用R理解统计学
1、随机变量( random variable)概念的引入
该数据来自杰克逊实验室。2组数据,每组12只老鼠,一组普通食物,另一组高脂肪(hf)饮食。几周后,科学家们称了每只老鼠的体重,得到了这个数据:
dir <- "https://raw.githubusercontent.com/genomicsclass/dagdata/master/inst/extdata/"
filename <- "femaleMiceWeights.csv"
url <- paste0(dir, filename)
dat <- read.csv(url)
library(dplyr)
control <- filter(dat,Diet=="chow") %>% select(Bodyweight) %>% unlist #其中%>%相当于管道符,fileter相当于Excel中按关键词行筛选,select为列筛选,只保留你提到的变量
treatment <- filter(dat,Diet=="hf") %>% select(Bodyweight) %>% unlist
print(mean(treatment))
print(mean(control) )
obsdiff <- mean(treatment) - mean(control) #3.020833
print(obsdiff)
因此,食用hf的小鼠体重增加了10%我们做了什么?为什么我们需要p值和置信区间?原因是这些平均值是随机变量。它们可以取很多值。如果我们重复这个实验,我们从杰克逊实验室得到24只新老鼠,然后随机分配给每一种食物,我们得到不同的平均值。每次我们重复这个实验,我们得到不同的值。我们称之为随机变量。
2、理解随机变量( random variable)
population <- read.csv('https://raw.githubusercontent.com/genomicsclass/dagdata/master/inst/extdata/femaleControlsPopulation.csv')
str(population)
population <- unlist(population)
control <- sample(population,12)
mean(control)
control <- sample(population,12)
mean(control)
control <- sample(population,12)
mean(control)
可以看到每次抽样12只,平均体重是有差别的。
3、 The Null Hypothesis
现在让我们回到obsdiff的平均差异。作为怀疑论者,我们怎么知道这种强迫症是由饮食引起的呢?如果我们给24只老鼠同样的食物会发生什么?我们会看到这么大的不同吗?统计学家将这种情况称为零假设。“null”这个名字是用来提醒我们,我们在扮演怀疑论者的角色:我们相信没有区别的可能性。因为我们有群体( population),我们可以随机从群体中抽取24只老鼠,给以同样的食物,然后将24只老鼠随机分配两组,来观察这两组的平均值。
Because we have access to the population, we can actually observe as many values as we want of the difference of the averages when the diet has no effect. We can do this by randomly sampling 24 control mice, giving them the same diet, and then recording the difference in mean between two randomly split groups of 12 and 12. Here is this process written in R code:
control <- sample(population,12)
treatment <- sample(population,12)
print(mean(treatment) - mean(control)) #注意每次结果会不一样,因为是随机抽取的
现在我们用for循环随机抽取10000次。
n <- 10000
null <- vector("numeric",n)
for (i in 1:n) { control <- sample(population,12)
treatment <- sample(population,12)
null[i] <- mean(treatment) - mean(control) }
mean(null >= obsdiff) ##0.0138
The values in null form what we call the null distribution.So what percent of the 10,000 are bigger than obsdiff?
在10000次模拟中,只有很小的一部分。作为怀疑论者,我们的结论是什么?在没有饮食影响的情况下,这里随机抽样10000次和我们在实验中观察到的差异(框1)只有1.5%,这就是所谓的p值,即这1.5%的差异是随机(偶然)产生的,该值越小,说明实验值与对照值差别越大,处理效果越明显(p越小,越拒绝零 假设);该值越大说明实验值与对照值差异是偶然因素造成的,越接受零假设。我们将在本书后面更正式地定义它。
Only a small percent of the 10,000 simulations. As skeptics what do we conclude? When there is no diet effect, we see a difference as big as the one we observed only 1.5% of the time. This is what is known as a p-value
4、distribution
我们已经解释了零假设中零的含义,但分布到底是什么呢?考虑分布最简单的方法是用许多数字的紧凑描述。例如,假设你测量了一个总体中所有人的身高。想象一下,你需要向一个不知道这些高度的人描述这些数字,比如一个从未去过地球的外星人。假设所有这些高度都包含在下面的数据集中,总结这些数字的一种方法是简单地把它们列出来让外星人看:
data(father.son,package="UsingR")
x <- father.son$fheight
round(sample(x,10),1)
5、Cumulative Distribution Function(累积分布函数)
通过浏览这些数字,我们开始大致了解整个列表的样子,但它肯定是低效的。我们可以通过定义和可视化分布来快速改进这种方法。为了定义一个分布,我们对a的所有可能值,计算列表中低于a的数字的比例。我们使用以下符号:
F(a) =Pr(x ≤ a)
这称为累积分布函数(cumulative distribution function ,CDF)。当CDF来自于数据时,与理论相对,我们也称它为经验CDF (ECDF)。

6、Histograms
虽然实证的CDF概念在统计教科书中得到了广泛的讨论,但在实际操作中却并不十分流行。原因是直方图给了我们相同的信息,而且更容易解释。直方图告诉我们值在区间中的比例:
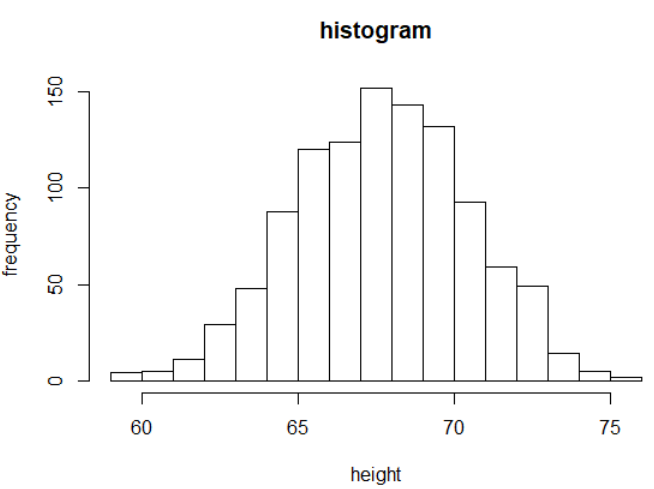
Pr(a ≤ x ≤ b) = F (b) − F (a)。把这些高度用柱状图表示就是我们所说的直方图。这是一个更有用的图,因为我们通常更感兴趣的是区间,在70到71英寸之间的这个百分比,而不是小于特定高度的那个百分比。通过直方图也更容易区分分布的不同类型(族)。这是高度的直方图:
hist(x,xlab='height',ylab = 'frequency',main='histogram')
我们可以通过以下方式来指定区间(bin)和添加更好的标签:
smallest=min(x)
largest=max(x)
bins <- seq(smallest, largest+1)
hist(x,breaks=bins,xlab="Height (in inches)",main="Adult men heights")
向外星人展示这个情节比展示数字更有信息。用这个简单的图,我们可以近似出任意给定区间内的个体数量。例如,大约有70个人身高超过6英尺(72英寸)。
7、Probability Distribution
另外一个重要的概念是概率分布,我们不是描述比例,而是描述概率。例如,如果我们从列表中随机选择一个高度,那么它落在a和b之间的概率表示为:

注意,现在将X大写,以区分它是一个随机变量,上面的方程定义了随机变量的概率分布。知道这个分布在科学上非常有用。例如,在上面的例子中,如果我们知道零假设为真时小鼠体重均值差的分布,也就是零分布(null distribution),我们就可以计算出观察到一个和我们之前实验处理组得到的一样大的值的概率,也就是p值。
Knowing this distribution is incredibly useful in science. For example, in the case above, if we know the distribution of the difference in mean of mouse weights when the null hypothesis is true,referred to as the null distribution, we can compute the probability of observing a value as large as we did, referred to as a p-value.
让我们重复上面的循环,但这次让我们在每次重新运行实验时向图中添加一个点。在上一部分中,我们运行了所谓的MonteCarlo模拟(我们将在后面的章节中提供更多关于蒙特卡罗模拟的细节),在零假设下我们得到了10,000个随机变量的结果。如果您运行这段代码,您可以看到null分布的形成是由于所观察到的值堆叠在一起。
data(father.son,package="UsingR")
x <- father.son$fheight
n <- 100
population <- read.csv('https://raw.githubusercontent.com/genomicsclass/dagdata/master/inst/extdata/femaleControlsPopulation.csv')
library(rafalib)
nullplot(-5,5,1,30, xlab="Observed differences (grams)", ylab="Frequency")
totals <- vector("numeric",11) for (i in 1:n) {
control <- sample(population,12)
treatment <- sample(population,12)
nulldiff <- mean(treatment) - mean(control)
j <- pmax(pmin(round(nulldiff)+6,11),1)
totals[j] <- totals[j]+1
text(j-6,totals[j],pch=15,round(nulldiff,1))
##if(i < 15) Sys.sleep(1) ##You can add this line to see values appear slowly
}
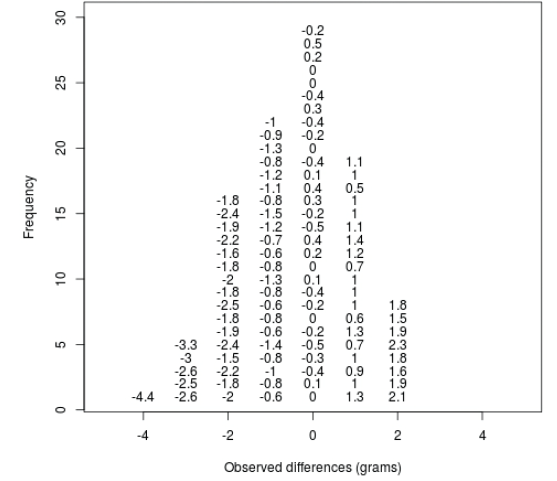
上图相当于直方图。从我们之前计算的null vector的直方图中,我们可以看到obsdiff这样大的值是比较少见的。这里需要记住的重要一点是,当我们通过计算案例来定义Pr(a)时,我们会学到,在某些情况下,数学给了我们Pr(a)的公式,省去了我们计算它们的麻烦。这种强大方法的一个例子使用了正态分布近似。
8、正态分布
我们上面看到的概率分布近似于自然界中很常见的一种:钟形曲线,也称为正态分布或高斯分布。当一组数字的直方图近似于正态分布时,我们可以使用一个方便的数学公式来近似任意给定区间内的值或结果的比例:
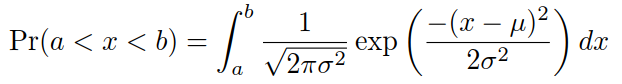
虽然公式看起来吓人,别担心,你将永远不会记忆,因为它是存储在一个更方便的形式(如pnorm R,设置a为−∞,并以b作为参数)。这里µ和σ被称为人口的平均值和标准偏差。如果这个正态逼近适用于我们的列表,那么列表的总体均值和方差可以用在上面的公式中。
一个例子是,当我们在上面注意到null 分布中上只有1.5%的null分布值在obsdiff之上。
总结,计算老鼠饮食差异的p值很简单,对吧?但为什么我们还没有完成呢?为了进行计算,我们从Jackson实验室购买了所有可用的小鼠,并重复执行我们的实验来定义零分布。然而,这不是我们在实践中可以做到的。统计推理是一种数学理论,它允许你仅用样本中的数据(即最初的24只老鼠)来近似这个结果。我们将在下面的部分中重点讨论这个问题。
9、Setting the random seed
在继续之前,我们简要解释一下以下重要的代码行:
set.seed(1)
在本书中,我们使用随机数生成器。这意味着,所给出的许多结果实际上可以随机更改,包括问题的正确答案。确保结果不变的一种方法是设置R的随机数生成种子。
练习random seed
dir <- "https://raw.githubusercontent.com/genomicsclass/dagdata/master/inst/extdata/"
filename <- "femaleControlsPopulation.csv"
url <- paste0(dir, filename)
x <- unlist(read.csv(url))
这里x代表整个总体的权重。
10、Populations, Samples and Estimates
现在我们已经介绍了随机变量、零分布和p值的概念,现在我们准备描述允许我们在实践中计算p值的数学理论。我们还将学习置信区间和功率计算。
总体参数:
统计推断的第一步是了解你感兴趣的是什么。在小鼠体重的例子中,我们有两个种群:控制饮食的雌鼠和高脂肪饮食的雌鼠,体重是感兴趣的结果。我们认为这个总体是固定的,随机性来自于抽样。我们使用这个数据集作为示例的一个原因是,我们碰巧拥有这种类型的所有鼠标的权重。
dir <- "https://raw.githubusercontent.com/genomicsclass/dagdata/master/inst/extdata/"
filename <- "mice_pheno.csv"
url <- paste0(dir, filename)
dat <- read.csv(url)
library(dplyr)
controlPopulation <- filter(dat,Sex == "F" & Diet == "chow") %>% select(Bodyweight) %>% unlist
hfPopulation <- filter(dat,Sex == "F" & Diet == "hf") %>% select(Bodyweight) %>% unlist
library(rafalib)
mypar(1,2)
hist(hfPopulation)
hist(controlPopulation)
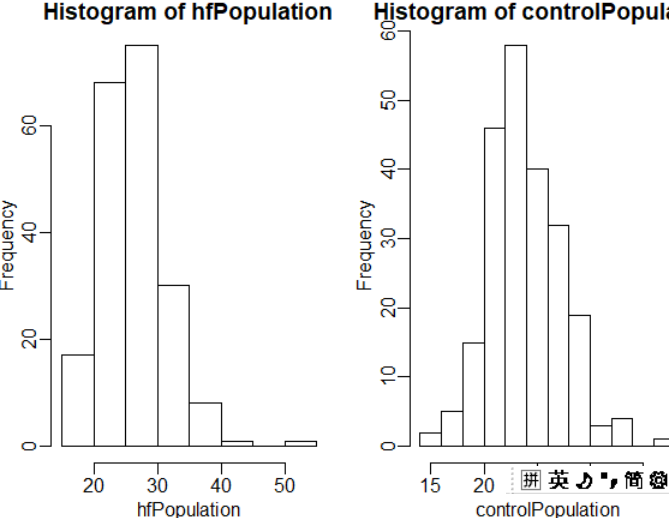
我们可以用q-plot图来证明分布是相对接近于非均匀分布的。后面将详细讨论,重要的是要知道它比较(y轴上的)数据和(x轴上的)理论分布。如果点落在恒等线上,则数据接近理论分布。
mypar(1,2)
qqnorm(hfPopulation)
qqline(hfPopulation)
qqnorm(controlPopulation)
qqline(controlPopulation)

两个种群所有权重的分位数-分位数图。
样本量越大,对这种近似的缺点就越宽容。在下一节中,我们将看到对于这个特定的数据集,t分布甚至对于小到3的样本容量也能很好地工作。
如果一组数的分布近似正态分布,那么随机抽取一个数,它就会服从正态分布。If the distribution of a list of numbers is approximately normal, then if we pick a number at random from this distribution, it will follow a normal distribution.
dir <- "https://raw.githubusercontent.com/genomicsclass/dagdata/master/inst/extdata/"
filename <- "mice_pheno.csv"
url <- paste0(dir, filename)
##The data has missing values.
##We remove them with the na.omit function
dat <- na.omit( read.csv(url))
y <- filter(dat, Sex=="M" & Diet=="chow") %>% select(Bodyweight) %>% unlist
avgs <- replicate(10000, mean( sample(y, 25)))
mypar(1,2)
hist(avgs)
qqnorm(avgs)
qqline(avgs)
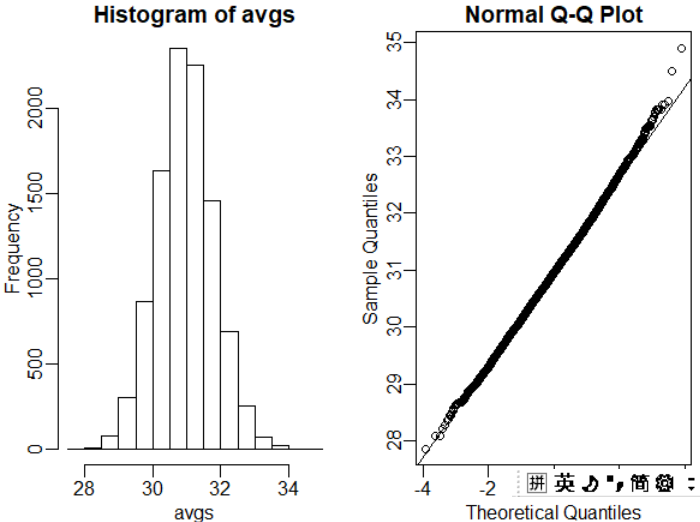
11、实践中的中心极限定理
用R理解统计学的更多相关文章
- 用R进行统计学分析
1.基本统计 summary函数:R中的summary函数根据输入的类提供输入的摘要.该函数根据输入对象的类调用各种函数.返回值也取决于输入对象.例如,如果输入是一个由数字数据组成的向量,它将为数据提 ...
- 机器学习与R语言
此书网上有英文电子版:Machine Learning with R - Second Edition [eBook].pdf(附带源码) 评价本书:入门级的好书,介绍了多种机器学习方法,全部用R相关 ...
- 普通程序员转型AI免费教程整合,零基础也可自学
普通程序员转型AI免费教程整合,零基础也可自学 本文告诉通过什么样的顺序进行学习以及在哪儿可以找到他们.可以通过自学的方式掌握机器学习科学家的基础技能,并在论文.工作甚至日常生活中快速应用. 可以先看 ...
- matplotlib basic and boxplot
============================================matplotlib 绘图基础========================================= ...
- postgresql 函数&存储过程 ; 递归查询
函数:http://my.oschina.net/Kenyon/blog/108303 紧接上述,补充一下: 输入/输出参数的函数demo(输入作为变量影响sql结果,输出作为结果返回) create ...
- SPSS-相关分析
相关分析(二元定距变量的相关分析.二元定序变量的相关分析.偏相关分析和距离相关分析) 定义:衡量事物之间,或称变量之间线性关系相关程度的强弱并用适当的统计指标表示出来,这个过程就是相关分析 变量之间的 ...
- Mmseg中文分词算法解析
Mmseg中文分词算法解析 @author linjiexing 开发中文搜索和中文词库语义自己主动识别的时候,我採用都是基于mmseg中文分词算法开发的Jcseg开源project.使用场景涉及搜索 ...
- 转:以下是目前已经建立的sub一览 来自:https://zhuanlan.zhihu.com/p/91935757
转:以下是目前已经建立的sub一览 来自:https://zhuanlan.zhihu.com/p/91935757 作者: Lorgar 理工科 科学(和英文r/science一样,只接受论文讨论 ...
- 倍增小结 ST 与 LCA
倍增 倍增我是真滴不会 倍增法(英语:binary lifting),顾名思义就是翻倍. 能够使线性的处理转化为对数级的处理,大大地优化时间复杂度. (ps:上次学倍增LCA,没学会,老老实实为了严格 ...
随机推荐
- python学习之----BeautifulSoup示例二
网络爬虫可以通过class 属性的值,轻松地区分出两种不同的标签.例如,它们可以用 BeautifulSoup 抓取网页上所有的红色文字,而绿色文字一个都不抓.因为CSS 通过属性准 确地呈现网站的样 ...
- Running a jupyter notebook server
你也许需要服务器运行jupyter notebook 阿里云: https://yq.aliyun.com/articles/98527 关于更安全的证书访问: http://jupyter-note ...
- 写了一个bug----使用已经被删除的内存
#include <iostream> #include <stdio.h> #include <memory.h> using namespace std; ; ...
- 《算法》第一章部分程序 part 2
▶ 书中第一章部分程序,加上自己补充的代码,包括简单的计时器,链表背包迭代器,表达式计算相关 ● 简单的计时器,分别记录墙上时间和 CPU 时间. package package01; import ...
- apt-get 使用指南
# apt-get update——在修改/etc/apt/sources.list或者/etc/apt/preferences之後运行该命令.此外您需要定期运行这一命令以确保您的软件包列表是最新的. ...
- python中的get
get()根据键获取字典中的值,如果键不存在则返回一个默认值,默认值不填写则返回None 1 a = { 2 "name":"dlrb", 3 "ag ...
- IIS编辑器错误信息:CS0016解决方案
错误信息: 运行asp.net程序时候,编译器错误消息: CS0016: 未能写入输出文件“c:\Windows\Microsoft.NET\Framework\v2.0.50727\Temporar ...
- Ubuntu系统tensorflow安装问题及解决
su root ps:如果你没有改过root密码,sudo passwd 然后输入你的账户密码,然后设置你的root密码 在root权限下执行pip install --upgrade pip 更 ...
- chattr 改变文件、目录属性 (chmod、passwd等涉及文件修改的命令提示Operation not permitted)
与chmod这个命令相比,chmod只是改变文件的读写.执行权限,更底层的属性控制是由chattr来改变的. lsattr查看文件或目录属性 chattr命令的用法:chattr [ -RVf ] [ ...
- math模块
序号 方法 功能 示例 1 matd.ceil 取大于等于x的最小的整数值,如果x是一个整数,则返回x print(matd.ceil(10.1))# 11print(matd.ceil(-3.1)) ...