个推基于 Apache Pulsar 的优先级队列方案
作者:个推平台研发工程师 祥子
一、业务背景
在个推的推送场景中,消息队列在整个系统中占有非常重要的位置。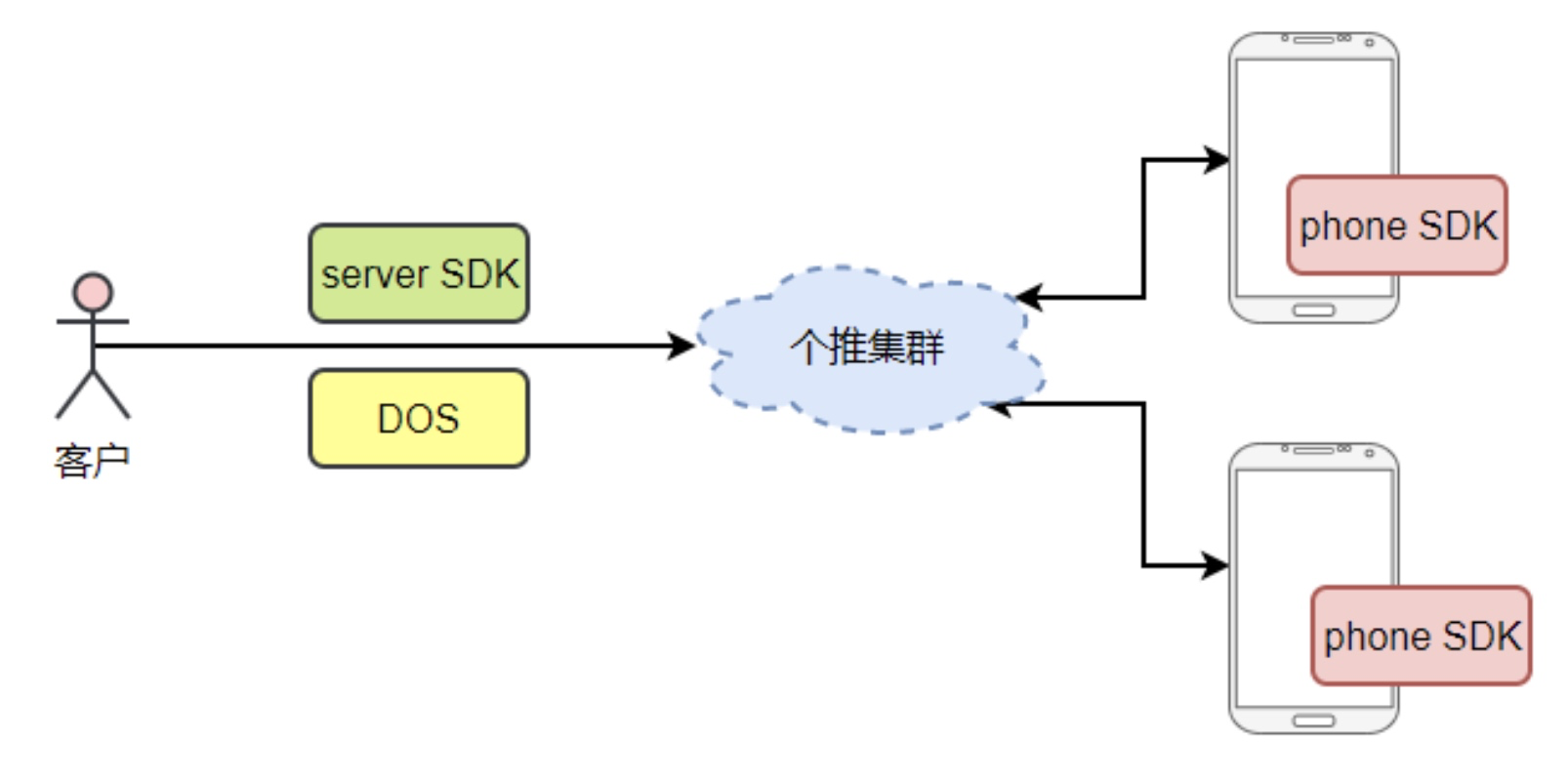
当 APP 有推送需求的时候, 会向个推发送一条推送命令,接到推送需求后,我们会把APP要求推送消息的用户放入下发队列中,进行消息下发;当同时有多个APP进行消息下发时,难免会出现资源竞争的情况, 因此就产生了优先级队列的需求,在下发资源固定的情况下, 高优先级的用户需要有更多的下发资源。
二、基于 Kafka 的优先级队列方案
针对以上场景,个推基于 Kafka 设计了第一版的优先级队列方案。Kafka 是 LinkedIn 开发的一个高性能、分布式消息系统;Kafka 在个推有非常广泛的应用,如日志收集、在线和离线消息分发等。
架构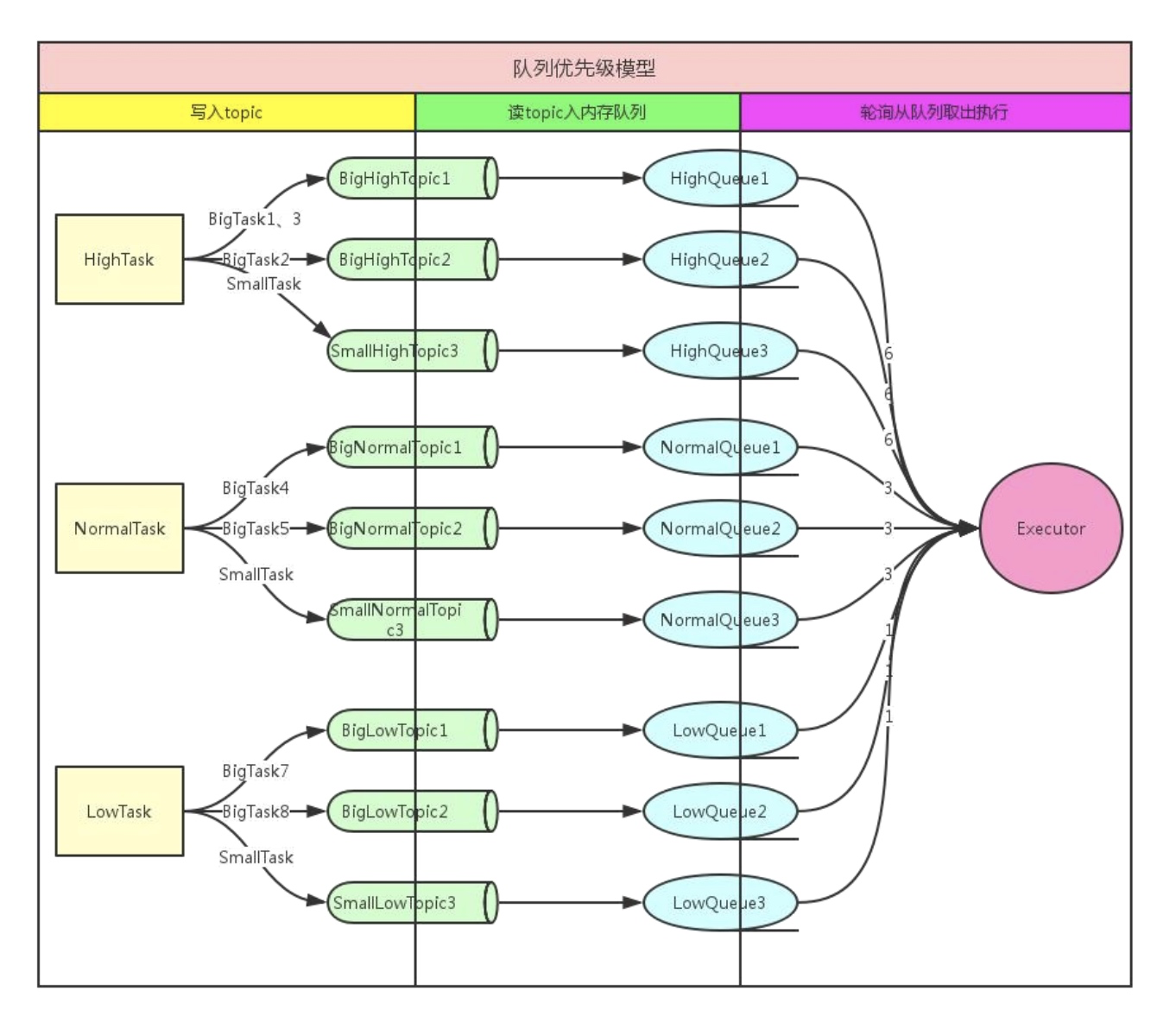
在该方案中,个推将优先级统一设定为高、中、低三个级别。具体操作方案如下:
1. 对某个优先级根据 task (单次推送任务)维度,存入不同的 Topic,一个 task 只写入一个 Topic,一个 Topic 可存多个 task;
2. 消费模块根据优先级配额(如 6:3:1),获取不同优先级的消息数,同一优先级轮询获取消息;这样既保证了高优先级用户可以更快地发送消息,又避免了低优先级用户出现没有下发的情况。
Kafka 方案遇到的问题
随着个推业务的不断发展,接入的 APP 数量逐渐增多,第一版的优先级方案也逐渐暴露出一些问题:
1. 当相同优先级的 APP 在同一时刻推送任务越来越多时,后面进入的 task 消息会因为前面 task 消息还存在队列情况而出现延迟。如下图所示, 当 task1 消息量过大时,在task1 消费结束前,taskN 将一直处于等待状态。
2. Kafka 在 Topic 数量由 64 增长到 256 时,吞吐量下降严重,Kafka 的每个 Topic、每个分区都会对应一个物理文件。当 Topic 数量增加时,消息分散的落盘策略会导致磁盘 IO 竞争激烈,因此我们不能仅通过增加 Topic 数量来缓解第一点中的问题。
基于上述问题,个推进行了新一轮的技术选型, 我们需要可以创建大量的 Topic, 同时吞吐性能不能比 Kafka 逊色。经过一段时间的调研,Apache Pulsar 引起了我们的关注。
三、为什么是 Pulsar
Apache Pulsar 是一个企业级的分布式消息系统,最初由 Yahoo 开发,在 2016 年开源,并于2018年9月毕业成为 Apache 基金会的顶级项目。Pulsar 已经在 Yahoo 的生产环境使用了三年多,主要服务于Mail、Finance、Sports、 Flickr、 the Gemini Ads platform、 Sherpa (Yahoo 的 KV 存储)。
架构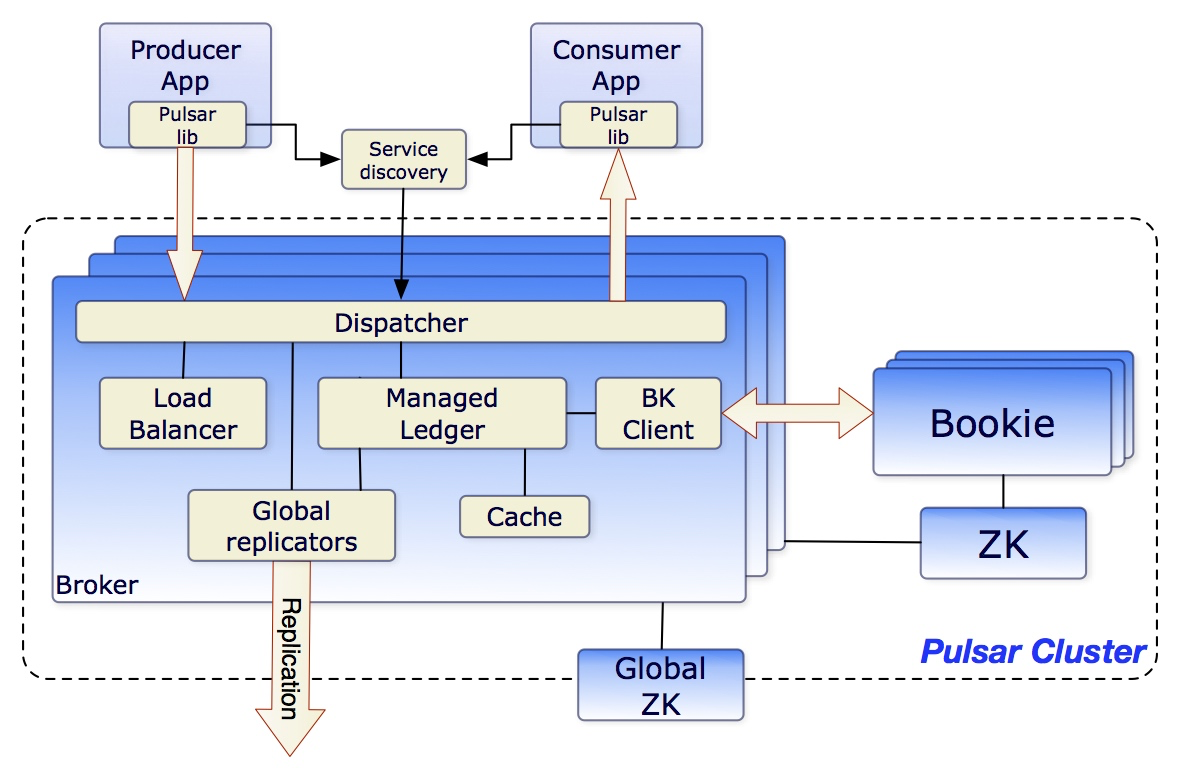
Topic 数量
Pulsar 可以支持百万级别 Topic 数量的扩展,同时还能一直保持良好的性能。Topic 的伸缩性取决于它的内部组织和存储方式。Pulsar 的数据保存在 bookie (BookKeeper 服务器)上,处于写状态的不同 Topic 的消息,在内存中排序,最终聚合保存到大文件中,在 Bookie 中需要更少的文件句柄。另一方面 Bookie 的 IO 更少依赖于文件系统的 Pagecache,Pulsar 也因此能够支持大量的主题。
消费模型
Pulsar 支持三种消费模型:Exclusive、Shared 和Failover。
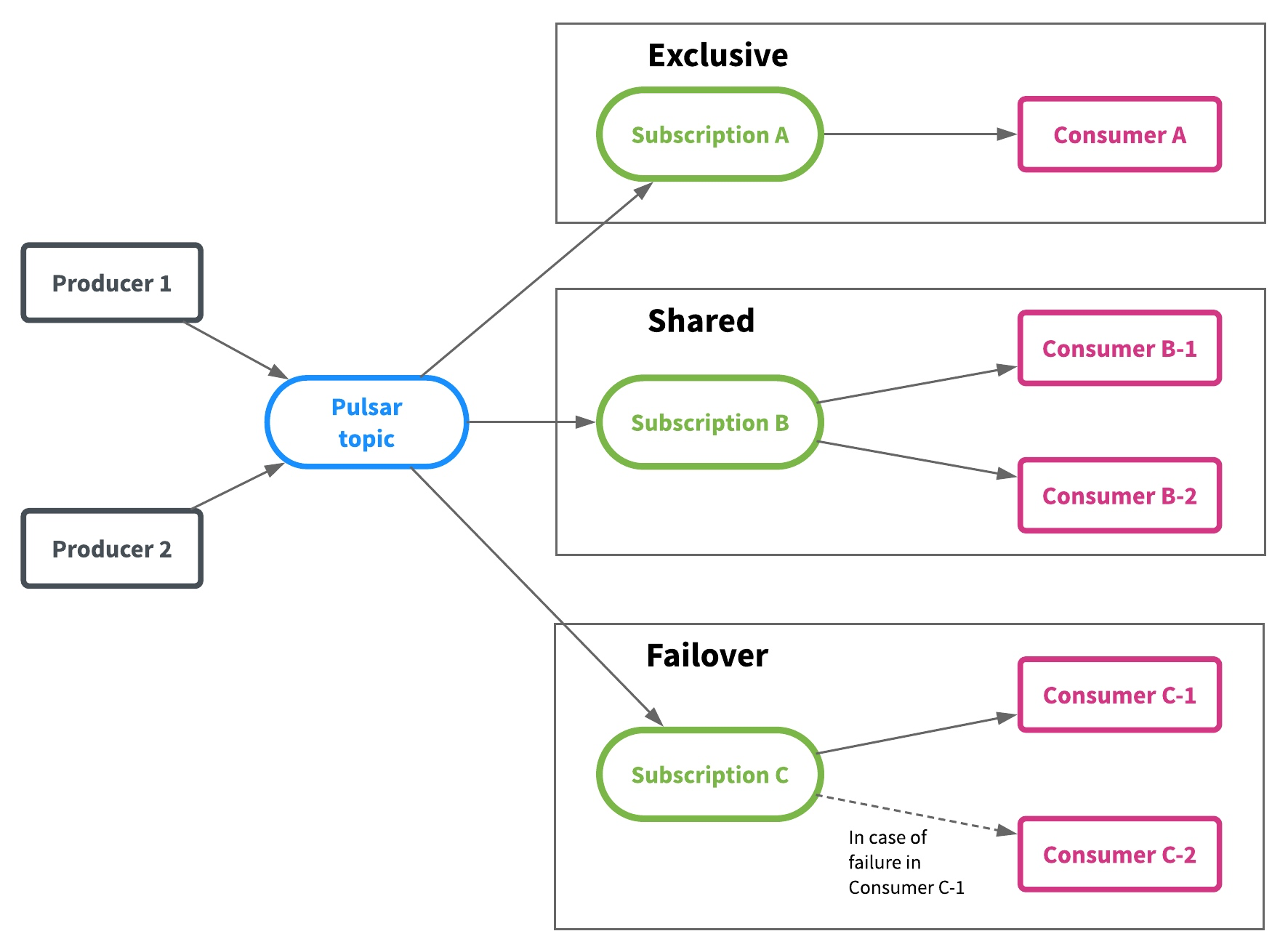
- Exclusive (独享):一个 Topic 只能被一个消费者消费。Pulsar 默认使用这种模式。
- Shared(共享):共享模式,多个消费者可以连接到同一个 Topic,消息依次分发给消费者。当一个消费者宕机或者主动断开连接时,那么分发给这个消费者的未确认(ack)的消息会得到重新调度,分发给其他消费者。
- Failover (灾备):一个订阅同时只有一个消费者,可以有多个备份消费者。一旦主消费者故障,则备份消费者接管。不会出现同时有两个活跃的消费者。
Exclusive和Failover订阅,仅允许一个消费者来使用和消费每个订阅的Topic。这两种模式都按 Topic 分区顺序使用消息。它们最适用于需要严格消息顺序的流(Stream)用例。
Shared 允许每个主题分区有多个消费者。同一个订阅中的每个消费者仅接收Topic分区的一部分消息。Shared最适用于不需要保证消息顺序队列(Queue)的使用模式,并且可以按照需要任意扩展消费者的数量。
存储
Pulsar 引入了 Apache BookKeeper 作为存储层,BookKeeper 是一个专门为实时系统优化过的分布式存储系统,具有可扩展、高可用、低延迟等特性。具体介绍,请参考 [BookKeeper官网](https://github.com/apache/bookkeeper)。
Segment
BookKeeper以 Segment (在 BookKeeper 内部被称作 ledger) 作为存储的基本单元。从 Segment 到消息粒度,都会均匀分散到 BookKeeper 的集群中。这种机制保证了数据和服务均匀分散在 BookKeeper 集群中。
Pulsar 和 Kafka 都是基于 partition 的逻辑概念来做 Topic 存储的。最根本的不同是,Kafka 的物理存储是以 partition 为单位的,每个 partition 必须作为一个整体(一个目录)存储在某个 broker 上。 而 Pulsar 的 partition 是以 segment 作为物理存储的单位,每个 partition 会再被打散并均匀分散到多个 bookie 节点中。
这样的直接影响是,Kafka 的 partition 的大小,受制于单台 broker 的存储;而 Pulsar 的 partition 则可以利用整个集群的存储容量。
扩容
当 partition 的容量达到上限后,需要扩容的时候,如果现有的单台机器不能满足,Kafka 可能需要添加新的存储节点,并将 partition 的数据在节点之间搬移达到 rebalance 的状态。
而 Pulsar 只需添加新的 Bookie 存储节点即可。新加入的节点由于剩余空间大,会被优先使用,接收更多的新数据;整个扩容过程不涉及任何已有数据的拷贝和搬移。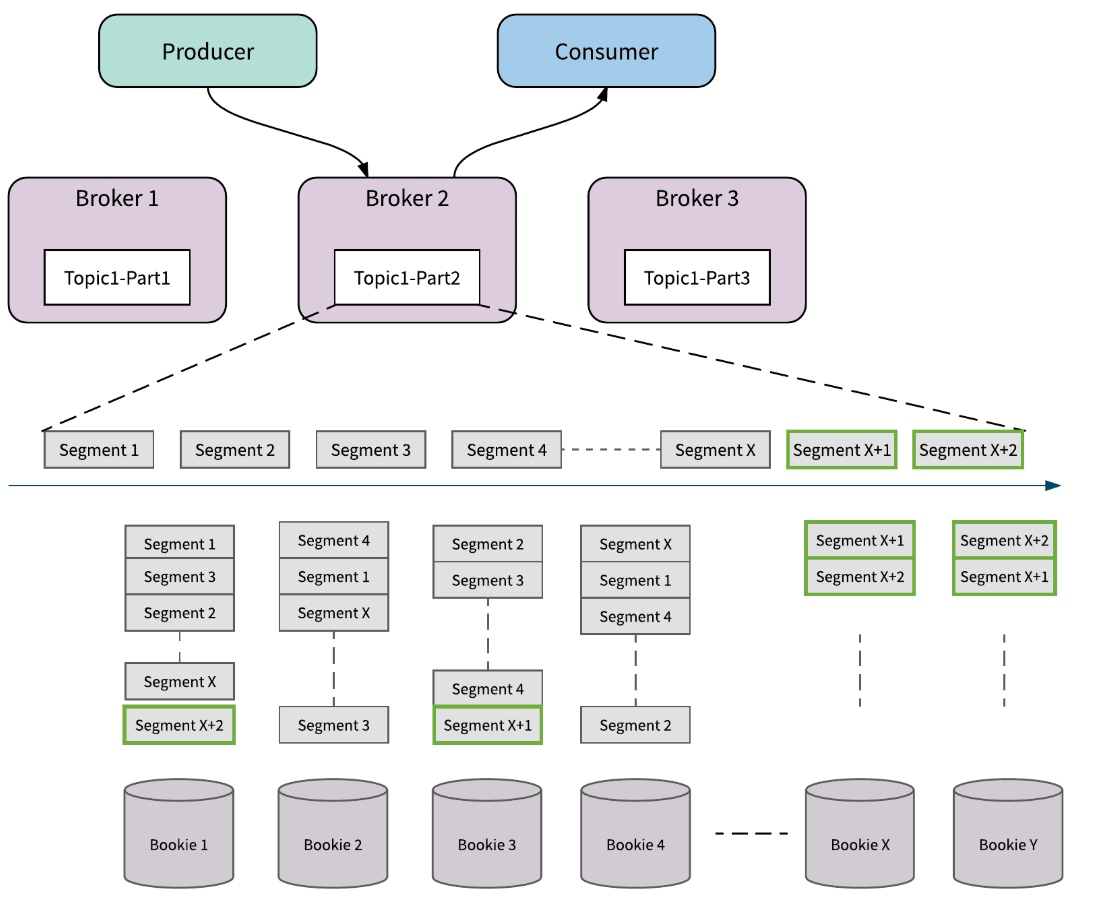
Broker 故障
Pulsar 在单个节点失败时也会体现同样的优势。如果 Pulsar 的某个服务节点 broker 失效,由于 broker 是无状态的,其他的 broker 可以很快接管 Topic,不会涉及 Topic 数据的拷贝;如果存储节点 Bookie 失效,在集群后台中,其他的 Bookie 会从多个 Bookie 节点中并发读取数据,并对失效节点的数据自动进行恢复,对前端服务不会造成影响。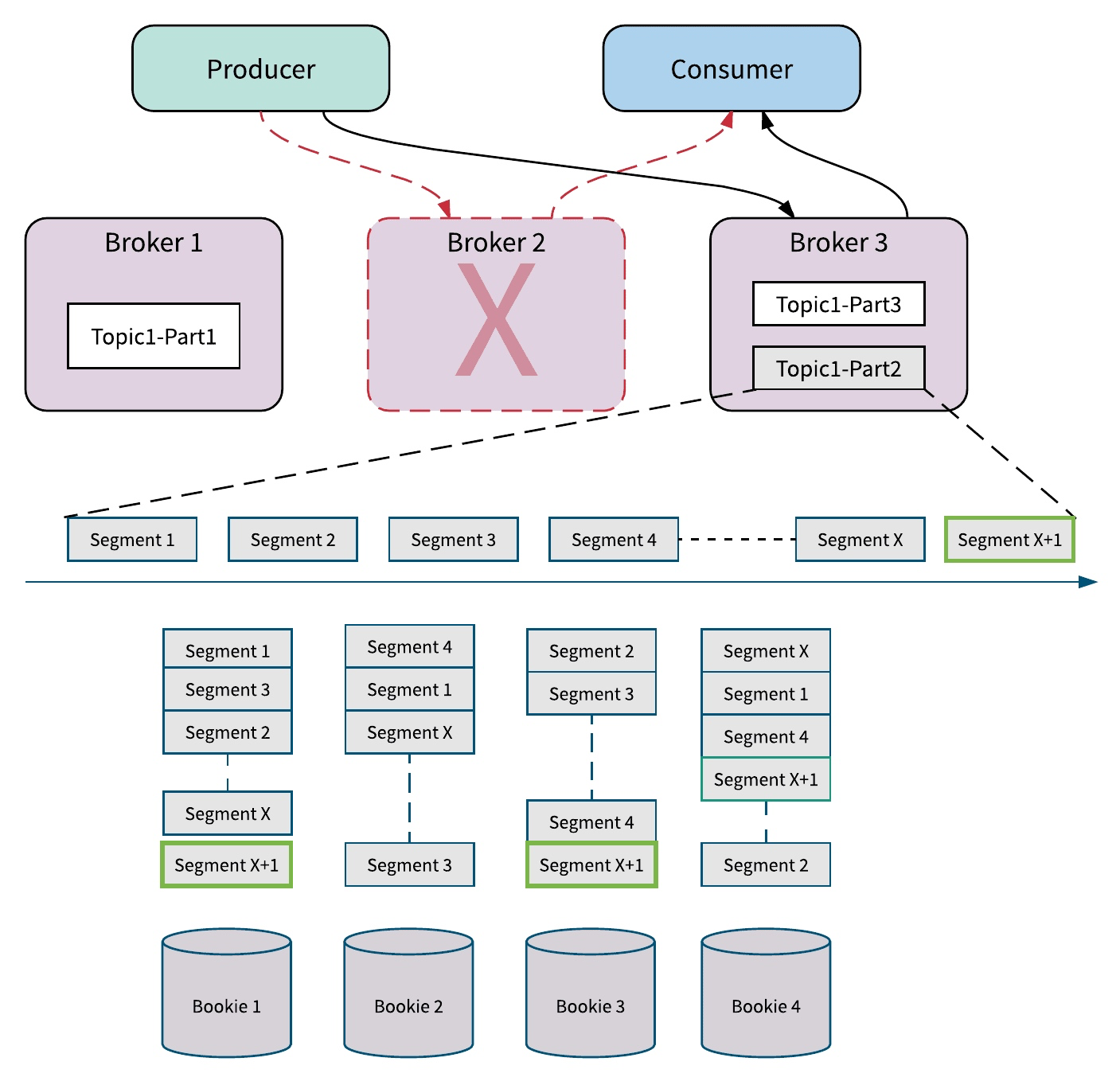
Bookie 故障
Apache BookKeeper 中的副本修复是 Segment (甚至是 Entry)级别的多对多快速修复。这种方式只会复制必须的数据,这比重新复制整个主题分区要精细。如下图所示,当错误发生时, Apache BookKeeper 可以从 bookie 3 和 bookie 4 中读取 Segment 4 中的消息,并在 bookie 1 处修复 Segment 4。所有的副本修复都在后台进行,对 Broker 和应用透明。
当某个 Bookie 节点出错时,BookKeeper会自动添加可用的新 Bookie 来替换失败的 Bookie,出错的 Bookie 中的数据在后台恢复,所有 Broker 的写入不会被打断,而且不会牺牲主题分区的可用性。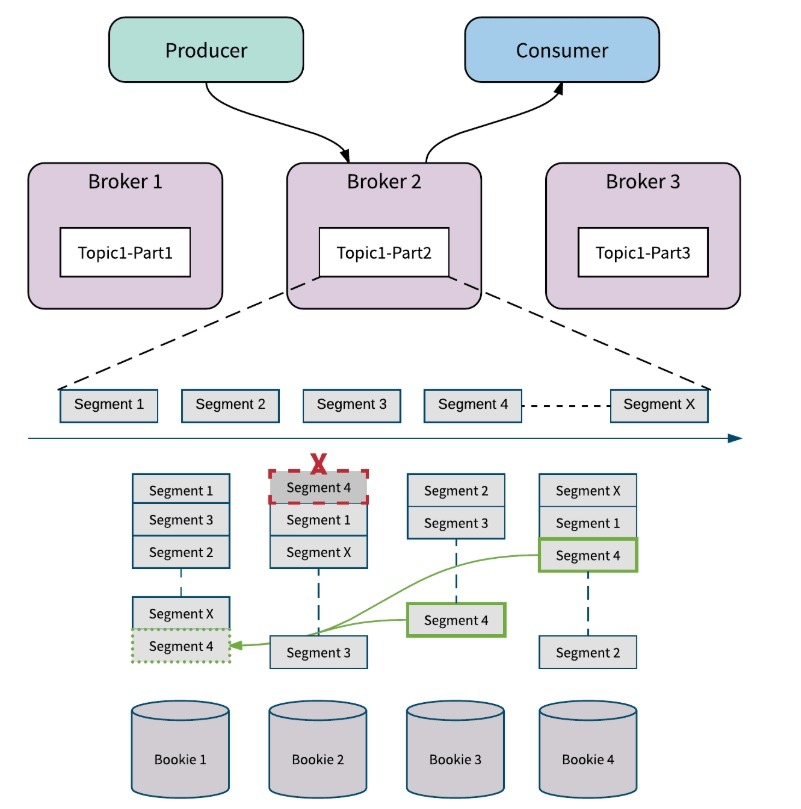
四、基于 Pulsar 的优先级队列方案
在设计思路上,Pulsar 方案和 Kafka 方案并没有多大区别。但在新方案中,个推技术团队借助 Pulsar 的特性,解决了 Kafka 方案中存在的问题。
1. 根据 task 动态生成 Topic,保证了后进入的 task 不会因为其他 task 消息堆积而造成等待情况。
2. 中高优先级 task 都独享一个 Topic,低优先级 task 共享 n 个 Topic。
3. 相同优先级内,各个 task 轮询读取消息,配额满后流转至下一个优先级。
4. 相同优先级内, 各个 task 可动态调整 quota, 在相同机会内,可读取更多消息。
5. 利用 Shared 模式, 可以动态添加删除 consumer,且不会触发 Rebalance 情况。
6. 利用 BookKeeper 特性,可以更灵活的添加存储资源。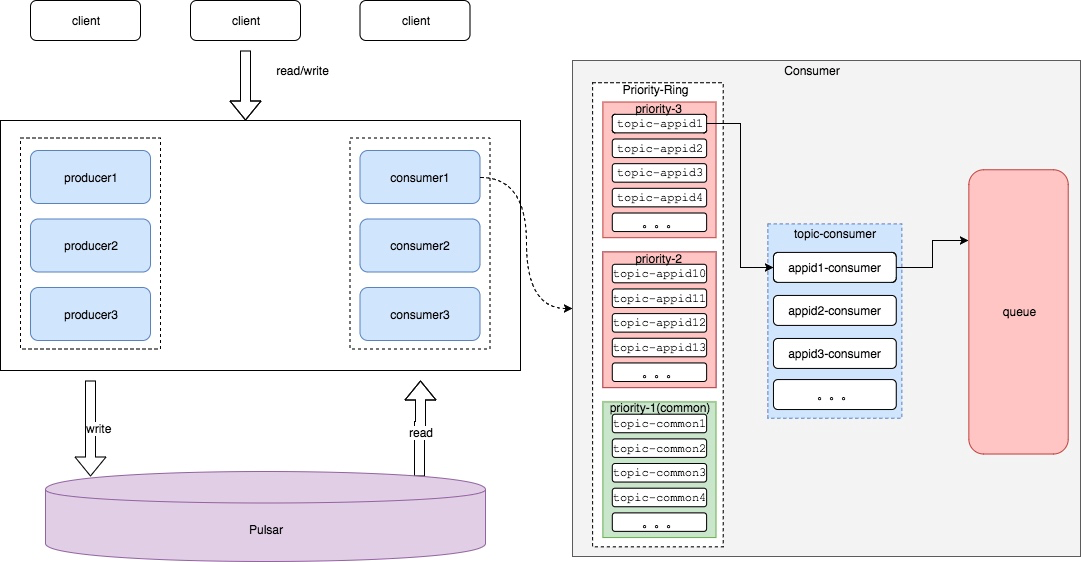
五、Pulsar 其他实践
1. 不同 subscription 之间相对独立,如果想要重复消费某个 Topic 的消息,需要使用不同的 subscriptionName 订阅;但是一直增加新的 subscriptionName,backlog 会不断累积。
2. 如果 Topic 无人订阅,发给它的消息默认会被删除。因此如果 producer 先发送,consumer 后接收,一定要确保 producer 发送之前,Topic 有 subscription 存在(哪怕 subscribe 之后 close 掉),否则这段时间发送的消息会导致无人处理。
3. 如果既没有人发送消息,又没有人订阅消息,一段时间后 Topic 会自动删除。
4. Pulsar 的 TTL 等设置,是针对整个 namespace 起效的,无法针对单个 Topic。
5. Pulsar 的键都建立在 zookeeper 的根目录上,在初始化时建议增加总节点名。
6. 目前 Pulsar 的 java api 设计,消息默认需要显式确认,这一点跟 Kafka 不一样。
7. Pulsar dashboard 上的 storage size 和 prometheus 上的 storage size (包含副本大小)概念不一样。
8. 把`dbStorage_rocksDB_blockCacheSize` 设置的足够大;当消息体量大,出现backlog 大量堆积时, 使用默认大小(256M)会出现读耗时过大情况,导致消费变慢。
9. 使用多 partition,提高吞吐。
10. 在系统出现异常时,主动抓取 stats 和 stats-internal,里面有很多有用数据。
11. 如果业务中会出现单 Topic 体量过大的情况,建议把 `backlogQuotaDefaultLimitGB` 设置的足够大(默认10G), 避免因为默认使用`producer_request_hold` 模式出现 block producer 的情况;当然可以根据实际业务选择合适的 `backlogQuotaDefaultRetentionPolicy`。
12. 根据实际业务场景主动选择 backlog quota。
13. prometheus 内如果发现读耗时为空情况,可能是因为直接读取了缓存数据;Pulsar 在读取消息时会先读取 write cache, 然后读取 read cache;如果都没有命中, 则会在 RocksDB 中读取条目位子后,再从日志文件中读取该条目。
14. 写入消息时, Pulsar 会同步写入 journal 和 write cache;write cache 再异步写入日志文件和 RocksDB; 所以有资源的话,建议 journal 盘使用SSD。
六、总结
现在, 个推针对优先级中间件的改造方案已经在部分现网业务中试运行,对于 Pulsar 的稳定性,我们还在持续关注中。
作为一个2016 年才开源的项目,Pulsar 拥有非常多吸引人的特性,也弥补了其他竞品的短板,例如跨地域复制、多租户、扩展性、读写隔离等。尽管在业内使用尚不广泛, 但从现有的特性来说, Pulsar 表现出了取代 Kafka 的趋势。在使用 Pulsar 过程中,我们也遇到了一些问题, 在此特别感谢翟佳和郭斯杰(两位均为 Stream Native 的核心工程师、开源项目 Apache Pulsar 的 PMC 成员)给我们提供的支持和帮助。
参考文献:
[1] 比拼 Kafka, 大数据分析新秀Pulsar 到底好在哪(https://www.infoq.cn/article/1UaxFKWUhUKTY1t_5gPq)
[2] 开源实时数据处理系统Pulsar:一套搞定Kafka+Flink+DB(https://juejin.im/post/5af414365188256717765441)
个推基于 Apache Pulsar 的优先级队列方案的更多相关文章
- SpringBoot | 第三十八章:基于RabbitMQ实现消息延迟队列方案
前言 前段时间在编写通用的消息通知服务时,由于需要实现类似通知失败时,需要延后几分钟再次进行发送,进行多次尝试后,进入定时发送机制.此机制,在原先对接银联支付时,银联的异步通知也是类似的,在第一次通知 ...
- 使用Apache Pulsar + Hudi构建Lakehouse方案了解下?
1. 动机 Lakehouse最早由Databricks公司提出,其可作为低成本.直接访问云存储并提供传统DBMS管系统性能和ACID事务.版本.审计.索引.缓存.查询优化的数据管理系统,Lakeho ...
- Apache Pulsar 在腾讯 Angel PowerFL 联邦学习平台上的实践
腾讯 Angel PowerFL 联邦学习平台 联邦学习作为新一代人工智能基础技术,通过解决数据隐私与数据孤岛问题,重塑金融.医疗.城市安防等领域. 腾讯 Angel PowerFL 联邦学习平台构建 ...
- Message deduplication 这里的去重与你想的可能不一样|Apache Pulsar 技术系列
导语 Apache Pulsar 是一个多租户.高性能的服务间消息传输解决方案,支持多租户.低延时.读写分离.跨地域复制.快速扩容.灵活容错等特性.腾讯云内部 Pulsar工作组对 Pulsar 做了 ...
- 分布式消息队列Apache Pulsar
Pulsar简介 Apache Pulsar是一个企业级的分布式消息系统,最初由Yahoo开发并在2016年开源,目前正在Apache基金会下孵化.Plusar已经在Yahoo的生产环境使用了三年多, ...
- java PriorityBlockingQueue 基于优先级队列,的读出操作可以阻止.
java PriorityBlockingQueue 基于优先级队列.的读出操作可以阻止. package org.rui.thread.newc; import java.util.ArrayLis ...
- 笔试算法题(57):基于堆的优先级队列实现和性能分析(Priority Queue based on Heap)
议题:基于堆的优先级队列(最大堆实现) 分析: 堆有序(Heap-Ordered):每个节点的键值大于等于该节点的所有孩子节点中的键值(如果有的话),而堆数据结构的所有节点都按照完全有序二叉树 排.当 ...
- 如何基于RabbitMQ实现优先级队列
概述 由于种种原因,RabbitMQ到目前为止,官方还没有实现优先级队列,只实现了Consumer的优先级处理. 但是,迫于种种原因,应用层面上又需要优先级队列,因此需求来了:如何为RabbitMQ加 ...
- Apache Pulsar 在 BIGO 的性能调优实战(上)
背景 在人工智能技术的支持下,BIGO 基于视频的产品和服务受到广泛欢迎,在 150 多个国家/地区拥有用户,其中包括 Bigo Live(直播)和 Likee(短视频).Bigo Live 在 15 ...
随机推荐
- system表空间不可改名
SQL> startup mount;ORACLE instance started. Total System Global Area 814227456 bytesFixed Size ...
- CS299笔记:广义线性模型
指数分布族 我们称一类分布属于指数分布族(exponential family distribution),如果它的分布函数可以写成以下的形式: \[ \begin{equation} p(y;\et ...
- Arcgis安装要素
1. ArcGIS安装过程中需将用户名改为计算机名,该计算机名称时需要新建对话框. 2. ArcGIS Server安装过程中要设置ArcGISWebServices用户的读写权限,即设置ASP.NE ...
- 本地navicat远程连接到云服务器数据库
本来没有开启秘钥的远程服务器端数据库连接非常方便,就在新建连接上填入数据就ok了,但是开启SSH秘钥后的服务器连接有一个大坑,下面来详细讲讲. 其实开启了秘钥,在新建连接下,先选择SSH方式登录到远程 ...
- stl源码剖析 详细学习笔记 算法(2)
//---------------------------15/03/29---------------------------- //****************************set相 ...
- 《Effective Java》学习笔记 —— 枚举、注解与方法
Java的枚举.注解与方法... 第30条 用枚举代替int常量 第31条 用实例域代替序数 可以考虑定义一个final int 代替枚举中的 ordinal() 方法. 第32条 用EnumSet代 ...
- CocoaPods 遇到 A host target is a "parent" target which embeds a "child" target 问题解决
正在开发的项目中,集成RN,在使用cocoapods 时候,pod install 遇到如下问题: [!] Unable to find host target(s) for ****Extensio ...
- 《Linux内核分析》第三周笔记 构造一个简单的Linux系统MenuOS
构造一个简单的Linux系统MenuOS 一.linux内核源代码简介 三大法宝(存储程序计算机.函数调用堆栈.中断)和两把宝剑(中断上下文的切换:保存现场和恢复现场.进程上下文的切换) 1.在lin ...
- 转发npm发布包的过程
老板,来个npm账号! 因为你的包是要放在npm上的,所以,没有npm的账号,根本什么活都干不了. 在npm上注册一个账号是很简单的,随便填一下用户名密码邮箱,然后人家就会发个邮件给你,然后就注册成功 ...
- PowerDesigner16工具学习笔记-建立CDM
1.基本术语 1.1.实体和属性 实体(entity):指现实世界中客观存在,并可相互区别的事物或者事件. 属性(attribute):一组用来描述实体特征的属性. 实体集(entity set):具 ...