SQL Server 查找统计信息的采样时间与采样比例
有时候我们会遇到,由于统计信息不准确导致优化器生成了一个错误的执行计划(或者这样表达:一个较差的执行计划),从而引起了系统性能问题。那么如果我们怀疑这个错误的执行计划是由于统计信息不准确引起的。那么我们如何判断统计信息不准确呢?当然首先得去查看实际执行计划中,统计信息的相关数据是否与实际情况有较大的出入,下面我们抛开这个大命题,仅仅从统计信息层面去查看统计信息的更新时间,统计信息的采样行数、采样比例等情况。
1:首先,我们要查查统计信息是什么时候更新的。
2:其次,我们查看统计信息的采样的百分比以及采样信息:采样选取的行数、自上次更新统计信息以来前导统计信息列(构建直方图的列)的总修改次数。。。
查看统计信息的最后更新时间。
方法1:
--查看统计信息的更新时间
DECLARE @TableName NVARCHAR(128);
SET @TableName = '[Maint].[JobHistoryDetails]';
SELECT @TableName AS Table_Name,
name AS Stats_Name ,
STATS_DATE(object_id, stats_id) AS Last_Stats_Update
FROM sys.stats
WHERE object_id = OBJECT_ID(@TableName)
ORDER BY 2 DESC;
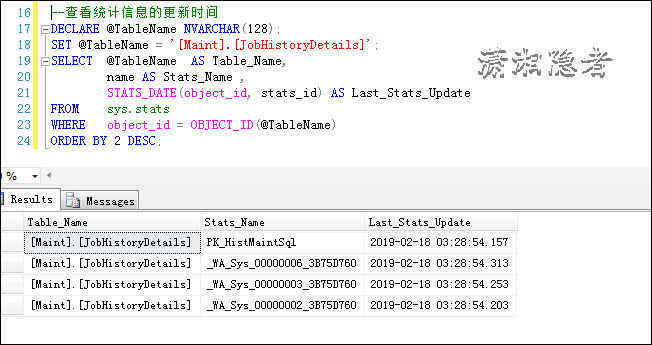
如上所示,我们通过这个脚本查看某个表所有的统计信息的最后一次更新时间。如果你需要查看某个具体的统计信息的最后更新时间,那么在这个SQL的基础上修改相关查询条件即可。
方法2:
--查看统计信息的更新时间
EXEC sp_autostats '[Maint].[JobHistoryDetails]';
方法3:
还有一种方法可以通过 sys.dm_db_stats_properties 返回统计信息的更新时间,不过这个DMF只有SQL Server 2008 R2 SP2这个版本之后的才有。
|
列名 |
数据类型 |
Description |
|
object_id |
int |
要返回统计信息对象属性的对象(表或索引视图)的 ID。 |
|
stats_id |
int |
统计信息对象的 ID。 在表或索引视图中是唯一的。 有关详细信息,请参阅 sys.stats (Transact-SQL)。 |
|
last_updated |
datetime2 |
上次更新统计信息对象的日期和时间。 有关详细信息,请参阅此页中的备注部分。 |
|
rows |
bigint |
上次更新统计信息时表或索引视图中的总行数。 如果筛选统计信息或者统计信息与筛选索引对应,该行数可能小于表中的行数。 |
|
rows_sampled |
bigint |
用于统计信息计算的抽样总行数。 |
|
Step |
int |
直方图中的值范围数(步长)(Number of steps in the histogram)。 有关详细信息,请参阅 DBCC SHOW_STATISTICS (Transact-SQL)。 |
|
unfiltered_rows |
bigint |
应用筛选表达式(用于筛选的统计信息)之前表中的总行数。 如果未筛选统计信息,则 unfiltered_rows 等于行列中返回的值。 |
|
modification_counter |
bigint |
自上次更新统计信息以来前导统计信息列(构建直方图的列)的总修改次数。 |
|
persisted_sample_percent |
float |
持久样本百分比用于未显式指定采样百分比的统计信息更新。 如果值为零,则不为此统计信息设置持久样本百分比。 |
SELECT sch.name + '.' + so.name AS table_name
, so.object_id
, ss.name AS stat_name
, ds.stats_id
, ds.last_updated
, ds.rows
, ds.rows_sampled
, ds.rows_sampled*1.0/ds.rows *100 AS sample_rate
, ds.steps
, ds.unfiltered_rows
--, ds.persisted_sample_percent
, ds.modification_counter
FROM sys.stats ss
JOIN sys.objects so ON ss.object_id = so.object_id
JOIN sys.schemas sch ON so.schema_id = sch.schema_id
CROSS APPLY sys.dm_db_stats_properties(ss.object_id,ss.stats_id) ds
WHERE so.is_ms_shipped = 0
AND so.object_id NOT IN (
SELECT major_id
FROM sys.extended_properties (NOLOCK)
WHERE name = N'microsoft_database_tools_support' );
查看统计信息采样的百分比
SELECT sch.name + '.' + so.name AS table_name
, so.object_id
, ss.name AS stat_name
, ds.stats_id
, ds.last_updated
, ds.rows
, ds.rows_sampled
, ds.steps
, ds.unfiltered_rows
, ds.modification_counter
FROM sys.stats ss
JOIN sys.objects so ON ss.object_id = so.object_id
JOIN sys.schemas sch ON so.schema_id = sch.schema_id
CROSS APPLY sys.dm_db_stats_properties(ss.object_id,ss.stats_id) ds
WHERE so.name = N'pbCutClothCost'
AND LEFT(ss.name, 4) != '_WA_';
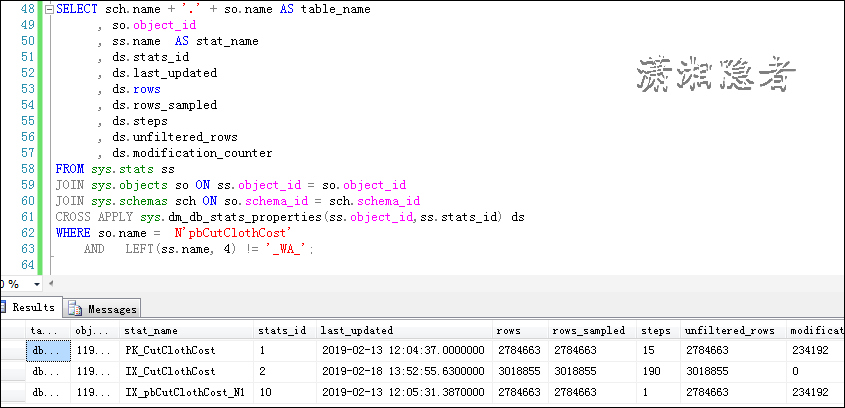
如上截图,索引IX_CutClothCost的统计信息有更新,是因为在执行上面脚本前,我更新了这个统计信息。通过rows与实际记录数对比、 modification_counter信息,我们从而有个大概的判断,这些统计信息是否过时。是否采样的比例太小。如果查看统计信息的采样百分比,那么可以使用下面脚本。
SELECT sch.name + '.' + so.name AS table_name
, so.object_id
, ss.name AS stat_name
, ds.stats_id
, ds.last_updated
, ds.rows
, ds.rows_sampled
, ds.rows_sampled*1.0/ds.rows *100 AS sample_rate
, ds.steps
, ds.unfiltered_rows
, ds.modification_counter
FROM sys.stats ss
JOIN sys.objects so ON ss.object_id = so.object_id
JOIN sys.schemas sch ON so.schema_id = sch.schema_id
CROSS APPLY sys.dm_db_stats_properties(ss.object_id,ss.stats_id) ds
WHERE so.name = N'pbCutClothCost'
AND LEFT(ss.name, 4) != '_WA_';
查看整个数据库的所有用户表的采样比例,可以使用下面脚本
--适应于SQL Server 2016 (13.x) SP1 CU4之前的版本
SELECT sch.name + '.' + so.name AS table_name
, so.object_id
, ss.name AS stat_name
, ds.stats_id
, ds.last_updated
, ds.rows
, ds.rows_sampled
, ds.rows_sampled*1.0/ds.rows *100 AS sample_rate
, ds.steps
, ds.unfiltered_rows
--, ds.persisted_sample_percent
, ds.modification_counter
FROM sys.stats ss
JOIN sys.objects so ON ss.object_id = so.object_id
JOIN sys.schemas sch ON so.schema_id = sch.schema_id
CROSS APPLY sys.dm_db_stats_properties(ss.object_id,ss.stats_id) ds
WHERE so.is_ms_shipped = 0
AND so.object_id NOT IN (
SELECT major_id
FROM sys.extended_properties (NOLOCK)
WHERE name = N'microsoft_database_tools_support' );
当然也可以使用DBCC SHOW_STATISTICS来查看统计信息的详细信息。
DBCC SHOW_STATISTICS ('dbo.pbCutClothCost', IX_pbCutClothCost_N1)
查看统计信息是否需要更新
判断统计信息是否过时的一个维度:统计信息最后更新的时间,通过时间维度(最后一次统计信息更新距今的时间)。这个对于下面的维度(修改的数据数量)而言,往往不是特别准确,但是也有参考意义。
SELECT
sch.name + '.' + so.name AS "Table",
ss.name AS"Statistic",
CASE
WHEN ss.auto_Created = 0 AND ss.user_created = 0 THEN 'Index Statistic'
WHEN ss.auto_created = 0 AND ss.user_created = 1 THEN 'USER Created'
WHEN ss.auto_created = 1 AND ss.user_created = 0 THEN 'Auto Created'
WHEN ss.AUTO_created = 1 AND ss.user_created = 1 THEN 'Not Possible'
END AS
"Statistic Type",
CASE
WHEN ss.has_filter = 1 THEN 'Filtered INDEX'
WHEN ss.has_filter = 0 THEN 'No Filter'
END AS "Filtered",
CASE
WHEN ss.filter_definition IS NULL THEN ''
WHEN ss.filter_definition IS NOT NULL THEN ss.filter_definition
END AS "Filter Definition",
sp.last_updated AS "Stats Last Updated",
sp.rows AS "Rows",
sp.rows_sampled AS "Rows Sampled",
sp.unfiltered_rows AS "Unfiltered Rows",
sp.modification_counter AS "Row Modifications",
sp.steps AS "Histogram Steps"
FROM sys.stats ss
JOIN sys.objects so ON ss.object_id = so.object_id
JOIN sys.schemas sch ON so.schema_id = sch.schema_id
OUTER APPLY sys.dm_db_stats_properties(so.object_id, ss.stats_id) AS sp
WHERE so.TYPE = 'U'
AND sp.last_updated < GETDATE() - 7
ORDER BY sp.last_updated DESC;
以前收集过一个查询过时的统计信息(忘记出自哪里了),自己对脚本做过调整、修改,这个是通过自上次统计信息更新以来,变化的行数超过某个阀值来判断统计信息是否过时。如下所示
Max(ApproximateRows) > 500 AND Max(RowModCtr) > (Max(ApproximateRows)*0.2 + 500 )
1:如果是SQL Server 2008 R2 SP2以上的版本,使用sys.dm_db_stats_properties的modification_counter字段值:自上次更新统计信息以来前导统计信息列(构建直方图的列)的总修改次数
2:如果是SQL Server 2008 R2 SP2之前的版本,使用sysindexes的rowmodctr字段值:对自上次更新表的统计信息后插入、删除或更新行的总数进行计数。
SET TRAN ISOLATION LEVEL READ UNCOMMITTED;
DECLARE @product_version NVARCHAR(128),
@db_version NVARCHAR(32) ,
@edition INT,
@small_edition INT,
@sql_script_index INT;
SET @product_version = CAST(SERVERPROPERTY('ProductVersion') AS NVARCHAR(128));
--版本为10.50.4000或高于这个版本使用sys.dm_db_stats_properties这个DMV,否则使用sysindexes中的rowmodctr字段
SELECT @db_version=
CASE
WHEN @product_version like '8%' THEN 'SQL2000'
WHEN @product_version like '9%' THEN 'SQL2005'
WHEN @product_version like '10.0%' THEN 'SQL2008'
WHEN @product_version like '10.5%' THEN 'SQL2008 R2'
WHEN @product_version like '11%' THEN 'SQL2012'
WHEN @product_version like '12%' THEN 'SQL2014'
WHEN @product_version like '13%' THEN 'SQL2016'
WHEN @product_version like '14%' THEN 'SQL2017'
ELSE 'unknown'
END
SET @edition= SUBSTRING(@db_version, 4, 4)
IF @edition <=2005
SET @sql_script_index=0;
ELSE IF @edition = 2008
IF @db_version ='SQL2008 R2'AND CAST(SUBSTRING(@product_version,7, 4) AS INT) >= 4000
SET @sql_script_index =1;
ELSE
SET @sql_script_index =0;
ELSE
SET @sql_script_index=1;
IF @sql_script_index = 0
BEGIN
PRINT '0'
EXEC sp_executesql N';WITH StatTables AS(
SELECT obj.schema_id AS ''schema_id''
,obj.name AS ''table_name''
,obj.object_id AS ''object_id''
,CASE INDEXPROPERTY(obj.object_id, dmv.name, ''IsStatistics'')
WHEN 0 THEN dmv.rows
ELSE (SELECT TOP 1 row_count FROM sys.dm_db_partition_stats ps (NOLOCK) WHERE ps.object_id=obj.object_id AND ps.index_id in (1,0))
END AS ''approximate_rows''
,dmv.rowmodctr AS ''row_mod_ctr''
FROM sys.objects obj (NOLOCK)
INNER JOIN sysindexes dmv (NOLOCK) ON obj.object_id = dmv.id
LEFT JOIN sys.indexes ind (NOLOCK) ON obj.object_id = ind.object_id AND obj.type in (''U'',''V'') AND ind.index_id = dmv.indid
WHERE obj.is_ms_shipped = 0 --object is not created by an internal sql server component
AND dmv.indid<>0
AND obj.object_id NOT IN (SELECT major_id FROM sys.extended_properties (NOLOCK) WHERE name = N''microsoft_database_tools_support'')
),
StatTableGrouped AS
(
SELECT
ROW_NUMBER() OVER(ORDER BY table_name) AS seq1
,ROW_NUMBER() OVER(ORDER BY table_name DESC) AS seq2
,table_name AS table_name
,CAST(MAX(approximate_rows) AS BIGINT) AS approximate_rows
,CAST(MAX(row_mod_ctr) AS BIGINT) AS row_mod_ctr
,schema_id
,object_id
FROM StatTables st
GROUP BY schema_id,object_id,table_name
HAVING (MAX(approximate_rows) > 500
AND MAX(row_mod_ctr) > (MAX(approximate_rows)*0.2 + 500 ))
)
SELECT
@@SERVERNAME AS instance_name
,seq1 + seq2 - 1 AS occurences_num
,SCHEMA_NAME(stg.schema_id) AS ''schema_name''
,stg.table_name
,CASE OBJECTPROPERTY(stg.object_id, ''TableHasClustIndex'')
WHEN 1 THEN ''Clustered''
WHEN 0 THEN ''Heap''
ELSE ''Indexed View''
END AS clustered_or_heap
,CASE OBJECTPROPERTY(stg.object_id, ''TableHasClustIndex'')
WHEN 0 THEN (SELECT COUNT(*) FROM sys.indexes i (NOLOCK) WHERE i.object_id= stg.object_id) - 1
ELSE (SELECT COUNT(*) FROM sys.indexes i (NOLOCK) WHERE i.object_id= stg.object_id)
END AS IndexCount
,(SELECT COUNT(*) FROM sys.columns c (NOLOCK) WHERE c.object_id = stg.object_id ) AS columns_count
,(SELECT COUNT(*) FROM sys.stats s (NOLOCK) WHERE s.object_id = stg.object_id) AS stats_count
,stg.approximate_rows
,stg.row_mod_ctr
,stg.schema_id
,stg.object_id
FROM StatTableGrouped stg';
END;
ELSE
BEGIN
EXEC sp_executesql N'
;WITH StatTables AS(
SELECT obj.schema_id AS schema_id
,obj.name AS table_name
,obj.object_id AS object_id
,ISNULL(sp.rows,0) AS approximate_rows
,ISNULL(sp.modification_counter,0) AS row_mod_ctr
FROM sys.objects obj (NOLOCK)
JOIN sys.stats st (NOLOCK) ON obj.object_id=st.object_id
CROSS APPLY sys.dm_db_stats_properties(obj.object_id, st.stats_id) AS sp
WHERE obj.is_ms_shipped = 0
AND st.stats_id<>0
AND obj.object_id NOT IN (
SELECT major_id FROM sys.extended_properties WITH(NOLOCK)
WHERE name = N''microsoft_database_tools_support'')
),
StatTableGrouped AS
(
SELECT
ROW_NUMBER() OVER(ORDER BY table_name) AS seq1,
ROW_NUMBER() OVER(ORDER BY table_name DESC) AS seq2,
table_name AS table_name,
CAST(MAX(approximate_rows) AS BIGINT) AS approximate_rows,
CAST(MAX(row_mod_ctr) AS BIGINT) AS row_mod_ctr,
COUNT(*) AS stats_count,
schema_id AS schema_id,
object_id AS object_id
FROM StatTables st
GROUP BY schema_id,object_id,table_name
HAVING (MAX(approximate_rows) > 500 AND Max(row_mod_ctr) > (Max(approximate_rows)*0.2 + 500 ))
)
SELECT
@@SERVERNAME AS instance_name
,seq1 + seq2 - 1 AS occurences_num
,SCHEMA_NAME(stg.schema_id) AS schema_name
,stg.table_name
,CASE OBJECTPROPERTY(stg.object_id, ''TableHasClustIndex'')
WHEN 1 THEN ''Clustered''
WHEN 0 THEN ''Heap''
ELSE ''Indexed View''
END AS clustered_or_heap
,CASE OBJECTPROPERTY(stg.object_id, ''TableHasClustIndex'')
WHEN 0 THEN (SELECT COUNT(*) FROM sys.indexes i WITH(NOLOCK) WHERE i.object_id= stg.object_id) - 1
ELSE (SELECT COUNT(*) FROM sys.indexes i WITH(NOLOCK) WHERE i.object_id= stg.object_id)
END AS IndexCount
,(SELECT COUNT(*) FROM sys.columns c (NOLOCK) WHERE c.object_id = stg.object_id ) AS columns_count
,stg.stats_count
,stg.approximate_rows
,stg.row_mod_ctr
,stg.schema_id
,stg.object_id
FROM StatTableGrouped stg';
END;
参考资料:
https://www.sqlskills.com/blogs/erin/new-statistics-dmf-in-sql-server-2008r2-sp2/
SQL Server 查找统计信息的采样时间与采样比例的更多相关文章
- Sql Server优化---统计信息维护策略
本位出处:http://www.cnblogs.com/wy123/p/5748933.html 首先解释一个概念,统计信息是什么: 简单说就是对某些字段数据分布的一种描述,让SQL Server大概 ...
- SQL SERVER的统计信息
1 什么是统计信息 统计信息 描述了 表格或者索引视图中的某些列的值 的分布情况,属于数据库对象.根据统计信息,查询优化器就能评估查询过程中需要读取的行数及结果集情况,同时也能创建高质量的查询 ...
- SQL Server 中统计信息直方图中对于没有覆盖到谓词预估以及预估策略的变化(SQL2012-->SQL2014-->SQL2016)
本位出处:http://www.cnblogs.com/wy123/p/6770258.html 统计信息写过几篇了相关的文章了,感觉还是不过瘾,关于统计信息的问题,最近又踩坑了,该问题虽然不算很常见 ...
- SQL Server 更新统计信息出现严重错误,应放弃任何可能产生的结果
一台SQL Server 2008 R2版本(具体版本如下所示)的数据库,最近几天更新统计信息的作业出错,错误如下所示: Microsoft SQL Server 2008 R2 (SP2) - ...
- SQL Server 等待统计信息基线收集
背景 我们随时监控每个服务器不同时间段的wait statistics ,可以根据监控信息大概判断什么时候开始出现异常,相当于一个wait statistics基线收集,还可以具体分析占比高的等待类型 ...
- SQL SERVER 查找锁信息
通过系统的存储过程 sp_who 或 sp_who2 可以查找出所有的锁信息, 但是看不出是哪个表, 什么语句 当使用 sp_who 或 sp_who2 查找锁信息的时候, 有个 spid 信息, ...
- c#Winform程序调用app.config文件配置数据库连接字符串 SQL Server文章目录 浅谈SQL Server中统计对于查询的影响 有关索引的DMV SQL Server中的执行引擎入门 【译】表变量和临时表的比较 对于表列数据类型选择的一点思考 SQL Server复制入门(一)----复制简介 操作系统中的进程与线程
c#Winform程序调用app.config文件配置数据库连接字符串 你新建winform项目的时候,会有一个app.config的配置文件,写在里面的<connectionStrings n ...
- 如何有效抓取SQL Server的BLOCKING信息
原文:如何有效抓取SQL Server的BLOCKING信息 转自:微软亚太区数据库技术支持组 官方博客 http://blogs.msdn.com/b/apgcdsd/archive/2011/12 ...
- sql server 查找包含字符串的对象
sql server 查找包含字符串的对象 SELECT sm.object_id, OBJECT_NAME(sm.object_id) AS object_name, o.type, o.type_ ...
随机推荐
- Git的思想和基本工作原理2
那么,简单地说,Git 究竟是怎样的一个系统呢?请注意,接下来的内容非常重要,若是理解了 Git 的思想和基本工作原理,用起来就会知其所以然,游刃有余. 在开始学习 Git 的时候,请不要尝试把各种概 ...
- Tiny4412 烧写uboot到emmc步骤
将uboot写入emmc,并通过EMMC驱动,不在只用SD卡启动 烧写uboot的之前用如下命令查看EMMC卡信息及分区信息: mmcinfo 0: 查看mmc卡信息, 0表示SD卡:1表示emmc卡 ...
- Windows Server 2008取消登录前的Ctrl+Alt+Delete组合键操作
前言: 在Windows Server 2008服务器中,为了防止人们登录服务器时错误的将账户和密码输入其他地方导致信息泄漏,所以在我们登录Windows Server 2008服务器操作系统时会要求 ...
- 这样入门asp.net core 之 静态文件
本文章主要说明asp.net core中静态资源处理方案: 一.静态文件服务 首先明确contentRoot和webroot这两个概念 contentRoot:web的项目文件夹,其中包含webroo ...
- redis与python交互
import redis #连接 r=redis.StrictRedis(host="localhost",port=6379,password="sunck" ...
- iOS推送:Java服务器端发送表情(绘文字)
http://blog.csdn.net/musou_ldns/article/details/8692520 功能的时候,客户要求能够给iphone发送表情图标,也就是绘文字. 手机环境:iOS5. ...
- Android 手势检测实战 打造支持缩放平移的图片预览效果(下)
转载请标明出处:http://blog.csdn.net/lmj623565791/article/details/39480503,本文出自:[张鸿洋的博客] 上一篇已经带大家实现了自由的放大缩小图 ...
- vs插件-基于TFS的源码记录可视化
插件地址:https://marketplace.visualstudio.com/items?itemName=AlexandrBiryukov.TFSSourceControlHistoryVis ...
- 理解Go Context机制
1 什么是Context 最近在公司分析gRPC源码,proto文件生成的代码,接口函数第一个参数统一是ctx context.Context接口,公司不少同事都不了解这样设计的出发点是什么,其实我也 ...
- BZOJ_2679_[Usaco2012 Open]Balanced Cow Subsets _meet in middle+双指针
BZOJ_2679_[Usaco2012 Open]Balanced Cow Subsets _meet in middle+双指针 Description Farmer John's owns N ...