暴力破解MD5的实现(MapReduce编程)
本文主要介绍MapReduce编程模型的原理和基于Hadoop的MD5暴力破解思路。
一、MapReduce的基本原理
Hadoop作为一个分布式架构的实现方案,它的核心思想包括以下几个方面:HDFS文件系统,MapReduce的编程模型以及RPC框架。无论是怎样的架构,一个系统的关键无非是存储结构和业务逻辑。HDFS分布式文件系统是整个Hadoop的基础。在HDFS文件系统之中,大文件被分割成很多的数据块,每一块都有可能分布在集群的不同节点中。也就是说在HDFS文件系统中,文件的情况是这样的:
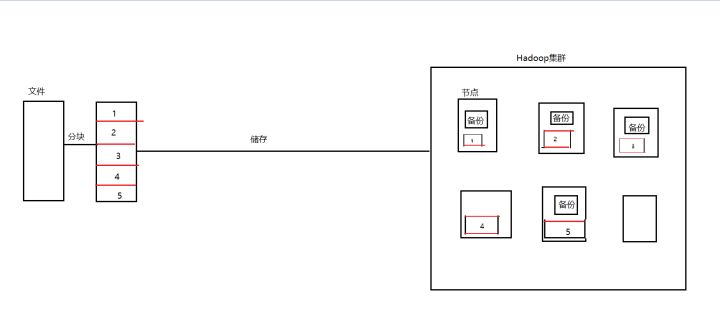
文件保存在不同的节点上,而Hadoop是用于海量数据处理的,那么如何把分布在各个节点的数据进行高效的并发处理呢?Hadoop对此提供了不同的解决方案,比如yarn框架等。框架已经帮我们写好了很多的诸如任务分配,节点通信之类的事情。而我们要做的就是写好自己的业务逻辑,那么我们就要遵守Hadoop的编程规范,而这个编程规范就是MapReduce。
那么MapReduce的运行过程是怎么样的呢?且看下图:
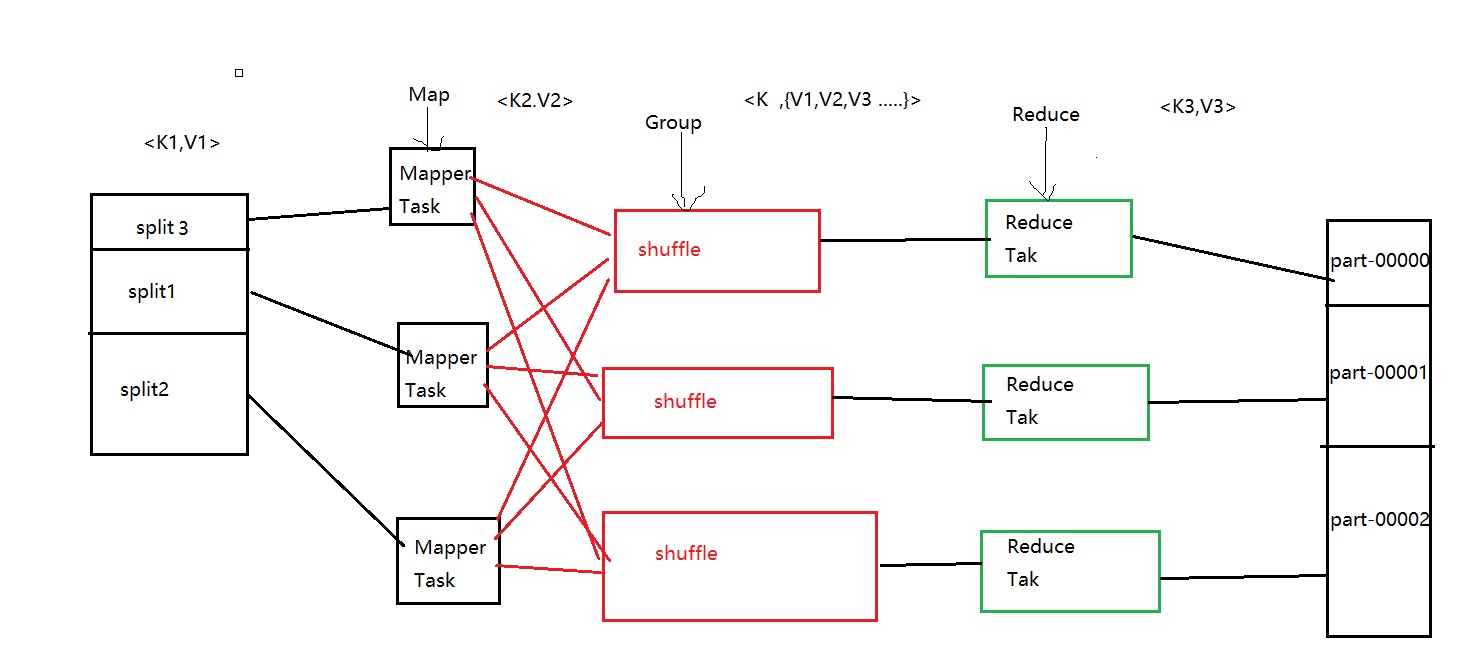
1.从HDFS文件系统中读取文件,每一个数据块对应一个MapTask。
2.进行Map任务,逐行读取文件,每一行调用一次Map函数,数据被封装为一个键值对也就是图中的<k2,v2>。
3.将Map后的键值对进行归约,key值相同的value会被封装到一起。就行了图中的<k,{v1,v2,v3}>
4.归约后的键值对会被送到不同的Reduce中,执行Reduce任务,输出<k3,v3>到输出文件中。
弄懂了MapReduce的执行过程之后,我们就可以编写自己的逻辑来进行处理了。
二、MD5暴力破解的基本思路
还是先上图:
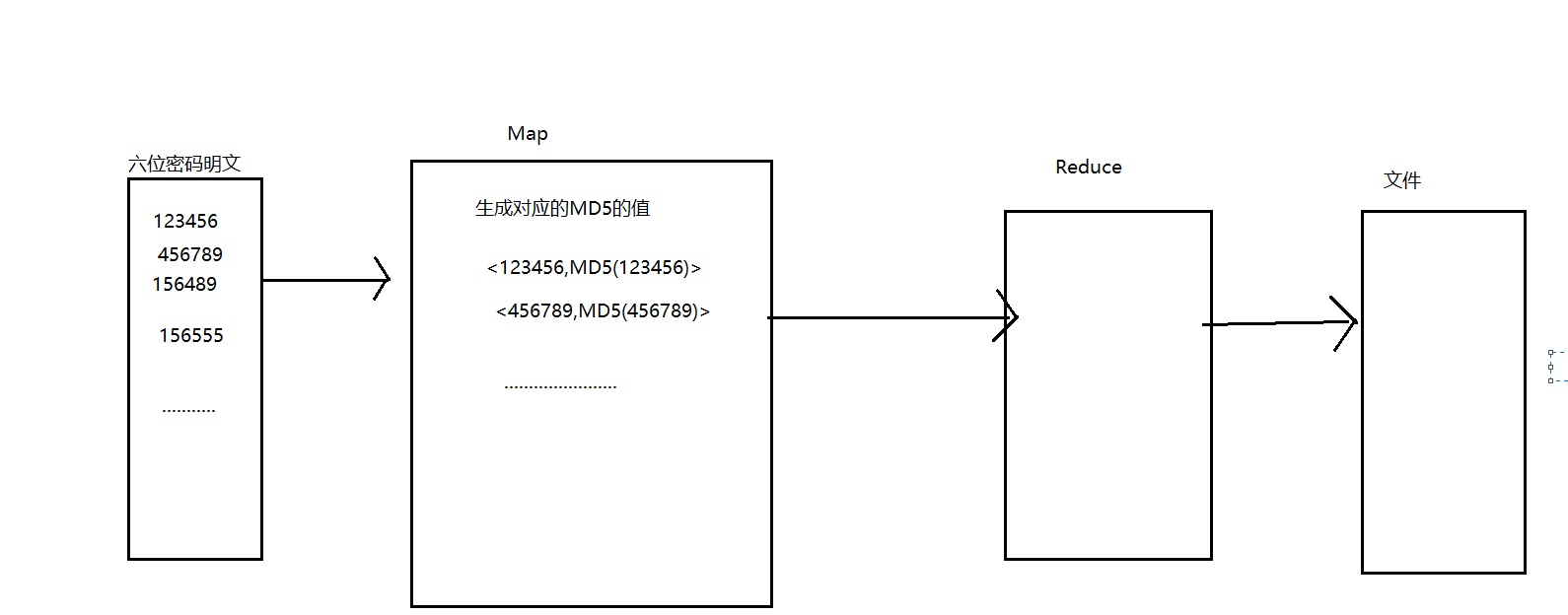
1.编程生成所有的密码明文文件。
2.将明文上传至HDFS文件系统中,在Map函数中实现MD5的求值。然后直接存入文件系统中中。
代码实现:
package com.test; import java.security.MessageDigest; import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 目地很简单。不需要reduce处理,直接在Map中解决问题
* @author hadoop
*
*/
public class Test {
//定义Map处理类
static class TestMapper extends Mapper<LongWritable, Text, Text, Text>{
//重写map方法
public void map(LongWritable key, Text value, Context context)throws InterruptedException {
try{
//生成MD5
String keyStr=value.toString();
String MD5=getMD5(keyStr);
context.write(new Text(keyStr), new Text(MD5));
}catch (Exception e){
e.printStackTrace();
}
}
}
/**
* MD5计算
* @param str
* @return
*/
public static String getMD5(String str) {
try {
// 生成一个MD5加密计算摘要
MessageDigest md = MessageDigest.getInstance("MD5");
// 计算md5函数
md.update(str.getBytes());
// digest()最后确定返回md5 hash值,返回值为8为字符串。因为md5 hash值是16位的hex值,实际上就是8位的字符
// BigInteger函数则将8位的字符串转换成16位hex值,用字符串来表示;得到字符串形式的hash值
byte[] encrypt = md.digest();
StringBuilder sb = new StringBuilder();
for (byte t : encrypt) {
String s = Integer.toHexString(t & 0xFF);
if (s.length() == 1) {
s = "0" + s;
}
sb.append(s);
}
String res = sb.toString();
return res;
} catch (Exception e) {
e.printStackTrace();
}
return null;
} public static void main(String[] args) throws Exception {
//必须要传递的是自定的mapper和reducer的类,输入输出的路径必须指定,输出的类型<k3,v3>必须指定
//将自定义的MyMapper和MyReducer组装在一起
Configuration conf=new Configuration();
String jobName=Test.class.getSimpleName();
//首先写job,知道需要conf和jobname在去创建即可
Job job = Job.getInstance(conf, jobName);
//如果要打包运行改程序,则需要调用如下行
job.setJarByClass(Test.class);
//读取HDFS內容:设置输入路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
//指定解析<k1,v1>的类(谁来解析键值对)
//*指定解析的类可以省略不写,因为设置解析类默认的就是TextInputFormat.class
job.setInputFormatClass(TextInputFormat.class);
//指定自定义mapper类
job.setMapperClass(TestMapper.class);
//指定map输出的key2的类型和value2的类型 <k2,v2>
//下面两步可以省略,当<k3,v3>和<k2,v2>类型一致的时候,<k2,v2>类型可以不指定
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//分区(默认1个),排序,分组,规约 采用 默认
// job.setCombinerClass(null);
//接下来采用reduce步骤
//指定自定义的reduce类
// job.setReducerClass(null);
//指定输出的<k3,v3>类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//指定输出<K3,V3>的类
//下面这一步可以省
// job.setOutputFormatClass(TextOutputFormat.class);
//指定输出路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//写的mapreduce程序要交给resource manager运行
job.waitForCompletion(true);
} }
这里为什么不用Reduce过程?
Reduce是对归约后的键值对进行处理的,但是可以看见,我们的明文都是唯一的,经过Map后输出的键值对的Key都是不一样的,归约之后仍然如此,所以没有必要在Reduce过程中进行其他操作。
另外我之前的想法是不在map中处理,而是将Map中读取到的文件内容直接输出到Reduce,然后在Reduce中进行MD5的计算,但是从Map中传输过来的数据总会多出一些行,导致计算出错。(这个我也没能弄懂怎么回事,有大佬知道的可以靠诉我)
三、数据查询
有了上一步生成的数据,我们就可以做数据的查询了。生成的文件仍然是在HDFS文件系统中,通过终端输入参数(可以是明文或者是密文),然后用MapReduce进行查找,结果输出到文件中。
代码:
package com.test; import java.security.MessageDigest; import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 目地很简单。不需要reduce处理,直接在Map中解决问题
* @author hadoop
*
*/
public class Test {
private static String s=null;
//定义Map处理类
static class TestMapper extends Mapper<LongWritable, Text, Text, Text>{
//重写map方法
public void map(LongWritable key, Text value, Context context)throws InterruptedException {
try{
//查询MD5的值
int index=value.find(s);
if(index>=0){
System.out.println("=================="+value.toString());
context.write(new Text("result"), value);
}
}catch (Exception e){
e.printStackTrace();
}
}
}
/**
* MD5计算
* @param str
* @return
*/
public static String getMD5(String str) {
try {
// 生成一个MD5加密计算摘要
MessageDigest md = MessageDigest.getInstance("MD5");
// 计算md5函数
md.update(str.getBytes());
// digest()最后确定返回md5 hash值,返回值为8为字符串。因为md5 hash值是16位的hex值,实际上就是8位的字符
// BigInteger函数则将8位的字符串转换成16位hex值,用字符串来表示;得到字符串形式的hash值
byte[] encrypt = md.digest();
StringBuilder sb = new StringBuilder();
for (byte t : encrypt) {
String s = Integer.toHexString(t & 0xFF);
if (s.length() == 1) {
s = "0" + s;
}
sb.append(s);
}
String res = sb.toString();
return res;
} catch (Exception e) {
e.printStackTrace();
}
return null;
} public static void main(String[] args) throws Exception {
//必须要传递的是自定的mapper和reducer的类,输入输出的路径必须指定,输出的类型<k3,v3>必须指定
//将自定义的MyMapper和MyReducer组装在一起 //参数(明文或者MD5值)
s=args[2];
Configuration conf=new Configuration();
String jobName=Test.class.getSimpleName();
//首先写job,知道需要conf和jobname在去创建即可
Job job = Job.getInstance(conf, jobName);
//如果要打包运行改程序,则需要调用如下行
job.setJarByClass(Test.class);
//读取HDFS內容:设置输入路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
//指定解析<k1,v1>的类(谁来解析键值对)
//*指定解析的类可以省略不写,因为设置解析类默认的就是TextInputFormat.class
job.setInputFormatClass(TextInputFormat.class);
//指定自定义mapper类
job.setMapperClass(TestMapper.class);
//指定map输出的key2的类型和value2的类型 <k2,v2>
//下面两步可以省略,当<k3,v3>和<k2,v2>类型一致的时候,<k2,v2>类型可以不指定
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//分区(默认1个),排序,分组,规约 采用 默认
// job.setCombinerClass(null);
//接下来采用reduce步骤
//指定自定义的reduce类
// job.setReducerClass(null);
//指定输出的<k3,v3>类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//指定输出<K3,V3>的类
//下面这一步可以省
// job.setOutputFormatClass(TextOutputFormat.class);
//指定输出路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//写的mapreduce程序要交给resource manager运行
job.waitForCompletion(true);
} }
四、导出JAR包放到Hadoop中运行
把文件导出成JAR包,在终端使用命令
生成密文:
bin/hadoop jar [jar包路径] [输入文件路径] [输出路径]
查询
bin/hadoop jar [jar包路径] [输入文件路径] [输出路径] [密文或者明文]
生成的密文结果实例:
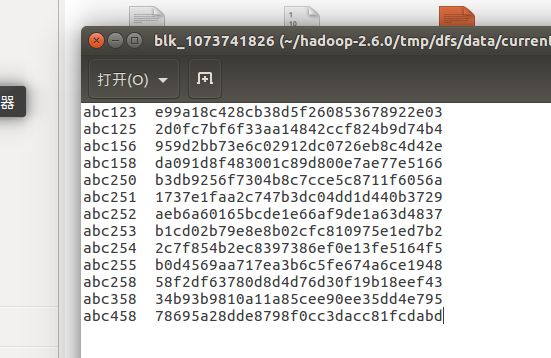
查询的结果示例:

ok以上,祝君好运。
暴力破解MD5的实现(MapReduce编程)的更多相关文章
- Python黑客编程2 入门demo--zip暴力破解
Python黑客编程2 入门demo--zip暴力破解 上一篇文章,我们在Kali Linux中搭建了基本的Python开发环境,本篇文章为了拉近Python和大家的距离,我们写一个暴力破解zip包密 ...
- burp暴力破解之md5和绕过验证码
Burpsuite是一个功能强大的工具,也是一个比较复杂的工具 本节主要说明一下burp的intruder模块中的2个技巧 1.md5加密 我们在payload Processing中的add选项可以 ...
- Linux 利用hosts.deny 防止暴力破解ssh(转)
一.ssh暴力破解 利用专业的破解程序,配合密码字典.登陆用户名,尝试登陆服务器,来进行破解密码,此方法,虽慢,但却很有效果. 二.暴力破解演示 2.1.基础环境:2台linux主机(centos 7 ...
- Web攻防之暴力破解(何足道版)
原创文章 原文首发我实验室公众号 猎户安全实验室 然后发在先知平台备份了一份 1 @序 攻防之初,大多为绕过既有逻辑和认证,以Getshell为节点,不管是SQL注入获得管理员数据还是XSS 获得后台 ...
- 385cc412a70eb9c6578a82ac58fce14c 教大家破解md5验证值
Md5密文破解(解密)可以说是网络攻击中的一个必不可少的环节,是工具中的一个重要"辅助工具".md5解密主要用于网络攻击,在对网站等进行入侵过程,有可能获得管理员或者其他用户的账号 ...
- 《11招玩转网络安全》之第三招:Web暴力破解-Low级别
Docker中启动LocalDVWA容器,准备DVWA环境.在浏览器地址栏输入http://127.0.0.1,中打开DVWA靶机.自动跳转到了http://127.0.0.1/login.php登录 ...
- DVWA 黑客攻防演练(二)暴力破解 Brute Froce
暴力破解,简称"爆破".不要以为没人会对一些小站爆破.实现上我以前用 wordpress 搭建一个博客开始就有人对我的站点进行爆破.这是装了 WordfenceWAF 插件后的统计 ...
- 如何通过Python暴力破解网站登陆密码
首先申明,该文章只可以用于交流学习,不可以用于其他用途,否则后果自负. 现在国家对网络安全的管理,越来越严,但是还是有一些不法网站逍遥法外,受限于国内的人力.物力,无法对这些网站进行取缔. 今天演示的 ...
- 【Linux笔记】阿里云服务器被暴力破解
一.关于暴力破解 前几天新购进了一台阿里云服务器,使用过程中时常会收到“主机被暴力破解”的警告,警告信息如下: 云盾用户您好!您的主机:... 正在被暴力破解,系统已自动启动破解保护.详情请登录htt ...
随机推荐
- 【转】Linux shell笔记
由于工作的需要,越来越多的接触到linux系统.最近看了<Linux与Unix Shell>这本书,安装书的章节整理了一些自己认为比较重要的命令,方便以后查阅. No.001 文件安全与权 ...
- JS中的算法与数据结构——排序(Sort)(转)
排序算法(Sort) 引言 我们平时对计算机中存储的数据执行的两种最常见的操作就是排序和查找,对于计算机的排序和查找的研究,自计算机诞生以来就没有停止过.如今又是大数据,云计算的时代,对数据的排序和查 ...
- BSGS(Baby Steps,Giant Steps)算法详解
BSGS(Baby Steps,Giant Steps)算法详解 简介: 此算法用于求解 Ax≡B(mod C): 由费马小定理可知: x可以在O(C)的时间内求解: 在x=c之后又会循环: 而BS ...
- MonogoDB 查询小结
MonogoDB是一种NoSQL数据库 优点: 1.数据的存储以json的文档进行存储(面向文档存储) 2.聚合框架查询速度快 3.高效存储二进制大对象 缺点: 1.不支持事务 2.文件存储空间占用过 ...
- Python CRM项目八
自定义用户认证 目的:实现Django自定义的认证系统,在生产环境都是根据此代码进行定制的 步骤: 1.在settings文件中配置要使用的类 #命名规则 app名称.类名 AUTH_USER_MOD ...
- 只用120行Java代码写一个自己的区块链
区块链是目前最热门的话题,广大读者都听说过比特币,或许还有智能合约,相信大家都非常想了解这一切是如何工作的.这篇文章就是帮助你使用 Java 语言来实现一个简单的区块链,用不到 120 行代码来揭示区 ...
- spring boot + vue + element-ui全栈开发入门——前端列表页面开发
一.页面 1.布局 假设,我们要开发一个会员列表的页面. 首先,添加vue页面文件“src\pages\Member.vue” 参照文档http://element.eleme.io/#/zh-CN ...
- 从UUID想到的
1.UUID的定义 通用唯一标识符(UUID)被设计成一个在时间和空间上都独一无二的数字,常被用作唯一性标识. UUID是一个由5位十六进制数的字符串表示的128比特数字,其格式为 aaaaaaaa- ...
- 对JavaScript中的静态属性和原型属性的理解
首先是在访问上的区别,当访问实例对象的某个属性但它本身没有时,它就会到原型中去查找,但不会去查找静态属性. // 实例对象不会去查找静态属性 function Foo(){} Foo.a = 1; v ...
- Javascript获取数组中的最大值和最小值方法汇总
方法一 sort()方法 b-a从大到小,a-b从小到大 var max2 = arr.sort(function(a,b){ return b-a; })[0]; console.log(max2) ...