python14 常用模块 二
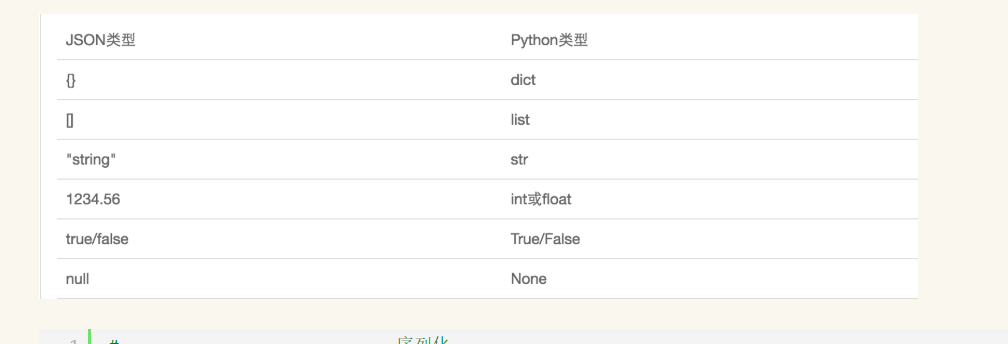
- 一.json模块
强大:不同语言之间可以进行数据交换
序列化:把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
#json 不认单引号
#dct=str({"1":111})#报错,因为生成的数据还是单引号:{'one': 1}
无论数据是怎样创建的,只要满足json格式,就可以json.loads出来,不一定非要dumps的数据才能loads
json.dumps(dic) 序列化 将python中的字典类型转为字符串类型;
json.loads()反序列化 是将json格式的字符串转为字典类型。
json.dump()函数是将json格式的字符串写到一个文件中。
json.load()是从文件中读出json格式的字符串;
- 二. pickle模块
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。
pickle序列化后是字节
使用上完全一样
不能跨语言传输
三.shelve模块
shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型
,不能跨语言传输
import shelve
f = shelve.open(r'shelve.txt')# f['stu1_info']={'name':'alex','age':'18'}# f['stu2_info']={'name':'alvin','age':'20'}# f['school_info']={'website':'oldboyedu.com','city':'beijing'}### f.close()print(f.get('stu_info')['age'])四.xml模块
跨语言传输
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
print(root.tag)
#遍历xml文档
for child in root:
print(child.tag, child.attrib)
for i in child:
print(i.tag,i.text)
#只遍历year 节点
for node in root.iter('year'):
print(node.tag,node.text)
#---------------------------------------
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
#修改
for node in root.iter('year'):
new_year = int(node.text) + 1
node.text = str(new_year)
node.set("updated","yes")
tree.write("xmltest.xml")
#删除node
for country in root.findall('country'):
rank = int(country.find('rank').text)
if rank > 50:
root.remove(country)
tree.write('output.xml')
创建xml
import xml.etree.ElementTree as ET
new_xml = ET.Element("namelist")
name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"})
age = ET.SubElement(name,"age",attrib={"checked":"no"})
sex = ET.SubElement(name,"sex")
sex.text = '33'
name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"})
age = ET.SubElement(name2,"age")
age.text = '19'
et = ET.ElementTree(new_xml) #生成文档对象
et.write("test.xml", encoding="utf-8",xml_declaration=True)
ET.dump(new_xml) #打印生成的格式
创建xml文档
- 五.logging模块
import logging
logging.debug('debug message')
logging.info('info message')
logging.warning('warning message')
logging.error('error message')
logging.critical('critical message')
默认情况下Python的logging模块将日志打印到了标准输出中,
且只显示了大于等于WARNING级别的日志,
这说明默认的日志级别设置为WARNING(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG > NOTSET),
默认的日志格式为日志级别:Logger名称:用户输出消息。
1.配置(用的不多)
logging.basicConfig(level=logging.DEBUG, //等级
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s', //日志模板
datefmt='%a, %d %b %Y %H:%M:%S', //时间格式模板
filename='/tmp/test.log', //存储位置
filemode='w') //打开日志文件,默认为追加
2.常用格式
logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有
filename:用指定的文件名创建FiledHandler(后边会具体讲解handler的概念),这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open('test.log','w')),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。 format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s用户输出的消息
3.logger对象

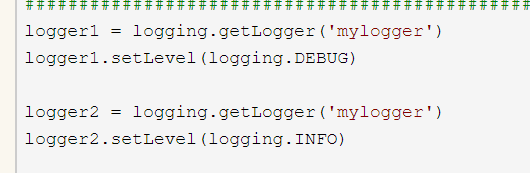 注意getLogger方法,带名字一样,则是一个对象,Level会被后面的覆盖
注意getLogger方法,带名字一样,则是一个对象,Level会被后面的覆盖
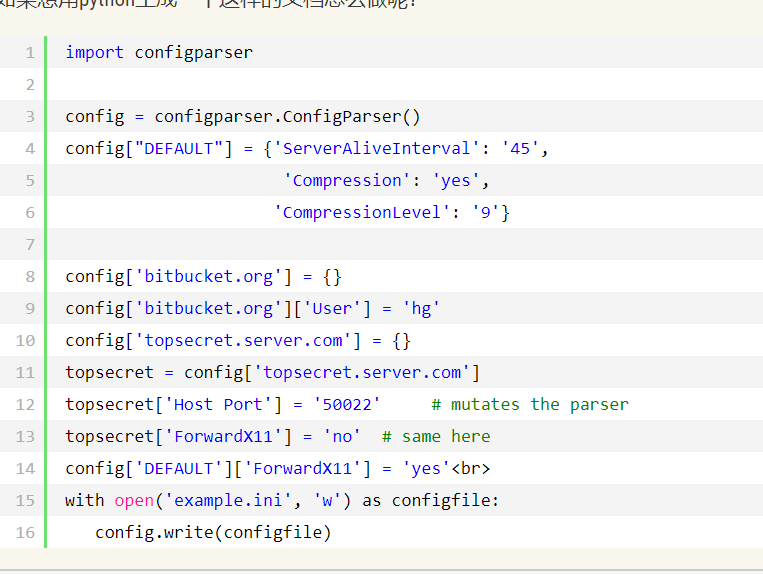
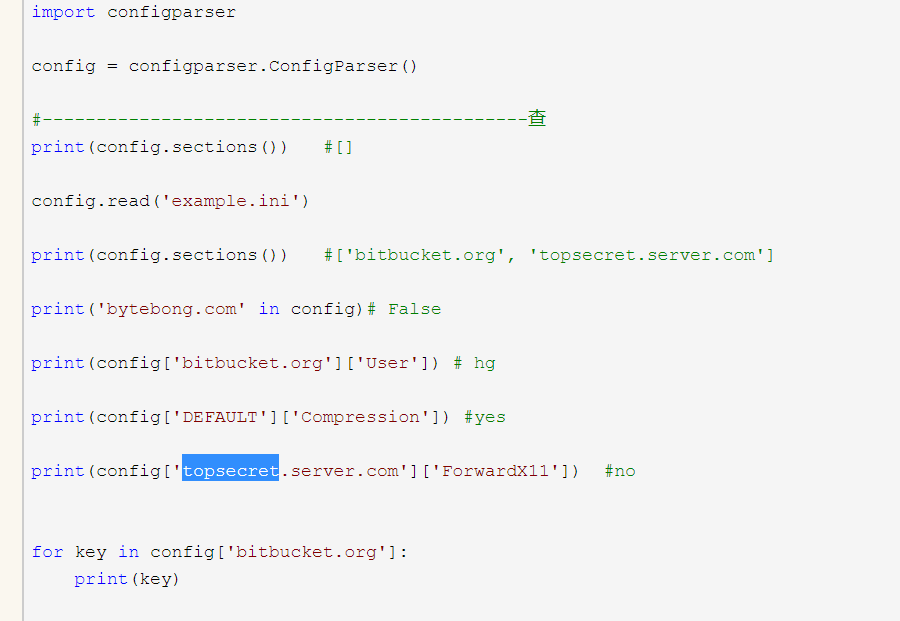
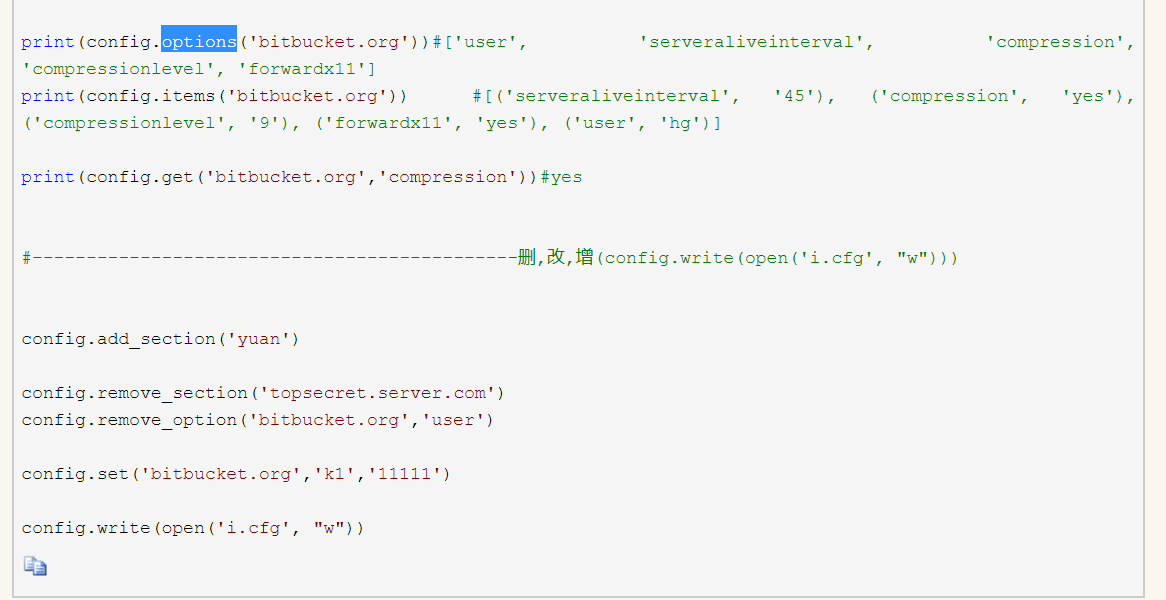
- 六.configparser模块
1.配置文件解析模块
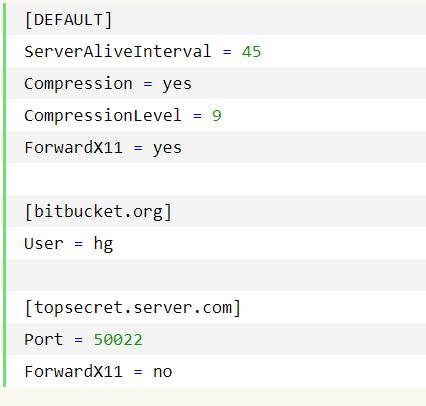
结果
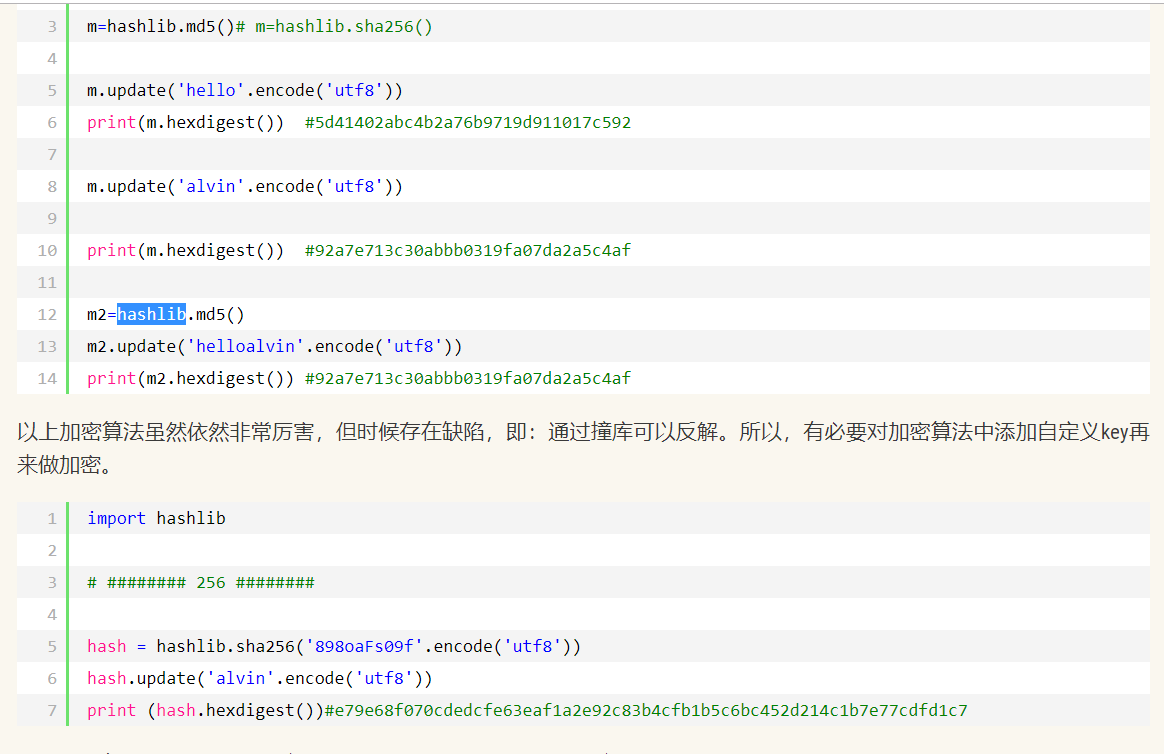
- 七 hashlib模块
1.用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
2.用法
python14 常用模块 二的更多相关文章
- 常用模块二(hashlib、configparser、logging)
阅读目录 常用模块二 hashlib模块 configparse模块 logging模块 常用模块二 返回顶部 hashlib模块 Python的hashlib提供了常见的摘要算法,如MD5,SH ...
- python之常用模块二(hashlib logging configparser)
摘要:hashlib ***** logging ***** configparser * 一.hashlib模块 Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等. 摘要算法 ...
- Python自动化开发 - 常用模块(二)
本节内容 1.shutil模块 2.shelve模块 3.xml处理模块 4.configparser模块 5.hashlib模块 6.subprocess模块 7.re模块 一.shutil模块 高 ...
- Python常用模块二
一.time & datetime #_*_coding:utf-8_*_ import time # print(time.clock()) #返回处理器时间,3.3开始已废弃 , 改成了t ...
- Python常用模块(二)
一.json与pickle json与pickle模块是为了完成数据的序列化. 序列化是指把对象(变量)从内存中变成可存储或传输的过程,在Python中叫picking,在其他语言中也由其他的叫法,但 ...
- DAY18 常用模块(二)
一.随机数:RANDOM 1.(0,1)小数:random.random() 2.[1,10]整数:random.randint(1,10) 3.[1,10)整数:random.randrang(1, ...
- python之路----常用模块二
collections模块 在内置数据类型(dict.list.set.tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter.deque.defaultdict. ...
- Python中常用模块二
一.hashlib (加密) hashlib:提供摘要算法的模块 1.正常的md5算法 import hashlib # 提供摘要算法的模块 md5 = hashlib.md5() md5.upd ...
- python:常用模块二
1,hashlib模块---摘要算法 import hashlib md5 = hashlib.md5() md5.update('how to use md5 in python hashlib?' ...
随机推荐
- [持续交付实践] Jenkins Pipeline 高可用设计方法
前言 这篇写好一段时间了,一直也没发布上来,今天稍微整理下了交下作业,部分内容偷懒引用了一些别人的内容.使用Jenkins做持续集成/持续交付,当业务达到一定规模的时候,Jenkins本身就很容易成为 ...
- 将自己的SpringBoot应用打包发布到Linux下Docker中
目录 将自己的SpringBoot应用打包发布到Linux下Docker中 1. 环境介绍 2. 开始前的准备 2.1 开启docker远程连接 2.2 新建SpringBoot项目 3. 开始构建我 ...
- 质心坐标(barycentric coordinates)及其应用
一.什么是质心坐标? 在几何结构中,质心坐标是指图形中的点相对各顶点的位置. 以图1的线段 AB 为例,点 P 位于线段 AB 之间, 图1 线段AB和点P 此时计算点 P 的公式为 . 同理,在三角 ...
- 如何用Bat批处理自制自解压文件
转载▼http://blog.sina.com.cn/s/blog_48462a890102e0nu.html 1.在桌面上新建一个文本文档,如:“新建 文本文档.txt”,方法是:在桌面的空 ...
- ubuntu装bochs的常见问题
1.Message: dlopen failed for module ‘x’: file not found 原因 未安装bochs-x的缘故 解决办法 sudo apt-get install b ...
- 常用的web服务器软件整理(win+linux)
(1)Apache Apache是世界使用排名第一的Web服务器软件.它可以运行在几乎所有广泛使用的计算机平台上.Apache源于NCSAhttpd服务器,经过多次修改,成为世界上最流行的Web服务器 ...
- Server Memory Server Configuration Options 服务器内存服务配置选项
Server Memory Server Configuration Options https://docs.microsoft.com/en-us/sql/database-engine/conf ...
- VS2019正式版注册码秘钥
Visual Studio 2019 EnterpriseBF8Y8-GN2QH-T84XB-QVY3B-RC4DF Visual Studio 2019 ProfessionalNYWVH-HT4X ...
- C#使用Mutex实现单例应用程序
不少应用程序有单一实例的需求,也就是同时只能开启一个实例(一般也就是一个进程). 实现的方式可能有判断进程名字,使用特殊文件等等,但是最靠谱的方式还是使用系统提供的 Mutex 工具. Mutex是互 ...
- 【CPU微架构设计】分布式多端口(4写2读)寄存器堆设计
寄存器堆(Register File)是微处理的关键部件之一.寄存器堆往往具有多个读写端口,其中写端口往往与多个处理单元相对应.传统的方法是使用集中式寄存器堆,即一个集中式寄存器堆匹配N个处理单元.随 ...