RDD概念、特性、缓存策略与容错
一、RDD概念与特性
1. RDD的概念
RDD(Resilient Distributed Dataset),是指弹性分布式数据集。数据集:Spark中的编程是基于RDD的,将原始数据加载到内存变成RDD,RDD再经过若干次转化,仍为RDD。分布式:读数据一般都是从分布式系统中去读,如hdfs、kafka等,所以原始文件存在磁盘是分布式的,spark加载完数据的RDD也是分布式的,换句话说RDD是抽象的概念,实际数据仍在分布式文件系统中;因为有了RDD,在开发代码过程会非常方便,只需要将原始数据理解为一个集合,然后对集合进行操作即可。RDD里面每一块数据/partition,分布在某台机器的物理节点上,这是物理概念。弹性:这里是指数据集会进行转换,所以会忽大忽小,partition数量忽多忽少。
2. RDD的特性
Spark-1.6.1源码在org.apache.spark.rdd下的RDD.scala指出了每一个RDD都具有五个主要特点,如下:

- A list of partion
RDD是由一组partition组成。例如要读取hdfs上的文本文件的话,可以使用textFile()方法把hdfs的文件加载过来,把每台机器的数据放到partition中,并且封装了一个HadoopRDD,这就是一个抽象的概念。每一个partition都对应了机器中的数据。因为在hdfs中的一个Datanode,有很多的block,读机器的数据时,会将每一个block变成一个partition,与MapReduce中split的大小由min split,max split,block size (max(min split, min(max split, block size)))决定的相同,spark中的partition大小实际上对应了一个split的大小。经过转化,HadoopRDD会转成其他RDD,如FilteredRDD、PairRDD等,但是partition还是相应的partition,只是因为有函数应用里面的数据变化了。
- A function for computing each split
对每个split(partition)都有函数操作。一个函数应用在一个RDD上,可以理解为一个函数对集合(RDD)内的每个元素(split)的操作。
- A list of dependencies on other RDDs
一个RDD依赖于一组RDD。例如,下列代码片段
val lines=sc.textFlie("hdfs://namenode:8020/path/file.txt")
val wc=lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).sortBy(_._2)
wc.foreach(println)
sc.stop()
这里就存在RDD的依赖关系。
- Optionally, a Partitioner for key-value RDDs
该可选项意思是对于一个RDD,如果其中的每一个元素是Key-Value形式时,可以传一个Partitioner(自定义分区),让这个RDD重新分区。这种情况的本质是shuffle,多点到多点的数据传输。
- Optionally, a list of preferred locations to compute each split on
textFile()过程中,可以指定加载到性能好的机器中。例如,hdfs中的数据可能放在一大堆破旧的机器上,hdfs数据在磁盘上,磁盘可能很大,CPU、内存的性能很差。Spark默认做的事情是,把数据加载进来,会把数据抽象成一个RDD,抽象进来的数据在内存中,这内存指的是本机的内存,这是因为在分布式文件系统中,要遵循数据本地性原则,即移动计算(把函数、jar包发过去)而不移动数据(移动数据成本较高)。而一般hdfs的集群机器的内存比较差,如果要把这么多数据加载到烂机器的内存中,会存在问题,一是内存可能装不下,二是CPU差、计算能力差,这就等于没有发挥出spark的性能。在这种情况下,Spark的RDD可以提供一个可选项,可以指定一个preferred locations,即指定一个位置来加载数据。这样就可以指定加载到性能好的机器去计算。例如,可以将hdfs数据加载到Tachyon内存文件系统中,然后再基于Tachyon来做spark程序。
二、RDD缓存策略
1. 源码
源码org.apache.spark.storage包下的StorageLevel.scala中定义缓存策略。
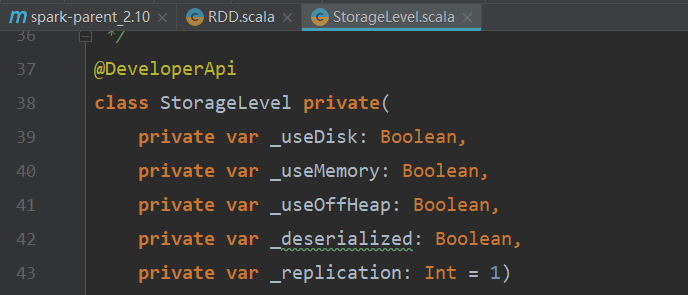
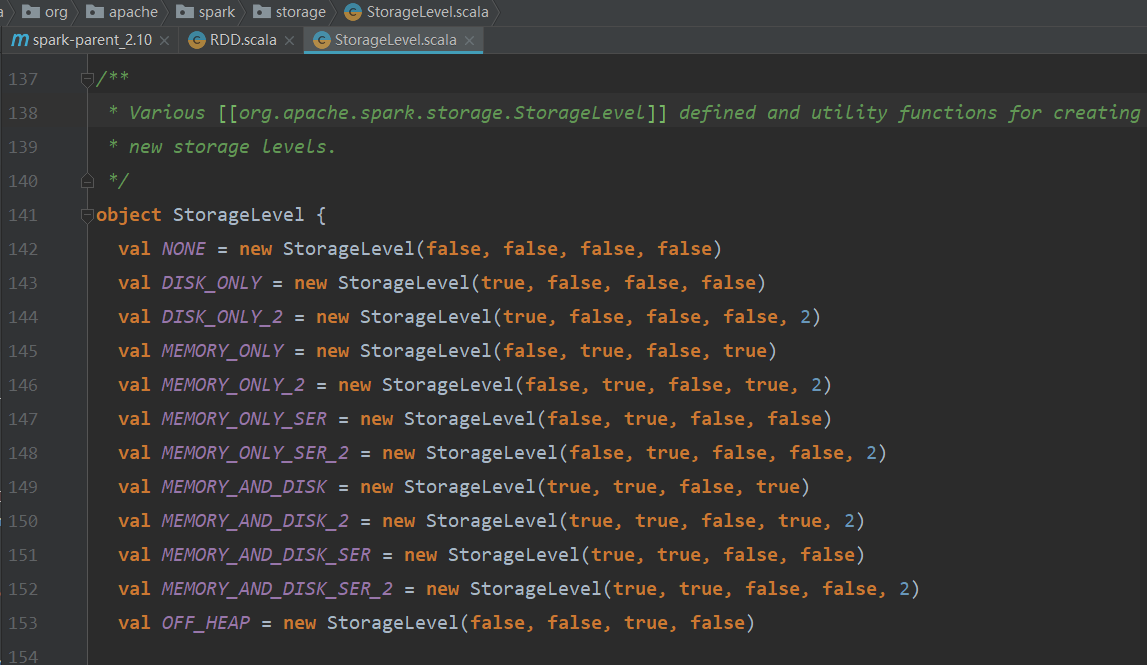
StorageLevel类默认的构造器有五个属性,如下图所示:
2. 源码解读
- StorageLevel私有类的构造器
class StorageLevel private(
private var _useDisk: Boolean,/*使用磁盘*/
private var _useMemory: Boolean,/*使用内存*/
private var _useOffHeap: Boolean,/*不使用堆内存(堆在JVM中)*/
private var _deserialized: Boolean,/*不序列化*/
private var _replication: Int = 1)/*副本数,默认为1*/
- NONE
val NONE = new StorageLevel(false, false, false, false)
NONE表示不需要缓存。(不使用磁盘,不用内存,使用堆,序列化)
- DISK_ONLY
val DISK_ONLY = new StorageLevel(true, false, false, false)
DISK_ONLY表示使用磁盘。(使用磁盘,不用内存,使用堆,序列化)
- DISK_ONLY_2
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
DISK_ONLY_2表示使用磁盘,两个副本。(使用磁盘,不用内存,使用堆,序列化,2)
- MEMORY_ONLY
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
MEMORY_ONLY表示只使用内存,例如1G的数据要放入512M的内存,会将数据切成两份,先将512M加载到内存,剩下的512M还在原来位置(如hdfs),之后如果有RDD的运算,会从内存和磁盘中去找各自的512M数据。(不使用磁盘,使用内存,使用堆,不序列化)
- MEMORY_ONLY_2
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
MEMORY_ONLY_2表示只使用内存,2个副本。(不使用磁盘,使用内存,使用堆,不序列化,2)
- MEMORY_ONLY_SER
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
MEMORY_ONLY_SER表示只使用内存,序列化。(不使用磁盘,使用内存,使用堆,序列化)
- MEMORY_ONLY_SER_2
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
MEMORY_ONLY_SER表示只使用内存,序列化,2个副本。(不使用磁盘,使用内存,使用堆,序列化,2)
- MEMORY_AND_DISK
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
MEMORY_AND_DISK和MEMORY_ONLY很类似,都使用到了内存和磁盘,只是使用的是本机本地磁盘,例如1G数据要加载到512M的内存中,首先将hdfs的1G数据的512M加载到内存,另外的512M加载到本地的磁盘缓存着(和hdfs就没有关系了),RDD要读取数据的话就在内存和本地磁盘中找。(使用磁盘,使用内存,使用堆,不序列化)
- MEMORY_AND_DISK_2
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
MEMORY_AND_DISK_2表示两个副本。(使用磁盘,使用内存,使用堆,不序列化,2)
- MEMORY_AND_DISK_SER
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
MEMORY_AND_DISK_SER本地内存和磁盘,序列化。序列化的好处在于可以压缩,但是压缩就意味着要解压缩,需要消耗一些CPU。
- MEMORY_AND_DISK_SER_2
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
MEMORY_AND_DISK_SER2,两个副本。
- OFF_HEAP
val OFF_HEAP = new StorageLevel(false, false, true, false)
OFF_HEAP不使用堆内存(例如可以使用Tachyon的分布式内存文件系统)。(不使用磁盘,不用内存,不使用堆,序列化)
3. 缓存策略试验
- 不缓存
package com.huidoo.spark
import org.apache.spark.{SparkConf, SparkContext}
object TestCache {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("TestCache").setMaster("local[2]")
val sc = new SparkContext(conf)
val lines = sc.textFile("hdfs://cdh01:8020/flume/2018-03-23/2230") //目录下有17个文件,总大小约为335MB,不做缓存
val beginTime1 = System.currentTimeMillis() //记录第1个job开始时间
val count1 = lines.count() //调用count()方法,会产生一个job
val endTime1 = System.currentTimeMillis() //记录第1个job结束时间
val beginTime2 = System.currentTimeMillis() //记录第2个job开始时间
val count2 = lines.count() //调用count()方法,会产生一个job
val endTime2 = System.currentTimeMillis() //记录第2个job结束时间
println(count1)
println("第1个job总共消耗时间" + (endTime1 - beginTime1) + "毫秒")
println(count2)
println("第2个job总共消耗时间" + (endTime2 - beginTime2) + "毫秒")
sc.stop()
}
}
运行结果如下:

可见,所有文件的总行数为1935077行,第一个job和第二个job的用时分别为14.7s和12.2s,差别不大。
- 缓存
只需在原代码基础上将HadoopRDD lines添加调用cache()方法即可。
val lines = sc.textFile("hdfs://cdh01:8020/flume/2018-03-23/2230").cache() //目录下有17个文件,总大小约为335MB,做缓存
运行结果如下:
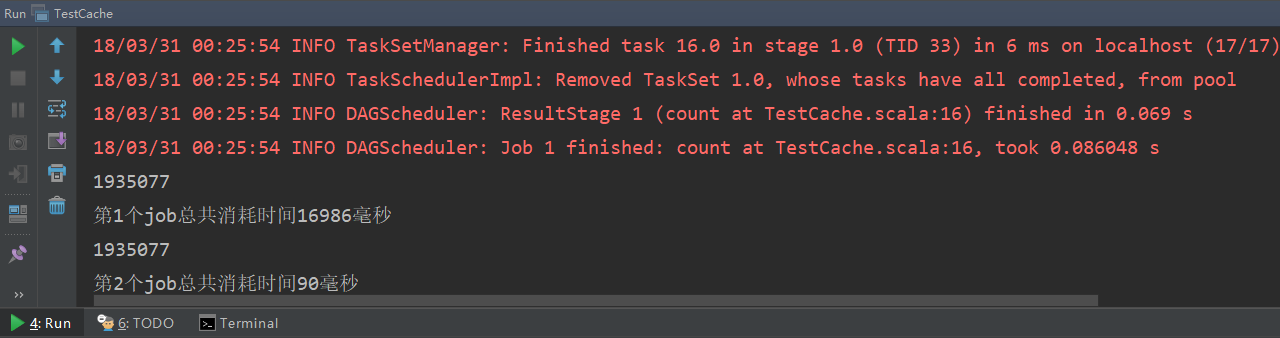
可见,所有文件的总行数为1935077行,第一个job和第二个job的用时分别为19.4s和0.09s,速度相比不做缓存明显提升。这是因为没有做缓存,第二个job还需要先从hdfs上读取数据,需要消耗更长时间;而做了缓存则直接从缓存中读取(cache方法默认缓存策略是MEMORY_ONLY),所以速度会快很多。
三、RDD Lineage与容错
1. Lineage(血统)
一系列RDD到RDD的transformation操作,称为lineage(血统)。某个RDD依赖于它前面的所有RDD。例如一个由10个RDD到RDD的转化构成的lineage,如果在计算到第9个RDD时失败了,一般较好的计算框架会自动重新计算。一般地,这种错误发生了会去找上一个RDD,但是实际上如果不做缓存是找不到的,因为即使RDD9知道它是由RDD8转化过来的,但是因为它并没有存RDD数据本身,在内存中RDD瞬时转化,瞬间就会在内存中消失,所以还是找不到数据。如果这时RDD8做过cache缓存,那么就是在RDD8的时候进行了数据的保存并记录了位置,这时如果RDD9失败了就会从缓存中读取RDD8的数据;如果RDD8没有做cache就会找RDD7,以此类推,如果都没有做cache就需要重新从HDFS中读取数据。所以所谓的容错就是指,当计算过程复杂,为了降低因某些关键点计算出错而需要重新计算的带来的惨重代价的风险,则需要在某些关键点使用cache或用persist方法做一下缓存。
2. 容错
- 容错理论
上述缓存策略还存在一个问题。使用cache或persist的缓存策略是使用默认的仅在内存,所以实际的RDD缓存位置是在内存当中,如果机器出现问题,也会造成内存中的缓存RDD数据丢失。所以可以将要做容错的RDD数据存到指定磁盘(可以是hdfs)路径中,可以对RDD做doCheckpoint()方法。使用doCheckpoint()方法的前提示,需要在sc中要先设置SparkContext.setCheckpointDir(),设置数据存储路径。这时候如果程序计算过程中出错了,会先到cache中找缓存数据,如果cache中没有就会到设置的磁盘路径中找。
在RDD计算,通过checkpoint进行容错,做checkpoint有两种方式,一个是checkpoint data,一个是logging the updates。用户可以控制采用哪种方式来实现容错,默认是logging the updates方式,通过记录跟踪所有生成RDD的转换(transformations)也就是记录每个RDD的lineage(血统)来重新计算生成丢失的分区数据。
- 容错源码解读
//RDD.scala中的doCheckpoint方法:
/**
* Performs the checkpointing of this RDD by saving this. It is called after a job using this RDD
* has completed (therefore the RDD has been materialized and potentially stored in memory).
* doCheckpoint() is called recursively on the parent RDDs.
*/
private[spark] def doCheckpoint(): Unit = { RDDOperationScope.withScope(sc, "checkpoint", allowNesting = false, ignoreParent = true) {
//如果doCheckpointCalled不为true,就先将其改为true
if (!doCheckpointCalled) {
doCheckpointCalled = true
//如果checkpointData已定义,就把data get出来,然后做一下checkpoint。
if (checkpointData.isDefined) {
checkpointData.get.checkpoint()
} else {
//如果checkpointData没有的话,就把这个RDD的所有依赖拿出来,foreach一把,把里面的每个元素RDD,再递归调用本方法。
dependencies.foreach(_.rdd.doCheckpoint())
}
}
}
}
//RDD.scala中的checkpoint()方法
def checkpoint(): Unit = RDDCheckpointData.synchronized {
// NOTE: we use a global lock here due to complexities downstream with ensuring
// children RDD partitions point to the correct parent partitions. In the future
// we should revisit this consideration.
//首先检查context的checkpointDir是否为空,如果没有设置就会抛出异常
if (context.checkpointDir.isEmpty) {
throw new SparkException("Checkpoint directory has not been set in the SparkContext")
} else if (checkpointData.isEmpty) {
checkpointData = Some(new ReliableRDDCheckpointData(this))
}
}
//SparkContext.scala中的setCheckpointDir方法
/**
* Set the directory under which RDDs are going to be checkpointed. The directory must
* be a HDFS path if running on a cluster.
*/
def setCheckpointDir(directory: String) { // If we are running on a cluster, log a warning if the directory is local.
// Otherwise, the driver may attempt to reconstruct the checkpointed RDD from
// its own local file system, which is incorrect because the checkpoint files
// are actually on the executor machines.
//如果运行了集群模式,checkpointDir必须是非本地的。
if (!isLocal && Utils.nonLocalPaths(directory).isEmpty) {
logWarning("Checkpoint directory must be non-local " +
"if Spark is running on a cluster: " + directory)
} checkpointDir = Option(directory).map { dir =>
val path = new Path(dir, UUID.randomUUID().toString)
val fs = path.getFileSystem(hadoopConfiguration)
fs.mkdirs(path)
fs.getFileStatus(path).getPath.toString
}
}
RDD概念、特性、缓存策略与容错的更多相关文章
- RDD缓存策略
Spark支持将数据集放置在集群的缓存中,以便于数据重用. Spark缓存策略对应的类: class StorageLevel private( private var useDisk_ : Bool ...
- 第1章 RDD概念 弹性分布式数据集
第1章 RDD概念 弹性分布式数据集 1.1 RDD为什么会产生 RDD是Spark的基石,是实现Spark数据处理的核心抽象.那么RDD为什么会产生呢? Hadoop的MapReduce是一种基于 ...
- Web缓存基础:术语、HTTP报头和缓存策略
简介 对于您的站点的访问者来说,智能化的内容缓存是提高用户体验最有效的方式之一.缓存,或者对之前的请求的临时存储,是HTTP协议实现中最核心的内容分发策略之一.分发路径中的组件均可以缓存内容来加速后续 ...
- 【转】理解Java Integer的缓存策略
本文将介绍 Java 中 Integer 缓存的相关知识.这是 Java 5 中引入的一个有助于节省内存.提高性能的特性.首先看一个使用 Integer 的示例代码,展示了 Integer 的缓存行为 ...
- Web开发基本准则-55实录-缓存策略
续上篇<Web开发基本准则-55实录-Web访问安全>. Web开发基本准则-55实录-缓存策略 郑昀 创建于2013年2月 郑昀 最后更新于2013年10月26日 提纲: Web访问安全 ...
- 理解Java Integer的缓存策略
转载自http://www.importnew.com/18884.html 本文将介绍 Java 中 Integer 缓存的相关知识.这是 Java 5 中引入的一个有助于节省内存.提高性能的特性. ...
- .net 4.0 自定义本地缓存策略的不同实现
在分布式系统的开发中,为了提高系统运行性能,我们从服务器中获取的数据需要缓存在本地,以便下次使用,而不用从服务器中重复获取,有同学可能要问,为什么不使用 分布式缓存等,注意,服务器端肯定是考虑到扩展, ...
- HTTP1.1缓存策略
以下是一幅虽然信息包含量有限.但足够以最简洁的方式说明了“什么是HTTP1.1缓存策略”的图 缓存和缓存策略 web缓存(web cache)或代理缓存(proxy cache)是一种特殊的HTTP ...
- ExoPlayer Talk 01 缓存策略分析与优化
操作系统:Windows8.1 显卡:Nivida GTX965M 开发工具:Android studio 2.3.3 | ExoPlayer r2.5.1 使用 ExoPlayer已经有一段时间了, ...
随机推荐
- Linux显示cat帮助信息并退出
Linux显示cat帮助信息并退出 youhaidong@youhaidong-ThinkPad-Edge-E545:~$ cat --help 用法:cat [选项]... [文件]... 将[文件 ...
- RHEL64 缺少ISO 9660图像 安装程序试图挂载映像#1,在硬盘上无法找到该映像
用光盘安装Linux,很容易,按照提示一步一步就好.如果没有光驱,只好想办法用硬盘或者U盘安装了. 首先说说怎样用U盘启动Linux的安装程序:1.将ISO镜像文件拷贝到U盘中,并解压到U盘根目录.将 ...
- hdu5925 Coconuts
比完看acdream说这题是签到题 怎么都不会写 我现在补完也觉得 这不是傻逼题么 我我这个这么快5题的人真的不应该啊 #include<bits/stdc++.h> using name ...
- lightoj 1025 区间dp
#include<bits/stdc++.h> using namespace std; typedef long long ll; char a[70]; ll dp[70][70]; ...
- python 字符串格式化输出 %d,%s及 format函数
旧式格式化方式:%s,%d 1.顺序填入格式化内容 s = "hello %s, hello %d"%("world", 100) print(s) 结果: ' ...
- SpringMVC国际化支持
这周公司领导希望我对一个项目,出一个国际化的解决方案,研究两个小时,采用了SpringMVC的国际化支持,在此记录下. 原理: 在DispatchServlet中注册localeResolver(区域 ...
- [APIO2009]会议中心
[APIO2009]会议中心 题目大意: 原网址与样例戳我! 给定n个区间,询问以下问题: 1.最多能够选择多少个不相交的区间? 2.在第一问的基础上,输出字典序最小的方案. 数据范围:\(n \le ...
- golang 互斥锁和读写锁
golang 互斥锁和读写锁 golang中sync包实现了两种锁Mutex(互斥锁)和RWMutex(读写锁),其中RWMutex是基于Mutex实现的,只读锁的实现使用类似引用计数器的功能. ty ...
- linux 添加ftp用户与登录配置详解
不同类Unix有一定区别 版本不同也有些区别 在linux主机上如何添加ftp用户 (一)修改配置文件 vi /etc/vsftpd/vsftpd.conf 在96行,97,98行 96 chroot ...
- python 批量删除mysql前缀相同的表
1,一般游戏log数据库会存储大量的玩家行为日志,一种行为一张表,每天生成一张新表,一天会有30+张不同行为的表,通常会保留玩家日志1年左右,对于超过1年的日志需要删除 2,log数据库一年会保存1W ...