实战Google深度学习框架-C5-MNIST数字识别问题
5.1 MNIST数据处理
MNIST是NIST数据集的一个子集,包含60000张图片作为训练数据,10000张作为测试数据,其中每张图片代表0~9中的一个数字,图片大小为28*28(可以用一个28*28矩阵表示)
为了清楚表示,用下图14*14矩阵表示了,其实应该是28*28矩阵
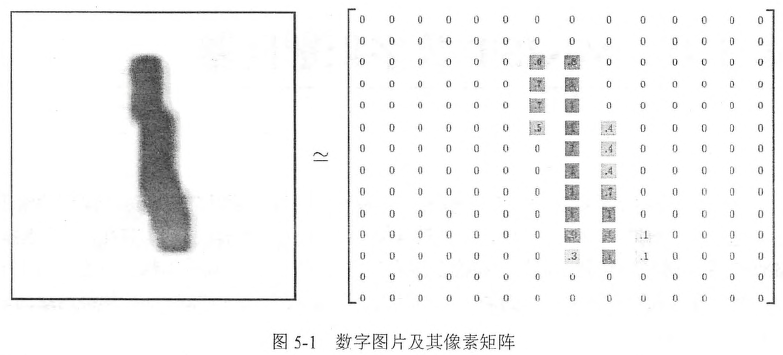
TF提供了一个类来处理MNIST数据:
准备工作:桌面新建MNIST数字识别->cd MNIST数字识别->shift + 右键->在此处新建命令窗口->jupyter notebook->新建get_mnist_data脚本:
- import warnings
- warnings.filterwarnings('ignore')
- from tensorflow.examples.tutorials.mnist import input_data
- #如果某路径如当前路径下没有mnist数据,则自动进行下载
- #如果存在mnist数据,则进行提取,并且input_data.read_data_sets函数会自动进行数据拆分
- #拆分为train,validation,test data
- mnist = input_data.read_data_sets('./', one_hot=True)
- #Training data size:55000
- print('Training data size:', mnist.train.num_examples)
- #Validating data size:5000
- print('Validating data size:', mnist.validation.num_examples)
- #Test data size:10000
- print('Testing data size:', mnist.test.num_examples)
- #(784,)的向量
- print('Example training data:\n', mnist.train.images[0])
- #one_hot形式的标签:[0. 0. 0. 0. 0. 0. 0. 1. 0. 0.]
- print('Example training data label:\n', mnist.train.labels[0])
- #为了方便使用随机梯度下降,input_data.read_data_sets函数生成的类还提供了
- #mnist.train.next_batch函数,可以从所有train_data中读取一小部分作为一个训练batch
- batch_size = 100
- xs, ys = mnist.train.next_batch(batch_size)
- #从train中选取batch_size个训练数据
- print ('X shape', xs.shape)#(100, 784)
- print('Y shape', ys.shape)#(100, 10)
- #X shape (100, 784)
- #Y shape (100, 10)
5.2 神经网络模型训练及不同模型结果对比
5.2.1 TF训练神经网络
在上面提到的路径(MNIST数字识别)下新建mnist_train_NN脚本:
- import tensorflow as tf
- from tensorflow.examples.tutorials.mnist import input_data
- import matplotlib.pyplot as plt
- import matplotlib as mpl
- mpl.rcParams['font.sans-serif']=['SimHei']#解决中文乱码的问题
- mpl.rcParams['axes.unicode_minus']=False #该行会影响坐标轴正负号
- import numpy as np
- import warnings
- warnings.filterwarnings('ignore')
- INPUT_NODE = 784 #输入层节点数:其实就是特征数目
- OUTPUT_NODE = 10 #输出层节点数:10分类问题,多少种分类,就设置为多少
- LAYER1_NODE = 500 #隐藏层节点数,这里使用只有一个隐藏层的网络结构为例,该隐藏层有500个节点
- BATCH_SIZE = 100 #一个训练batch中训练数据个数,数字越大,越接近梯度下降,数字越小,越接近随机梯度下降
- LEARNING_RATE_BASE = 0.8 #最初的学习率
- LEARNING_RATE_DECAY = 0.99 #学习率衰减系数
- REGULARIZATION_RATE = 0.0001 #描述模型复杂度的正则化项在损失函数中的系数
- TRAINING_STEPS = 30000 #训练轮数
- MOVING_AVERAGE_DECAY = 0.99 #滑动平均衰减率
- def inference(input_tensor, avg_class, weights1, biases1, weights2, biases2):
- if avg_class == None:
- #计算隐藏层的前向传播结果,使用ReLU激活函数
- layer1 = tf.nn.relu( tf.matmul(input_tensor, weights1) + biases1 )
- #计算输出层的前向传播结果,因为在计算损失函数时会一并计算softmax函数
- #所以这里不用激活函数,而且不加入softmax不会影响结果
- #因为预测时使用的是不同类别对应节点输出值的相对大小,有没有softmax层对最后分类结果的计算
- #没有影响,于是在计算整个神经网络的前向传播时可以不用加入最后的softmax层
- return tf.matmul(layer1, weights2) + biases2
- else:
- #首先使用avg_class.average函数来计算得出变量的滑动平均值
- #然后再计算相应的神经网络前向传播结果
- layer1 = tf.nn.relu( tf.matmul( input_tensor, avg_class.average(weights1) ) + avg_class.average(biases1) )
- return tf.matmul( layer1, avg_class.average(weights2) ) + avg_class.average(biases2)
- #训练过程
- def train(mnist):
- global my_validate_acc, my_test_acc, my_estimators
- my_validate_acc = []
- my_test_acc = []
- my_estimators = []
- x = tf.placeholder(tf.float32, shape=([None, INPUT_NODE]), name='x-input' )
- y_ = tf.placeholder(tf.float32, shape=([None, OUTPUT_NODE]), name='y-output' )
- #生成隐藏层的参数
- weights1 = tf.Variable( tf.truncated_normal( [INPUT_NODE, LAYER1_NODE], stddev=0.1 ))
- biases1 = tf.Variable( tf.constant(0.1, shape=[LAYER1_NODE]) )
- #生成输出层参数
- weights2 = tf.Variable( tf.truncated_normal( [LAYER1_NODE, OUTPUT_NODE], stddev=0.1 ) )
- biases2 = tf.Variable( tf.constant(0.1, shape=[OUTPUT_NODE]) )
- #计算在当前参数下的神经网络前向传播结果,这里给出的用于滑动平均的类为None
- y = inference(x, None, weights1, biases1, weights2, biases2)
- #定义存储训练轮数的变量,这个变量不需要计算滑动平均值,所以这里指定这个变量为不可训练的变量(trainable=False)
- #在使用TF训练神经网络时,一般会将代表训练轮数的变量指定为不可训练的参数
- global_step = tf.Variable(0, trainable=False)
- #给定滑动平均衰减率和训练轮数的变量,初始化滑动平均类
- #给定训练轮数的变量可以加快训练早期变量的更新速度
- variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
- #在所有代表神经网络参数的变量上使用滑动平均,其他辅助变量(如global_step)就不需要了
- #tf.trainable_variables返回的就是图上集合GraphKeys.TRAINABLE_VARIABLES中的元素
- #这个集合的元素就是没有指定trainable=False的参数
- variable_averages_op = variable_averages.apply( tf.trainable_variables() )
- #计算使用了滑动平均之后的前向传播结果
- #滑动平均不会改变变量本身的取值,而是会维护一个影子变量来记录其滑动平均值
- #所以当需要使用这个滑动平均值时,需要明确调用average函数
- average_y = inference(x, variable_averages, weights1, biases1, weights2, biases2)
- #计算交叉熵来刻画预测值与真实值之间差距的损失函数,这里使用tf.nn.sparse_softma_cross_entropy_with_logits
- #当问题只有一个正确答案时,可以使用这个函数来加速交叉熵的计算
- #MNIST问题的图片中只包含了0-9中的一个数字,所以可以使用这个函数来计算交叉熵损失
- #这个函数的第一个参数是神经网络不包含softmax层的前向传播结果,第二个是训练数据的正确答案
- #因为标准答案是个长度为10的一维数组,而该函数需要提供的是一个正确答案的数字,所以需要tf.argmax函数来得到
- #正确答案对应的类别编号
- cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits( logits=y,labels=tf.argmax(y_, 1) )
- #计算当前batch中所有样例的交叉熵平均值
- cross_entropy_mean = tf.reduce_mean( cross_entropy )
- #计算L2正则化损失函数
- regularizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
- #计算模型的正则化损失,一般只计算神经网络边上权重的正则化损失,而不使用偏置项
- regularization = regularizer(weights1) + regularizer(weights2)
- #总损失等于交叉熵损失和正则化损失的和
- loss = cross_entropy_mean + regularization
- #设置指数衰减的学习率
- learning_rate = tf.train.exponential_decay( LEARNING_RATE_BASE, #基础学习率,随着训练进行,在此基础上递减
- global_step, #当前迭代次数
- mnist.train.num_examples / BATCH_SIZE, #过完所有训练数据需要的迭代次数
- LEARNING_RATE_DECAY ) #学习率衰减速度
- #使用tf.train.GradientDescentOptimizer优化算法来优化损失函数
- #注意这里的损失函数包含了交叉熵损失和L2正则化损失
- train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
- #在训练神经网络模型时,每过一遍数据既需要通过反向传播来更新神经网络中的参数
- #又需要更新每个参数的滑动平均值。为了一次完成多个操作,下面两行程序和
- #train_op = tf.group(train_step, variables_averages_op)是等价的
- with tf.control_dependencies( [train_step, variable_averages_op] ):
- train_op = tf.no_op( name='train' )
- correct_prediction = tf.equal( tf.argmax(average_y, 1), tf.argmax(y_, 1) )
- #这个运算首先将一个布尔型的数值转换为实数型,然后计算平均值,这个平均值就是模型在这一组数据上的正确率
- accuracy = tf.reduce_mean( tf.cast(correct_prediction, tf.float32) )
- #初始化会话并开始训练过程
- with tf.Session() as sess:
- sess.run( tf.global_variables_initializer() )
- #准备验证数据,一般在神经网络的训练过程中会通过验证数据来大致判断停止条件和评判训练的效果
- validate_feed = { x: mnist.validation.images,
- y_: mnist.validation.labels }
- #准备测试数据,在真实运用中,这部分数据在训练时是不可见的,这个数据只是作为模型优劣的最后评价标准
- test_feed = { x: mnist.test.images,
- y_: mnist.test.labels }
- #迭代训练神经网络
- for i in range(TRAINING_STEPS):
- #每1000轮上输出一次在验证数据集上的测试效果
- if i % 1000 == 0:
- #计算滑动平均模型在验证数据上的结果,因为MNIST数据集比较小,所以一次可以
- #处理所有的验证数据,为了计算方便,本例程序没有将验证数据划分为更
- #小的batch,当神经网络模型比较复杂或者验证数据比较大时,太大的batch
- #会导致计算时间过长甚至内存溢出的错误
- validate_acc = sess.run( accuracy, feed_dict=validate_feed )
- #每1000轮再来看看在测试数据上的正确率
- test_acc = sess.run( accuracy, feed_dict=test_feed)
- print( 'After %d training step(s), validation accuracy using average model is %g,test accuracy using average model is %g' % (i, validate_acc, test_acc) )
- my_validate_acc.append( validate_acc )
- my_test_acc.append( test_acc )
- my_estimators.append(i)
- #产生这一轮使用的一个batch的训练数据并运行训练过程
- xs, ys = mnist.train.next_batch(BATCH_SIZE)
- sess.run( train_op, feed_dict={x:xs, y_:ys} )
- #训练结束之后,在测试数据上检测神经网络模型的最终正确率
- test_acc = sess.run( accuracy, feed_dict=test_feed )
- print('After %d training step(s), test accuracy using average model is %g' % (TRAINING_STEPS, test_acc) )
- plt.figure(figsize=(14,5))
- plt.plot( my_estimators[1:], my_validate_acc[1:] )
- plt.plot( my_estimators[1:], my_test_acc[1:] )
- plt.grid()
- plt.xlabel('迭代次数')
- plt.ylabel('正确率')
- plt.xticks(np.arange(my_estimators[0], my_estimators[-1]+999, 1000), rotation=30)
- plt.legend(['验证数据集上正确率','测试数据集上正确率'], loc='lower right')
- plt.show()
- #主程序入口
- def main(argv=None):
- #声明处理MNIST数据集的类,这个类在初始化时会自动下载数据
- mnist = input_data.read_data_sets('./', one_hot=True)
- train(mnist)
- #TF提供的一个主程序入口,tf.app.run()会调用上面定义的main函数
- if __name__ == '__main__':
- tf.app.run()
运行结果如下:

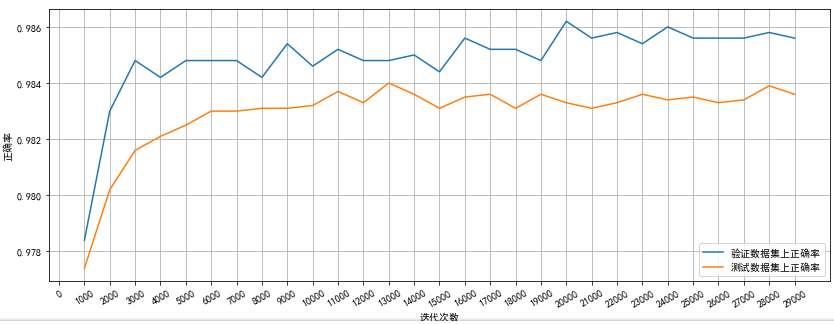
从上面的结果看(由于随机因素,读者可能不会得到相同的结果):4000轮开始,模型在验证数据上的表现开始波动,这说明模型已经接近极小值,迭代也就可以结束了
而且从图上看出我们的模型在验证数据集和测试数据集上的表现很一致,说明我们的验证数据集能很好的代表测试数据分布:
一般来说,选取的验证数据分布越接近测试数据分布,模型在验证数据上的表现越可以提现模型在测试数据上的表现
实战Google深度学习框架-C5-MNIST数字识别问题的更多相关文章
- 吴裕雄--天生自然python Google深度学习框架:MNIST数字识别问题
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data INPUT_NODE = 784 ...
- [Tensorflow实战Google深度学习框架]笔记4
本系列为Tensorflow实战Google深度学习框架知识笔记,仅为博主看书过程中觉得较为重要的知识点,简单摘要下来,内容较为零散,请见谅. 2017-11-06 [第五章] MNIST数字识别问题 ...
- Reading | 《TensorFlow:实战Google深度学习框架》
目录 三.TensorFlow入门 1. TensorFlow计算模型--计算图 I. 计算图的概念 II. 计算图的使用 2.TensorFlow数据类型--张量 I. 张量的概念 II. 张量的使 ...
- 1 如何使用pb文件保存和恢复模型进行迁移学习(学习Tensorflow 实战google深度学习框架)
学习过程是Tensorflow 实战google深度学习框架一书的第六章的迁移学习环节. 具体见我提出的问题:https://www.tensorflowers.cn/t/5314 参考https:/ ...
- 【书评】【不推荐】《TensorFlow:实战Google深度学习框架》(第2版)
参考书 <TensorFlow:实战Google深度学习框架>(第2版) 这本书我老老实实从头到尾看了一遍(实际上是看到第9章,刚看完,后面的实在看不下去了,但还是会坚持看的),所有的代码 ...
- TensorFlow+实战Google深度学习框架学习笔记(5)----神经网络训练步骤
一.TensorFlow实战Google深度学习框架学习 1.步骤: 1.定义神经网络的结构和前向传播的输出结果. 2.定义损失函数以及选择反向传播优化的算法. 3.生成会话(session)并且在训 ...
- 学习《TensorFlow实战Google深度学习框架 (第2版) 》中文PDF和代码
TensorFlow是谷歌2015年开源的主流深度学习框架,目前已得到广泛应用.<TensorFlow:实战Google深度学习框架(第2版)>为TensorFlow入门参考书,帮助快速. ...
- TensorFlow实战Google深度学习框架5-7章学习笔记
目录 第5章 MNIST数字识别问题 第6章 图像识别与卷积神经网络 第7章 图像数据处理 第5章 MNIST数字识别问题 MNIST是一个非常有名的手写体数字识别数据集,在很多资料中,这个数据集都会 ...
- TensorFlow实战Google深度学习框架-人工智能教程-自学人工智能的第二天-深度学习
自学人工智能的第一天 "TensorFlow 是谷歌 2015 年开源的主流深度学习框架,目前已得到广泛应用.本书为 TensorFlow 入门参考书,旨在帮助读者以快速.有效的方式上手 T ...
随机推荐
- AIM Tech Round 4 Div. 1
A:显然最优方案是对所形成的置换的每个循环排个序. #include<iostream> #include<cstdio> #include<cmath> #inc ...
- Android大学课件SQLite3 数据库操作
一.数据库介绍 SQLite3:当有大量相似结构的数据需要存储的时候 . 其实SQLite3 就是一个文件,类似之前学过的MySQL SqlServer等. 二.SQLiteOpenHelper 是一 ...
- pip详解
pip是一个安装和管理 Python 包的工具.python安装包的工具有easy_install, setuptools, pip,distribute等,pip是Python官方推荐的包管理工具 ...
- (转)最短路径算法-Dijkstra算法分析及实践
原地址:http://www.wutianqi.com/?p=1890 这篇博客写的非常简洁易懂,其中各个函数的定义也很清晰,配合图表很容易理解这里只选取了 其中一部分(插不来图片). Dijkstr ...
- 让Mac 可以使用mysql -u用户直接连接数据库
在执行完安装版本的mysql数据库后,会发现执行mysql还是会出现 command not found的错误:解决方案 方案1.设置软连接到/usr/local/bin下在命令行下输入如下 ln - ...
- Python中字符串、列表、元组、字典、集合常用方法总结
- Java 验证代理ip
原文地址:http://www.cnblogs.com/junrong624/p/5416503.html 1 import java.io.IOException; import java.io.I ...
- ELK日志系统安装、配置
1.关闭SELINUX: [root@ELK /]# vim /etc/selinux/config 将SELINUX=enforcing修改为SELINUX=disabled 2.关闭防火墙: [r ...
- 第一次有人把5G讲的这么简单明了
第一次有人把5G讲的这么简单明了 鲜枣课堂 纯洁的微笑 今天 关于5G通信,常见的文章都讲的晦涩难懂,不忍往下看,特转载一篇,用大白话实现5G入门. 简单说,5G就是第五代通信技术,主要特点是波长为毫 ...
- Ubuntu 16.04交换Ctrl和Caps
将Caps这个鸡肋的键位换成Ctrl的人不在少数,Ubuntu 12.04 中可以通过设置-键盘更改,新版去掉了这个功能,可以通过修改系统文件实现 方法1 在~/.xinputrc中加入:setxkb ...