Spark源码剖析 - SparkContext的初始化(九)_启动测量系统MetricsSystem
9. 启动测量系统MetricsSystem
MetricsSystem使用codahale提供的第三方测量仓库Metrics。MetricsSystem中有三个概念:
- Instance:指定了谁在使用测量系统;
- Source:指定了从哪里收集测量数据;
- Sink:指定了从哪里输出测量数据;
Spark按照Instance的不同,区分为Master、Worker、Application、Driver和Executor。
Spark目前提供的Sink有ConsoleSink、CsvSink、JmxSink、MetricsServlet、GraphiteSink等。
Spark中使用MetricsServlet作为默认的Sink。
MetricsSystem在SparkEnv执行环境创建的过程中创建,代码如下:

MetricsSystem的启动代码如下:


MetricsSystem的启动过程包括以下步骤:
1) 注册Sources;
2) 注册Sinks;
3) 给Sinks增加Jetty的ServletContextHandler。
MetricsSystem启动完毕后,会遍历与Sinks有关的ServletContextHandler,并调用attachHandler将它们绑定到Spark UI上。代码如上图
9.1 注册Sources
registerSources方法用于注册Sources,告诉测量系统从哪里收集测量数据。注册Sources的过程分为以下步骤:
1) 从metricsConfig获取Driver的Properties,默认为创建MetricsSystem的过程中解析的{sink.servlet.class=org.apache.spark.metrics.sink.MetricsServlet,sink.servlet.path=/metrics/json}。
2) 用正则匹配Driver的Properties中以source.开头的属性。然后将属性中的Source发射得到的实例加入ArrayBuffer[Source]。
3) 将每个source的metricRegistry(也是MetricSet的子类型)注册到ConcurrentMap<String, Metric>metrics。

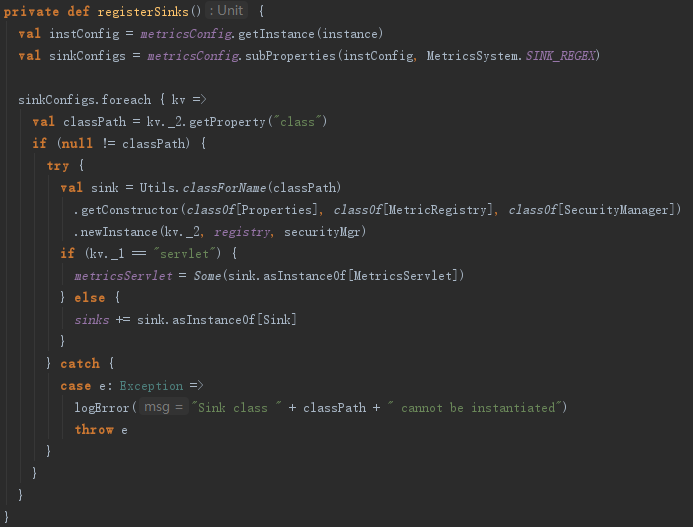
9.2 注册Sinks
registerSinks方法用于注册Sinks,即告诉测量系统MetricsSystem往哪里输出测量数据。注册Sinks的步骤如下:
1) 从Driver的Properties中用正则匹配以sink.开头的属性,如{sink.servlet.class=org.apache.spark.metrics.sink.MetricsServlet,sink.servlet.path=/metrics/json},将其转换为Map(servlet->{class=org.apache.spark.metrics.sink.MetricsServlet,path=/metrics/json})。
2) 将子属性class对应的类metricsServlet发射得到MetricsServlet实例。如果属性的key是serlvet,将其设置为metricsServlet;如果是Sink,则加入到ArrayBuffer[Sink]中。
9.3 给Sinks增加Jetty的ServletContextHandler
为了能够在SparkUI(网页)访问到测量数据,所以需要给Sinks增加Jetty的ServletContextHandler,这里主要用到MetricsSystem的getServletHandlers方法实现如下:

可以看到调用了metricsServlet的getHandlers,其实现如下:

最终生成处理/metrics/json请求的ServletContextHandler,而请求的真正处理由getMetricsSnapshot方法,利用fastjson解析。生成的ServletContextHandler通过SparkUI。最终我们可以使用以下这些地址来访问测量数据。
http://localhost:4040/metrics/applications/json
http://localhost:4040/metrics/json
http://localhost:4040/metrics/master/json
Spark源码剖析 - SparkContext的初始化(九)_启动测量系统MetricsSystem的更多相关文章
- Spark源码剖析 - SparkContext的初始化(二)_创建执行环境SparkEnv
2. 创建执行环境SparkEnv SparkEnv是Spark的执行环境对象,其中包括众多与Executor执行相关的对象.由于在local模式下Driver会创建Executor,local-cl ...
- Spark源码剖析 - SparkContext的初始化(三)_创建并初始化Spark UI
3. 创建并初始化Spark UI 任何系统都需要提供监控功能,用浏览器能访问具有样式及布局并提供丰富监控数据的页面无疑是一种简单.高效的方式.SparkUI就是这样的服务. 在大型分布式系统中,采用 ...
- Spark源码剖析 - SparkContext的初始化(五)_创建任务调度器TaskScheduler
5. 创建任务调度器TaskScheduler TaskScheduler也是SparkContext的重要组成部分,负责任务的提交,并且请求集群管理器对任务调度.TaskScheduler也可以看作 ...
- Spark源码剖析 - SparkContext的初始化(八)_初始化管理器BlockManager
8.初始化管理器BlockManager 无论是Spark的初始化阶段还是任务提交.执行阶段,始终离不开存储体系.Spark为了避免Hadoop读写磁盘的I/O操作成为性能瓶颈,优先将配置信息.计算结 ...
- Spark源码剖析 - SparkContext的初始化(六)_创建和启动DAGScheduler
6.创建和启动DAGScheduler DAGScheduler主要用于在任务正式交给TaskSchedulerImpl提交之前做一些准备工作,包括:创建Job,将DAG中的RDD划分到不同的Stag ...
- Spark源码剖析 - SparkContext的初始化(一)
1. SparkContext概述 注意:SparkContext的初始化剖析是基于Spark2.1.0版本的 Spark Driver用于提交用户应用程序,实际可以看作Spark的客户端.了解Spa ...
- Spark源码剖析 - SparkContext的初始化(十)_Spark环境更新
12. Spark环境更新 在SparkContext的初始化过程中,可能对其环境造成影响,所以需要更新环境,代码如下: SparkContext初始化过程中,如果设置了spark.jars属性,sp ...
- Spark源码剖析 - SparkContext的初始化(七)_TaskScheduler的启动
7. TaskScheduler的启动 第五节介绍了TaskScheduler的创建,要想TaskScheduler发挥作用,必须要启动它,代码: TaskScheduler在启动的时候,实际调用了b ...
- Spark源码剖析 - SparkContext的初始化(四)_Hadoop相关配置及Executor环境变量
4. Hadoop相关配置及Executor环境变量的设置 4.1 Hadoop相关配置信息 默认情况下,Spark使用HDFS作为分布式文件系统,所以需要获取Hadoop相关配置信息的代码如下: 获 ...
随机推荐
- day5 笔记
笔记 字符格式化输出: 占位符%s s=string 字符型%d d=dight 整数型%f f=float 浮点数 约等于小数 通过格式:%(str1,str2,str3)一一对应 数据运算 数据类 ...
- day2 网络基础
网路基础 网络OSI模型七层: 物理层: 定义特性:机械,电器,功能,过程: 定义接口标准:双绞线,光纤,同轴电缆: 相关协议:无: 数据链路层: 定义帧的开始结束,封装成帧,差错校验,透明传输(防止 ...
- centos7安装mha4mysql
mysql搭建mha需要用的两个rpm包.(manager包和node包) 下载地址:https://download.csdn.net/download/dajdajdajdaj/10603389 ...
- codeforces #541 F Asya And Kittens(并查集+输出路径)
F. Asya And Kittens Asya loves animals very much. Recently, she purchased nn kittens, enumerated the ...
- Python3 与 C# 扩展之~模块专栏
代码裤子:https://github.com/lotapp/BaseCode/tree/maste 在线编程:https://mybinder.org/v2/gh/lotapp/BaseCode ...
- 洛谷P1477 假面舞会
坑死了...... 题意:给你个有向图,你需要把点分成k种,满足每条边都是分层的(从i种点连向i + 1种点,从k连向1). 要确保每种点至少有一个. 求k的最大值,最小值. n <= 1e5, ...
- luogu4211 LCA
题目链接 思路 我们换一种求\(dep[lca(i,j)]\)的方法. 将从根到\(i\)的路径上所有点的权值加\(1\),然后求从根节点到j路径上点的权值和.就是\(i\)和\(j\)的\(lca\ ...
- Python线程状态和全局解释器锁
在刚接触Python的时候时常听到GIL这个词,并且发现这个词经常和Python无法高效的实现多线程划上等号.本着不光要知其然,还要知其所以然的研究态度,博主搜集了各方面的资料,花了一周内几个小时的闲 ...
- Ubuntu下安装Goldendict(翻译软件)
Ubuntu直接安装 sudo apt-get install goldendict 通过源码安装 失败 下载词典 http://blog.sina.com.cn/s/blog_c58823b3010 ...
- 论文总结(Frequent Itemsets Mining With Differential Privacy Over Large-Scale Data)
一.论文目标:将差分隐私和频繁项集挖掘结合,主要针对大规模数据. 二.论文的整体思路: 1)预处理阶段: 对于大的数据集,进行采样得到采样数据集并计算频繁项集,估计样本数据集最大长度限制,然后再缩小源 ...