php页面编码与字符操作
<meta http-equiv="content-type" content="text/html; charset=编码类型">
1 header("content-type:text/html; charset=编码类型");
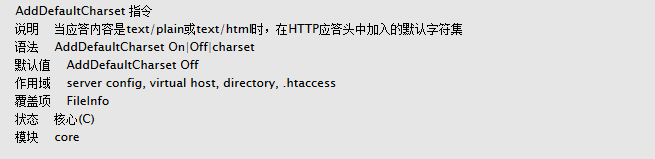
1:如果页面没有指定编码 , Apache配置defaultcharset gbk , 页面文件编码是utf-8。
页面显示是乱码。在页面没有meta指明charset,设置defaultcharset gbk,这个时候服务器的设置生效,编码不一致,造成乱码;
2:如果页面指定编码为utf-8, Apache配置defaultcharset gbk. 页面文件编码是utf-8。
页面显示乱码。设置defaultcharset gbk,会覆盖页面级别(meta)的编码设置;
3:如果页面header申明charset为utf8, Apache配置defaultcharst gbk,页面文件编码是utf8。
页面显示正常。这个说明header优先级要高于服务器和浏览器的设置;
4:如果Apache关闭DefaultCharset 。
页面显示正常。
$string = "赵亚飞";
$encode = mb_detect_encoding($string, array("ASCII","UTF-8","GB2312","GBK","BIG5"));
header("content-Type: text/html; charset=".$encode);
echo $string;
有时会出现检查错误(解决办法)例如:对与GB2312和UTF- 8,或者UTF-8和GBK网上说是由于字符短是,mb_detect_encoding会出现误判。 不是bug,写程序时也不应当过于依赖mb_detect_encoding,当字符串较短时,检测结果产生偏差的可能性很大。
三个参数分别是:被检测的输入变量、编码方式的检测顺序(如果为真,后面自动忽略)、strict模式
对编码检测的顺序进行调整,将最大可能性放在前面,这样减少被错误转换的机会。 一般要先排gb2312,当有GBK和UTF-8时,需要将常用的排列到前面。
例如:
1: 将任意类型( 'ASCII,GB2312,GBK,UTF-8')字符串$html_str转换成'UTF-8'编码
$html_str = mb_convert_encoding($html_str, 'UTF-8', 'ASCII,GB2312,GBK,UTF-8');
2:gbk To utf-8
< ?php
header("content-Type: text/html; charset=Utf-8");
echo mb_convert_encoding("赵亚飞", "UTF-8", "GBK");
?>
注意:使用上面的函数需要安装但是需要先enable mbstring 扩展库。 在 php.ini里将; extension=php_mbstring.dll 前面的 ; 去掉
iconv("UTF-8","GB2312//IGNORE",$data)
function check_encod($encod,$string){
//判断字符编码
$encode = mb_detect_encoding($string, array("ASCII","UTF-8","GB2312","GBK","BIG5"));
var_dump($encode);
if($encode != $encod){
$string = iconv($encode, $encod, $string);
}
return $string;
}
$path = "赵亚飞。.jpg";
$path = check_encod("GB2312",$path);
echo mb_substr('赵亚飞赵亚飞er',0,9); //输出:赵亚飞
echo mb_substr('赵亚飞赵亚飞er',0,9,'utf-8'); //输出:赵亚飞赵亚飞er
第一个是以三个字节为一个中文,这就是utf-8编码的特点,下面加上utf-8字符集说明,是以一个字为单位来截取的
Substr是截取字符的函数,但是很多时候,截取中文却需要额外处理,原因是中文在UTF-8中占用3个字节,在GB2312中占用2个字节,在截取中随时存在截取的字符串长度与组成未知,所以给很多人造成了困扰。PHP5开始,iconv_substr函数出现
<?php
$str='赵z亚y飞f/include';
echo substr($str,1,5);
echo "<br>";
echo iconv_substr($str,1,5,"UTF-8");
?>
这个是在网页编码为UTF-8的PHP代码中使用的截取编码。如果在UTF-8网页中使用GB2312或者GBK编码来截取,会出错,占用字节不同;反之,在GB2312或GBK网页中,不能使用UTF-8来进行截取 。由于iconv_substr是按照字符而非占用字节来计算,所以“a”和“叶”均计算为1位。在GB2312或者GBK中,由于占用字节是一样的,所以可以随意使用GB2312或GBK编码来截取,截取结果是一样的。
3:兼容性良好的截取字符串的函数
1 /**
* 截取字符串兼容各种编码
*
* @param string $str
* @param int $start //开始截取位置默认是0
* @param int $length //截取长度
* @param string $charset //字符编码
* @param int $is_addnode //是否加省略号
* @return string
**/
public static function cut_string($str, $start=0, $length, $charset="", $is_addnode=true){
if(empty($str) || $str == ''){
return $str;
}
$real_set = mb_detect_encoding($str, array("UTF-8", "ASCII", "GB2312", "GBK", "BIG5"));
if(empty($charset)){
//没有传编码就按本身编码;
$charset = $real_set;
if(empty($charset)){
$charset = 'utf-8';
}
}else{
if($real_set != $charset){
//如果编码不一致就设置为传入的编码,防止截取乱码
$str = iconv($real_set, $charset, $str);
}
} //兼容没有安装扩展的情况
if(function_exists("mb_substr")){
$cut_str = mb_substr($str, $start, $length, $charset);
}elseif(function_exists('iconv_substr')) {
$cut_str = iconv_substr($str, $start, $length, $charset);
}
if($is_addnode){
if($str == $cut_str){
return $cut_str;
}else{
return $cut_str . "......";
}
}else{
return $cut_str;
}
//兼容正则截取
$preg['utf-8'] = "/[\x01-\x7f]|[\xc2-\xdf][\x80-\xbf]|[\xe0-\xef][\x80-\xbf]{2}|[\xf0-\xff][\x80-\xbf]{3}/";
$preg['gb2312'] = "/[\x01-\x7f]|[\xb0-\xf7][\xa0-\xfe]/";
$preg['gbk'] = "/[\x01-\x7f]|[\x81-\xfe][\x40-\xfe]/";
$preg['big5'] = "/[\x01-\x7f]|[\x81-\xfe]([\x40-\x7e]|\xa1-\xfe])/";
preg_match_all($preg[$charset], $str, $match);
$string = join("",array_slice($match[0], $start, $length));
if($is_addnode){
return $string . "......";
}
return $string;
}
php页面编码与字符操作的更多相关文章
- dedecms功能性函数封装(XSS过滤、编码、浏览器XSS hack、字符操作函数)
dedecms虽然有诸多漏洞,但不可否认确实是一个很不错的内容管理系统(cms),其他也不乏很多功能实用性的函数,以下就部分列举,持续更新,不作过多说明.使用时需部分修改,你懂的 1.XSS过滤. f ...
- day08(字符编码,字符与字节,文件操作)
一,复习 ''' 类型转换 1.数字类型:int() | bool() | float() 2.str与int: int('10') | int('-10') | int('0') | float(' ...
- Python 字符编码及其文件操作
本章节内容导航: 1.字符编码:人识别的语言与机器机器识别的语言转化的媒介. 2.字符与字节:字符占多少个字节,字符串转化 3.文件操作:操作硬盘中的一块区域:读写操作 注:浅拷贝与深拷贝 用法: d ...
- Python编程Day7——字符编码、字符与字节、文件操作
一.字符编码 重点 ***** 1. 什么是字符编码:将人识别的字符转换计算机能识别的01,转换的规则就是字符编码表2. 常用的编码表:ascii.unicode.GBK.Shift_JIS.Euc- ...
- Python之字符编码与文件操作
目录 字符编码 Python2和Python3中字符串类型的差别 文件操作 文件操作的方式 文件内光标的移动 文件修改 字符编码 什么是字符编码? ''' 字符编码就是制定的一个将人类的语言的字符与二 ...
- DAY7 字符编码和文件操作
一.软件与python解释器打开文件的方法 1.软件打开文件读取数据的流程: 1. 打开软件 2. 往计算机发生一个打开文件的指令,来打开文件 3. 读取数据渲染给用户(存取编码不一致:乱码) 2.p ...
- Day 07 字符编码,文件操作
今日内容 1.字符编码:人识别的语言与机器识别的语言转换的媒介 2.字符与字节:字符占多少字节,字符串转换 3.文件操作:操作硬盘的一块区域 字符编码 重点:什么是字符编码 人类能识别的字符等高级标识 ...
- Python 入门基础6 --字符编码、文件操作1
今日内容: 1.字符编码 2.字符与字节 3.文件操作 一.字符编码 了解: cpu:将数据渲染给用户 内存:临时存放数据,断电消失 硬盘:永久存放数据,断电后不消失 1.1 什么是编码? 人类能够识 ...
- Python基础之字符编码,文件操作流与函数
一.字符编码 1.字符编码的发展史 阶段一:现代计算机起源于美国,最早诞生也是基于英文考虑的ASCII ASCII:一个Bytes代表一个字符(英文字符/键盘上的所有其他字符),1Bytes=8bit ...
随机推荐
- js鼠标事件大全
一般事件 事件 浏览器支持 描述 onClick HTML: 2 | 3 | 3.2 | 4 Browser: IE3 | N2 | O3 鼠标点击事件,多用在某个对象控制的范围内的鼠标点击 onDb ...
- DialogFragment is gone after returning back from another activity
基本情景如下: 在DialogFragment中单击一个按钮跳转到another Activity做一些逻辑处理,然后将返回的结果回显到该DialogFragment上. 处理逻辑是: 在Dialog ...
- WIN10 CMD 启动虚拟WIFI
1.以管理员身份运行命令提示符: 快捷键win+R→输入cmd→回车 2.启用并设定虚拟WiFi网卡: 运行命令:netsh wlan set hostednetwork mode=allow ssi ...
- WPF面试准备
1.wpf中有两类模板,控件模板controltemplate和datatemplate都派生自Frameworktemplate. 总共有三大模板 ControlTemplate,ItemsPane ...
- Ubuntu下的MySQL安装
<1>安装mysql-server sudo apt-get update sudo apt-get install mysql-server mysql-client <2> ...
- Node.js入门笔记(2):全局对象(1)
以下将以API文档为基础进行分析学习 global对象 这些对象在所有模块里都可用.有些对象不是在全局作用域而是在模块作用域里,这些情况下面文档都会标注出来. __filename--返回当前模块文件 ...
- curl命令使用
curl命令可以用来构造http请求.参数有很多,常用的参数如下: 通用语法:curl [option] [URL...]在处理URL时其支持类型于SHELL的名称扩展功能,如http://www.j ...
- 进入OS前的两步之System tick
OK,继续向操作系统迈进.由简入繁,先实现两个小功能.第一个是system tick,第二个是任务切换(PendSV).一个是操作系统的心跳,一个是操作系统的并发处理的具体实现. System tic ...
- 关于session和cookie
一.cookie机制和session机制的区别 **************************************************************************** ...
- Login Reference for PhotoSomething
Android Background Processing with Handlers and AsyncTask and Loaders - Tutorial http://www.vogella. ...