库的操作&表的操作
一 库的操作
掌握库的增删改查
一、系统数据库
执行如下命令,查看系统库
show databases;
information_schema: 虚拟库,不占用磁盘空间,存储的是数据库启动后的一些参数,如用户表信息、列信息、权限信息、字符信息等
performance_schema: MySQL 5.5开始新增一个数据库:主要用于收集数据库服务器性能参数,记录处理查询请求时发生的各种事件、锁等现象
mysql: 授权库,主要存储系统用户的权限信息
test: MySQL数据库系统自动创建的测试数据库
二、创建数据库
1、求救语法:
help create database;
2、创建数据库语法
CREATE DATABASE 数据库名 charset utf8;
3、数据库命名规则:

可以由字母、数字、下划线、@、#、$
区分大小写
唯一性
不能使用关键字如 create select
不能单独使用数字
最长128位
# 基本上跟python或者js的命名规则一样
三、数据库相关操作
#查看数据库
show databases;
#查看当前库
show create database db1;
#查看所在的库
select database(); #选择数据库
use 数据库名 #删除数据库
DROP DATABASE 数据库名;
# 修改数据库
alter database db1 charset utf8;
四、了解内容
SQL语言主要用于存取数据、查询数据、更新数据和管理关系数据库系统,SQL语言由IBM开发。SQL语言分为3种类型:
、DDL语句 数据库定义语言: 数据库、表、视图、索引、存储过程,例如CREATE DROP ALTER 、DML语句 数据库操纵语言: 插入数据INSERT、删除数据DELETE、更新数据UPDATE、查询数据SELECT 、DCL语句 数据库控制语言: 例如控制用户的访问权限GRANT、REVOKE
二 表的操作
- 表的增删改查(重要)
一、存储引擎(了解)
前几节我们知道mysql中建立的库===》文件夹,库中的表====》文件
现实生活中我们用来存储数据的文件有不同的类型,每种文件类型对应各自不同的处理机制:比如处理文本用txt类型,处理表格用excel,处理图片用png等
数据库中的表也应该有不同的类型,表的类型不同,会对应mysql不同的存取机制,表类型又称为存储引擎。
ps: 存储引擎说白了就是如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术的实现方法。因为在关系数据库中数据的存储是以表的形式存储的,所以存储引擎也可以称为表类型(即存储和操作此表的类型)
在Oracle 和SQL Server等数据库中只有一种存储引擎,所有数据存储管理机制都是一样的。而MySql
数据库提供了多种存储引擎。用户可以根据不同的需求为数据表选择不同的存储引擎,用户也可以根据
自己的需要编写自己的存储引擎
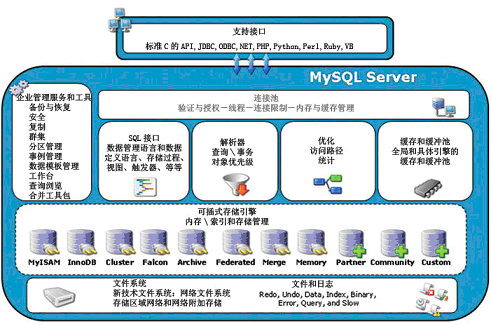
SQL 解析器、SQL 优化器、缓冲池、存储引擎等组件在每个数据库中都存在,但不是每 个数据库都有这么多存储引擎。MySQL 的插件式存储引擎可以让存储引擎层的开发人员设 计他们希望的存储层,例如,有的应用需要满足事务的要求,有的应用则不需要对事务有这 么强的要求 ;有的希望数据能持久存储,有的只希望放在内存中,临时并快速地提供对数据 的查询。
二、mysql支持的存储引擎
mysql> show engines\G;# 查看所有支持的引擎
mysql> show variables like 'storage_engine%'; # 查看正在使用的存储引擎
1、InnoDB 存储引擎
支持事务,其设计目标主要面向联机事务处理(OLTP)的应用。其
特点是行锁设计、支持外键,并支持类似 Oracle 的非锁定读,即默认读取操作不会产生锁。 从 MySQL 5.5.8 版本开始是默认的存储引擎。
InnoDB 存储引擎将数据放在一个逻辑的表空间中,这个表空间就像黑盒一样由 InnoDB 存储引擎自身来管理。从 MySQL 4.1(包括 4.1)版本开始,可以将每个 InnoDB 存储引擎的 表单独存放到一个独立的 ibd 文件中。此外,InnoDB 存储引擎支持将裸设备(row disk)用 于建立其表空间。
InnoDB 通过使用多版本并发控制(MVCC)来获得高并发性,并且实现了 SQL 标准 的 4 种隔离级别,默认为 REPEATABLE 级别,同时使用一种称为 netx-key locking 的策略来 避免幻读(phantom)现象的产生。除此之外,InnoDB 存储引擎还提供了插入缓冲(insert buffer)、二次写(double write)、自适应哈希索引(adaptive hash index)、预读(read ahead) 等高性能和高可用的功能。
对于表中数据的存储,InnoDB 存储引擎采用了聚集(clustered)的方式,每张表都是按 主键的顺序进行存储的,如果没有显式地在表定义时指定主键,InnoDB 存储引擎会为每一 行生成一个 6 字节的 ROWID,并以此作为主键。
InnoDB 存储引擎是 MySQL 数据库最为常用的一种引擎,Facebook、Google、Yahoo 等 公司的成功应用已经证明了 InnoDB 存储引擎具备高可用性、高性能以及高可扩展性。对其 底层实现的掌握和理解也需要时间和技术的积累。如果想深入了解 InnoDB 存储引擎的工作 原理、实现和应用,可以参考《MySQL 技术内幕:InnoDB 存储引擎》一书。
2、MyISAM 存储引擎
不支持事务、表锁设计、支持全文索引,主要面向一些 OLAP 数 据库应用,在 MySQL 5.5.8 版本之前是默认的存储引擎(除 Windows 版本外)。数据库系统 与文件系统一个很大的不同在于对事务的支持,MyISAM 存储引擎是不支持事务的。究其根 本,这也并不难理解。用户在所有的应用中是否都需要事务呢?在数据仓库中,如果没有 ETL 这些操作,只是简单地通过报表查询还需要事务的支持吗?此外,MyISAM 存储引擎的 另一个与众不同的地方是,它的缓冲池只缓存(cache)索引文件,而不缓存数据文件,这与 大多数的数据库都不相同。
3、NDB 存储引擎
年,MySQL AB 公司从 Sony Ericsson 公司收购了 NDB 存储引擎。 NDB 存储引擎是一个集群存储引擎,类似于 Oracle 的 RAC 集群,不过与 Oracle RAC 的 share everything 结构不同的是,其结构是 share nothing 的集群架构,因此能提供更高级别的 高可用性。NDB 存储引擎的特点是数据全部放在内存中(从 5.1 版本开始,可以将非索引数 据放在磁盘上),因此主键查找(primary key lookups)的速度极快,并且能够在线添加 NDB 数据存储节点(data node)以便线性地提高数据库性能。由此可见,NDB 存储引擎是高可用、 高性能、高可扩展性的数据库集群系统,其面向的也是 OLTP 的数据库应用类型。
4、Memory 存储引擎
正如其名,Memory 存储引擎中的数据都存放在内存中,数据库重 启或发生崩溃,表中的数据都将消失。它非常适合于存储 OLTP 数据库应用中临时数据的临时表,也可以作为 OLAP 数据库应用中数据仓库的维度表。Memory 存储引擎默认使用哈希 索引,而不是通常熟悉的 B+ 树索引。
5、Infobright 存储引擎
第三方的存储引擎。其特点是存储是按照列而非行的,因此非常 适合 OLAP 的数据库应用。其官方网站是 http://www.infobright.org/,上面有不少成功的数据 仓库案例可供分析。
6、NTSE 存储引擎
网易公司开发的面向其内部使用的存储引擎。目前的版本不支持事务, 但提供压缩、行级缓存等特性,不久的将来会实现面向内存的事务支持。
7、BLACKHOLE
黑洞存储引擎,可以应用于主备复制中的分发主库。
MySQL 数据库还有很多其他存储引擎,上述只是列举了最为常用的一些引擎。如果 你喜欢,完全可以编写专属于自己的引擎,这就是开源赋予我们的能力,也是开源的魅 力所在。
指定表类型/存储引擎
create table t1(id int)engine=innodb;# 默认不写就是innodb
小练习:
创建四张表,分别使用innodb,myisam,memory,blackhole存储引擎,进行插入数据测试
create table t1(id int)engine=innodb;
create table t2(id int)engine=myisam;
create table t3(id int)engine=memory;
create table t4(id int)engine=blackhole;
查看data文件下db1数据库中的文件:
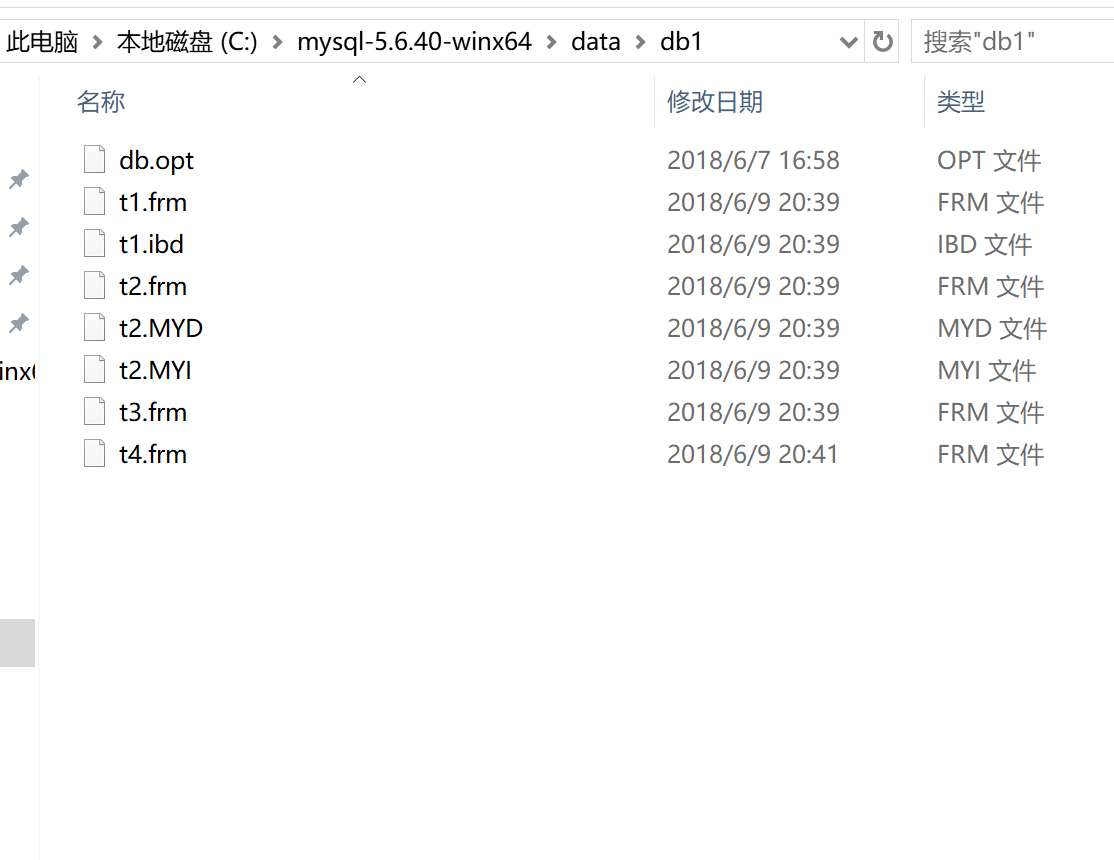
#.frm是存储数据表的框架结构 # .ibd是mysql数据文件 #.MYD是MyISAM表的数据文件的扩展名 #.MYI是MyISAM表的索引的扩展名 #发现后两种存储引擎只有表结构,无数据 #memory,在重启mysql或者重启机器后,表内数据清空
#blackhole,往表内插入任何数据,都相当于丢入黑洞,表内永远不存记录
三、表介绍
表相当于文件,表中的一条记录就相当于文件的一行内容,不同的是,表中的一条记录有对应的标题,称为表的字段

id,name,sex,age,birth称为字段,其余的,一行内容称为一条记录
四、创建表
语法:
create table 表名(
字段名1 类型[(宽度) 约束条件],
字段名2 类型[(宽度) 约束条件],
字段名3 类型[(宽度) 约束条件]
); #注意:
1. 在同一张表中,字段名是不能相同
2. 宽度和约束条件可选
3. 字段名和类型是必须的
1.创建数据库
create database db2 charset utf8;
2.使用数据库
use db2;
3.创建a1表
create table a1(
id int,
name varchar(50),
age int(3)
);
4.插入表的记录
insert into a1 values
(1,'mjj',18),
(2,'wusir',28);
ps:以;作为mysql的结束语
5.查询表的数据和结构
(1)查询a1表中的存储数据
mysql> select * from a1;
+------+-------+------+
| id | name | age |
+------+-------+------+
| 1 | mjj | 18 |
| 2 | wusir | 28 |
+------+-------+------+
2 rows in set (0.02 sec)
mysql>
(2)查看a1表的结构
mysql> desc a1;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(50) | YES | | NULL | |
| age | int(3) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
3 rows in set (0.16 sec)
(3)查看表的详细结构
mysql> show create table a1\G;
*************************** 1. row ***************************
Table: a1
Create Table: CREATE TABLE `a1` (
`id` int(11) DEFAULT NULL,
`name` varchar(50) DEFAULT NULL,
`age` int(3) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
6.复制表
(1)新创建一个数据库db3
mysql> create database db3 charset utf8;
Query OK, 1 row affected (0.00 sec)
(2)使用db3
mysql> use db3;
Database changed
#这是上个创建的db2数据库中的a1表
mysql> select * from db2.a1;
+------+-------+------+
| id | name | age |
+------+-------+------+
| 1 | mjj | 18 |
| 2 | wusir | 28 |
+------+-------+------+
(3)复制db2.a1的表结构和记录
# 这就是复制表的操作(既复制了表结构,又复制了记录)
mysql> create table b1 select * from db2.a1;
Query OK, 2 rows affected (0.03 sec)
(4)查看db3.b1中的数据和表结构
#再去查看db3文件夹下的b1表发现 跟db2文件下的a1表数据一样
mysql> select * from db3.b1;
+------+-------+------+
| id | name | age |
+------+-------+------+
| 1 | mjj | 18 |
| 2 | wusir | 28 |
+------+-------+------+
2 rows in set (0.00 sec)
ps1:如果只要表结构,不要记录
#在db2数据库下新创建一个b2表,给一个where条件,条件要求不成立,条件为false,只拷贝表结构
mysql> create table b2 select * from db2.a1 where 1>5;
Query OK, 0 rows affected (0.05 sec)
Records: 0 Duplicates: 0 Warnings: 0
查看表结构:
# 查看表结构
mysql> desc b2;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(50) | YES | | NULL | |
| age | int(3) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
3 rows in set (0.02 sec) #查看表结构中的数据,发现是空数据
mysql> select * from b2;
Empty set (0.00 sec)
ps2:还有一种做法,使用like(只拷贝表结构,不拷贝记录)
mysql> create table b3 like db2.a1;
Query OK, 0 rows affected (0.01 sec) mysql> desc b3;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(50) | YES | | NULL | |
| age | int(3) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
3 rows in set (0.02 sec) mysql> select * from db3.b3;
Empty set (0.00 sec)
7.删除表:
drop table 表名;
库的操作&表的操作的更多相关文章
- python -使用Requests库完成Post表单操作
""" 使用Requests库完成Post表单操作 """ #_*_codingn:utf8 _*_ import requests fro ...
- python 全栈开发,Day61(库的操作,表的操作,数据类型,数据类型(2),完整性约束)
昨日内容回顾 一.回顾 定义:mysql就是一个基于socket编写的C / S架构的软件 包含: ---服务端软件 - socket服务端 - 本地文件操作 - 解析指令(mysql语句) ---客 ...
- mysql更新(三)语句 库的操作 表的操作
04-初始mysql语句 本节课先对mysql的基本语法初体验. 操作文件夹(库) 增 create database db1 charset utf8; 查 # 查看当前创建的数据库 show ...
- Mysql --库和表的操作
库的增删改查 系统数据库 创建数据库 数据库的相关操作 表的操作 存储引擎介绍(有点多 很啰唆) 表的介绍 表的操作 一.系统数据库 查看系统库: show databases; nformation ...
- SQL server学习(二)表结构操作、SQL函数、高级查询
数据库查询的基本格式为: select ----输出(显示)你要查询出来的值 from -----查询的依据 where -----筛选条件(对依据(数据库中存在的表)) group by ----- ...
- MySQL使用笔记(三)表的操作
By francis_hao Dec 11,2016 表的操作 表的操作有创建表.查看表.删除表和修改表 创建表 创建表之前要在某个数据库中. mysql> create table ta ...
- MySQL(一) -- MySQL学习路线、数据库的基础、关系型数据库、关键字说明、SQL、MySQL数据库、MySQL服务器对象、SQL的基本操作、库操作、表操作、数据操作、中文数据问题、 校对集问题、web乱码问题
1 MySQL学习路线 基础阶段:MySQL数据库的基本操作(增删改查),以及一些高级操作(视图.触发器.函数.存储过程等). 优化阶段:如何提高数据库的效率,如索引,分表等. 部署阶段:如何搭建真实 ...
- 第八章| 1. MySQL数据库|库操作|表操作
1.初识数据库 我们在编写任何程序之前,都需要事先写好基于网络操作一台主机上文件的程序(socket服务端与客户端程序),于是有人将此类程序写成一个 专门的处理软件,这就是mysql等数据库管理软件的 ...
- {MySQL的库、表的详细操作}一 库操作 二 表操作 三 行操作
MySQL的库.表的详细操作 MySQL数据库 本节目录 一 库操作 二 表操作 三 行操作 一 库操作 1.创建数据库 1.1 语法 CREATE DATABASE 数据库名 charset utf ...
随机推荐
- Cross origin requests are only supported for protocol schemes: http, data, chrome, chrome-extension, https.
转自:https://www.zhihu.com/question/20948649?sort=created 我最近也遇到这个问题了,用传统的快捷方式加参数并没有用,不知道是不是和chrome版本有 ...
- git的团队协作开发
title: git的团队协作开发 date: 2018-04-24 14:00:03 tags: [git] --- 项目负责人创建组织架构 在控制面板中点击组织按钮,添加组织,在这里可以把组织理解 ...
- WPF线性渐变画刷应用之——炫彩线条
效果图: Xaml代码: <Rectangle Width="800" Height="10"> <Rectangle.Fill> &l ...
- Django-wed开发框架-练习题
https://www.cnblogs.com/pandaboy1123/p/9894981.html 1.列举Http请求常见的请求方式 HTTP协议是Hyper Text Transfer Pro ...
- R-CNN 学习记录
CNN是一个运用卷积神经网络进行图片分类的开山之作.RCNN是第一个把图片分类和目标检测连接起来的作品. RCNN主要解决的问题是: 1.怎样用深度神经网络进行目标定位:2.怎样用小批量的标注数据来训 ...
- 从初始化列表和构造函数谈C++的初始化机制
来源:http://blog.csdn.net/theprinceofelf/article/details/20057359 前段时间被人问及“初始化列表和构造有什么区别?”我竟一时语塞,只好回头 ...
- PHP多例模式介绍_PHP教程
1.多例类可以有多个实例2.多例类必须能够自我创建并管理自己的实例,并向外界提供自己的实例. 大家都知道PHP单例模式,却很少说PHP多例模式,下面是在wikipedia上看到的PHP多例模式的例子: ...
- zatree的安装
zatree的安装有2种 一种是支持2.x的用以下方法安装 zabbix安装zatree 实现图形树状化 官网:https://github.com/spide4k/zatree [root@SERV ...
- 解决error: only position independent executables (PIE) are supported
在Android.mk文件中添加以下内容 LOCAL_CFLAGS += -pie -fPIE LOCAL_LDFLAGS += -pie -fPIE 原帖地址:http://blog.csdn.ne ...
- [SQL]UNPIVOT 多個欄位
有朋友問「如何直接unpivot成2個欄位」,如下所示, 先準備測試資料如下, view source print? 01 create table T ( 02 no varchar(10), 03 ...