Hive学习之路 (十二)Hive SQL练习之影评案例
案例说明
现有如此三份数据:
1、users.dat 数据格式为: 2::M::56::16::70072,
共有6040条数据
对应字段为:UserID BigInt, Gender String, Age Int, Occupation String, Zipcode String
对应字段中文解释:用户id,性别,年龄,职业,邮政编码
2、movies.dat 数据格式为: 2::Jumanji (1995)::Adventure|Children's|Fantasy,
共有3883条数据
对应字段为:MovieID BigInt, Title String, Genres String
对应字段中文解释:电影ID,电影名字,电影类型
3、ratings.dat 数据格式为: 1::1193::5::978300760,
共有1000209条数据
对应字段为:UserID BigInt, MovieID BigInt, Rating Double, Timestamped String
对应字段中文解释:用户ID,电影ID,评分,评分时间戳
题目要求
数据要求:
(1)写shell脚本清洗数据。(hive不支持解析多字节的分隔符,也就是说hive只能解析':', 不支持解析'::',所以用普通方式建表来使用是行不通的,要求对数据做一次简单清洗)
(2)使用Hive能解析的方式进行
Hive要求:
(1)正确建表,导入数据(三张表,三份数据),并验证是否正确
(2)求被评分次数最多的10部电影,并给出评分次数(电影名,评分次数)
(3)分别求男性,女性当中评分最高的10部电影(性别,电影名,影评分)
(4)求movieid = 2116这部电影各年龄段(因为年龄就只有7个,就按这个7个分就好了)的平均影评(年龄段,影评分)
(5)求最喜欢看电影(影评次数最多)的那位女性评最高分的10部电影的平均影评分(观影者,电影名,影评分)
(6)求好片(评分>=4.0)最多的那个年份的最好看的10部电影
(7)求1997年上映的电影中,评分最高的10部Comedy类电影
(8)该影评库中各种类型电影中评价最高的5部电影(类型,电影名,平均影评分)
(9)各年评分最高的电影类型(年份,类型,影评分)
(10)每个地区最高评分的电影名,把结果存入HDFS(地区,电影名,影评分)
数据下载
https://files.cnblogs.com/files/qingyunzong/hive%E5%BD%B1%E8%AF%84%E6%A1%88%E4%BE%8B.zip
解析
之前已经使用MapReduce程序将3张表格进行合并,所以只需要将合并之后的表格导入对应的表中进行查询即可。
1、正确建表,导入数据(三张表,三份数据),并验证是否正确
(1)分析需求
需要创建一个数据库movie,在movie数据库中创建3张表,t_user,t_movie,t_rating
t_user:userid bigint,sex string,age int,occupation string,zipcode string
t_movie:movieid bigint,moviename string,movietype string
t_rating:userid bigint,movieid bigint,rate double,times string
原始数据是以::进行切分的,所以需要使用能解析多字节分隔符的Serde即可
使用RegexSerde
需要两个参数:
input.regex = "(.*)::(.*)::(.*)"
output.format.string = "%1$s %2$s %3$s"
(2)创建数据库
drop database if exists movie;
create database if not exists movie;
use movie;
(3)创建t_user表
create table t_user(
userid bigint,
sex string,
age int,
occupation string,
zipcode string)
row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe'
with serdeproperties('input.regex'='(.*)::(.*)::(.*)::(.*)::(.*)','output.format.string'='%1$s %2$s %3$s %4$s %5$s')
stored as textfile;
(4)创建t_movie表
use movie;
create table t_movie(
movieid bigint,
moviename string,
movietype string)
row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe'
with serdeproperties('input.regex'='(.*)::(.*)::(.*)','output.format.string'='%1$s %2$s %3$s')
stored as textfile;
(5)创建t_rating表
use movie;
create table t_rating(
userid bigint,
movieid bigint,
rate double,
times string)
row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe'
with serdeproperties('input.regex'='(.*)::(.*)::(.*)::(.*)','output.format.string'='%1$s %2$s %3$s %4$s')
stored as textfile;
(6)导入数据
0: jdbc:hive2://hadoop3:10000> load data local inpath "/home/hadoop/movie/users.dat" into table t_user;
No rows affected (0.928 seconds)
0: jdbc:hive2://hadoop3:10000> load data local inpath "/home/hadoop/movie/movies.dat" into table t_movie;
No rows affected (0.538 seconds)
0: jdbc:hive2://hadoop3:10000> load data local inpath "/home/hadoop/movie/ratings.dat" into table t_rating;
No rows affected (0.963 seconds)
0: jdbc:hive2://hadoop3:10000>
(7)验证
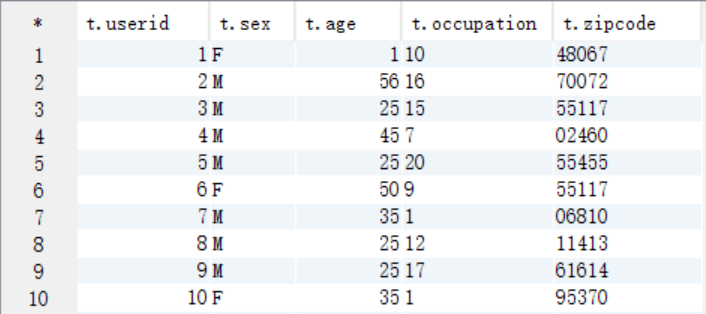
select t.* from t_user t;
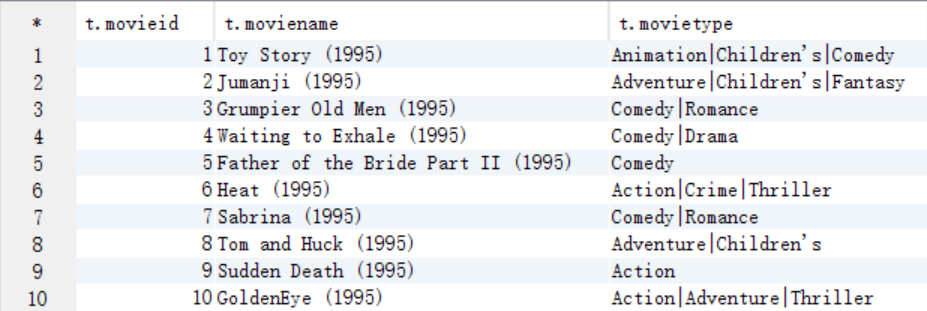
select t.* from t_movie t;
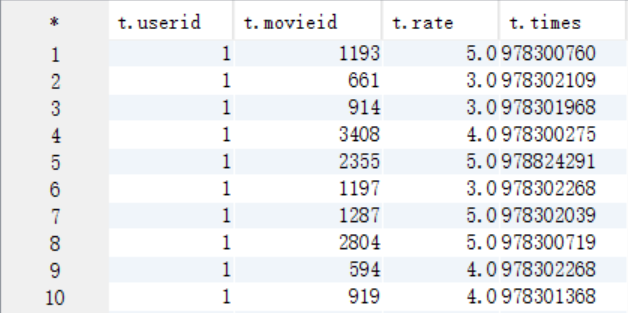
select t.* from t_rating t;
2、求被评分次数最多的10部电影,并给出评分次数(电影名,评分次数)
(1)思路分析:
1、需求字段:电影名 t_movie.moviename
评分次数 t_rating.rate count()
2、核心SQL:按照电影名进行分组统计,求出每部电影的评分次数并按照评分次数降序排序
(2)完整SQL:
create table answer2 as
select a.moviename as moviename,count(a.moviename) as total
from t_movie a join t_rating b on a.movieid=b.movieid
group by a.moviename
order by total desc
limit 10;
select * from answer2;

3、分别求男性,女性当中评分最高的10部电影(性别,电影名,影评分)
(1)分析思路:
1、需求字段:性别 t_user.sex
电影名 t_movie.moviename
影评分 t_rating.rate
2、核心SQL:三表联合查询,按照性别过滤条件,电影名作为分组条件,影评分作为排序条件进行查询
(2)完整SQL:
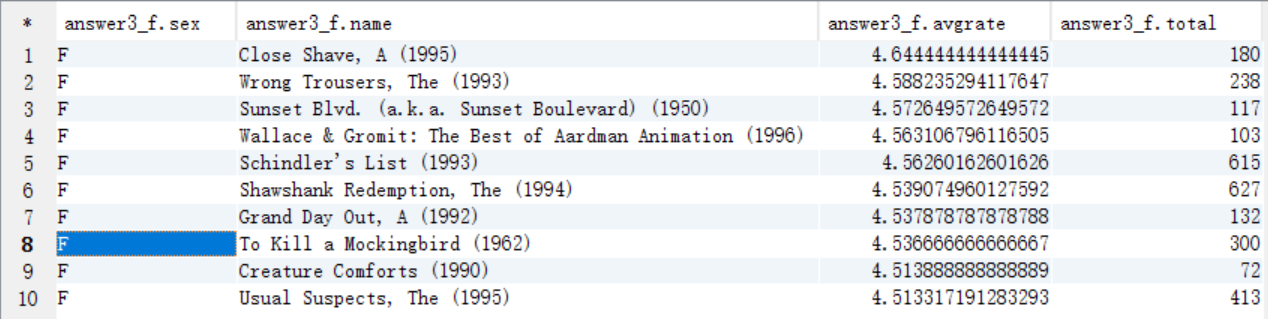
女性当中评分最高的10部电影(性别,电影名,影评分)评论次数大于等于50次
create table answer3_F as
select "F" as sex, c.moviename as name, avg(a.rate) as avgrate, count(c.moviename) as total
from t_rating a
join t_user b on a.userid=b.userid
join t_movie c on a.movieid=c.movieid
where b.sex="F"
group by c.moviename
having total >= 50
order by avgrate desc
limit 10;
select * from answer3_F;
男性当中评分最高的10部电影(性别,电影名,影评分)评论次数大于等于50次
create table answer3_M as
select "M" as sex, c.moviename as name, avg(a.rate) as avgrate, count(c.moviename) as total
from t_rating a
join t_user b on a.userid=b.userid
join t_movie c on a.movieid=c.movieid
where b.sex="M"
group by c.moviename
having total >= 50
order by avgrate desc
limit 10;
select * from answer3_M;

4、求movieid = 2116这部电影各年龄段(因为年龄就只有7个,就按这个7个分就好了)的平均影评(年龄段,影评分)
(1)分析思路:
1、需求字段:年龄段 t_user.age
影评分 t_rating.rate
2、核心SQL:t_user和t_rating表进行联合查询,用movieid=2116作为过滤条件,用年龄段作为分组条件
(2)完整SQL:
create table answer4 as
select a.age as age, avg(b.rate) as avgrate
from t_user a join t_rating b on a.userid=b.userid
where b.movieid=2116
group by a.age;
select * from answer4;
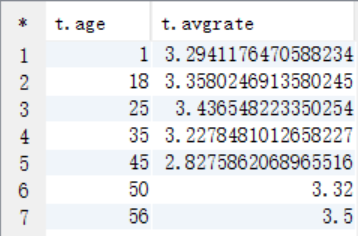
5、求最喜欢看电影(影评次数最多)的那位女性评最高分的10部电影的平均影评分(观影者,电影名,影评分)
(1)分析思路:
1、需求字段:观影者 t_rating.userid
电影名 t_movie.moviename
影评分 t_rating.rate
2、核心SQL:
A. 需要先求出最喜欢看电影的那位女性
需要查询的字段:性别:t_user.sex
观影次数:count(t_rating.userid)
B. 根据A中求出的女性userid作为where过滤条件,以看过的电影的影评分rate作为排序条件进行排序,求出评分最高的10部电影
需要查询的字段:电影的ID:t_rating.movieid
C. 求出B中10部电影的平均影评分
需要查询的字段:电影的ID:answer5_B.movieid
影评分:t_rating.rate
(2)完整SQL:
A. 需要先求出最喜欢看电影的那位女性
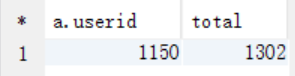
select a.userid, count(a.userid) as total
from t_rating a join t_user b on a.userid = b.userid
where b.sex="F"
group by a.userid
order by total desc
limit 1;
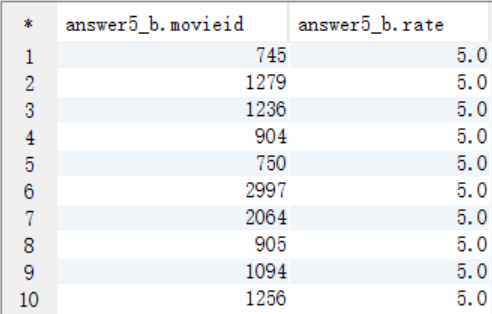
B. 根据A中求出的女性userid作为where过滤条件,以看过的电影的影评分rate作为排序条件进行排序,求出评分最高的10部电影
create table answer5_B as
select a.movieid as movieid, a.rate as rate
from t_rating a
where a.userid=1150
order by rate desc
limit 10;
select * from answer5_B;
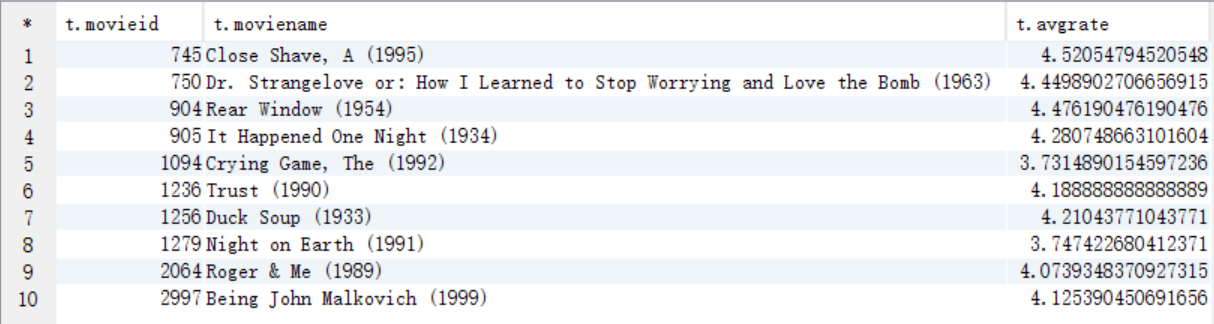
C. 求出B中10部电影的平均影评分
create table answer5_C as
select b.movieid as movieid, c.moviename as moviename, avg(b.rate) as avgrate
from answer5_B a
join t_rating b on a.movieid=b.movieid
join t_movie c on b.movieid=c.movieid
group by b.movieid,c.moviename;
select * from answer5_C;
6、求好片(评分>=4.0)最多的那个年份的最好看的10部电影
(1)分析思路:
1、需求字段:电影id t_rating.movieid
电影名 t_movie.moviename(包含年份)
影评分 t_rating.rate
上映年份 xxx.years
2、核心SQL:
A. 需要将t_rating和t_movie表进行联合查询,将电影名当中的上映年份截取出来,保存到临时表answer6_A中
需要查询的字段:电影id t_rating.movieid
电影名 t_movie.moviename(包含年份)
影评分 t_rating.rate
B. 从answer6_A按照年份进行分组条件,按照评分>=4.0作为where过滤条件,按照count(years)作为排序条件进行查询
需要查询的字段:电影的ID:answer6_A.years
C. 从answer6_A按照years=1998作为where过滤条件,按照评分作为排序条件进行查询
需要查询的字段:电影的ID:answer6_A.moviename
影评分:answer6_A.avgrate
(2)完整SQL:
A. 需要将t_rating和t_movie表进行联合查询,将电影名当中的上映年份截取出来
create table answer6_A as
select a.movieid as movieid, a.moviename as moviename, substr(a.moviename,-5,4) as years, avg(b.rate) as avgrate
from t_movie a join t_rating b on a.movieid=b.movieid
group by a.movieid, a.moviename;
select * from answer6_A;
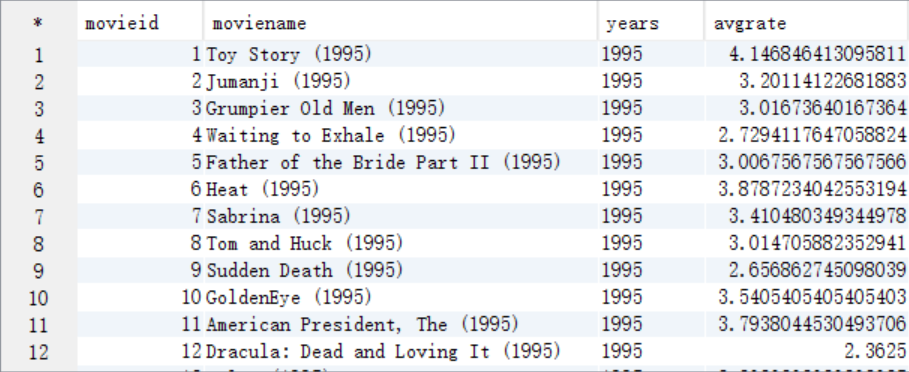
B. 从answer6_A按照年份进行分组条件,按照评分>=4.0作为where过滤条件,按照count(years)作为排序条件进行查询
select years, count(years) as total
from answer6_A a
where avgrate >= 4.0
group by years
order by total desc
limit 1;
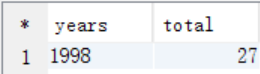
C. 从answer6_A按照years=1998作为where过滤条件,按照评分作为排序条件进行查询
create table answer6_C as
select a.moviename as name, a.avgrate as rate
from answer6_A a
where a.years=1998
order by rate desc
limit 10;
select * from answer6_C;
7、求1997年上映的电影中,评分最高的10部Comedy类电影
(1)分析思路:
1、需求字段:电影id t_rating.movieid
电影名 t_movie.moviename(包含年份)
影评分 t_rating.rate
上映年份 xxx.years(最终查询结果可不显示)
电影类型 xxx.type(最终查询结果可不显示)
2、核心SQL:
A. 需要电影类型,所有可以将第六步中求出answer6_A表和t_movie表进行联合查询
需要查询的字段:电影id answer6_A.movieid
电影名 answer6_A.moviename
影评分 answer6_A.rate
电影类型 t_movie.movietype
上映年份 answer6_A.years
B. 从answer7_A按照电影类型中是否包含Comedy和按上映年份作为where过滤条件,按照评分作为排序条件进行查询,将结果保存到answer7_B中
需要查询的字段:电影的ID:answer7_A.id
电影的名称:answer7_A.name
电影的评分:answer7_A.rate
(2)完整SQL:
A. 需要电影类型,所有可以将第六步中求出answer6_A表和t_movie表进行联合查询
create table answer7_A as
select b.movieid as id, b.moviename as name, b.years as years, b.avgrate as rate, a.movietype as type
from t_movie a join answer6_A b on a.movieid=b.movieid;
select t.* from answer7_A t;
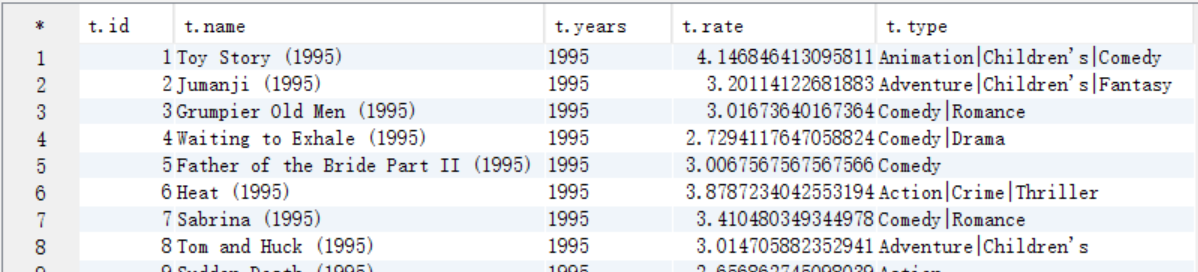
B. 从answer7_A按照电影类型中是否包含Comedy和按照评分>=4.0作为where过滤条件,按照评分作为排序条件进行查询,将结果保存到answer7_B中
create table answer7_B as
select t.id as id, t.name as name, t.rate as rate
from answer7_A t
where t.years=1997 and instr(lcase(t.type),'comedy') >0
order by rate desc
limit 10;
select * from answer7_B;
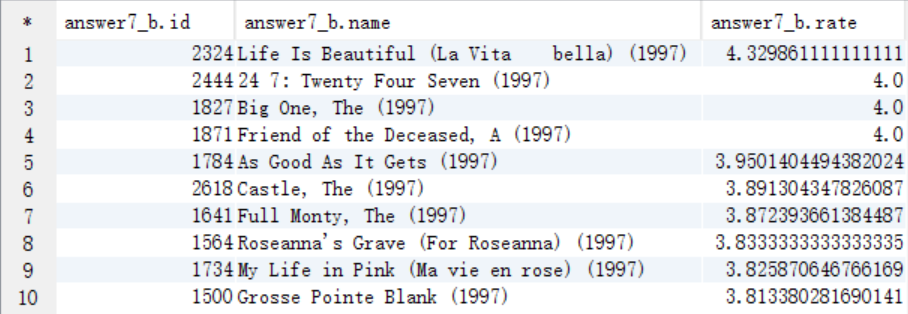
8、该影评库中各种类型电影中评价最高的5部电影(类型,电影名,平均影评分)
(1)分析思路:
1、需求字段:电影id movieid
电影名 moviename
影评分 rate(排序条件)
电影类型 type(分组条件)
2、核心SQL:
A. 需要电影类型,所有需要将answer7_A中的type字段进行裂变,将结果保存到answer8_A中
需要查询的字段:电影id answer7_A.id
电影名 answer7_A.name(包含年份)
上映年份 answer7_A.years
影评分 answer7_A.rate
电影类型 answer7_A.movietype
B. 求TopN,按照type分组,需要添加一列来记录每组的顺序,将结果保存到answer8_B中
row_number() :用来生成 num字段的值
distribute by movietype :按照type进行分组
sort by avgrate desc :每组数据按照rate排降序
num:新列, 值就是每一条记录在每一组中按照排序规则计算出来的排序值
C. 从answer8_B中取出num列序号<=5的
(2)完整SQL:
A. 需要电影类型,所有需要将answer7_A中的type字段进行裂变,将结果保存到answer8_A中
create table answer8_A as
select a.id as id, a.name as name, a.years as years, a.rate as rate, tv.type as type
from answer7_A a
lateral view explode(split(a.type,"\\|")) tv as type;
select * from answer8_A;
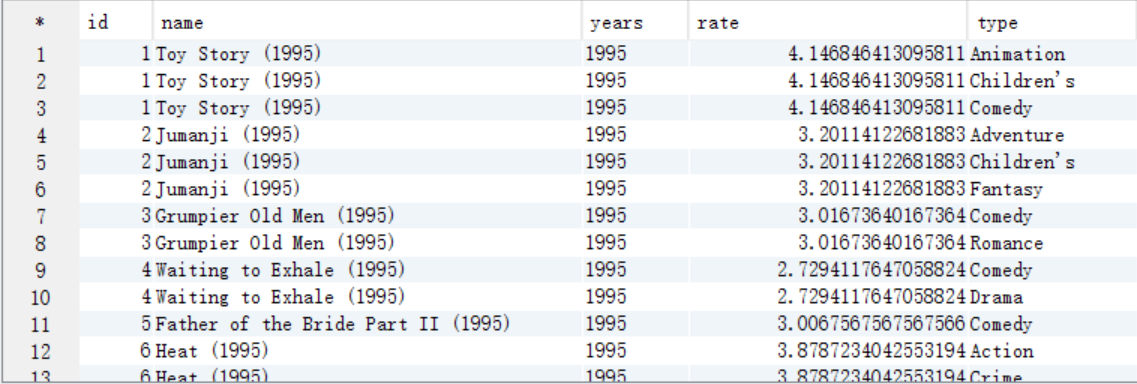
B. 求TopN,按照type分组,需要添加一列来记录每组的顺序,将结果保存到answer8_B中
create table answer8_B as
select id,name,years,rate,type,row_number() over(distribute by type sort by rate desc ) as num
from answer8_A;
select * from answer8_B;
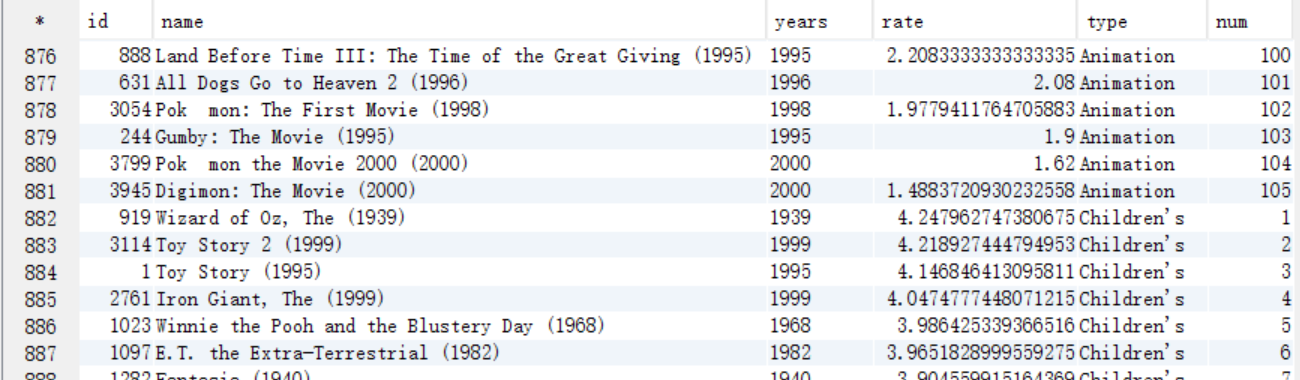
C. 从answer8_B中取出num列序号<=5的
select a.* from answer8_B a where a.num <= 5;
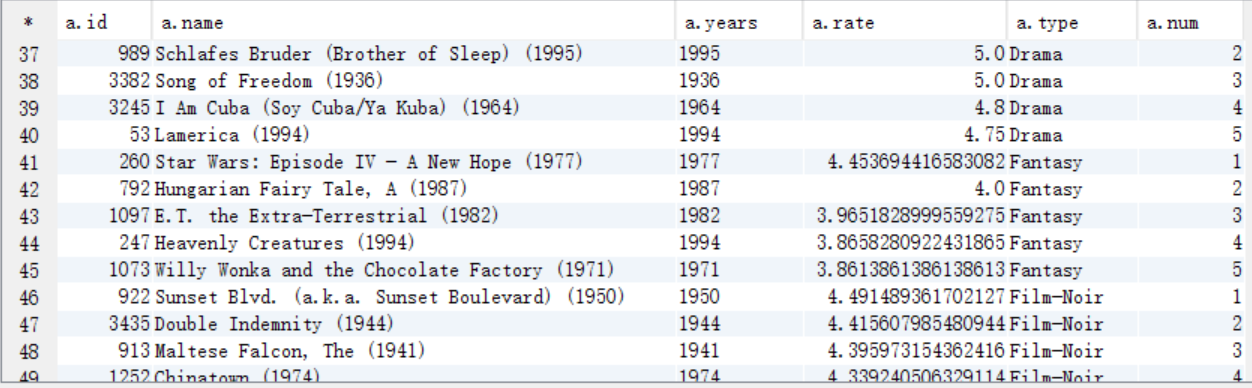
9、各年评分最高的电影类型(年份,类型,影评分)
(1)分析思路:
1、需求字段:电影id movieid
电影名 moviename
影评分 rate(排序条件)
电影类型 type(分组条件)
上映年份 years(分组条件)
2、核心SQL:
A. 需要按照电影类型和上映年份进行分组,按照影评分进行排序,将结果保存到answer9_A中
需要查询的字段:
上映年份 answer7_A.years
影评分 answer7_A.rate
电影类型 answer7_A.movietype
B. 求TopN,按照years分组,需要添加一列来记录每组的顺序,将结果保存到answer9_B中
C. 按照num=1作为where过滤条件取出结果数据
(2)完整SQL:
A. 需要按照电影类型和上映年份进行分组,按照影评分进行排序,将结果保存到answer9_A中
create table answer9_A as
select a.years as years, a.type as type, avg(a.rate) as rate
from answer8_A a
group by a.years,a.type
order by rate desc;
select * from answer9_A;
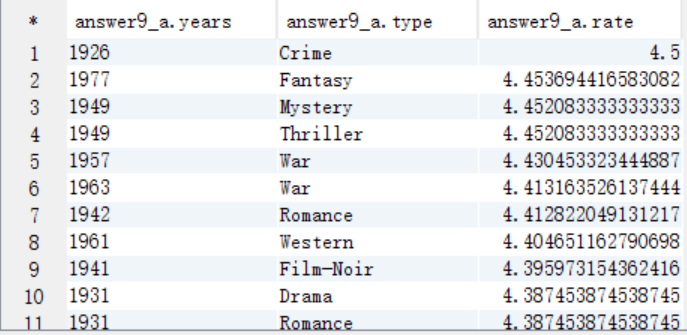
B. 求TopN,按照years分组,需要添加一列来记录每组的顺序,将结果保存到answer9_B中
create table answer9_B as
select years,type,rate,row_number() over (distribute by years sort by rate) as num
from answer9_A;
select * from answer9_B;
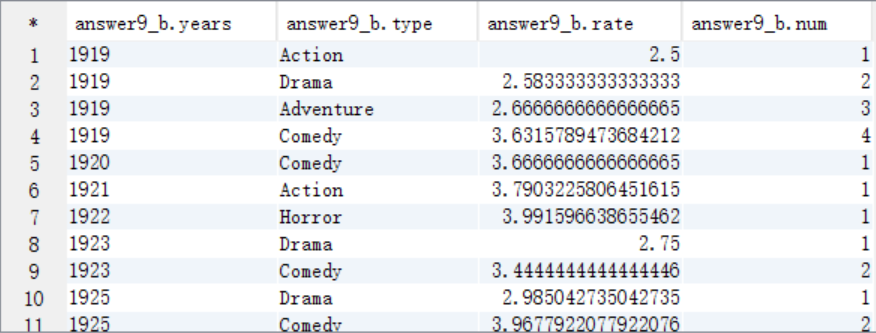
C. 按照num=1作为where过滤条件取出结果数据
select * from answer9_B where num=1;
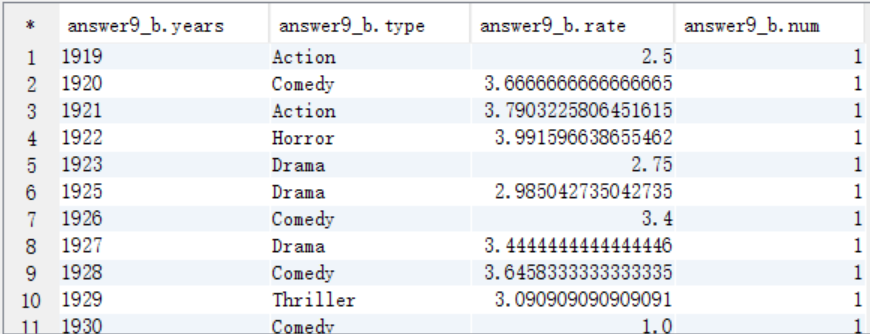
10、每个地区最高评分的电影名,把结果存入HDFS(地区,电影名,影评分)
(1)分析思路:
1、需求字段:电影id t_movie.movieid
电影名 t_movie.moviename
影评分 t_rating.rate(排序条件)
地区 t_user.zipcode(分组条件)
2、核心SQL:
A. 需要把三张表进行联合查询,取出电影id、电影名称、影评分、地区,将结果保存到answer10_A表中
需要查询的字段:电影id t_movie.movieid
电影名 t_movie.moviename
影评分 t_rating.rate(排序条件)
地区 t_user.zipcode(分组条件)
B. 求TopN,按照地区分组,按照平均排序,添加一列num用来记录地区排名,将结果保存到answer10_B表中
C. 按照num=1作为where过滤条件取出结果数据
(2)完整SQL:
A. 需要把三张表进行联合查询,取出电影id、电影名称、影评分、地区,将结果保存到answer10_A表中
create table answer10_A as
select c.movieid, c.moviename, avg(b.rate) as avgrate, a.zipcode
from t_user a
join t_rating b on a.userid=b.userid
join t_movie c on b.movieid=c.movieid
group by a.zipcode,c.movieid, c.moviename;
select t.* from answer10_A t;

B. 求TopN,按照地区分组,按照平均排序,添加一列num用来记录地区排名,将结果保存到answer10_B表中
create table answer10_B as
select movieid,moviename,avgrate,zipcode, row_number() over (distribute by zipcode sort by avgrate) as num
from answer10_A;
select t.* from answer10_B t;
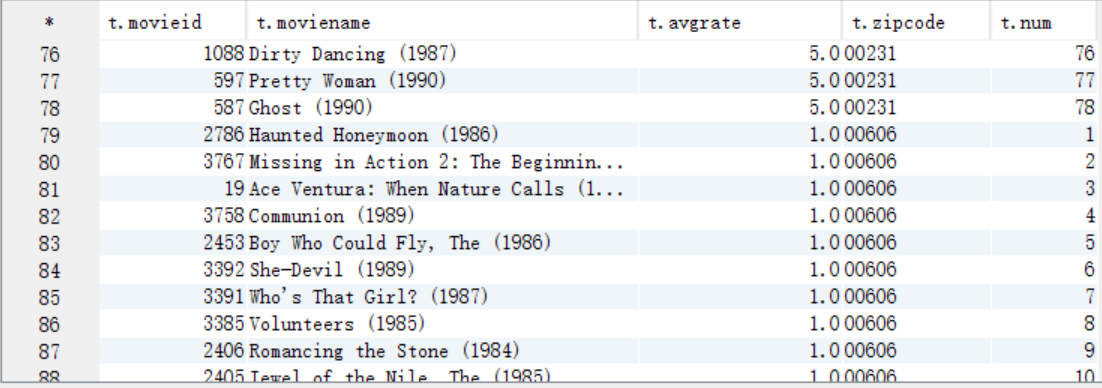
C. 按照num=1作为where过滤条件取出结果数据并保存到HDFS上
insert overwrite directory "/movie/answer10/" select t.* from answer10_B t where t.num=1;

Hive学习之路 (十二)Hive SQL练习之影评案例的更多相关文章
- Hive学习之路 (二十一)Hive 优化策略
一.Hadoop 框架计算特性 1.数据量大不是问题,数据倾斜是个问题 2.jobs 数比较多的作业运行效率相对比较低,比如即使有几百行的表,如果多次关联多次 汇总,产生十几个 jobs,耗时很长.原 ...
- Hive学习之路 (二)Hive安装
Hive的下载 下载地址http://mirrors.hust.edu.cn/apache/ 选择合适的Hive版本进行下载,进到stable-2文件夹可以看到稳定的2.x的版本是2.3.3 Hive ...
- Hive学习之路 (二十)Hive 执行过程实例分析
一.Hive 执行过程概述 1.概述 (1) Hive 将 HQL 转换成一组操作符(Operator),比如 GroupByOperator, JoinOperator 等 (2)操作符 Opera ...
- Hive学习之路(二)—— Linux环境下Hive的安装部署
一.安装Hive 1.1 下载并解压 下载所需版本的Hive,这里我下载版本为cdh5.15.2.下载地址:http://archive.cloudera.com/cdh5/cdh/5/ # 下载后进 ...
- zigbee学习之路(十二):zigbee协议原理介绍
一.前言 从今天开始,我们要正式开始进行zigbee相关的通信实验了,我所使用的协议栈是ZStack 是TI ZStack-CC2530-2.3.0-1.4.0版本,大家也可以从TI的官网上直接下载T ...
- Object-c学习之路十二(OC的copy)
oc中的拷贝分为:copy(浅拷贝)和mutablecopy(深拷贝). 浅拷贝也为指针拷贝,拷贝后原来的对象计数器会+1: 深拷贝为对象拷贝,原来的对象计数器不变. 注意:自定义对象拷贝时要实现NS ...
- Java学习之路(十二):IO流<二>
字符流 字符流是可以直接读写字符的IO流 使用字符流从文件中读取字符的时候,需要先读取到字节数据,让后在转换为字符 使用字符流向文件中写入字符时,需要把字符转为字节在写入文件 Reader和Write ...
- 嵌入式Linux驱动学习之路(十二)按键驱动-poll机制
实现的功能是在读取按键信息的时候,如果没有产生按键,则程序休眠在read函数中,利用poll机制,可以在没有退出的情况下让程序自动退出. 下面的程序就是在读取按键信息的时候,如果5000ms内没有按键 ...
- IOS学习之路十二(UITableView下拉刷新页面)
今天做了一个下拉刷新的demo,主要用到了实现的开源框架是:https://github.com/enormego/EGOTableViewPullRefresh 运行结果如下: 实现很简单下载源代码 ...
- Java学习之路(十二):IO流<三>
复习:序列流 序列流可以把多个字节输入整合成一个,从序列流中读取到数据时,将从被整合的第一个流开始读取,读完这个后,然后开始读取第二个流,依次向后推. 详细见上一篇文章 ByteArrayOutput ...
随机推荐
- ZAB 算法
ZAB (Zookeeper Atomic Broadcast ) zookeeper原子消息广播协议 保证:分布式数据一致性 所有事务请求必须由一个全局唯一的服务器来协调处理,这样的服务器被称为 ...
- MySQL 报错
SELECT COUNT(1) FROM (select tid from teacher where tname like '李%') 1248 - Every derived table must ...
- 传统javabean与spring中的bean的区别
javabean已经没人用了 springbean可以说是javabean的发展, 但已经完全不是一回事儿了 用处不同:传统javabean更多地作为值传递参数,而spring中的bean用处几乎无处 ...
- BZOJ3672: [Noi2014]购票(dp 斜率优化 点分治 二分 凸包)
题意 题目链接 Sol 介绍一种神奇的点分治的做法 啥?这都有根树了怎么点分治?? 嘿嘿,这道题的点分治不同于一般的点分治.正常的点分治思路大概是先统计过重心的,再递归下去 实际上一般的点分治与统计顺 ...
- display none隐藏后如果表单有数值,那么他的数值还存在!
以前以为display:none后他的值就不存在了, display:none隐藏后如果表单有数值,那么他的数值还存在.(项目出了问题!!) <!DOCTYPE html PUBLIC &quo ...
- P2P文件上传
采用uploadify上传 官网:http://www.uploadify.com/ (有H5版本和flash版本,H5收费,所以暂时用flash) uploadify的重要配置属性(http:/ ...
- elixir 基础数据结构
Elixir中的一些基础的数据结构:整数,浮点数,字符串,原子,列表,元组 整数,浮点数,字符串 跟其他语言差不多 原子:名字为值的常量 在ruby类似Symbols 在erlang是用大写 ...
- 在android工程中,res目录下又有anim、drawable、layout、menu、raw、values和xml文件夹,分别用来保存?
res目录主要是存放资源文件的!layout 布局 这个就是你经常看到的与用户交互的界面的 xml 文件,就是各个 view 的排列和嵌套,没什 么好说的啦 风格和主题. 风格主要是指 view 的显 ...
- Android资源文件说明
一. Android资源文件简介 1. Android应用资源的作用 (1) Android项目中文件分类 在Android工程中, 文件主要分为下面几类 : 界面布局文件, Java src源文件, ...
- linux(centos7)下SVN服务器搭建手札
linux(centos)下SVN服务器如何搭建?说到SVN服务器,想必大家都知道,可以是在LINUX下如何搭建SVN服务器呢?那么今天给大家分享一下linux(centos)搭建SVN服务器的思路! ...