python入门学习笔记(二)
6.6替换元素

7.tuple类型
7.1创建tuple

7.2创建单元素tuple

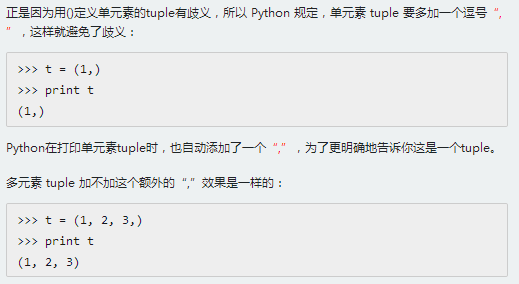
7.3“可变”的tuple



8.条件判断和循环
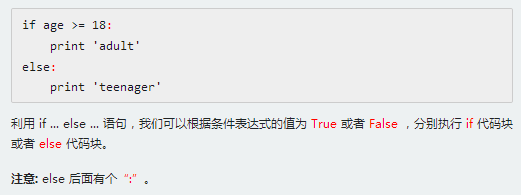
8.1,if语句


8.2,if...else
8.3,if-elif-else
要避免嵌套结构的if...else...,可以用if...多个elif...else...的结构,一次写完所有的规则:
score = 85
if score>=90:
print 'excellent'
elif score>=80:
print 'good'
elif score>=60:
print 'passed'
else:
print 'failed'
elif 意思就是else if。这样一来,我们就写出了结构非常清晰的一系列条件判断。
特别注意: 这一系列条件判断会从上到下依次判断,如果某个判断为 True,执行完对应的代码块,后面的条件判断就直接忽略,不再执行了。
8.4,for循环
Python的 for 循环就可以依次把list或tuple的每个元素迭代出来:
L = ['Adam', 'Lisa', 'Bart']
for name in L:
print name
注意: name 这个变量是在 for 循环中定义的,意思是,依次取出list中的每一个元素,并把元素赋值给 name,然后执行for循环体(就是缩进的代码块)。
这样一来,遍历一个list或tuple就非常容易了。
8.5,while循环
和 for 循环不同的另一种循环是 while 循环,while 循环不会迭代 list 或 tuple 的元素,而是根据表达式判断循环是否结束。
比如要从 0 开始打印不大于 N 的整数:
N = 10
x = 0
while x < N:
print x
x = x + 1
while循环每次先判断 x < N,如果为True,则执行循环体的代码块,否则,退出循环。
在循环体内,x = x + 1 会让 x 不断增加,最终因为 x < N 不成立而退出循环。
如果没有这一个语句,while循环在判断 x < N 时总是为True,就会无限循环下去,变成死循环,所以要特别留意while循环的退出条件。
8.6,break退出循环
用 for 循环或者 while 循环时,如果要在循环体内直接退出循环,可以使用 break 语句。
比如计算1至100的整数和,我们用while来实现:
sum = 0
x = 1
while True:
sum = sum + x
x = x + 1
if x > 100:
break
print sum
咋一看, while True 就是一个死循环,但是在循环体内,我们还判断了 x > 100 条件成立时,用break语句退出循环,这样也可以实现循环的结束。
8.7,continue继续循环
在循环过程中,可以用break退出当前循环,还可以用continue跳过后续循环代码,继续下一次循环。
假设我们已经写好了利用for循环计算平均分的代码:
L = [75, 98, 59, 81, 66, 43, 69, 85]
sum = 0.0
n = 0
for x in L:
sum = sum + x
n = n + 1
print sum / n
现在老师只想统计及格分数的平均分,就要把 x < 60 的分数剔除掉,这时,利用 continue,可以做到当 x < 60的时候,不继续执行循环体的后续代码,直接进入下一次循环:
for x in L:
if x < 60:
continue
sum = sum + x
n = n + 1
计算1-100所有奇数的和:
sum = 1
x = 1
while True:
x = x + 1
if x%2==0:
continue
if x > 100:
break
sum+=x
print sum
8.8,多重循环
在循环内部,还可以嵌套循环,我们来看一个例子:
for x in ['A', 'B', 'C']:
for y in ['1', '2', '3']:
print x + y
x 每循环一次,y 就会循环 3 次,这样,我们可以打印出一个全排列:
A1
A2
A3
B1
B2
B3
C1
C2
C3
9.Dict和Set类型
9.1,什么是dict
用 dict 表示“名字”-“成绩”的查找表如下:
d = {
'Adam': 95,
'Lisa': 85,
'Bart': 59
}
我们把名字称为key,对应的成绩称为value,dict就是通过 key 来查找 value。
花括号 {} 表示这是一个dict,然后按照 key: value, 写出来即可。最后一个 key: value 的逗号可以省略
由于dict也是集合,len() 函数可以计算任意集合的大小:
>>> len(d)
3
注意: 一个 key-value 算一个,因此,dict大小为3。
9.2,访问dict
可以简单地使用 d[key] 的形式来查找对应的 value,这和 list 很像,不同之处是,list 必须使用索引返回对应的元素,而dict使用key:
>>> print d['Adam']
95
>>> print d['Paul']
Traceback (most recent call last):
File "index.py", line 11, in <module>
print d['Paul']
KeyError: 'Paul'
注意: 通过 key 访问 dict 的value,只要 key 存在,dict就返回对应的value。如果key不存在,会直接报错:KeyError。
要避免 KeyError 发生,有两个办法:
一是先判断一下 key 是否存在,用 in 操作符:
if 'Paul' in d:
print d['Paul']
如果 'Paul' 不存在,if语句判断为False,自然不会执行 print d['Paul'] ,从而避免了错误。
二是使用dict本身提供的一个 get 方法,在Key不存在的时候,返回None:
>>> print d.get('Bart')
59
>>> print d.get('Paul')
None
9.3,dict的特点
dict的第一个特点是查找速度快,无论dict有10个元素还是10万个元素,查找速度都一样。而list的查找速度随着元素增加而逐渐下降。
不过dict的查找速度快不是没有代价的,dict的缺点是占用内存大,还会浪费很多内容,list正好相反,占用内存小,但是查找速度慢。
由于dict是按 key 查找,所以,在一个dict中,key不能重复。
dict的第二个特点就是存储的key-value序对是没有顺序的!这和list不一样:
d = {
'Adam': 95,
'Lisa': 85,
'Bart': 59
}
当我们试图打印这个dict时:
>>> print d
{'Lisa': 85, 'Adam': 95, 'Bart': 59}
打印的顺序不一定是我们创建时的顺序,而且,不同的机器打印的顺序都可能不同,这说明dict内部是无序的,不能用dict存储有序的集合。
dict的第三个特点是作为 key 的元素必须不可变,Python的基本类型如字符串、整数、浮点数都是不可变的,都可以作为 key。但是list是可变的,就不能作为 key。
不可变这个限制仅作用于key,value是否可变无所谓:
{
'123': [1, 2, 3], # key 是 str,value是list
123: '123', # key 是 int,value 是 str
('a', 'b'): True # key 是 tuple,并且tuple的每个元素都是不可变对象,value是 boolean
}
最常用的key还是字符串,因为用起来最方便。
9.4,更新dict
dict是可变的,也就是说,我们可以随时往dict中添加新的 key-value。比如已有dict:
d = {
'Adam': 95,
'Lisa': 85,
'Bart': 59
}
要把新同学'Paul'的成绩 72 加进去,用赋值语句:
>>> d['Paul'] = 72
再看看dict的内容:
>>> print d
{'Lisa': 85, 'Paul': 72, 'Adam': 95, 'Bart': 59}
如果 key 已经存在,则赋值会用新的 value 替换掉原来的 value:
>>> d['Bart'] = 60
>>> print d
{'Lisa': 85, 'Paul': 72, 'Adam': 95, 'Bart': 60}
9.4,遍历dict
直接使用for循环可以遍历 dict 的 key:
>>> d = { 'Adam': 95, 'Lisa': 85, 'Bart': 59 }
>>> for key in d:
... print key
...
Lisa
Adam
Bart
由于通过 key 可以获取对应的 value,因此,在循环体内,可以获取到value的值。
有的时候,我们只想要 dict 的 key,不关心 key 对应的 value,目的就是保证这个集合的元素不会重复,这时,set就派上用场了。
set 持有一系列元素,这一点和 list 很像,但是set的元素没有重复,而且是无序的,这点和 dict 的 key很像。
创建 set 的方式是调用 set() 并传入一个 list,list的元素将作为set的元素:
>>> s = set(['A', 'B', 'C'])
可以查看 set 的内容:
>>> print s
set(['A', 'C', 'B'])
请注意,上述打印的形式类似 list, 但它不是 list,仔细看还可以发现,打印的顺序和原始 list 的顺序有可能是不同的,因为set内部存储的元素是无序的。
因为set不能包含重复的元素,所以,当我们传入包含重复元素的 list 会怎么样呢?
>>> s = set(['A', 'B', 'C', 'C'])
>>> print s
set(['A', 'C', 'B'])
>>> len(s)
3
结果显示,set会自动去掉重复的元素,原来的list有4个元素,但set只有3个元素。
9.6,访问set
例如,存储了班里同学名字的set:
>>> s = set(['Adam', 'Lisa', 'Bart', 'Paul'])
我们可以用 in 操作符判断:
Bart是该班的同学吗?
>>> 'Bart' in s
True
Bill是该班的同学吗?
>>> 'Bill' in s
False
bart是该班的同学吗?
>>> 'bart' in s
False
看来大小写很重要,'Bart' 和 'bart'被认为是两个不同的元素。
9.6,set的特点
set的内部结构和dict很像,唯一区别是不存储value,因此,判断一个元素是否在set中速度很快。
set存储的元素和dict的key类似,必须是不变对象,因此,任何可变对象是不能放入set中的。
最后,set存储的元素也是没有顺序的。set的这些特点,可以应用在哪些地方呢?
星期一到星期日可以用字符串'MON', 'TUE', ... 'SUN'表示。假设我们让用户输入星期一至星期日的某天,如何判断用户的输入是否是一个有效的星期呢?
可以用 if 语句判断,但这样做非常繁琐:
x = '???' # 用户输入的字符串
if x!= 'MON' and x!= 'TUE' and x!= 'WED' ... and x!= 'SUN':
print 'input error'
else:
print 'input ok'
如果事先创建好一个set,包含'MON' ~ 'SUN':
weekdays = set(['MON', 'TUE', 'WED', 'THU', 'FRI', 'SAT', 'SUN'])
再判断输入是否有效,只需要判断该字符串是否在set中:
x = '???' # 用户输入的字符串
if x in weekdays:
print 'input ok'
else:
print 'input error'
这样一来,代码就简单多了。
9.7,遍历set
由于 set 也是一个集合,所以,遍历 set 和遍历 list 类似,都可以通过 for 循环实现。
直接使用 for 循环可以遍历 set 的元素:
>>> s = set(['Adam', 'Lisa', 'Bart'])
>>> for name in s:
... print name
...
Lisa
Adam
Bart
注意: 观察 for 循环在遍历set时,元素的顺序和list的顺序很可能是不同的,而且不同的机器上运行的结果也可能不同。
9.8,更新set
由于set存储的是一组不重复的无序元素,因此,更新set主要做两件事:
一是把新的元素添加到set中,二是把已有元素从set中删除。
添加元素时,用set的add()方法:
>>> s = set([1, 2, 3])
>>> s.add(4)
>>> print s
set([1, 2, 3, 4])
如果添加的元素已经存在于set中,add()不会报错,但是不会加进去了:
>>> s = set([1, 2, 3])
>>> s.add(3)
>>> print s
set([1, 2, 3])
删除set中的元素时,用set的remove()方法:
>>> s = set([1, 2, 3, 4])
>>> s.remove(4)
>>> print s
set([1, 2, 3])
如果删除的元素不存在set中,remove()会报错:
>>> s = set([1, 2, 3])
>>> s.remove(4)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 4
所以用add()可以直接添加,而remove()前需要判断。
python入门学习笔记(二)的更多相关文章
- Python入门学习笔记4:他人的博客及他人的学习思路
看其他人的学习笔记,可以保证自己不走弯路.并且一举两得,即学知识又学方法! 廖雪峰:https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958 ...
- Python入门 学习笔记 (二)
今天学习了一些简单的语法规则,话不多说,开始了: 二.数据类型 常用数据类型中的整形和浮点型就不多说了. 1.字符串 ...
- Python入门学习笔记
了解 一下Python中的基本语法,发现挺不适应的,例如变量经常想去指定类型或者if加个括号之类的.这是在MOOC中学习到的知识中一点简单的笔记. Python的变量和数据类型: 1.Python这种 ...
- Python入门学习(二)
1 字典 1.1 字典的创建和访问 字典不同于前述的序列类型,它是一种映射类型.它的引入是为了简化定义索引值和元素值存在特定关系的定义和访问问题. 字典的定义形式为:字典变量名 = {key1:val ...
- python入门学习笔记(三)
10.函数 求绝对值的函数 abs(x) 也可以在交互式命令行通过 help(abs) 查看abs函数的帮助信息.调用 abs 函数:>>> abs(100)100>>& ...
- 【原】Learning Spark (Python版) 学习笔记(二)----键值对、数据读取与保存、共享特性
本来应该上周更新的,结果碰上五一,懒癌发作,就推迟了 = =.以后还是要按时完成任务.废话不多说,第四章-第六章主要讲了三个内容:键值对.数据读取与保存与Spark的两个共享特性(累加器和广播变量). ...
- webdriver(python)学习笔记二
自己开始一个脚本开始学习: # coding = utf-8 from selenium import webdriver browser = webdriver.Firefox() browser. ...
- python入门 -- 学习笔记1
学习资料:笨方法学Python 准备: 安装环境----请自行网络搜索(Windows安装很简单,和其他安装程序一样) 找一个自己习惯的编辑器(比如:sublime text 3) 创建一个专门的目录 ...
- 笔记1 python入门学习笔记
目录 官方手册 菜鸟站手册地址: python的运行方法 注释 小技巧: input()接收用户输入的内容(默认为字符串) print() 运算符 is 是判断两个标识符是不是引用自一个对象 all和 ...
随机推荐
- 通过自定义的URL Scheme启动你的App
iPhone SDK可以把你的App和一个自定义的URL Scheme绑定.该URL Scheme可用来从浏览器或别的App启动你的App. 如何响应从别的App里发给你的URL Scheme申请,由 ...
- myeclipse编码
window --->perferences
- oracle02
SQL语句完整结构: select from where group by having order by 今天分享的知识点:(1)分组查询 select 中非组函数的列需要在group by 进行参 ...
- LINUX文件操作命令
body, table{font-family: 微软雅黑} table{border-collapse: collapse; border: solid gray; border-width: 2p ...
- Source Insight、Xshell(putty)、Xftp
body, table{font-family: 微软雅黑} table{border-collapse: collapse; border: solid gray; border-width: 2p ...
- ThinkPhp关闭Debug后出错解决方案
注:我使用的是ThinkPHP的3.2版本,其他版本类似 从自己入手PHP开发以来,一直使用的是ThinkPHP的框架,前几天偶然间碰到了一个错误,在Debug模式下网站一切正常,而关闭Debug进行 ...
- 如何用命令将本地项目上传到github
一.Git终端软件安装 1.下载windows上git终端,类似shell工具,下载地址:http://msysgit.github.io/ 2.安装方法,打开文件,一路点击Next即可 3.安装完成 ...
- Mysql基本命令一
一.清除mysql表中数据 delete from 表名;truncate table 表名;不带where参数的delete语句可以删除mysql表中所有内容,使用truncate table也可以 ...
- 搭建yum仓库与定制rpm包
笔者Q:972581034 交流群:605799367.有任何疑问可与笔者或加群交流 当我们自动化部署集群的时候,想要快速的安装所有服务,搭建yum仓库与定制rpm包是我们首先要做的 原创作品,转载请 ...
- 2018-01-28-TF源码做版本兼容的一个粗暴方法
layout: post title: 2018-01-28-TF源码做版本兼容的一个粗暴方法 key: 20180128 tags: IT AI TF modify_date: 2018-01-28 ...