?\n', '\n怎样用C语言画出一个佛祖?\n', '\n捡到狗是什么体验?\n', '\n为什么男生追到一半就不追了?\n', '\n野比大雄为什么被称为野比海皇,具体有哪些事迹?\n', '\n人的努力可以有多可怕?\n', '\n你遇到过最有教养的人是什么样的?\n', '\n欧美有没有中国当代作家的书卖的很好,任何行业的都行?\n', '\n德云社的哪个演员最会说话/双商高?\n', '\n为什么路飞的船停在码头敌人都不会破坏船呢?\n']
我们发现,这里成功的提取出了所有的问题内容。
抓取二进制数据
在上面的例子中,我们抓取的是知乎的一个页面,实际上他返回的是一个HTML文档。如果想要抓取图片、音频、视频、等文件,应该怎么办呢?
图片、音频、视频这些文件本质上都是有二进制码组成的,由于有特定的保存格式和对应的解析方式,我们才可以看到这些形形色色的多媒体。所以,想要抓取他们,就要拿到他们的二进制码。
下面以GitHub的站点图标为例来看一下:
import requests
response = requests.get('https://github.com/favicon.ico')
print(response.text)
print(response.content)
这里抓取的内容是站点图标,也就是浏览器在每一个标签上的小图标,如下图所示
这里打印了Response对象的两个属性,一个是text,一个是content。
运行结果如下图所示,其中前两行是response.text的结果,最后一行是response.content的结果。

可以注意到的,前者出现了乱码,后者结果前带了一个b,这代表是bytes类型的数据。由于图片是二进制数据,所以前者在打印是转化为str类型,也就是图片直接转化为字符串,这理所当然会出现乱码。
接着,我们将刚才的提取到的图片保存下来:
import requests
response = requests.get('https://github.com/favicon.ico')
with open('favicon.ico','wb')as f:
f.write(response.content)
这里用了open()方法,他的第一个参数是文件名称,第二个参数以二进制写的形式打开,可以向文件里写入二进制数据。
运行结束之后,可以发现在文件夹中出现了名为favicon.ico的图标,如图:
同样的,音频和视频文件也可以用这种方式获取。
添加headers
与urllib.request一样,我们也可以通过headers参数来传递头信息。
比如,在上面‘’知乎‘’的例子中,如果不传递headers,就不能正常请求:

但是如果加上headers并加上User-Agent信息,那就没问题了:
当然,我们可以在headers这个参数中任意添加其他的字段信息。
1.4 POST请求
前面我们了解了最基本的GET 请求,另外一种比较常见的请求方式是POST。使用requesrs实现POST请求同样非常简单,示例如下:
import requests
data = {
'name':'germey',
'age':''
}
r = requests.post('http://httpbin.org/post',data=data)
print(r.text)
这里还是请求http://httpbin.org/post,该网站可以判断如果请求是POST方式,就把相关请求信息返回。
运行结构如下:
{
"args": {},
"data": "",
"files": {},
"form": {
"age": "",
"name": "germey"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.21.0"
},
"json": null,
"origin": "139.226.173.216, 139.226.173.216",
"url": "https://httpbin.org/post"
}
可以发现,我们成功获得了返回结果,其中form部分就是提交的数据,这就证明POST请求成功发送了。
1.5 响应
发送请求后,得到的自然就是响应。在上面的实例中,我们使用text和content获取了响应的内容。此外,还有很多属性和方法可以用来获取信息,比如状态码、响应头、Cookies等。示例如下:
import requests
r = requests.get('http://www.jianshu.com')
print(type(r.status_code),r.status_code)
print(type(r.headers),r.headers)
print(type(r.cookies),r.cookies)
print(type(r.url),r.url)
print(type(r.history),r.history)
这里分别打出输出 status-code属性得到状态码,输出 headers属性得到响应头,输出 cookies属性得到cookies,输出 url得到URL,输出 history属性得到请求历史。
运行结果如下:
<class 'int'> 403
<class 'requests.structures.CaseInsensitiveDict'> {'Server': 'Tengine', 'Content-Type': 'text/html', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive', 'Date': 'Thu, 07 Mar 2019 11:58:21 GMT', 'Vary': 'Accept-Encoding', 'Strict-Transport-Security': 'max-age=31536000; includeSubDomains; preload', 'Content-Encoding': 'gzip', 'x-alicdn-da-ups-status': 'endOs,0,403', 'Via': 'cache25.l2nu17-1[4,0], cache19.l2nu17[4,0], cache3.cn550[86,0]', 'Timing-Allow-Origin': '*', 'EagleId': '24faeb4315519599018091620e'}
<class 'requests.cookies.RequestsCookieJar'> <RequestsCookieJar[]>
<class 'str'> https://www.jianshu.com/
<class 'list'> [<Response [301]>]
因为session_id太长,再次简写,可以看到,headers和cookies这两个属性得到的结果分别是CaseInsensitiveDict和RequestsCookieJar类型。
状态码判断
状态码常用来判断请求是否成功,而requests海亭公路一个内置的状态码查询对象request.code,示例如下:
import requests
r = requests.get('http://www.jianshu.com')
exit() if not r.status_code == requests.codes.ok else print('Request Successfully')
这里通过比较返回码和内置的成功的返回码,来保证请求得到了正常响应,输出成功请求的消息,否则程序终止,这里我们用request.code.ok得到的是成功的状态码200.
那么肯定不能只有ok这个条件码。下面列出了返回码和相应的查询条件:
信息状态码
成功状态码
重定向状态码
客户端错误状态码
服务端错误状态码
高级操作
在上满我们了解了requests的基本用法,如基本的GET、POST请求以及Response对象,接下来,我们再来了解下request的一些高级用法,如上传文件、Cookies设置。代理设置等。
1、文件上传
我们知道requests可以模拟提交一些数据。假如有的网站需要上传文件,我们也可以用它来实现。这非常简单,示例如下:
import requests
files = {
'file':open('favicon.ico','rb')
}
r = requests.post('http://www.httpbin.org/post',files=files)
print(r.text)
在之前我们保存了一个文件 favicon.ico,这次试用它来模拟文件上传的过程。需要注意的是,favicon.ico 需要和当前脚本在同一目录下。如果有其他文件,当然可以使用其他文件来上传,更改下代码即可。
{
"args": {},
"data": "",
"files": {
"file": "data:application/octet-stream;base64,AAABAAIAEBAAAAEAIAAoBQAAJgAAACAgAAABACAAKBQAAE4FAAAoAAAAEAAAACAAAAABACAAAAAAAAAFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABERE3YTExPFDg4OEgAAAAAAAAAADw8PERERFLETExNpAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABQUFJYTExT8ExMU7QAAABkAAAAAAAAAAAAAABgVFRf/FRUX/xERE4UAAAAAAAAAAAAAAAAAAAAAAAAAABEREsETExTuERERHhAQEBAAAAAAAAAAAAAAAAAAAAANExMU9RUVF/8VFRf/EREUrwAAAAAAAAAAAAAAABQUFJkVFRf/BgYRLA4ODlwPDw/BDw8PIgAAAAAAAAAADw8PNBAQEP8VFRf/FRUX/xUVF/8UFBSPAAAAABAQEDAPDQ//AAAA+QEBAe0CAgL/AgIC9g4ODjgAAAAAAAAAAAgICEACAgLrFRUX/xUVF/8VFRf/FRUX/xERES0UFBWcFBQV/wEBAfwPDxH7DQ0ROwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA0NEjoTExTnFRUX/xUVF/8SEhKaExMT2RUVF/8VFRf/ExMTTwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAERERTBUVF/8VFRf/ExMT2hMTFPYVFRf/FBQU8AAAAAIAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAITExTxFRUX/xMTFPYTExT3FRUX/xQUFOEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFBQU4RUVF/8TExT3FBQU3hUVF/8TExT5Dw8PIQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAEBAQHxMTFPgVFRf/FBQU3hERFKIVFRf/FRUX/w8PDzQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABAQEEAVFRf/FRUX/xERFKIODg44FRUX/xUVF/8SEhKYAAAAAAAAAAwAAAAKAAAAAAAAAAAAAAAMAAAAAQAAAAASEhKYFRUX/xUVF/8ODg44AAAAABERFKQVFRf/ERESwQ4ODjYAAACBDQ0N3BISFNgSEhTYExMU9wAAAHQFBQU3ERESwRUVF/8RERSkAAAAAAAAAAAAAAADExMTxhUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX/xUVF/8TExPGAAAAAwAAAAAAAAAAAAAAAAAAAAMRERSiFRUX/xUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX/xUVF/8RERSiAAAAAwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABAQED4TExOXExMT2RISFPISEhTyExMT2RMTE5cQEBA+AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAoAAAAIAAAAEAAAAABACAAAAAAAAAUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABUVKwweHh4RAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAbGxscJCQkDgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABYWHSMXFxiSFRUX8RYWF/NAQEAEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABYWGO0WFhfzFhYYlRwcHCUAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACQkJAcWFhiAFhYY+BUVF/8VFRf/FRUX/yAgIAgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFRUX/hUVF/8VFRf/FhYY+RYWGIIgICAIAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAbGxscFhYX0BUVF/8VFRf/FRUX/xUVF/8VFRf/KysrBgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAVFRf9FRUX/xUVF/8VFRf/FRUX/xYWF9IaGhoeAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFhYbLxUVF+YVFRf/FRUX/BYWGLgWFhh0FhYZZxYWGH5VVVUDAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABUVF/wVFRf/FRUX/xUVF/8VFRf/FRUX/xUVF+YWFhsvAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABoaGh0VFRfmFRUX/xUVF/wYGBhJAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFRUX+xUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX/xUVF+YaGhodAAAAAAAAAAAAAAAAAAAAAAAAAAAkJCQHFhYX0RUVF/8VFRf/FRUYnQAAAAAVFSAYFhYYcxUVF5AXFxlmJCQkBwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABwcHBIVFRf/FRUX/xUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX/xYWF9EkJCQHAAAAAAAAAAAAAAAAAAAAABYWGIEVFRf/FRUX/xUVF/EbGxscHBwcJRYWGOsVFRf/FRUX/xUVF/8XFxpOAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAGBgYQBUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX/xYWGIAAAAAAAAAAAAAAAAAVFRwkFhYY+RUVF/8VFRjuFhYaRRUVKwwWFhfPFRUX/xUVF/8VFRf/FRUX/xYWF8SAgIACAAAAAAAAAAAAAAAAAAAAAAAAAAAVFRi/FRUX/xUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX/xUVF/8VFRf/FhYY+BYWHSMAAAAAAAAAABYWGJQVFRf/FRUX/xYWF44XFxpaFhYX0RUVF/8VFRf/FRUY4hYWGIAWFhpFHBwcEgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACIiIg8XFxdCFxcZexYWF9sVFRf/FRUX/xUVF/8VFRf/FRUX/xUVF/8VFRf/FxcYkwAAAAAnJycNFRUX8hUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX/hYWGIIzMzMFAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAgICAAhYWGHQVFRf8FRUX/xUVF/8VFRf/FRUX/xUVF/8VFRfyFRUrDBYWGVIVFRf/FRUX/xUVF/8VFRf/FRUX/xUVF/8WFhh0AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABUVGGAVFRf/FRUX/xUVF/8VFRf/FRUX/xUVF/8WFhlSFRUZkRUVF/8VFRf/FRUX/xUVF/8VFRf/FRUYyv///wEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABYWGLcVFRf/FRUX/xUVF/8VFRf/FRUX/xUVGZEWFhjJFRUX/xUVF/8VFRf/FRUX/xUVF/8WFhlcAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFhYZRxUVF/8VFRf/FRUX/xUVF/8VFRf/FhYYyBYWGOEVFRf/FRUX/xUVF/8VFRf/FRUX/xcXFxYAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAgICAIFhYY+BUVF/8VFRf/FRUX/xUVF/8WFhjgFhYY9RUVF/8VFRf/FRUX/xUVF/8VFRfyAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAWFhjeFRUX/xUVF/8VFRf/FRUX/xYWGPUWFhfzFRUX/xUVF/8VFRf/FRUX/xYWGN4AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABUVGMoVFRf/FRUX/xUVF/8VFRf/FhYX8xUVGNkVFRf/FRUX/xUVF/8VFRf/FhYY9P///wEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFhYY4RUVF/8VFRf/FRUX/xUVF/8VFRjZFRUYvxUVF/8VFRf/FRUX/xUVF/8VFRf/HBwcJQAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACAgIBAVFRf/FRUX/xUVF/8VFRf/FRUX/xUVGL8WFhiVFRUX/xUVF/8VFRf/FRUX/xUVF/8WFhh2AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAFRUYYRUVF/8VFRf/FRUX/xUVF/8VFRf/FhYYlRYWGUcVFRf/FRUX/xUVF/8VFRf/FRUX/xYWGPQZGRkfAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABsbGxMWFhjrFRUX/xUVF/8VFRf/FRUX/xUVF/8WFhlHKysrBhUVF/EVFRf/FRUX/xUVF/8VFRf/FRUX/xYWGV0AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAGBgYSRUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX8SsrKwYAAAAAFhYYlxUVF/8VFRf/FRUX/xUVF/8VFRf/GRkZMwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAaGhoeFRUX/xUVF/8VFRf/FRUX/xUVF/8WFhiXAAAAAAAAAAAVFSAYFhYY9BUVF/8VFRf/FRUX/xUVF/8YGBg1AAAAAAAAAAAAAAAAFRUrDBgYGCqAgIACAAAAAAAAAAAAAAAAAAAAAP///wEbGxsmHh4eEQAAAAAAAAAAAAAAABcXFyEVFRf/FRUX/xUVF/8VFRf/FhYY9BUVIBgAAAAAAAAAAAAAAAAWFhiCFRUX/xUVF/8VFRf/FRUX/xcXGWYAAAAAQEBABBcXF2IWFhfnFRUX/xYWF/MWFhfSFRUYwRUVGMAWFhfRFRUX8BUVF/8WFhjtFRUYbCsrKwYAAAAAFhYZUhUVF/8VFRf/FRUX/xUVF/8WFhiCAAAAAAAAAAAAAAAAAAAAACQkJAcWFhjIFRUX/xUVF/8VFRf/FRUY1hUVGKgWFhjsFRUX/xUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX7xUVGKoVFRjNFRUX/xUVF/8VFRf/FhYYyCQkJAcAAAAAAAAAAAAAAAAAAAAAAAAAABUVIBgVFRjjFRUX/xUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX/xUVGOMVFSAYAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABYWHC4VFRjjFRUX/xUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX/xUVF/8VFRjjFhYcLgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABUVIBgWFhjIFRUX/xUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX/xUVF/8VFRf/FhYYyBUVIBgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACQkJAcWFhiCFhYY9BUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX/xUVF/8VFRf/FhYY9BYWGIIkJCQHAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAVFSAYFhYYlxUVF/EVFRf/FRUX/xUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX/xUVF/8VFRf/FRUX8RYWGJcVFSAYAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAKysrBhYWGUcWFhiVFRUYvxUVGNkWFhfzFhYX8xUVGNkVFRi/FhYYlRYWGUcrKysGAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA="
},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "",
"Content-Type": "multipart/form-data; boundary=bc5b787ed0aaa230edb1b69ac4c30b65",
"Host": "www.httpbin.org",
"User-Agent": "python-requests/2.21.0"
},
"json": null,
"origin": "139.226.173.216, 139.226.173.216",
"url": "https://www.httpbin.org/post"
}
这个网站会返回响应,里面包含files这个字段,而form字段是空的,说明文件上传部分会单独有一个files字段来标识。
Cookies
前面我们使用urllib处理过Cookies,写法比较复杂,而有了requests,获取和设置Cookies只需一步即可完成。
我们先用一个实例看一下获取Cookies的过程:
import requests
r = requests.get('https://www.baidu.com')
print(r.cookies)
for key,value in r.cookies.items():
print(key + '=' + value)
运行结果如下:
<RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
BDORZ=27315
这里我们首先调用 Cookies 属性即可成功得到Cookies,可以发现它是RequestsCookieJar类型。
然后用items()方法将其转化为元组组成的列表,遍历输出每一个Cookies的名称和值,实现Cookies的遍历解析。
当然,我们也可以直接用Cookies来维持登录状态,下面以知乎为例来说明。首先登录知乎,将Headers中的Cookies内容复制下来,如下图所示:
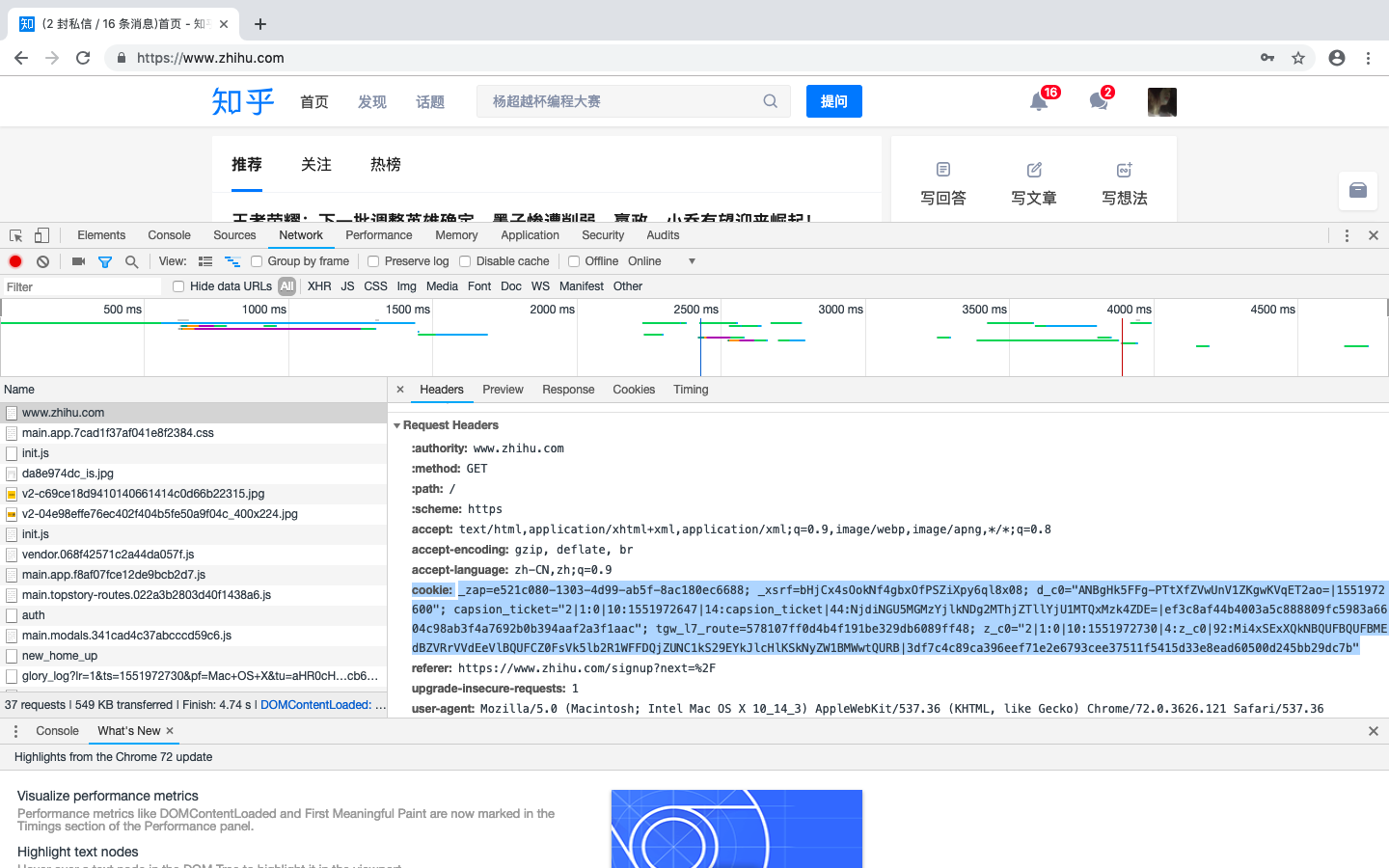
Headers中的Cookies
cookie: _zap=e521c080-1303-4d99-ab5f-8ac180ec6688; _xsrf=bHjCx4sOokNf4gbxOfPSZiXpy6ql8x08; d_c0="ANBgHk5FFg-PTtXfZVwUnV1ZKgwKVqET2ao=|1551972600"; capsion_ticket="2|1:0|10:1551972647|14:capsion_ticket|44:NjdiNGU5MGMzYjlkNDg2MThjZTllYjU1MTQxMzk4ZDE=|ef3c8af44b4003a5c888809fc5983a6604c98ab3f4a7692b0b394aaf2a3f1aac"; tgw_l7_route=578107ff0d4b4f191be329db6089ff48; z_c0="2|1:0|10:1551972730|4:z_c0|92:Mi4xSExXQkNBQUFBQUFBMEdBZVRrVVdEeVlBQUFCZ0FsVk5lb2R1WFFDQjZUNC1kS29EYkJlcHlKSkNyZW1BMWwtQURB|3df7c4c89ca396eef71e2e6793cee37511f5415d33e8ead60500d245bb29dc7b"
这里可以替换成你自己的Cookies,将其设置到Headers里面,然后发送请求,示例如下:
当然,我们也可以通过cookies参数来设置,不过这样就需要构造RequestsCookieJar对象,而且需要分割一下cookies。这相对繁琐,不过效果还是相同的,示例如下:
会话维持
在requests中,如果直接利用get()或post()等方法的确可以做到模拟网页的请求,但是这实际上是相当于不同的会话,也就是说相当于你用了两个浏览器打开了不同的页面。
设想这样一个场景,第一个请求用post()方法登录了某个网站,第二次想获取成功登陆后的自己的个人信息,你有用了一次get()方法去请求这个人信息页面。实际上,这相当于打开了两个浏览器,是两个完全不相关的会话,能成功获取个人信息吗?那当然不能。
SSL证书验证
代理设置
对于某些网站,在测试的时候请求几次,能正常获取内容。但是一旦开始大规模爬取,对于大规模且频繁的请求,网站可能会弹出验证码,或者跳到登录认证页面,更甚至可能会直接封禁客户端的IP,导致一段时间内无法访问。
那么为了防止这种情况发生,我们需要设置代理来解决这个问题,这就需要用到proxies参数。可以用这样的方式设置:
import requests
proxies = {
'http':'http://10.10.1.10:3128',
'https':'http://10.10.1.10:1080',
}
requests.get('https://www.taobao.com',proxies=proxies)
import requests
proxies = {
'http':'http://user:password@10.10.1.10:3128',
}
requests.get('https://www.taobao.com',proxies=proxies)
超时设置
在本机网络不好或者服务器网络延迟响应太慢甚至无响应时,我们可能会等待特别就得时间才可能收到响应,甚至到最后收不到响应而报错。为了防止服务器不能及时响应,应该设置一个超时时间,即超过了这个时间还没得到响应,那就报错。这需要用到timeout这个参数。这个时间的计算是发出请求到服务器返回响应的时间。示例如下:
身份认证
Prepared Request
爬虫 之Requests库的详细使用的更多相关文章
- Python爬虫之requests库介绍(一)
一:Requests: 让 HTTP 服务人类 虽然Python的标准库中 urllib2 模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 ...
- python爬虫之requests库
在python爬虫中,要想获取url的原网页,就要用到众所周知的强大好用的requests库,在2018年python文档年度总结中,requests库使用率排行第一,接下来就开始简单的使用reque ...
- 爬虫相关--requests库
requests的理想:HTTP for Humans 一.八个方法 相比较urllib模块,requests模块要简单很多,但是需要单独安装: 在windows系统下只需要在命令行输入命令 pip ...
- Python爬虫:requests 库详解,cookie操作与实战
原文 第三方库 requests是基于urllib编写的.比urllib库强大,非常适合爬虫的编写. 安装: pip install requests 简单的爬百度首页的例子: response.te ...
- Python爬虫之requests库的使用
requests库 虽然Python的标准库中 urllib模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests宣传是 "HTTP for ...
- 【Python爬虫】爬虫利器 requests 库小结
requests库 Requests 是一个 Python 的 HTTP 客户端库. 支持许多 HTTP 特性,可以非常方便地进行网页请求.网页分析和处理网页资源,拥有许多强大的功能. 本文主要介绍 ...
- 爬虫值requests库
requests简介 简介 Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库 ,使用起来比urllib简洁很多 因为是第三方库, ...
- (爬虫)requests库
一.requests库简介 urllib库和request库的作用一样,都是服务器发起请求数据,但是requests库比urllib库用起来更方便,它的接口更简单,选用哪种库看自己. 如果没有安装过这 ...
- 【Python爬虫】Requests库的基本使用
Requests库的基本使用 阅读目录 基本的GET请求 带参数的GET请求 解析Json 获取二进制数据 添加headers 基本的POST请求 response属性 文件上传 获取cookie 会 ...
随机推荐
- python之模块与包
一模块 二包 一模块 常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀. 但其实import加载的模块分为四个通用类别: 1 使用python编写的代 ...
- python六十四课——高阶函数练习题(一)
1.lt = ['sdfasdfa', 'ewqrewrewqr', 'dsafa12312fdsafd', 'safsadf'] --> 得到长度列表2.tp = ('TOM', 'Lilei ...
- Oracle调整顾问(SQL Tuning Advisor 与 SQL Access Advisor
在Oracle数据库出现性能问题时,使用Oracle本身的工具包,给出合理的调优建议是比较省力的做法. tuning advisor 是对输入的sql set的执行计划进行优化accsee advis ...
- 二、Oracle 数据库基本操作
一.oracle常用数据类型数字:number(p,s) p表示数字的长度包括小数点后的位数,s表示小数点后的位数固定长度字符:char(n):n表示最大长度,n即是最大也是固定的长度,当数据不满长度 ...
- Home Assistant-自动化设备
触发器(trigger) 条件(condition) 动作(action) 自动化中的模板(template) 触发器(trigger) 时间(time)触发器时间触发器在指定的时间触发规则,可以是某 ...
- pytorch visdom可视化工具学习—1—详细使用-1—基本使用函数
使用教程,参考: https://github.com/facebookresearch/visdom https://www.pytorchtutorial.com/using-visdom-for ...
- 01-认识Jenkins
1.1 Jenkins是什么? Jenkins官网: http://jenkins.io/ .Jenkins前身是Hudson,使用java语言开发的自动化发布工具.在中大型金融等企业中普遍使用Jen ...
- A2D Framework - 看如何精简业务逻辑 - 缓存子系统
A2D中一项功能是关于Cache的,能够将判断.获取.删除cache的代码缩减到最少量,如下是Order业务逻辑的demo示范: interface IOrder { [Cachable()] str ...
- 性能调优3:硬盘IO性能
数据库系统严重依赖服务器的资源:CPU,内存和硬盘IO,通常情况下,内存是数据的读写性能最高的存储介质,但是,内存的价格昂贵,这使得系统能够配置的内存容量受到限制,不能大规模用于数据存储:并且内存是易 ...
- [C#] LINQ之Join与GroupJoin
声明:本文为www.cnc6.cn原创,转载时请注明出处,谢谢! 一.编写Person与City类,如下: class Person { public int CityID { set; get; } ...