Hadoop生态圈-Kafka的旧API实现生产者-消费者
Hadoop生态圈-Kafka的旧API实现生产者-消费者
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.旧API实现生产者-消费者
1>.开启kafka集群
[yinzhengjie@s101 ~]$ more `which xkafka.sh`
#!/bin/bash
#@author :yinzhengjie
#blog:http://www.cnblogs.com/yinzhengjie
#EMAIL:y1053419035@qq.com #判断用户是否传参
if [ $# -ne ];then
echo "无效参数,用法为: $0 {start|stop}"
exit
fi #获取用户输入的命令
cmd=$ for (( i= ; i<= ; i++ )) ; do
tput setaf
echo ========== s$i $cmd ================
tput setaf
case $cmd in
start)
ssh s$i "source /etc/profile ; kafka-server-start.sh -daemon /soft/kafka/config/server.properties"
echo s$i "服务已启动"
;;
stop)
ssh s$i "source /etc/profile ; kafka-server-stop.sh"
echo s$i "服务已停止"
;;
*)
echo "无效参数,用法为: $0 {start|stop}"
exit
;;
esac
done [yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ more `which xkafka.sh`
[yinzhengjie@s101 ~]$ xkafka.sh start
========== s102 start ================
s102 服务已启动
========== s103 start ================
s103 服务已启动
========== s104 start ================
s104 服务已启动
[yinzhengjie@s101 ~]$
开启kafka集群([yinzhengjie@s101 ~]$ xkafka.sh start)
[yinzhengjie@s101 ~]$ xcall.sh jps
============= s101 jps ============
Jps
命令执行成功
============= s102 jps ============
QuorumPeerMain
Kafka
Jps
命令执行成功
============= s103 jps ============
Jps
QuorumPeerMain
Kafka
命令执行成功
============= s104 jps ============
Jps
QuorumPeerMain
Kafka
命令执行成功
============= s105 jps ============
Jps
命令执行成功
[yinzhengjie@s101 ~]$
[yinzhengjie@s101 ~]$ more `which xcall.sh`
#!/bin/bash
#@author :yinzhengjie
#blog:http://www.cnblogs.com/yinzhengjie
#EMAIL:y1053419035@qq.com #判断用户是否传参
if [ $# -lt ];then
echo "请输入参数"
exit
fi #获取用户输入的命令
cmd=$@ for (( i=;i<=;i++ ))
do
#使终端变绿色
tput setaf
echo ============= s$i $cmd ============
#使终端变回原来的颜色,即白灰色
tput setaf
#远程执行命令
ssh s$i $cmd
#判断命令是否执行成功
if [ $? == ];then
echo "命令执行成功"
fi
done
[yinzhengjie@s101 ~]$
检查kafka是否正常启动([yinzhengjie@s101 ~]$ xcall.sh jps)
2>.编写生产者端代码
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.kafka; import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
import java.util.Properties; public class TestProducer { public static void main(String[] args) throws Exception {
//初始化Java的Properties属性
Properties props = new Properties();
//通过metadata.broker.list参数设置代理,其value对应的kafka服务器地址,如果有多个就用逗号(",")分隔。
props.put("metadata.broker.list", "s102:9092, s103:9092, s104:9092");
//指定message的数据类型,将传输的数据都序列化成字符串(String),当然还有很多序列化方式(LongEncoder,NullEncoder,DefalutEmcoder,IntegerEncoder),比如默认为字节类型等等。
props.put("serializer.class", "kafka.serializer.StringEncoder");
//包装java的prop,包装成ProducerConfig
ProducerConfig config = new ProducerConfig(props);
//使用producerConfig初始化producer
//<String, String> 中第一个为key类型(未接触到),第二个是value类型,真实数据
Producer<String, String> producer = new Producer<String, String>(config);
//定义kafka的主题
String topic = "yinzhengjie";
for (int i = 1000; i < 2000; i++) {
KeyedMessage<String, String> data = new KeyedMessage<String, String>(topic, "BigData" + i);
producer.send(data);
Thread.sleep(500);
}
producer.close();
}
}
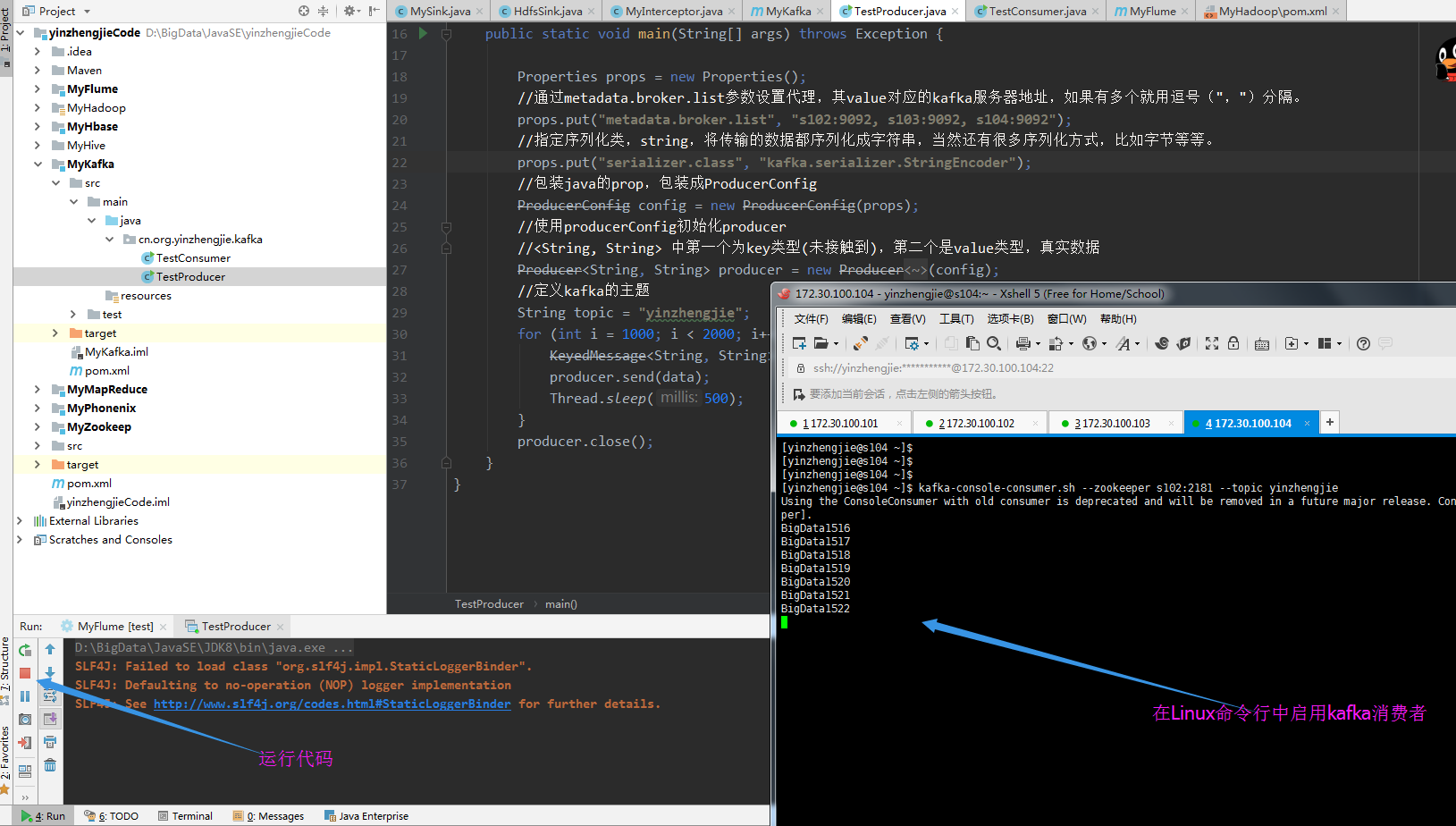
运行以上代码,并在Linux中断启用KafKa的消费者,截图如下:
3>.编写消费者端代码
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Hadoop%E7%94%9F%E6%80%81%E5%9C%88/
EMAIL:y1053419035@qq.com
*/
package cn.org.yinzhengjie.kafka; import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector; public class TestConsumer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("zookeeper.connect", "s102:2181,s103:2181,s104:2181");
//设置组id名称
props.put("group.id", "yzj");
//ZooKeeper的最大超时时间,就是心跳的间隔,若是没有反映,那么认为已经死了,不易过大
props.put("zookeeper.session.timeout.ms", "500");
//定义ZooKeeper集群中leader和follower之间的同步时间
props.put("zookeeper.sync.time.ms", "250");
//consumer向zookeeper提交offset的频率,单位是毫秒
props.put("auto.commit.interval.ms", "1000");
//把props封装成一个ConsumerConfig对象
ConsumerConfig conf = new ConsumerConfig(props);
//创建出一个ConsumerConnector实例
ConsumerConnector consumer = kafka.consumer.Consumer.createJavaConsumerConnector(conf);
//定义一个集合,这个集合最终被被传入到consumer.createMessageStreams()方法中。
Map<String, Integer> topicMap = new HashMap<String, Integer>();
//topicMap中指定第一个参数是主题,第二个参数是指定线程个数。
topicMap.put("yinzhengjie", new Integer(1));
//通过consumer和topic获取到数据流,在Map中的第一个参数是:topic,第二个参数是:消息列表
Map<String, List<KafkaStream<byte[], byte[]>>> consumerStreamsMap = consumer.createMessageStreams(topicMap);
//通过topic返回所有消息列表
List<KafkaStream<byte[], byte[]>> streamList = consumerStreamsMap.get("yinzhengjie");
//迭代所有list,通过迭代器获取消息流中的k-v
for (final KafkaStream<byte[], byte[]> stream : streamList) {
ConsumerIterator<byte[], byte[]> consumerIte = stream.iterator();
while (consumerIte.hasNext())
System.out.println("Message from Single Topic :: "+ new String(consumerIte.next().message()));
}
}
}
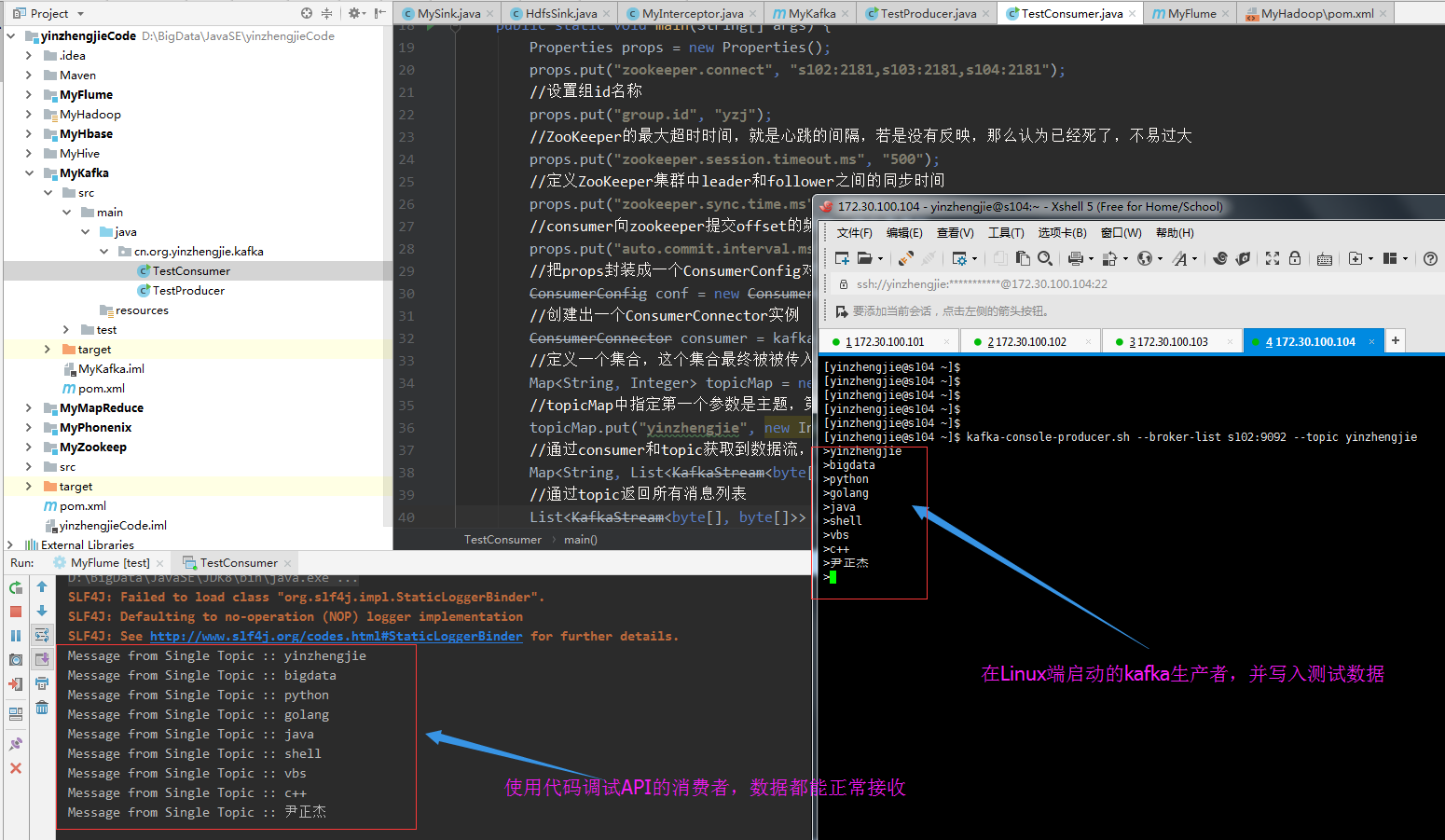
在Linux端启动生产者并运行以上代码,输出结果如下:
二.kafka的producer和Consumer配置(实战重点,调优手段)
1>.kafka的producer配置
>.metadata.broker.list
答:kafka服务器地址,如果有多个就用逗号(",")分隔。
>.serializer.class
答:指定message的数据类型。
>.key.serializer.class
答:指定key的数据类型,key的作用,用作选择分区。默认kafka.serializer.DefaultEncoder(byte[]),常用的还有
"kafka.serializer.NullEncoder","kafka.serializer.NullEncoder","kafka.serializer.StringEncoder","kafka.serializer.IntegerEncoder"
"kafka.serializer.LongEncoder"。 >.producer.type
答:指定消息应该如何发送。比如async和sync。
//async 异步,将数据发在缓冲区,一并发送给broker,无序 100000条数据:3792
//sync 同步,正常发送,有序 100000条数据:31939ms >.batch.num.messages
答:指定异步发送中一个批次含有多少条数据,默认200,超过此值就会发送。
>.queue.buffer.max.ms
答:队列的毫秒数,到达此值数据也会发送。 >.request.required.acks
答:获取回值,有三种回值方式(并对着三种方式处理100000条数据的所用时间):
//0意味着 producer不等待broker的回执,适用于最低延迟,不保证数据的完整性(3559)
//1意味着 只接收分区中的leader回执(4421)
//-1意味着 接收所有in-sync状态下的节点回执(6792) >.partitioner.class
答:指定分区函数类。 >.compression.codec
答:指定压缩编解码器none, gzip, and snappy.
2>.kafka的Consumer配置
重复消费的手段:
设置从头消费 //--from-beginning
//auto.offset.reset = smallest
手动控制消费偏移量 //通过修改zk数据 consumer/groupid/offsets/topic/partition >.group.id
答:指定消费者组id,没有指定会自动创建。 >.consumer.id
答:指定消费者的id,没有指定会自动创建。 >.zookeeper.connect
答:指定zookeeper客户端地址。 >.client.id
答:指定自己的客户端id,没有指定会和group.id一样。 >.zookeeper.session.timeout.ms
答:zk会话超时则抛异常。 >.zookeeper.connection.timeout.ms
答:zk连接超时则抛异常。 >.zookeeper.sync.time.ms
答:控制zk同步数据的时间。 >.auto.commit.enable
答:自动提交消息的偏移量到zk。
>.auto.commit.interval.ms
答:自动提交偏移量的间隔。 >.auto.offset.reset
答:设置从哪里读取数据
//largest 读取最新数据
//smallest 读取zk中偏移量的数据 >.consumer.timeout.ms
答:consumer超时抛异常,并关闭连接
3>.以上部分参数测试代码如下
三.
Hadoop生态圈-Kafka的旧API实现生产者-消费者的更多相关文章
- Hadoop生态圈-Kafka的新API实现生产者-消费者
Hadoop生态圈-Kafka的新API实现生产者-消费者 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Hadoop生态圈-Kafka的完全分布式部署
Hadoop生态圈-Kafka的完全分布式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客主要内容就是搭建Kafka完全分布式,它是在kafka本地模式(https:/ ...
- Hadoop生态圈-Kafka的本地模式部署
Hadoop生态圈-Kafka的本地模式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Kafka简介 1>.什么是JMS 答:在Java中有一个角消息系统的东西,我 ...
- Hadoop生态圈-kafka事务控制以及性能测试
Hadoop生态圈-kafka事务控制以及性能测试 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Hadoop生态圈-Kafka配置文件详解
Hadoop生态圈-Kafka配置文件详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.默认kafka配置文件内容([yinzhengjie@s101 ~]$ more /s ...
- Hadoop生态圈-使用phoenix的API进行JDBC编程
Hadoop生态圈-使用phoenix的API进行JDBC编程 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- Hadoop日记Day15---MapReduce新旧api的比较
我使用hadoop的是hadoop1.1.2,而很多公司也在使用hadoop0.2x版本,因此市面上的hadoop资料版本不一,为了扩充自己的知识面,MapReduce的新旧api进行了比较研究. h ...
- 使用Win32 API实现生产者消费者线程同步
使用win32 API创建线程,创建信号量用于线程的同步 创建信号量 语法例如以下 HANDLE semophore; semophore = CreateSemaphore(lpSemaphoreA ...
- Hadoop生态圈-Kafka常用命令总结
Hadoop生态圈-Kafka常用命令总结 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.管理Kafka服务的命令 1>.开启kafka服务 [yinzhengjie@s ...
随机推荐
- app.use( )做一个静态资源服务
var express = require("express"); var app = express(); //静态服务 app.use("/jingtai" ...
- Webpack学习-Webpack初识
一.前言 webpack 到底是个什么东西呢,看了一大堆的文档,没一个能看懂的,因为上来就是给个module.exports 然后列一大堆配置,这个干啥,那个干啥,没一点用.但凡要用一个东西,一个东西 ...
- 移动端效果之ScrollList
写在前面 列表一直是展示数据的一个重要方式,在手机端的列表展示又和PC端展示不同,毕竟手机端主要靠滑.之前手机端之前一直使用的IScroll,但是IScroll本身其实有很多兼容性BUG,想改动一下需 ...
- Configuration Section Designer for VS2017
Configuration Section Designer是在Visual Studio中设计符合.Net配置体系配置文件和代码的神器.然而,它的源码已经很久不维护了.现在在新的VS2017中无法使 ...
- 百炼1001: Exponentiation 解题
链接:http://bailian.openjudge.cn/practice/1001/ 思路 乍一看是很简单的题目,但是答案必须高精度输出,因此需要手动实现一个高精度运算方法.如果直接使用int, ...
- Katalon Studio学习笔记(二)——请求响应中文乱码解决方法
Katalon Studio接口测试发现返回的中文消息是乱码,这是因为KS的编码格式是UTF-8,因此导致中文字体出现乱码.如下图所示: 在我们的系统中添加一个名字为JAVA_TOOL_OPTIONS ...
- Frida----安装
介绍 它是本机应用程序的 Greasemonkey,或者更多技术术语,它是一个动态代码检测工具包.它允许您将JavaScript或您自己的库的片段注入Windows,macOS,GNU / Linux ...
- 《杜增强讲Unity之Tanks坦克大战》1-准备工作
0.案例介绍 0.1开始界面 点击Play Now 进入游戏界面 左边的坦克使用ws控制前后移动,ad键左右旋转,空格键开火 右边的坦克使用方向键上下控制前后移动,方向键左右键实现左右旋转 ...
- 作业要求 20181204-5 Final阶段贡献分配规则及实施
此作业要求参见:https://edu.cnblogs.com/campus/nenu/2018fall/homework/2479 贡献规则 贡献分分配规则: 组内一共八名同学,贡献分共计80分. ...
- linux 常用命令-ps(process state)
ps -ef | grep 端口号:查看某个端口的占用情况 ps -tunlp | grep 端口号:查看占用端口的进程名称