爬虫--requests模块学习
requests模块
- 基于如下5点展开requests模块的学习
- 什么是requests模块
- requests模块是python中原生的基于网络请求的模块,其主要作用是用来模拟浏览器发起请求。功能强大,用法简洁高效。在爬虫领域中占据着半壁江山的地位。
- 为什么要使用requests模块
- 因为在使用urllib模块的时候,会有诸多不便之处,总结如下:
- 手动处理url编码
- 手动处理post请求参数
- 处理cookie和代理操作繁琐
- ......
- 使用requests模块:
- 自动处理url编码
- 自动处理post请求参数
- 简化cookie和代理操作
- ......
- 因为在使用urllib模块的时候,会有诸多不便之处,总结如下:
- 如何使用requests模块
- 安装:
- pip install requests
- 使用流程
- 指定url
- 基于requests模块发起请求
- 获取响应对象中的数据值
- 持久化存储
- 安装:
- 通过5个基于requests模块的爬虫项目对该模块进行学习和巩固
- 基于requests模块的get请求
- 需求:爬取搜狗指定词条搜索后的页面数据
- 基于requests模块的post请求
- 需求:登录豆瓣电影,爬取登录成功后的页面数据
- 基于requests模块ajax的get请求
- 需求:爬取豆瓣电影分类排行榜 https://movie.douban.com/中的电影详情数据
- 基于requests模块ajax的post请求
- 需求:爬取肯德基餐厅查询http://www.kfc.com.cn/kfccda/index.aspx中指定地点的餐厅数据
- 综合练习
- 需求:爬取搜狗知乎指定词条指定页码下的页面数据
- 基于requests模块的get请求
1、基于requests模块的get请求--不带参数
- 需求:爬取搜狗首页数据
import requests
# 1.指定url
url = 'https://www.sogou.com/' # 不带参数 # 2.发起一个get请求,get方法会返回 请求成功后的响应对象
response = requests.get(url=url) # 3.获取响应中的数据值:text可以获取响应对象中的字符串形式的页面数据
page_data = response.text
#print(page_data) # 持久化操作
with open('./sogou.html','w',encoding='utf-8')as f:
f.write(page_data)

response对象中其他重要的属性
# response对象中其他重要的属性
import requests
# 1.指定url--用于请求的目标网站
url = 'https://www.sogou.com/'
# 2.发起一个get请求,get方法会返回 请求成功后的响应对象
response = requests.get(url=url) # content获取的是response对象中二进制(byte)类型的页面数据
#print(response.content) # 返回一个响应状态码
#print(response.status_code) # 返回响应头信息--字典的形式
#print(response.headers) # 获取请求的url
print(response.url)
- requests模块如何处理携带参数的get请求
- 需求:指定一个词条,获取搜狗搜索结果所对应的页面数据
# 方式1
import requests
# 1指定url
url = 'https://www.sogou.com/web?query=周杰伦&ie=utf8' #带参数 # 获取响应对象
response = requests.get(url=url) page_text = response.text # 持久化存储
with open('./zhou.html','w',encoding='utf-8')as f:
f.write(page_text)
-------------------------------------------------------------------------
# 方式2:
import requests
url = 'https://www.sogou.com/web' # 将参数封装到字典中
params = {'query':'周杰伦','ie':'utf8'}
response = requests.get(url=url,params=params)
response.status_code
#print(response.content)
requests--自定义请求头信息
# 自定义请求头信息
import requests
url = 'https://www.sogou.com/web'
# 将参数封装到字典中
params = {'query':'周杰伦','ie':'utf8'} # 自定义请求头信息
# 此处用的百度的UA
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'} # 拿到响应对象
response = requests.get(url=url,params=params,headers=headers)
response.status_code
request模块的post请求
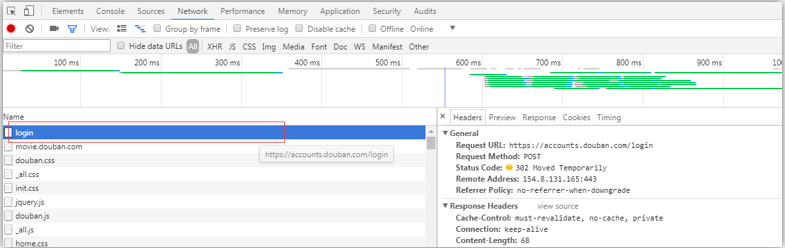
需求:登录豆瓣电影,爬取登录成功后的页面数据---测试成功
点击登陆后

----------------------------------------------------------------------------------------------------------------------------
------------------------------------

import requests
# 1.指定post请求的url
url = 'https://accounts.douban.com/login' # 封装post请求的参数
data = {
'source':'movie',
'redir':'https://movie.douban.com/',
'form_email':'你的豆瓣邮箱',
'form_password':'你的登录密码',
'login':'登录',
}
# 自定义请求头信息
# 此处用的百度的UA
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
# 拿到响应对象
# 2.发起post请求
response = requests.post(url=url,data=data,headers=headers)
response.status_code # 3.获取响应对象的页面数据
page_text = response.text # 持久化存储
with open('./douban.html','w',encoding='utf-8')as f:
f.write(page_text)

基于requests模块ajax的get请求
爬取豆瓣电影分类排行榜 https://movie.douban.com/中的电影详情数据

选择一个种类的电影:点击加载更多

点击加载更多--ajax异步-get请求--局部刷新


------------------------
import requests
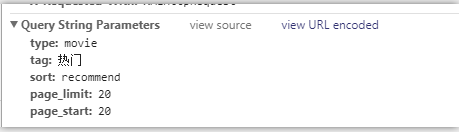
# url = 'https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=20' #指定ajax-get请求的url(通过抓包进行获取)
url = 'https://movie.douban.com/j/search_subjects?' params = {
'type':'movie',
'tag':'热门',
'sort':'recommend',
'page_limit':'',
'page_start':'',
} # 自定义请求头信息
# 此处用的百度的UA
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'} response = requests.get(url=url,params=params,headers=headers) # 3.获取响应对象的页面数据
page_text = response.text
print(page_text)
---------------------------------------

基于ajax的post请求
- 爬取肯德基餐厅查询http://www.kfc.com.cn/kfccda/index.aspx中指定地点的餐厅数据
点击查询是ajax异步请求,局部刷新

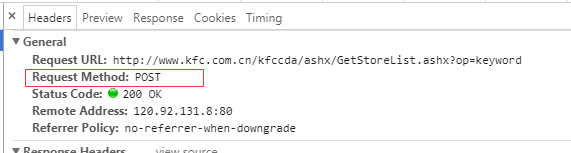
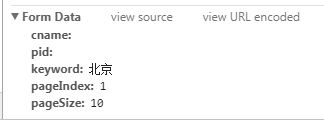
import requests post_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword' # 处理post请求的参数
data = {
'cname':'',
'pid':'',
'keyword':'北京',
'pageIndex':'',
'pageSize':'',
} headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'} # 发起基于ajax的post请求
response = requests.post(url=post_url,data=data,headers=headers) # 3.获取响应对象的页面数据
page_text = response.text
print(page_text)

综合实战
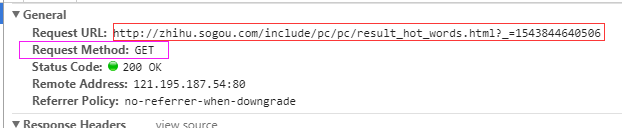
需求:爬取搜狗知乎指定词条指定页码下的页面数据
具有分页的爬取

http://zhihu.sogou.com/zhihu?query=%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD&page=2&ie=utf8

----------------------------------------------
# 前三页的数据{1,2,3}
import requests
import os
# 创建一个文件夹
if not os.path.exists('./pages'):
os.mkdir('./pages')
# s搜索词条
word = input('enter a word')
# 动态指定页码的范围
start_page = int(input('enter a start pageNum:'))
end_page = int(input('enter a end pageNum'))
# 1.指定url--设计成一个具有通用的url
url = 'http://zhihu.sogou.com/zhihu'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
# 循环取页面值 -- page
for page in range(start_page,end_page+1):
params = {'query':word,'page':page,'ie':'utf-8'}
response = requests.get(url=url,params=params,headers=headers)
# 获取响应中页面数据(指定页码(page))
page_text = response.text
# 进行持久化处理
fileName = word+str(page)+'.html'
filePath = 'pages/'+fileName
with open(filePath,'w',encoding='utf-8')as f:
f.write(page_text)
print(f"第{page}页数据写入成功")
# get ===>params
# post===>data


爬虫--requests模块学习的更多相关文章
- 爬虫入门之Requests模块学习(四)
1 Requests模块解析 Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用 Requests 继承了urllib2的所有特性.Requests支持HTTP连接保 ...
- requests模块学习
- 基于如下5点展开requests模块的学习 什么是requests模块 requests模块是python中原生的基于网络请求的模块,其主要作用是用来模拟浏览器发起请求.功能强大,用法简洁高效.在 ...
- 爬虫 requests模块的其他用法 抽屉网线程池回调爬取+保存实例,gihub登陆实例
requests模块的其他用法 #通常我们在发送请求时都需要带上请求头,请求头是将自身伪装成浏览器的关键,常见的有用的请求头如下 Host Referer #大型网站通常都会根据该参数判断请求的来源 ...
- 爬虫----requests模块
一.介绍 #介绍:使用requests可以模拟浏览器的请求,比起之前用到的urllib,requests模块的api更加便捷(本质就是封装了urllib3) #注意:requests库发送请求将网页内 ...
- 爬虫——requests模块
一 爬虫简介 #1.什么是互联网? 互联网是由网络设备(网线,路由器,交换机,防火墙等等)和一台台计算机连接而成,像一张网一样. #2.互联网建立的目的? 互联网的核心价值在于数据的共享/传递:数据是 ...
- 2 爬虫 requests模块
requests模块 Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库,Requests它会比urllib更加方便,reques ...
- 爬虫--requests模块高级(代理和cookie操作)
代理和cookie操作 一.基于requests模块的cookie操作 引言:有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个人主页数据)时,如果使用之前requests ...
- Python网络爬虫-requests模块(II)
有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个人主页数据)时,如果使用之前requests模块常规操作时,往往达不到我们想要的目的,例如: #!/usr/bin/env ...
- Python网络爬虫-requests模块
requests模块 requests模块是python中原生的基于网络请求的模块,其主要作用是用来模拟浏览器发起请求.功能强大,用法简洁高效.在爬虫领域中占据着半壁江山的地位. 如何使用reques ...
随机推荐
- 即用了 测试脚本里面的 类的值,又继承了 unittest类 使用他的断言方法 (接口自动化 数据分离 变量相互调用 看这里)
- java1.8 新特性(五 如何使用filter,limit ,skip ,distinct map flatmap ,collect 操作 java集合)
使用filter 根据 条件筛选 出结果:例如 找出 user 中 age >=15 的用户 package lambda.stream; /** * @author 作者:cb * @vers ...
- windows修改远程桌面端口3389
regedit 按照路径打开,HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Terminal Server\WinStations\RDP-T ...
- go中的make和new的区别
适用范围:make 只能创建内建类型(slice map channel), new 则是可以对所有类型进行内存分配 返回值: new 返回指针, make 返回引用 填充值: new 填充零值, m ...
- 标准C库函数
标准库函数由15个头文件组成 1.math.h 1.1 绝对值函数 1.2 幂函数.开平方函数 1.3 指数函数.对数函数 1.5 三角函数 注意参数范围: 1.6 取整函数.取余函数 2.字符串处理 ...
- studio之mac快捷键
2. SouceTree忽略文件: .gitignore文件编辑: 忽略指定文件:直接写文件名 忽略文件夹:直接写文件夹路径,例:target或者target/ -> 忽略target下的所有 ...
- [UE4]Datasmith
Datasmith 是帮助您将内容导入到虚幻引擎4中的一组工具和插件. 作为虚幻工作室产品的部分,Datasmith设计用于解决非游戏行业人士所面临的独特挑战,例如建筑.工程.建造.制造.实时培训等行 ...
- [UE4]圆形的动态材质,使用VectorParameter、Get Dynamic Material、Set Vector Parameter Value
一.新建一个名为M_FriendColor的材质.使用VectorParameter函数 二.新建一个名为FriendFlag的UserWidget,生成随机颜色,并传递给上一步设置的材质参数Colo ...
- [UE4]Cast to OverlaySlot、Set Vertical Alignment、Get Slot,解决Child Widget垂直居中对齐问题
- echarts3更新
dataRange: { realtime: false, itemHeight: 80, splitNumber:6, borderWidth:1, textStyle: { color: '#33 ...