浅谈Web网站的架构演变过程
前言
- 用户模块:用户注册和管理
- 商品模块:商品展示和管理
- 交易模块:创建交易和管理
阶段一、单机构建网站
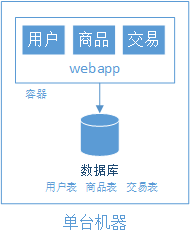
阶段二、应用服务器与数据库分离

阶段三、应用服务器集群
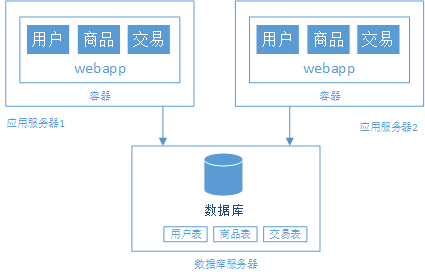
- 用户的请求由谁来转发到到具体的应用服务器
- 有什么转发的算法
- 应用服务器如何返回用户的请求
- 用户如果每次访问到的服务器不一样,那么如何维护session的一致性
我们来看看解决问题的方案:
1、第一个问题即是负载均衡的问题,一般有5种解决方案:
1、http重定向。HTTP重定向就是应用层的请求转发。用户的请求其实已经到了HTTP重定向负载均衡服务器,服务器根据算法要求用户重定向,用户收到重定向请求后,再次请求真正的集群
优点:简单。
缺点:性能较差。
2、DNS域名解析负载均衡。DNS域名解析负载均衡就是在用户请求DNS服务器,获取域名对应的IP地址时,DNS服务器直接给出负载均衡后的服务器IP。
优点:交给DNS,不用我们去维护负载均衡服务器。
缺点:当一个应用服务器挂了,不能及时通知DNS,而且DNS负载均衡的控制权在域名服务商那里,网站无法做更多的改善和更强大的管理。
3、反向代理服务器。在用户的请求到达反向代理服务器时(已经到达网站机房),由反向代理服务器根据算法转发到具体的服务器。常用的apache,nginx都可以充当反向代理服务器。
优点:部署简单。
缺点:代理服务器可能成为性能的瓶颈,特别是一次上传大文件。
4、IP层负载均衡。在请求到达负载均衡器后,负载均衡器通过修改请求的目的IP地址,从而实现请求的转发,做到负载均衡。
优点:性能更好。
缺点:负载均衡器的宽带成为瓶颈。
5、数据链路层负载均衡。在请求到达负载均衡器后,负载均衡器通过修改请求的mac地址,从而做到负载均衡,与IP负载均衡不一样的是,当请求访问完服务器之后,直接返回客户。而无需再经过负载均衡器。
2、第二个问题即是集群调度算法问题,常见的调度算法有10种。
1、rr 轮询调度算法。顾名思义,轮询分发请求。
优点:实现简单
缺点:不考虑每台服务器的处理能力
2、wrr 加权调度算法。我们给每个服务器设置权值weight,负载均衡调度器根据权值调度服务器,服务器被调用的次数跟权值成正比。
优点:考虑了服务器处理能力的不同
3、sh 原地址散列:提取用户IP,根据散列函数得出一个key,再根据静态映射表,查处对应的value,即目标服务器IP。过目标机器超负荷,则返回空。
4、dh 目标地址散列:同上,只是现在提取的是目标地址的IP来做哈希。
优点:以上两种算法的都能实现同一个用户访问同一个服务器。
5、lc 最少连接。优先把请求转发给连接数少的服务器。
优点:使得集群中各个服务器的负载更加均匀。
6、wlc 加权最少连接。在lc的基础上,为每台服务器加上权值。算法为:(活动连接数*256+非活动连接数)÷权重 ,计算出来的值小的服务器优先被选择。
优点:可以根据服务器的能力分配请求。
7、sed 最短期望延迟。其实sed跟wlc类似,区别是不考虑非活动连接数。算法为:(活动连接数+1)*256÷权重,同样计算出来的值小的服务器优先被选择。
8、nq 永不排队。改进的sed算法。我们想一下什么情况下才能“永不排队”,那就是服务器的连接数为0的时候,那么假如有服务器连接数为0,均衡器直接把请求转发给它,无需经过sed的计算。
9、LBLC 基于局部性的最少连接。均衡器根据请求的目的IP地址,找出该IP地址最近被使用的服务器,把请求转发之,若该服务器超载,最采用最少连接数算法。
10、LBLCR 带复制的基于局部性的最少连接。均衡器根据请求的目的IP地址,找出该IP地址最近使用的“服务器组”,注意,并不是具体某个服务器,然后采用最少连接数从该组中挑出具体的某台服务器出来,把请求转发之。若该服务器超载,那么根据最少连接数算法,在集群的非本服务器组的服务器中,找出一台服务器出来,加入本服务器组,然后把请求转发之。
3、第三个问题是集群模式问题,一般3种解决方案:
1、NAT:负载均衡器接收用户的请求,转发给具体服务器,服务器处理完请求返回给均衡器,均衡器再重新返回给用户。
2、DR:负载均衡器接收用户的请求,转发给具体服务器,服务器出来玩请求后直接返回给用户。需要系统支持IP Tunneling协议,难以跨平台。
3、TUN:同上,但无需IP Tunneling协议,跨平台性好,大部分系统都可以支持。
4、第四个问题是session问题,一般有4种解决方案:
1、Session Sticky。session sticky就是把同一个用户在某一个会话中的请求,都分配到固定的某一台服务器中,这样我们就不需要解决跨服务器的session问题了,常见的算法有ip_hash法,即上面提到的两种散列算法。
优点:实现简单。
缺点:应用服务器重启则session消失。
2、Session Replication。session replication就是在集群中复制session,使得每个服务器都保存有全部用户的session数据。
优点:减轻负载均衡服务器的压力,不需要要实现ip_hasp算法来转发请求。
缺点:复制时宽带开销大,访问量大的话session占用内存大且浪费。
3、Session数据集中存储:session数据集中存储就是利用数据库来存储session数据,实现了session和应用服务器的解耦。
优点:相比session replication的方案,集群间对于宽带和内存的压力减少了很多。
缺点:需要维护存储session的数据库。
4、Cookie Base:cookie base就是把session存在cookie中,有浏览器来告诉应用服务器我的session是什么,同样实现了session和应用服务器的解耦。
优点:实现简单,基本免维护。
缺点:cookie长度限制,安全性低,宽带消耗。
值得一提的是:
nginx目前支持的负载均衡算法有wrr、sh(支持一致性哈希)、fair(本人觉得可以归结为lc)。但nginx作为均衡器的话,还可以一同作为静态资源服务器。
keepalived+ipvsadm比较强大,目前支持的算法有:rr、wrr、lc、wlc、lblc、sh、dh
keepalived支持集群模式有:NAT、DR、TUN
nginx本身并没有提供session同步的解决方案,而apache则提供了session共享的支持。
好了,解决了以上的问题之后,系统的结构如下:
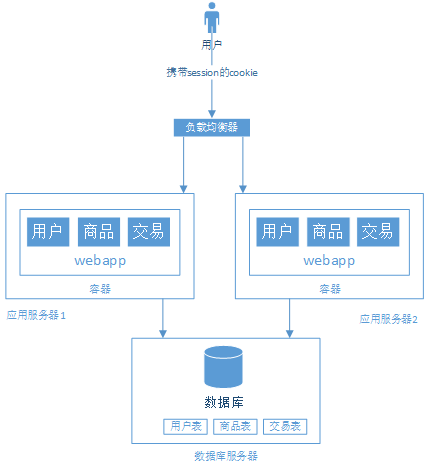
阶段四、数据库读写分离化

- 主从数据库之间数据同步问题
- 应用对于数据源的选择问题
- 我们可以使用MYSQL自带的master+slave的方式实现主从复制。
- 采用第三方数据库中间件,例如mycat。mycat是从cobar发展而来的,而cobar是阿里开源的数据库中间件,后来停止开发。mycat是国内比较好的mysql开源数据库分库分表中间件。
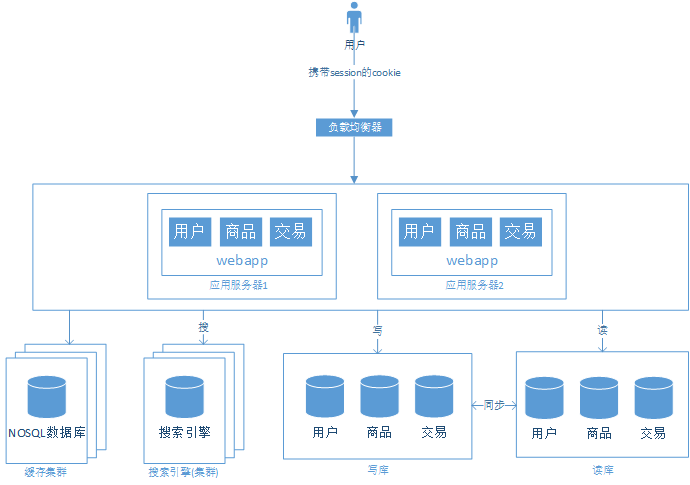
阶段五、用搜索引擎缓解读库的压力
数据库做读库的话,常常对模糊查找力不从心,即使做了读写分离,这个问题还未能解决。以我们所举的交易网站为例,发布的商品存储在数据库中,用户最常使用的功能就是查找商品,尤其是根据商品的标题来查找对应的商品。对于这种需求,一般我们都是通过like功能来实现的,但是这种方式的代价非常大。此时我们可以使用搜索引擎的倒排索引来完成。
- 它能够大大提高查询速度。
- 带来大量的维护工作,我们需要自己实现索引的构建过程,设计全量/增加的构建方式来应对非实时与实时的查询需求。
- 需要维护搜索引擎集群
搜索引擎并不能替代数据库,他解决了某些场景下的“读”的问题,是否引入搜索引擎,需要综合考虑整个系统的需求。引入搜索引擎后的系统结构如下:

阶段六、用缓存缓解读库的压力
1、后台应用层和数据库层的缓存
- 减轻数据库的压力
- 大幅度提高访问速度
- 需要维护缓存服务器
- 提高了编码的复杂性
值得一提的是:
缓存集群的调度算法不同与上面提到的应用服务器和数据库。最好采用“一致性哈希算法”,这样才能提高命中率。这个就不展开讲了,有兴趣的可以查阅相关资料。

阶段七、数据库水平拆分与垂直拆分
我们的网站演进到现在,交易、商品、用户的数据都还在同一个数据库中。尽管采取了增加缓存,读写分离的方式,但随着数据库的压力继续增加,数据库的瓶颈越来越突出,此时,我们可以有数据垂直拆分和水平拆分两种选择。
7.1、数据垂直拆分
垂直拆分的意思是把数据库中不同的业务数据拆分道不同的数据库中,结合现在的例子,就是把交易、商品、用户的数据分开。
- 解决了原来把所有业务放在一个数据库中的压力问题。
- 可以根据业务的特点进行更多的优化
- 需要维护多个数据库
- 需要考虑原来跨业务的事务
- 跨数据库的join
- 我们应该在应用层尽量避免跨数据库的事物,如果非要跨数据库,尽量在代码中控制。
- 我们可以通过第三方应用来解决,如上面提到的mycat,mycat提供了丰富的跨库join方案,详情可参考mycat官方文档。
垂直拆分后的结构如下:
7.2、数据水平拆分
数据水平拆分就是把同一个表中的数据拆分到两个甚至多个数据库中。产生数据水平拆分的原因是某个业务的数据量或者更新量到达了单个数据库的瓶颈,这时就可以把这个表拆分到两个或更多个数据库中。
- 如果我们能客服以上问题,那么我们将能够很好地对数据量及写入量增长的情况。
- 访问用户信息的应用系统需要解决SQL路由的问题,因为现在用户信息分在了两个数据库中,需要在进行数据操作时了解需要操作的数据在哪里。
- 主键的处理也变得不同,例如原来自增字段,现在不能简单地继续使用了。
- 如果需要分页,就麻烦了。
- 我们还是可以通过可以解决第三方中间件,如mycat。mycat可以通过SQL解析模块对我们的SQL进行解析,再根据我们的配置,把请求转发到具体的某个数据库。
- 我们可以通过UUID保证唯一或自定义ID方案来解决。
- mycat也提供了丰富的分页查询方案,比如先从每个数据库做分页查询,再合并数据做一次分页查询等等。
数据水平拆分后的结构:

阶段八、应用的拆分
8.1、拆分应用
随着业务的发展,业务越来越多,应用越来越大。我们需要考虑如何避免让应用越来越臃肿。这就需要把应用拆开,从一个应用变为俩个甚至更多。还是以我们上面的例子,我们可以把用户、商品、交易拆分开。变成“用户、商品”和“用户,交易”两个子系统。
拆分后的结构:

- 这样拆分后,可能会有一些相同的代码,如用户相关的代码,商品和交易都需要用户信息,所以在两个系统中都保留差不多的操作用户信息的代码。如何保证这些代码可以复用是一个需要解决的问题。
- 通过走服务化的路线来解决
8.2、走服务化的道路
为了解决上面拆分应用后所出现的问题,我们把公共的服务拆分出来,形成一种服务化的模式,简称SOA。
采用服务化之后的系统结构:
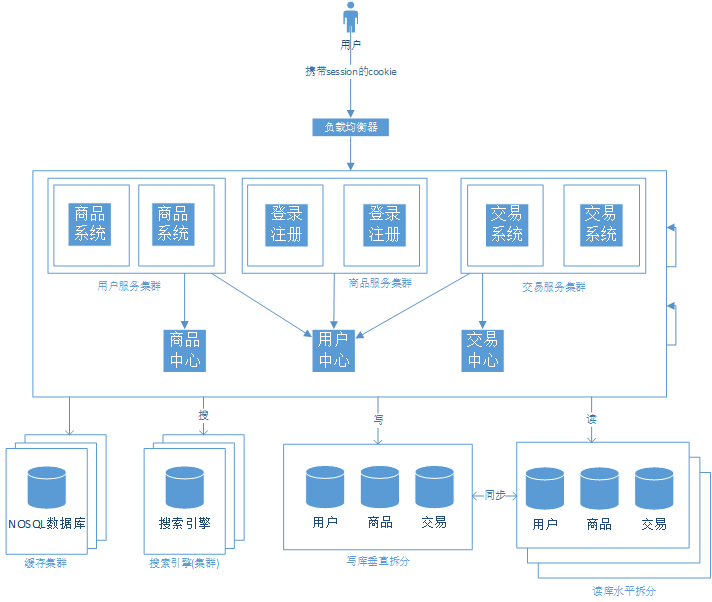
- 相同的代码不会散落在不同的应用中了,这些实现放在了各个服务中心,使代码得到更好的维护。
- 我们把对数据库的交互放在了各个服务中心,让”前端“的web应用更注重与浏览器交互的工作。
- 如何进行远程的服务调用
- 我们可以通过下面的引入消息中间件来解决
阶段九、引入消息中间件

十、总结
以上的演变过程只是一个例子,并不适合所有的网站,实际中网站演进过程与自身业务和不同遇到的问题有密切的关系,没有固定的模式。只有认真的分析和不断地探究,才能发现适合自己网站的架构。
浅谈Web网站的架构演变过程的更多相关文章
- 【架构】浅谈web网站架构演变过程
浅谈web网站架构演变过程 前言 我们以javaweb为例,来搭建一个简单的电商系统,看看这个系统可以如何一步步演变. 该系统具备的功能: 用户模块:用户注册和管理 商品模块:商品展示和管 ...
- 浅谈web网站架构演变过程
前言 我们以javaweb为例,来搭建一个简单的电商系统,看看这个系统可以如何一步步演变. 该系统具备的功能: 用户模块:用户注册和管理 商品模块:商品展示和管理 交易模块:创建交易和管理 阶 ...
- 浅谈web网站架构演变过程(转)
前言 我们以javaweb为例,来搭建一个简单的电商系统,看看这个系统可以如何一步步演变. 该系统具备的功能: 用户模块:用户注册和管理 商品模块:商品展示和管理 交易模块:创建交易和管理 阶 ...
- 浅谈web应用的负载均衡、集群、高可用(HA)解决方案(转)
1.熟悉几个组件 1.1.apache —— 它是Apache软件基金会的一个开放源代码的跨平台的网页服务器,属于老牌的web服务器了,支持基于Ip或者域名的虚拟主机,支持代理服务器,支持安 ...
- AngularJS进阶(二十五)requirejs + angular + angular-route 浅谈HTML5单页面架构
requirejs + angular + angular-route 浅谈HTML5单页面架构 众所周知,现在移动Webapp越来越多,例如天猫.京东.国美这些都是很好的例子.而在Webapp中,又 ...
- 浅谈HTML5单页面架构(二)——backbone + requirejs + zepto + underscore
本文转载自:http://www.cnblogs.com/kenkofox/p/4648472.html 上一篇<浅谈HTML5单页面架构(一)--requirejs + angular + a ...
- [原创]浅谈Web UI自动化测试
[原创]浅谈Web UI自动化测试 Web UI自动化测试相信大家都不陌生,今天来谈谈这个,我最早接触自动化测试时大约是在2004年,2006年当时在腾讯财付通算是开始正式接触自动化测试,之所以是正式 ...
- 浅谈|WEB 服务器 -- Caddy
浅谈|WEB 服务器 -- Caddy 2018年03月28日 12:38:00 yori_chen 阅读数:1490 标签: caddyserverwebhttps反向代理 更多 个人分类: ser ...
- 五分钟DBA:浅谈伪分布式数据库架构
[IT168 技术]12月25日消息,2010互联网行业技术研讨峰会今日在上海华东理工大学召开.本次峰会以“互联网行业应用最佳实践”为主题,定位于互联网架构设计.应用开发.应用运维管理,同时,峰会邀请 ...
随机推荐
- 巧用UserAgent来解决浏览器的各种问题
以前对UserAgent了解不是很透彻,今天发现UserAgent用处多多.比如我之前一直很喜欢用火狐浏览器,不过用了那么久发现火狐浏览器问题多多,比如有的论坛上传附件或者上传图片等按钮没有作用,并且 ...
- Python 3 中生成器函数yield表达式的使用
生成器函数或生成器方法中包含了一个yield表达式.调用生成器函数时,会返回一个迭代子,值从迭代子中每次提取一个(通过调用其__next__()方法).每次调用__next__()时,生成器函数的yi ...
- Git分支(5/5) -- 解决合并的冲突
如果两个分支上都对同一个文件进行了修改, 那么就有可能发生冲突. 首先创建一个分支, 并切换到该分支上: 然后修改index.html, 修改几个地方吧. 然后查看状态, 并commit: 然后切换到 ...
- 智能合约语言 Solidity 教程系列1 - 类型介绍
现在的Solidity中文文档,要么翻译的太烂,要么太旧,决定重新翻译下.尤其点名批评极客学院名为<Solidity官方文档中文版>的翻译,机器翻译的都比它好,大家还是别看了. 写在前面 ...
- 20165230 学习基础和C语言基础调查
20165230 学习基础和C语言基础调查 技能学习经验 我擅长弹钢琴.小时候我曾上过很多兴趣班,比如钢琴.跳舞.书法.绘画等等,唯一坚持至今的只有钢琴.仔细一算学习钢琴至今已有12年,不能说已经精通 ...
- 边做边学入门微信小程序之仿豆瓣评分
微信小程序由于适用性强.逻辑简要.开发迅速的特性,叠加具有海量活跃用户的腾讯公司背景,逐渐成为了轻量级单一功能应用场景的较佳承载方式,诸如电影购票.外卖点餐.移动商城.生活服务等场景服务提供商迅速切入 ...
- Kafka OffsetMonitor:监控消费者和延迟的队列
一个小应用程序来监视kafka消费者的进度和它们的延迟的队列. KafkaOffsetMonitor是用来实时监控Kafka集群中的consumer以及在队列中的位置(偏移量). 你可以查看当前的消费 ...
- 自动化运维工具---expec
作为运维经常操作Linux服务器是不可避免的事情的,那么你们都是怎么管理的呢? 我们管理的方式较为复杂了,我说一下: 有一套服务器资产管理系统,所有服务器都记录在上面,包括用户名密码,内外网地址都会有 ...
- 巨人大哥谈Java中的Synchronized关键字用法
巨人大哥谈Java中的Synchronized关键字用法 认识synchronized 对于写多线程程序的人来说,经常碰到的就是并发问题,对于容易出现并发问题的地方价格synchronized基本上就 ...
- Rails 定时任务——whenever实现周期性任务
根据项目的进展,我们需要实现后台进行定时读取信息的功能,而最关键的实现部分是周期性功能,根据调研,决定使用whenever来实现这一功能. github:https://github.com/java ...