kafka学习笔记——基本概念与安装
Kafka是一个开源的,轻量级的、分布式的、具有复制备份、基于zooKeeper协调管理的分布式消息系统。
它具备以下三个特性:
能够发布订阅流数据:
存储流数据时,提供相应的容错机制
当流数据到达时,能够被及时处理。
首发于个人博客网站:链接地址
下载安装
本次安装只介绍在linux环境下,windows的暂时不考虑。
下载
作为一个消息中间件,kafka并不是一个jar包,而是一个完整的应用,所以直接取官网下载部署包.
下载地址:https://kafka.apache.org/downloads
这里选择:
下载完毕之后,可以使用winSCP上传到服务器中。
也可以使用wget命令,直接下载:
wget http://mirrors.shuosc.org/apache/kafka/1.1.1/kafka_2.11-1.1.1.tgz
配置
下载完安装包之后,把它放在/usr/local
1 tar -zxf kafka_2.11-1.1.1.tgz
2 mv kafka_2.11-1.1.1.tgz kafka
换个目录名称,kafka看起来更简洁一些。
启动服务
kafka是依赖于zookeeper的,所以再启动kafka之前需要先启动zookeeper。
之前看到某书,书中说是要再去下载一个zookeeper,其实是没必要的,kafka部署包中本身就有zookeeper。
首先进入kafka目录
cd /usr/local/kakfa
启动zookeeper:
执行完命令后使用jps命令查看是否启动:
1 [root@izbp18twqnsvndjvj1mnagz kafka]# jps
2 9088 app.jar
3 25170 Jps
4 24539 QuorumPeerMain
看到有QuorumPeerMain,说明zookeeper启动成功了。
启动kafka:
当然,你也可以去掉 -daemon,这样就不会kafka占用控制台了。
还是使用jps命令查看运行是否启动成功:

现在已经完成了helloWorld的第一步,接下来,就了解一下kafka的基本概念,进行验证。
Kafka中几个关键概念
Kafka的使用场景:
1.构建实时的数据流管道,系统和应用程序能够可靠的获取消息。
2.构建转换或响应数据流的实时流应用程序.
基本概念:
1.Kafka是以集群的方式运行在一个或多个数据中心的服务器上的
2.Kafka引入了主题的概念,它是以主题来分类消息流的
3.每一条消息都有三部分组成,键,值,时间戳。
主题(Topic)
主题就是一个分类,或者说一个集合,用来将发布到kafka的消息进行归类。
通常来说,在Kafka中,一个主题通常有多个用户来订阅和生产消息。
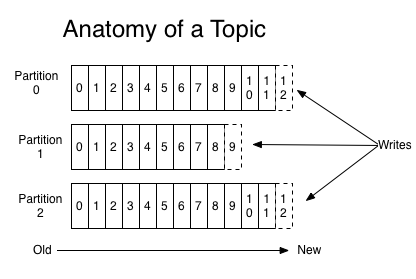
在实际生产中,在Kafka中都是有多个主题的,对于每个主题,都维护多个分区(partition)日志,如下图所示:

创建主题
创建主题使用kafka-topic.sh脚本,创建单分区单副本的topic test:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
查看主题:
bin/kafka-topics.sh --list --zookeeper localhost:2181
输出结果为:

分区(partition)
在主题中,每个分区都是一个有序的、不可变的记录序列,并不断地附加到一个结构化的提交日志中。
分区中的记录序列都被分配了一个偏移值,该偏移量惟一地标识分区中的每个记录。
这个偏移值可以是自增的,也可以是开发者自己指定。
在日志服务器中设置分区有以下几个好处:
首先,kafka集群允许日志消息扩展到适合的单个服务器的消息,每个分区都会有承载它大小的服务器,一个主题有多个分区,它可以处理任意数量的数据
其次,消息是并行的,可以同时处理.
分区的分布式
在kafka集群中,日志的分区是分布在每个主机上的,每个主机都共享数据和共同处理数据。
每个分区在集群中的服务器中进行复制,借此实现容错的功能。
与zookeeper类似,在集群中,总有一个主机扮演leader的角色,其他主机扮演follwers的角色。
当leader进行读和写操作时,follwers也将重复leader的操作,进行读和写。
遇到leader故障怎么办,那么其他follwers中的任意一台主机就会自动成为新的leader。
生产者(producers)
生产者,顾名思义,生产消息。生产者,选择kakfa中的某个主题某个分区进行推送消息。
为了负载均衡,也可以通过循环的方式来发送消息。
消费者(consumers)
消费者通常是以组的形式存在,消费者组订阅消息,并且分发给组中的每一个消费者实例。
消费者实例,可以分布在不同的进程中,也可是不同的机器中。
如果所有消费者都有相同的组,那么消息将会在消费者组中进行负载均衡分发。
如果所有消费者上都使用了不同的消费者,那么每个消息都将被广播到消费者实例。
如下图:

有两个kafka集群,这两个集群有四个分区,和两个消费者组。消费者组A有2个消费者实例,消费者组B有四个消费者实例。
通常来说,主题(topic)都会有少量的消费者组,主题中的一个逻辑(也可以说一个业务)对应着一个消费者组。
每个消费者组组都由许多消费者实例组成,从而保证可扩展性和容错性。
kafka只记录了所有分区的总数,并不单独记录每个主题中分区的总数。对于大多数应该程序来说,对分区的读写只需要根据分区的偏移值就能找到了。
保障
- 当消息发送到一个特定的主题分区中,消息的顺序按照其发送的顺序,比如先发送M1,后发送M2,那么M2就排在M1的后面。
- 当消费者订阅消息时,它获取消息的顺序是按照消息存储的顺序。
- 假设一个主题,他的容错因子是N(当它为leader时,有N个follwers),该集群最多能允许N-1个follwers 操作失败。
Kafka的优势
多个生产者
Kafka可无缝支持多个生产者,不管客户端使用单个主题还是多个主题。所以它适合从多个系统中收集数据,并以统一的格式对外提供数据。
多个消费者
Kafka支持多个消费者从一个单独的消息流上读取数据,而且消费者之间互不影响。这与其他队列系统不同,其他队列系统消息一旦被一个客户端读取,其他客户端就无法读取它。
除此之外,消费者可以组成一个群组,消费组可以共享消息流,并保证整个群组对每个给定的消息只处理一次。
消息持久化
消费者可以非实时的读取消息,这是因为kafka可以将消息存在磁盘中,根据设置的规则进行保存,而且每个主题可以设置单独的保留规则。
当消费者因为处理速度慢或者突然的流量暴增导致的无法及时的处理消息,那么就可以将消息进行持久化存储,并保证消息不会丢失。
消费者可以被关闭,但是消息被继续保留在Kafka中,消费者可以从上次中断的地方继续读取消息。
高性能与伸缩性
一个服务器可称为一个broker,开发时可以是一个,然后扩展成3个,小型集群,随着数据不断增长,可以扩展至上百个。
对于在线集群进行扩展,丝毫不影响系统的可用性。
在处理大数据时,Kafka能保证亚秒级别的消息延迟。
总结
kafka是高性能,吞吐量极高的消息中间件。学习kafka需要先去学习它其中的一些概念,只有理解了这些概念,
才能够在实际生产过程中更好的合理的使用kafka,本文是开篇,主要介绍了一些kafka的概念,下一篇主要内容是kafka的常用api。
kafka学习笔记——基本概念与安装的更多相关文章
- Kafka 学习笔记-基本概念
一.基本概念 Kafka是一个分布式的,可分区的,可复制的消息系统 Kafka以由一个或多个服务以集群的方式运行,服务叫broker producer,consuer通过kafka topic发布,预 ...
- Docker学习笔记一 概念、安装、镜像加速
本文地址:https://www.cnblogs.com/veinyin/p/10406378.html Docker 是一个容器,可以想象成一个轻便的虚拟机,但不虚拟硬件和操作系统. 优点:启动快 ...
- 大数据 -- kafka学习笔记:知识点整理(部分转载)
一 为什么需要消息系统 1.解耦 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险.许多 ...
- kafka学习笔记(一)消息队列和kafka入门
概述 学习和使用kafka不知不觉已经将近5年了,觉得应该总结整理一下之前的知识更好,所以决定写一系列kafka学习笔记,在总结的基础上希望自己的知识更上一层楼.写的不对的地方请大家不吝指正,感激万分 ...
- Oracle RAC学习笔记:基本概念及入门
Oracle RAC学习笔记:基本概念及入门 2010年04月19日 10:39 来源:书童的博客 作者:书童 编辑:晓熊 [技术开发 技术文章] oracle 10g real applica ...
- Java IO学习笔记:概念与原理
Java IO学习笔记:概念与原理 一.概念 Java中对文件的操作是以流的方式进行的.流是Java内存中的一组有序数据序列.Java将数据从源(文件.内存.键盘.网络)读入到内存 中,形成了 ...
- python3.4学习笔记(十八) pycharm 安装使用、注册码、显示行号和字体大小等常用设置
python3.4学习笔记(十八) pycharm 安装使用.注册码.显示行号和字体大小等常用设置Download JetBrains Python IDE :: PyCharmhttp://www. ...
- 学习笔记(1)centos7 下安装nginx
学习笔记(1)centos7 下安装nginx 这里我是通过来自nginx.org的nginx软件包进行安装的. 1.首先为centos设置添加nginx的yum存储库 1.通过vi命令创建一个rep ...
- jQuery学习笔记之概念(1)
jQuery学习笔记之概念(1) ----------------------学习目录-------------------- 1.概念 2.特点 3.选择器 4.DOM操作 5.事件 6.jQuer ...
随机推荐
- Java 数据类型与运算符
JAVA数据类型分基本(内置)数据类型和引用数据类型. 区别: 基本数据类型在被创建时,在栈上给其划分一块内存,将数值直接存储在栈上. 引用数据类型在被创建时,首先要在栈上给其引用(句柄)分配一块内存 ...
- 过滤器(Filter)与拦截器(Interceptor )区别
目录 过滤器(Filter) 拦截器(Interceptor) 拦截器(Interceptor)和过滤器(Filter)的区别 拦截器(Interceptor)和过滤器(Filter)的执行顺序 拦截 ...
- C# 使用运算符重载 简化结果判断
执行某个方法后, 一般都要对执行结果判断, 如果执行不成功, 还需要显示错误信息, 我先后使用了下面几种方式 /// <summary> /// 返回int类型结果, msg输出错误信息 ...
- github分支规范
转自:https://www.cnblogs.com/xuld 一.目的 我们制定分支规范,意在实现以下目标: 减少沟通成本:开发者可以很清晰地知道需要修改的代码位于哪个分支. 减少 bug 隐患:避 ...
- webpack 打包问题
Project is running at http://localhost:8080/webpack output is served from /dist/webpack: wait until ...
- 归并排序之python
想更好的了解归并排序, 需先了解, 将两个有序列表, 组成一个有序列表 有两个列表 l1 = [1, 3, 5, 7] l2 = [2, 4, 6] 需要将 l1 和 l2 组成一个 有序大列表 ...
- pclConfig.cmake or PCLConfig.cmake
Could not find a package configuration file provided by "pcl" (requested version 1.8) wit ...
- @无痕客 https://www.cnblogs.com/wuhenke/archive/2012/12/24/2830530.html 通篇引用
无痕客 https://www.cnblogs.com/wuhenke/archive/2012/12/24/2830530.html 关于Async与Await的FAQ 关于Async与Await的 ...
- NPOI颜色对照表
颜色对照表:颜色 测试 Class名称 short Test颜色 Black 8 Test颜色 Brown 60 Test颜色 Olive_Green 59 Test颜色 Dark_Gr ...
- java35
1.变量的访问:就近原则 2.this.name 本类的name 3.枚举:一个事物的固定状态 修饰符 enum 枚举名称{ } 4.枚举相当于一个特殊的类,默认继承了Enum 5.枚举不能直接创建对 ...