大数据入门第十四天——Hbase详解(一)入门与安装配置
一、概述
1.什么是Hbase
根据官网:https://hbase.apache.org/
Apache HBase™ is the Hadoop database, a distributed, scalable, big data store.
HBASE是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统
中文简明介绍:
Hbase是分布式、面向列的开源数据库(其实准确的说是面向列族)。HDFS为Hbase提供可靠的底层数据存储服务,MapReduce为Hbase提供高性能的计算能力,Zookeeper为Hbase提供稳定服务和Failover机制,因此我们说Hbase是一个通过大量廉价的机器解决海量数据的高速存储和读取的分布式数据库解决方案。
2.什么是列式存储
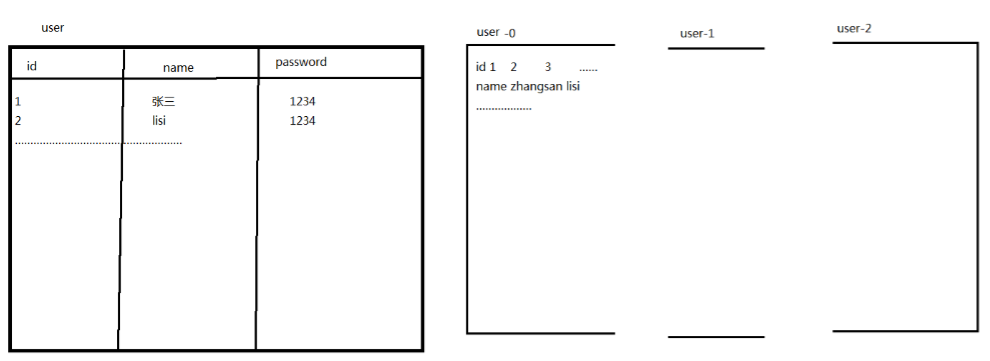
使用网友的图就是:


其中更加深入的内部原理讲解,参考:http://blog.csdn.net/lifuxiangcaohui/article/details/39891099
http://lib.csdn.net/article/datastructure/8951
3.为什么需要Hbase
以下介绍了一种Hbase出现的场景:

更多完整的原因介绍,参考:http://www.thebigdata.cn/HBase/30332.html
与传统数据库的对比如下:
1、传统数据库遇到的问题:
1)数据量很大的时候无法存储
2)没有很好的备份机制
3)数据达到一定数量开始缓慢,很大的话基本无法支撑
2、HBASE优势:
1)线性扩展,随着数据量增多可以通过节点扩展进行支撑
2)数据存储在hdfs上,备份机制健全
3)通过zookeeper协调查找数据,访问速度块。
4.hbase中的角色
1、一个或者多个主节点,Hmaster
2、多个从节点,HregionServer
二、安装与配置
1.上传
这里暂时使用hbase0.99,其他与Hadoop的兼容性问题,参考文档Basic Prerequisites处,另外,此文档有翻译版本:点击查看
这次我们使用sftp来上传(比古老的rz/sz要更快),操作参考之前随笔:http://www.cnblogs.com/jiangbei/p/8041713.html
2.解压
先在一台机器上操作,之后再复制发送到其他集群中的机器
[hadoop@mini1 ~]$ tar -zxvf hbase-0.99.-bin.tar.gz -C apps/
// 之后是可以删除这个压缩包的
3.重命名
[hadoop@mini1 apps]$ mv hbase-0.99./ hbase
//当然,这一步是可选的
4.修改环境变量
[hadoop@mini1 apps]$ sudo vim /etc/profile
增加以下两行
export HBASE_HOME=/home/hadoop/apps/hbase
export PATH=$PATH:$HBASE_HOME/bin
[hadoop@mini1 apps]$ source /etc/profile
5.修改配置文件
现在来看conf/下的文件,基本也能摸索出规律了:
[hadoop@mini1 hbase]$ cd conf/
[hadoop@mini1 conf]$ ls
hadoop-metrics2-hbase.properties hbase-policy.xml regionservers
hbase-env.cmd hbase-site.xml
hbase-env.sh log4j.properties
xxx-site:核心配置文件;xxx-env.sh:环境配置(以防PATH未配);没有后缀名的:配置从节点
修改hbase-env.sh:
# JDK
export JAVA_HOME=/opt/java/jdk1..0_151
# 通过hadoop配置文件,找到hadoop集群,请正确选择配置文件地址!
export HBASE_CLASSPATH=/home/hadoop/apps/hadoop-2.6./etc/hadoop
# 是否使用自带的zookeeper,false表示使用自己的
export HBASE_MANAGES_ZK=false
配置hbase-site.xml:
<configuration>
<!--指定hbase集群主控节点 -->
<property>
<name>hbase.master</name>
<value>mini1:60000</value>
</property>
<property>
<name>hbase.master.maxclockskew</name>
<value>180000</value>
</property>
<!-- 设置hbase数据库存放数据的目录-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://mini1:9000/hbase</value>
</property>
<!-- 打开hbase分布模式-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 指定zookeeper集群节点名,因为是由zookeeper表决算法决定的-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>mini1,mini2,mini3</value>
</property>
<!-- 指zookeeper集群data目录-->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/apps/hbase/tmp/zookeeper</value>
</property>
</configuration>
配置regionservers
mini2
mini3
6.分发配置到从节点
如果没有配置免密登录,请先参考这里
scp -r hbase/ mini2:/home/hadoop/apps/
scp -r hbase/ mini3:/home/hadoop/apps/
7.启动
需要先启动hadoop:
[hadoop@mini1 apps]$ start-dfs.sh
一键启动hbase也是非常类似的:
start-hbase.sh
通过Jps可以查看!
悔不该当初通过root装的zookeeper集群,现在启动还得通过root和绝对路径启动!所以这里选择重装zk集群!
// 或者切换到root使用一键启动脚本 startZK.sh
//这里0.99.2版本无法访问mini1:60010端口,不知何解(也不是hadoop安全模式问题),也不是1.0以后版本的问题:点击查看
不过这里web页面也不是重点,具体解决待补充
单独启动与停止脚本与hadoop基本类似:
hbase-daemon.sh start master
hbase-daemon.sh start regionserver
8.配置多master
在任意的安装了hbase的机器上启动hmaster.执行 命令:
local-master-backup.sh start
大数据入门第十四天——Hbase详解(一)入门与安装配置的更多相关文章
- 大数据入门第十四天——Hbase详解(二)基本概念与命令、javaAPI
一.hbase数据模型 完整的官方文档的翻译,参考:https://www.cnblogs.com/simple-focus/p/6198329.html 1.rowkey 与nosql数据库们一样, ...
- 大数据入门第十四天——Hbase详解(三)hbase基本原理与MR操作Hbase
一.基本原理 1.hbase的位置 上图描述了Hadoop 2.0生态系统中的各层结构.其中HBase位于结构化存储层,HDFS为HBase提供了高可靠性的底层存储支持, MapReduce为HBas ...
- 大数据入门第十五天——HBase整合:云笔记项目
一.功能简述 1.笔记本管理(增删改) 2.笔记管理 3.共享笔记查询功能 4.回收站 效果预览: 二.库表设计 1.设计理念 将云笔记信息分别存储在redis和hbase中. redis(缓存):存 ...
- 图解大数据 | 海量数据库查询-Hive与HBase详解
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/84 本文地址:http://www.showmeai.tech/article-det ...
- 大数据入门第十九天——推荐系统与mahout(一)入门与概述
一.推荐系统概述 为了解决信息过载和用户无明确需求的问题,找到用户感兴趣的物品,才有了个性化推荐系统.其实,解决信息过载的问题,代表性的解决方案是分类目录和搜索引擎,如hao123,电商首页的分类目录 ...
- 大数据入门第十六天——流式计算之storm详解(一)入门与集群安装
一.概述 今天起就正式进入了流式计算.这里先解释一下流式计算的概念 离线计算 离线计算:批量获取数据.批量传输数据.周期性批量计算数据.数据展示 代表技术:Sqoop批量导入数据.HDFS批量存储数据 ...
- 大数据入门第十天——hadoop高可用HA
一.HA概述 1.引言 正式引入HA机制是从hadoop2.0开始,之前的版本中没有HA机制 2.运行机制 实现高可用最关键的是消除单点故障 hadoop-ha严格来说应该分成各个组件的HA机制——H ...
- 大数据入门第十六天——流式计算之storm详解(三)集群相关进阶
一.集群提交任务流程分析 1.集群提交操作 参考:https://www.jianshu.com/p/6783f1ec2da0 2.任务分配与启动流程 参考:https://www.cnblogs.c ...
- 大数据笔记(十四)——HBase的过滤器与Mapreduce
一. HBase过滤器 1.列值过滤器 2.列名前缀过滤器 3.多个列名前缀过滤器 4.行键过滤器5.组合过滤器 package demo; import javax.swing.RowFilter; ...
随机推荐
- struts2、ajax实现前后端交互
跳过struts2环境搭建部分,或者可以看我的博客(http://www.cnblogs.com/zhangky/p/8436472.html),里面有写,很详细. 需要导入的jar包(struts官 ...
- OSGI企业应用开发(十)整合Spring和Mybatis框架(三)
上篇文章中,我们已经完成了OSGI应用中Spring和Mybatis框架的整合,本文就来介绍一下,如何在其他Bundle中,使用Mybatis框架来操作数据库. 为了方便演示,我们新建一个新的Plug ...
- SD从零开始29-30
SD从零开始29 外向交货单处理中的特殊功能 批次Batches 你可以在material handled in batches的相关详细屏幕指定一个batch(物料是否使用batches来处理标记在 ...
- Nginx的访问认证
1.设置访问认证的作用: 在实际的工作中,有时候我们会接到给网站加密的任务,就是需要有用户名和密码才能访问网站的内容,这个一般会是在企业的内部web服务上面来实现,其实也很简单就两个参数 语法: lo ...
- react native 第一次下载app的欢迎页+每次启动app的启动页设计
欢迎各位同学加入: React-Native群:397885169 大前端群:544587175 大神超多,热情无私帮助解决各种问题. 我想我写的这篇博文可以帮助到很多人,接下来要分享的东西,对app ...
- Django开发笔记(一)
Django开发笔记(一) 标签(空格分隔): Django Python 1. 创建并运行Django项目 创建开发环境 安装Django pip install django==version 执 ...
- Oracle EBS OPM reshedule batch
--reschedule_batch --created by jenrry DECLARE x_message_count NUMBER; x_message_list VARCHAR2 (2000 ...
- python自定义函数和推导
#之所以把这俩写一起,并不是因为这俩有什么关系,因为都太简单,没什么可说的 #自定义函数的格式,def开头,后面空格,在后面是函数名,接括号,括号里是入参参数 #!/usr/bin/python # ...
- tali -f 和 tail -F 之间的区别
tail -f 等同于--follow=descriptor,根据文件描述符进行追踪,当文件改名或被删除,追踪停止 tail -F 等同于--follow=name --retry ...
- ZooKeeper 分布式协调服务介绍
0. 说明 从自己的独立博客迁移,该部分为 Zookeeper分布式协调服务介绍 原文链接 ZooKeeper 指南 1. ZooKeeper 简介 [官方介绍] ZooKeeper 是一种集中式服 ...