python网络爬虫笔记(二)
一、函数调用的默认设置
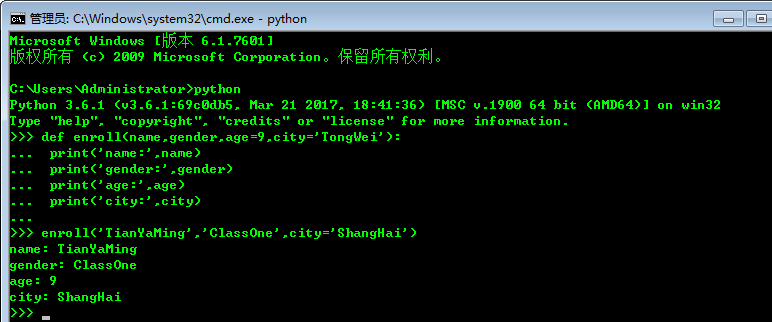
1、def enroll(name,grnder,age=4,city='Shanghai'):
print (''name:',name)
print (''gender', gender)
print('city',city)
print (''age', age)
这样调用参数的时候只需要传入 变化的参数 enroll('TianYaming','classONe'')
默认参数不符合的可以传入不同的参数。 enroll('TianYaming', 'ClassOne' '5) 注意参数的提供是按照 原先的预定的顺序执行

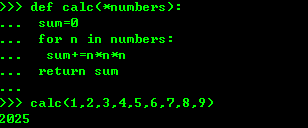
2、关键字参数

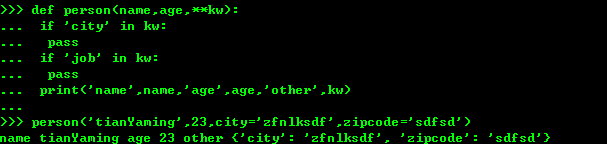
3、命名关键字参数 函数的调用者可以传入不受限制的的关键字参数,至于传入那些参数,就需要函数内部通过kw检查
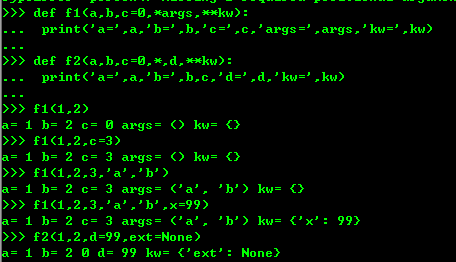
4、和关键字参数**kw不同,命名关键字参数需要一个特殊分隔符*,*后面的参数被视为命名关键字参数。

则也就是说,命名关键字参数必须传入参数名,不然报错
5、递归函数的使用
使用递归函数,要注意堆栈的溢出,理论上所有的递归可以写成循环的函数,但是循环的结构不如递归清晰
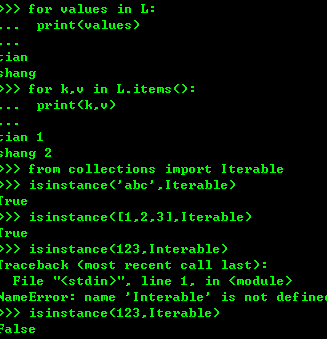
默认情况下,dict迭代的是key。如果要迭代value,可以用for value in d.values(),如果要同时迭代key和value,可以用for k, v in d.items()。
由于字符串也是可迭代对象
判断可以迭代的方法就是 使用collections 模块中的Iterable

python网络爬虫笔记(二)的更多相关文章
- Python网络爬虫笔记(五):下载、分析京东P20销售数据
(一) 分析网页 下载下面这个链接的销售数据 https://item.jd.com/6733026.html#comment 1. 翻页的时候,谷歌F12的Network页签可以看到下面 ...
- python 网络爬虫(二) BFS不断抓URL并放到文件中
上一篇的python 网络爬虫(一) 简单demo 还不能叫爬虫,只能说基础吧,因为它没有自动化抓链接的功能. 本篇追加如下功能: [1]广度优先搜索不断抓URL,直到队列为空 [2]把所有的URL写 ...
- python 网络爬虫(二)
一.编写第一个网络爬虫 为了抓取网站,我们需要下载含有感兴趣的网页,该过程一般被称为爬取(crawling).爬取一个网站有多种方法,而选择哪种方法更加合适,则取决于目标网站的结构. 首先探讨如何安全 ...
- Python网络爬虫笔记(二):链接爬虫和下载限速
(一)代码1(link_crawler()和get_links()实现链接爬虫) import urllib.request as ure import re import urllib.parse ...
- python网络爬虫之二requests模块
requests http请求库 requests是基于python内置的urllib3来编写的,它比urllib更加方便,特别是在添加headers, post请求,以及cookies的设置上,处理 ...
- python网络爬虫笔记(三)
一.切片和迭代 1.列表生成式 2.生成器的generate,但是generate保存的是算法,所以可以迭代计算,没有必要,每次调用generate 二.iteration 循环 1.凡是作用于for ...
- Python网络爬虫笔记(四):使用selenium获取动态加载的内容
(一) 说明 上一篇只能下载一页的数据,第2.3.4....100页的数据没法获取,在上一篇的基础上修改了下,使用selenium去获取所有页的href属性值. 使用selenium去模拟浏览器有点 ...
- Python网络爬虫笔记(一):网页抓取方式和LXML示例
(一) 三种网页抓取方法 1. 正则表达式: 模块使用C语言编写,速度快,但是很脆弱,可能网页更新后就不能用了. 2. Beautiful Soup 模块使用Python编写,速度慢. ...
- [Python]网络爬虫(二):利用urllib2通过指定的URL抓取网页内容
版本号:Python2.7.5,Python3改动较大. 所谓网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地. 类似于使用程序模拟IE浏览器的功能,把URL作为HTTP请求的 ...
随机推荐
- LOJ #6374「SDWC2018 Day1」网格
模拟赛考过的题 当时太菜了现在也一样只拿到了$ 30$分 回来填个坑 LOJ #6374 题意 你要从$ (0,0)$走到$ (T_x,T_y)$,每次移动的坐标增量满足$ 0 \leq \Delta ...
- 剑指Offer-第一个只出现一次的字符位置
题目描述 在一个字符串(1<=字符串长度<=10000,全部由字母组成)中找到第一个只出现一次的字符,并返回它的位置 思路 思路一: 使用整型数组对出现次数进行统计. 思路二: 使用Bit ...
- yum 记一次安装时的报错
我电脑是centos 6.8,我先安装了openslp-2.0.0-3.el6.x86_64.rpm 然后我更改了yum源配置文件,我将updates源给禁用了,只保留os源和extras源,注意了, ...
- #6284. 数列分块入门 8(区间询问等于一个数 cc 的元素,并将这个区间的所有元素改为 c)
题目链接:https://loj.ac/problem/6284 题目大意:中文题目 具体思路:还是和sqrt那个题的思路相同的,标记每一块的值是不是相同的,注意lazy下标的下放. AC代码: #i ...
- 【运维】略谈Raid级别
*何为Raid? Raid就是磁盘阵列(Redundant Arrays of Independent Disks,RAID),有"独立磁盘构成的具有冗余能力的阵列&quo ...
- Tomcat安装7.0.91
版本升级,JDK 1.7,Tomcat从7.0.73升级到7.0.91 为什么升级?解决安全漏洞! 升级就正常流程,下载*.tar.gz ,解压,改配置. 但碰到神奇的坑: 1.server.xml中 ...
- powerdesigner 使用技巧 建模工具 导出sql 导出实体类 导出word
显示comment列 Table Properties(表属性)=>Columns(列)=>Customize Columns and Filter(自定义列过滤) 勾上 comment ...
- hibernate框架学习之数据抓取(加载)策略
Hibernate获取数据方式 lHibernate提供了多种方式获取数据 •load方法获取数据 •get方法获取数据 •Query/ Criteria对象获取数据 lHibernate获取的数据分 ...
- web@css普通布局 , 高级布局 , 布局坑
1.高级布局<文档流概念>:页面从上至下,块式标签一行一行排列,内联式一行中从左至右排列<BFC规则>:左右位置(左右margin)垂直位置(上下margin)容器内外(互不影 ...
- Redis高级特性介绍及实例分析
转自:http://www.jianshu.com/p/af7043e6c8f9 Redis基础类型回顾 String Redis中最基本,也是最简单的数据类型.注意,VALUE既可以是简单的St ...