spring boot springmvc视图
pring boot 在springmvc的视图解析器方面就默认集成了ContentNegotiatingViewResolver和BeanNameViewResolver,在视图引擎上就已经集成自动配置的模版引擎,如下:
1. FreeMarker
2. Groovy
3. Thymeleaf
4. Velocity (deprecated in 1.4)
6. Mustache
JSP技术spring boot 官方是不推荐的,原因有三:
1. 在tomcat上,jsp不能在嵌套的tomcat容器解析即不能在打包成可执行的jar的情况下解析
2. Jetty 嵌套的容器不支持jsp
3. Undertow
而其他的模版引擎spring boot 都支持,并默认会到classpath的templates里面查找模版引擎,这里假如我们使用freemarker模版引擎
1.现在pom.xml启动freemarker模版引擎视图
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-freemarker</artifactId>
</dependency>2.定义一个模版后缀是ftp,注意是在classpath的templates目录下
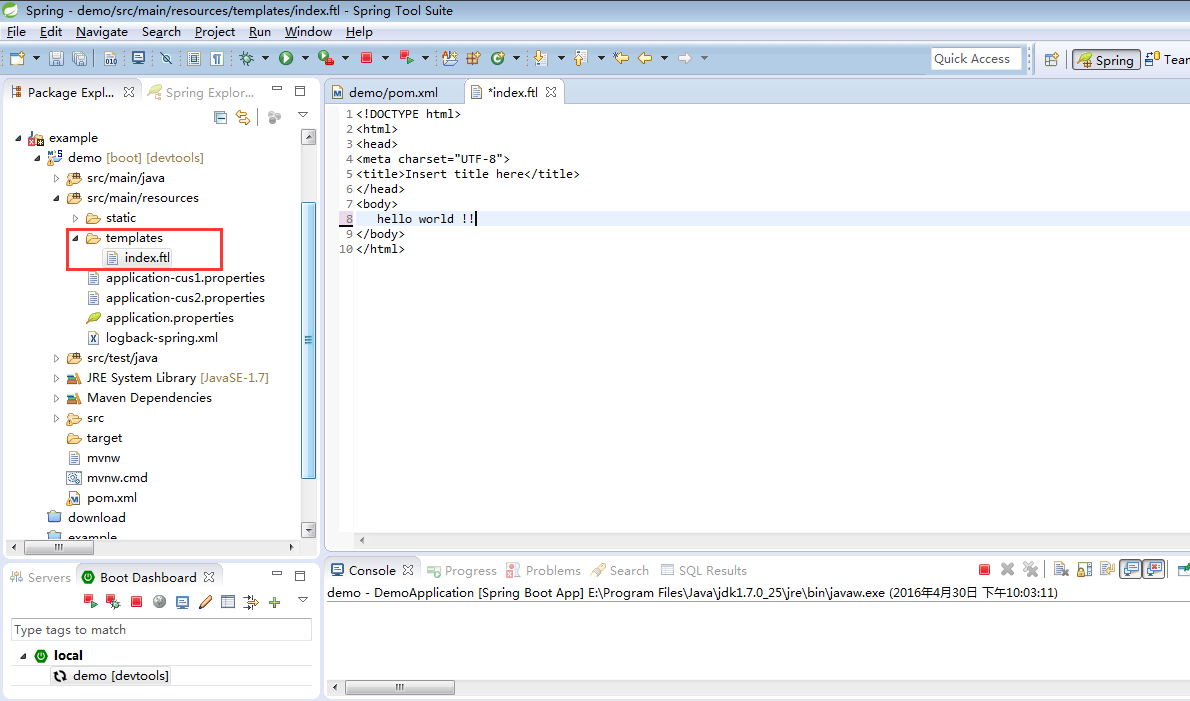
3.在controller上返回视图路径
@RestController
@RequestMapping("/task")
public class TaskController {
@RequestMapping("/mvc1")
public ModelAndView mvc1() {
return new ModelAndView("index");
}
}@RestController默认就会在每个方法上加上@Responsebody,方法返回值会直接被httpmessageconverter转化,如果想直接返回视图,需要直接指定modelAndView。
虽然,jsp技术,spring boot 官方不推荐,但考虑到是常用的技术,这里也来集成下jsp技术
1.首先,需要在你项目上加上webapp标准的web项目文件夹
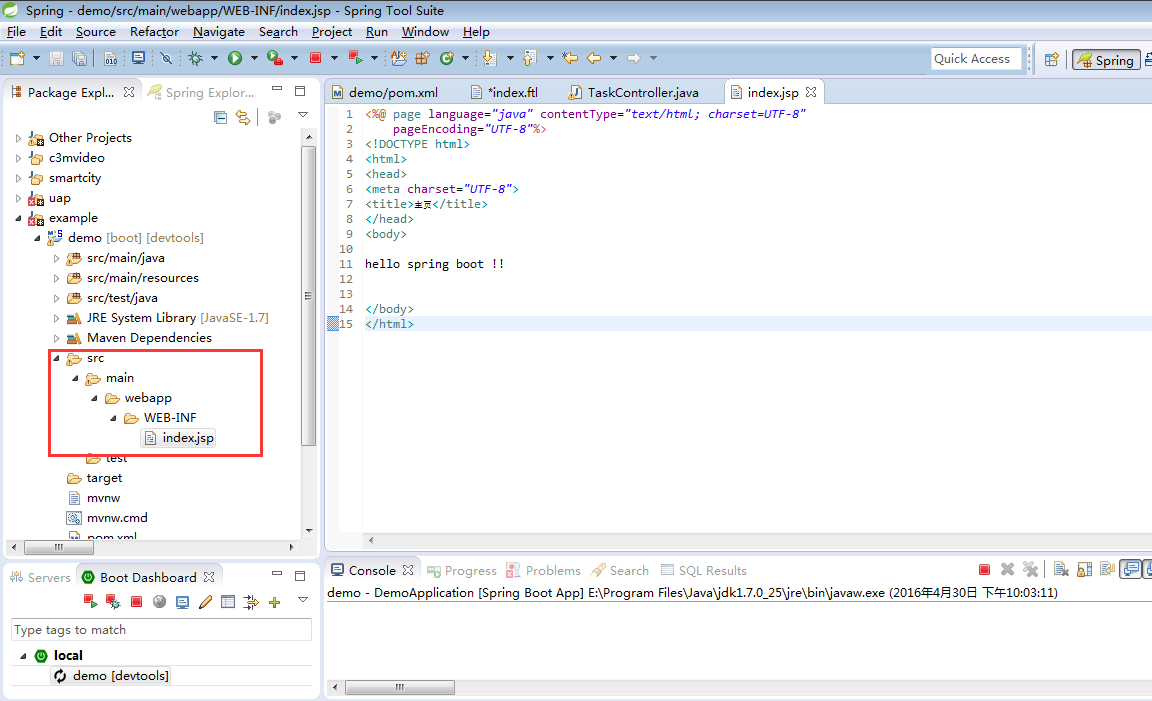
2.在配置文件上配置,jsp的前缀和后缀
spring.mvc.view.prefix=/WEB-INF/
spring.mvc.view.suffix=.jsp
3.然后直接在controller中返回视图
@RestController
@RequestMapping("/task")
public class TaskController {
@RequestMapping("/mvc1")
public ModelAndView mvc1() {
return new ModelAndView("index");
}
}这里要注意,只能是打成war包在非嵌套的tomcat容器才能看到效果,直接在嵌套的tomcat容器是看不到效果的,因为不支持,例如在IDE直接右键run main函数或者打成可执行的jar包都不行。
例外,如果出现freemarker模版引擎和jsp技术同时存在的话,springmvc会根据解析器的优先级来返回具体的视图,默认,FreeMarkerViewResolver的优先级大于InternalResourceViewResolver的优先级,所以同时存在的话,会返回freemarker视图
spring boot springmvc视图的更多相关文章
- Spring Boot 整合视图层技术,application全局配置文件
目录 Spring Boot 整合视图层技术 Spring Boot 整合jsp Spring Boot 整合freemarker Spring Boot 整合视图层技术 Spring Boot 整合 ...
- spring boot springMVC扩展配置 。WebMvcConfigurer ,WebMvcConfigurerAdapter
摘要: 在spring boot中 MVC这部分也有默认自动配置,也就是说我们不用做任何配置,那么也是OK的,这个配置类就是 WebMvcAutoConfiguration,但是也时候我们想设置自己的 ...
- Spring Boot 整合视图层技术
这一节我们主要学习如何整合视图层技术: Jsp Freemarker Thymeleaf 在之前的案例中,我们都是通过 @RestController 来处理请求,所以返回的内容为json对象.那么如 ...
- spring boot 1.视图解析器,2.开启静态资源访问
1.spring boot 视图解析器 #视图解析器 #前缀spring.mvc.view.prefix=/pages/ #后缀..jsp.dospring.mvc.view.suffix=.jsp ...
- spring cloud + spring boot + springmvc+mybatis分布式微服务云架构
做一个微服务架构需要的技术整理: View: H5.Vue.js.Spring Tag.React.angularJs Spring Boot/Spring Cloud:Zuul.Ribbon.Fei ...
- spring boot 使用视图modelandview
1:springboot使用视图解析器,添加依赖 <!-- freemarker模板引擎视图 --> <dependency> <groupId>org.sprin ...
- spring boot 自定义视图路径
boot 自定义访问视图路径 . 配置文件 目录结构 启动类: html页面 访问: 覆盖boot默认路径引用. 如果没有重新配置,则在pom引用模板. 修改配置文件. 注意一定要编译工程
- Spring Boot实践——SpringMVC视图解析
一.注解说明 在spring-boot+spring mvc 的项目中,有些时候我们需要自己配置一些项目的设置,就会涉及到这三个,那么,他们之间有什么关系呢? 首先,@EnableWebMvc=Web ...
- spring boot配置springMVC拦截器
spring boot通过配置springMVC拦截器 配置拦截器比较简单, spring boot配置拦截器, 重写preHandle方法. 1.配置拦截器: 2重写方法 这样就实现了拦截器. 其中 ...
随机推荐
- ES6入门声明
let.var区别点 1.let只在命令所在的代码块中有效. 2.变量一定要先声明在使用,否则会报错,不存在Es5的变量提升(暂时性死区,不存在重复使用). 3.块级作用域中存在let命令,所声明的变 ...
- Exchange重启脚本
Much more from the source article itself ...... details or code stated above http://therealshrimp.bl ...
- 增删改查列表angular.js页面实现
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <meta http ...
- Ubuntu的常用快捷键(摘自网络)
篇一 : Ubuntu的复制粘贴操作及常用快捷键(摘自网络) Ubuntu的复制粘贴操作 1.最为简单,最为常用的应该是鼠标右键操作了,可以选中文件,字符等,右键鼠标,复制,到目的地右键鼠标,粘贴就结 ...
- nginx 服务器常见配置以及负载均衡
# 配置启动用户,用户权限不够会出现访问 403 的情况 user root; # 启动多少个工作进程 worker_processes 1; # 错误日志文件进程文件的保存地址 error_log ...
- HTML学习-1网页基础知识
HTML超文本标记语言:HyperText Markup Language. 由浏览器运行解析. 它包括了静态页面.html .htm.动态页面.php .aspx .jsp,从数据库提取. 今天 ...
- day06-单表查询
1.单表查询的语法 SELECT 字段1,字段2... FROM 表名 WHERE 条件 GROUP BY field HAVING 筛选 ORDER BY field LIMIT 限制条数 2.关键 ...
- linux MYSQL大小写问题处理
1)window下默认大小写不敏感,所以在window下.创建表 test后再想创建表TEST会报错.而linux下默认可以.认为是不同的两张表 2)linux创建数据库,安装完毕后 首要任务是在li ...
- BroadcastReceiver的使用,动态注册和注销,优先级和中断控制
BroadcastReceiver: BroadcastReceiver(广播接收器)是Android中的四大组件之一,用来通知某些事件的相关信息,如下载完成,设置改变等. 默认的BroadcastR ...
- Java读写hdfs上的avro文件
1.通过Java往hdfs写avro文件 import java.io.File; import java.io.IOException; import java.io.OutputStream; i ...