关于SimHash去重原理的理解(能力工场小马哥)
阅读目录
- 1. SimHash与传统hash函数的区别
- 2. SimHash算法思想
- 3. SimHash流程实现
- 4. SimHash签名距离计算
- 5. SimHash存储和索引
- 6. SimHash存储和索引
- 7. 参考内容
在之前的两篇博文分别介绍了常用的hash方法([Data Structure & Algorithm] Hash那点事儿)以及局部敏感hash算法([Algorithm] 局部敏感哈希算法(Locality Sensitive Hashing)),本文介绍的SimHash是一种局部敏感hash,它也是Google公司进行海量网页去重使用的主要算法。
1. SimHash与传统hash函数的区别
传统的Hash算法只负责将原始内容尽量均匀随机地映射为一个签名值,原理上仅相当于伪随机数产生算法。传统的hash算法产生的两个签名,如果原始内容在一定概率下是相等的;如果不相等,除了说明原始内容不相等外,不再提供任何信息,因为即使原始内容只相差一个字节,所产生的签名也很可能差别很大。所以传统的Hash是无法在签名的维度上来衡量原内容的相似度,而SimHash本身属于一种局部敏感哈希算法,它产生的hash签名在一定程度上可以表征原内容的相似度。
我们主要解决的是文本相似度计算,要比较的是两个文章是否相识,当然我们降维生成了hash签名也是用于这个目的。看到这里估计大家就明白了,我们使用的simhash就算把文章中的字符串变成 01 串也还是可以用于计算相似度的,而传统的hash却不行。我们可以来做个测试,两个相差只有一个字符的文本串,“你妈妈喊你回家吃饭哦,回家罗回家罗” 和 “你妈妈叫你回家吃饭啦,回家罗回家罗”。
通过simhash计算结果为:
1000010010101101111111100000101011010001001111100001001011001011
1000010010101101011111100000101011010001001111100001101010001011
通过传统hash计算为:
0001000001100110100111011011110
1010010001111111110010110011101
大家可以看得出来,相似的文本只有部分 01 串变化了,而普通的hash却不能做到,这个就是局部敏感哈希的魅力。
2. SimHash算法思想
假设我们有海量的文本数据,我们需要根据文本内容将它们进行去重。对于文本去重而言,目前有很多NLP相关的算法可以在很高精度上来解决,但是我们现在处理的是大数据维度上的文本去重,这就对算法的效率有着很高的要求。而局部敏感hash算法可以将原始的文本内容映射为数字(hash签名),而且较为相近的文本内容对应的hash签名也比较相近。SimHash算法是Google公司进行海量网页去重的高效算法,它通过将原始的文本映射为64位的二进制数字串,然后通过比较二进制数字串的差异进而来表示原始文本内容的差异。
3. SimHash流程实现
simhash是由 Charikar 在2002年提出来的,本文为了便于理解尽量不使用数学公式,分为这几步:
(注:具体的事例摘自Lanceyan的博客《海量数据相似度计算之simhash和海明距离》)
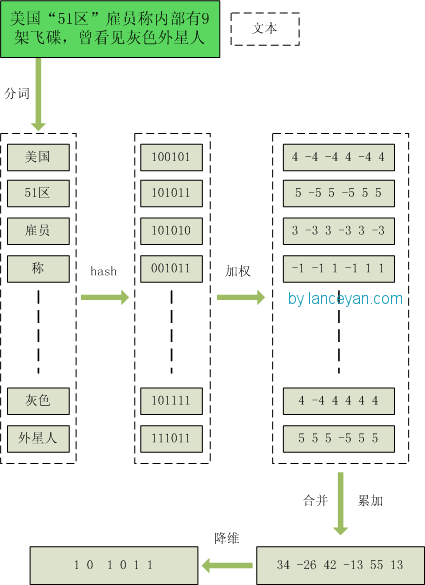
1、分词,把需要判断文本分词形成这个文章的特征单词。最后形成去掉噪音词的单词序列并为每个词加上权重,我们假设权重分为5个级别(1~5)。比如:“ 美国“51区”雇员称内部有9架飞碟,曾看见灰色外星人 ” ==> 分词后为 “ 美国(4) 51区(5) 雇员(3) 称(1) 内部(2) 有(1) 9架(3) 飞碟(5) 曾(1) 看见(3) 灰色(4) 外星人(5)”,括号里是代表单词在整个句子里重要程度,数字越大越重要。
2、hash,通过hash算法把每个词变成hash值,比如“美国”通过hash算法计算为 100101,“51区”通过hash算法计算为 101011。这样我们的字符串就变成了一串串数字,还记得文章开头说过的吗,要把文章变为数字计算才能提高相似度计算性能,现在是降维过程进行时。
3、加权,通过 2步骤的hash生成结果,需要按照单词的权重形成加权数字串,比如“美国”的hash值为“100101”,通过加权计算为“4 -4 -4 4 -4 4”;“51区”的hash值为“101011”,通过加权计算为 “ 5 -5 5 -5 5 5”。
4、合并,把上面各个单词算出来的序列值累加,变成只有一个序列串。比如 “美国”的 “4 -4 -4 4 -4 4”,“51区”的 “ 5 -5 5 -5 5 5”, 把每一位进行累加, “4+5 -4+-5 -4+5 4+-5 -4+5 4+5” ==》 “9 -9 1 -1 1 9”。这里作为示例只算了两个单词的,真实计算需要把所有单词的序列串累加。
5、降维,把4步算出来的 “9 -9 1 -1 1 9” 变成 0 1 串,形成我们最终的simhash签名。 如果每一位大于0 记为 1,小于0 记为 0。最后算出结果为:“1 0 1 0 1 1”。
整个过程的流程图为:
4. SimHash签名距离计算
我们把库里的文本都转换为simhash签名,并转换为long类型存储,空间大大减少。现在我们虽然解决了空间,但是如何计算两个simhash的相似度呢?难道是比较两个simhash的01有多少个不同吗?对的,其实也就是这样,我们通过海明距离(Hamming distance)就可以计算出两个simhash到底相似不相似。两个simhash对应二进制(01串)取值不同的数量称为这两个simhash的海明距离。举例如下: 10101 和 00110 从第一位开始依次有第一位、第四、第五位不同,则海明距离为3。对于二进制字符串的a和b,海明距离为等于在a XOR b运算结果中1的个数(普遍算法)。
5. SimHash存储和索引
经过simhash映射以后,我们得到了每个文本内容对应的simhash签名,而且也确定了利用汉明距离来进行相似度的衡量。那剩下的工作就是两两计算我们得到的simhash签名的汉明距离了,这在理论上是完全没问题的,但是考虑到我们的数据是海量的这一特点,我们是否应该考虑使用一些更具效率的存储呢?其实SimHash算法输出的simhash签名可以为我们很好建立索引,从而大大减少索引的时间,那到底怎么实现呢?
这时候大家有没有想到hashmap呢,一种理论上具有O(1)复杂度的查找数据结构。我们要查找一个key值时,通过传入一个key就可以很快的返回一个value,这个号称查找速度最快的数据结构是如何实现的呢?看下hashmap的内部结构:
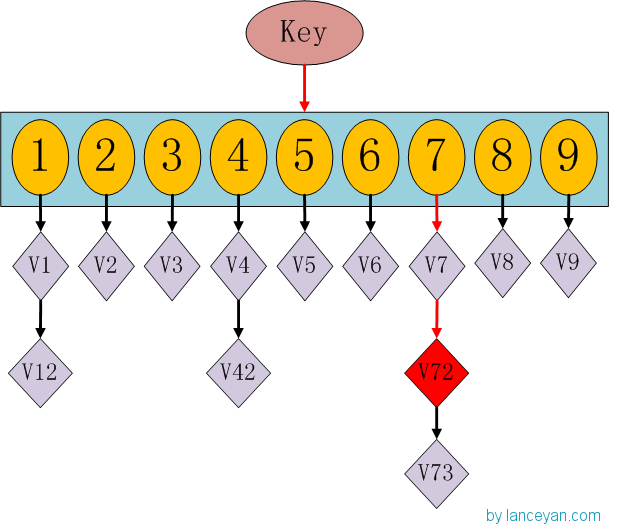
如果我们需要得到key对应的value,需要经过这些计算,传入key,计算key的hashcode,得到7的位置;发现7位置对应的value还有好几个,就通过链表查找,直到找到v72。其实通过这么分析,如果我们的hashcode设置的不够好,hashmap的效率也不见得高。借鉴这个算法,来设计我们的simhash查找。通过顺序查找肯定是不行的,能否像hashmap一样先通过键值对的方式减少顺序比较的次数。看下图:
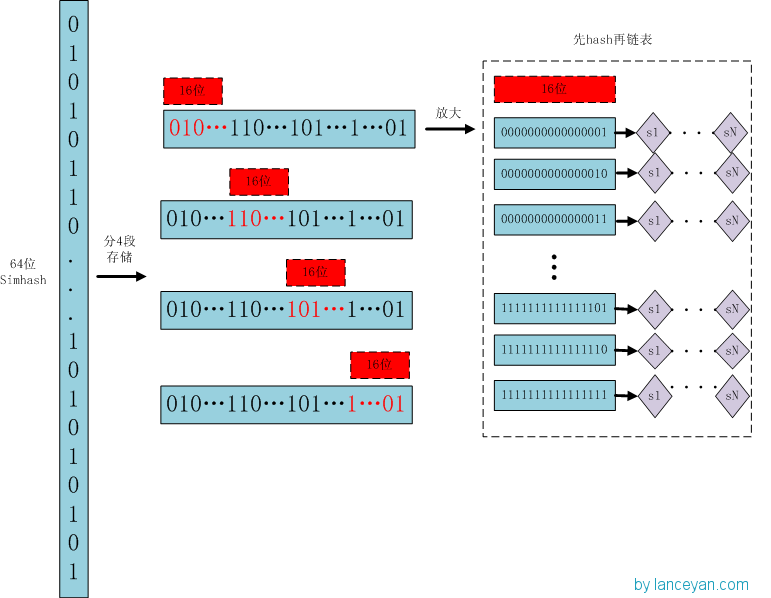
存储:
1、将一个64位的simhash签名拆分成4个16位的二进制码。(图上红色的16位)
2、分别拿着4个16位二进制码查找当前对应位置上是否有元素。(放大后的16位)
3、对应位置没有元素,直接追加到链表上;对应位置有则直接追加到链表尾端。(图上的 S1 — SN)
查找:
1、将需要比较的simhash签名拆分成4个16位的二进制码。
2、分别拿着4个16位二进制码每一个去查找simhash集合对应位置上是否有元素。
3、如果有元素,则把链表拿出来顺序查找比较,直到simhash小于一定大小的值,整个过程完成。
原理:
借鉴hashmap算法找出可以hash的key值,因为我们使用的simhash是局部敏感哈希,这个算法的特点是只要相似的字符串只有个别的位数是有差别变化。那这样我们可以推断两个相似的文本,至少有16位的simhash是一样的。具体选择16位、8位、4位,大家根据自己的数据测试选择,虽然比较的位数越小越精准,但是空间会变大。分为4个16位段的存储空间是单独simhash存储空间的4倍。之前算出5000w数据是 382 Mb,扩大4倍1.5G左右,还可以接受
6. SimHash存储和索引
1. 当文本内容较长时,使用SimHash准确率很高,SimHash处理短文本内容准确率往往不能得到保证;
2. 文本内容中每个term对应的权重如何确定要根据实际的项目需求,一般是可以使用IDF权重来进行计算。
7. 参考内容
1. 严澜的博客《海量数据相似度计算之simhash短文本查找》
2. 《Similarity estimation techniques from rounding algorithms》
关于SimHash去重原理的理解(能力工场小马哥)的更多相关文章
- 使用Eclipse的几个必须掌握的快捷方式(能力工场小马哥收集)
“工若善其事,必先利其器”,感谢Eclipse,她 使我们阅读一个大工程的代码更加容易,在阅读的过程中,我发现掌握几个Eclipse的快捷键会使阅读体验更加流畅,写出来与诸君分享,欢迎补充. 1. C ...
- Maven异常: No compiler is provided in this environment. Perhaps you are running on a JRE rather than a JDK解决(能力工场小马哥)
问题描述: No compiler is provided in this environment. Perhaps you are running on a JRE rather than a JD ...
- 通过Shell命令与JavaAPI读取ElasticSearch数据 (能力工场小马哥)
主要内容: 通过JavaAPI和Shell命令两种方式操作ES集群 集群环境: 两个 1,未配置集群名称的单节点(模拟学习测试环境); 2,两个节点的集群(模拟正常生产环境). JDK8+Elasti ...
- ElasticSearch异常归纳(能力工场小马哥)
异常1: can not run elasticsearch as root [WARN ][o.e.b.ElasticsearchUncaughtExceptionHandler] [node-2] ...
- simhash和minhash实现理解
文本相似度算法 minhash minhash 1. 把文档A分词形成分词向量L 2. 使用K个hash函数,然后每个hash将L里面的分词分别进行hash,然后得到K个被hash过的集合 3. 分别 ...
- Atitit 泛型原理与理解attilax总结
Atitit 泛型原理与理解attilax总结 1. 泛型历史11.1.1. 由来11.2. 为什么需要泛型,类型安全21.3. 7.泛型的好处22. 泛型的机制编辑22.1.1. 机制32.1.2. ...
- 从tcp原理角度理解Broken pipe和Connection reset by peer的区别
从tcp原理角度理解Broken pipe和Connection reset by peer的区别 http://lovestblog.cn/blog/2014/05/20/tcp-broken-pi ...
- scrapy暂停和重启,及url去重原理,telenet简单使用
一.scrapy暂停与重启 1.要暂停,就要保留一些中间信息,以便重启读取中间信息并从当前位置继续爬取,则需要一个目录存放中间信息: scrapy crawl spider_name -s JOBDI ...
- 对CAP原理的理解
对CAP原理的理解 CAP原理按照定义,指的是C(Consistency)一致性,A(Availability)可用性,P(Partition tolerance)分区容错性在一个完整的计算机系统中三 ...
随机推荐
- CentOS 7 下编译安装lnmp之nginx篇详解
一.安装环境 宿主机=> win7,虚拟机 centos => 系统版本:CentOS Linux release 7.5.1804 (Core),ip地址 192.168.1.168 ...
- PowerDesigner导出图片
但是通过上面导出的图片会比较模糊不清晰,但是可以通过这样解决: 1.放大设计,然后全选复制全部 2.打开画图工具 3.粘贴到画图工具
- 【scrapy】使用方法概要(三)(转)
请初学者作为参考,不建议高手看这个浪费时间] 前两篇大概讲述了scrapy的安装及工作流程.这篇文章主要以一个实例来介绍scrapy的开发流程,本想以教程自带的dirbot作为例子,但感觉大家应该最先 ...
- 在win7下安装VC6.0
一.以系统管理员的身份执行VC6.0安装文件 二.在安装或者使用VisualC++6.0时,凡是出现兼容性问题提示对话框,一律按下面方式处理--把"不再显示此消息"打上勾,然后选择 ...
- [Mysql]MySQL 服务无法启动。
摘要 在官网下载了mysql,版本mysql-5.7.17-winx64,免安装的压缩包,解压后.放在MySql的文件夹中.电脑系统win10 x64. 配置文件 # For advice on ho ...
- MySQL数据库事务各隔离级别加锁情况--Repeatable Read && MVCC(转)
本文转自https://m.imooc.com/article/details?article_id=17289 感谢作者 上节回顾 上两篇记录了我对MySQL 事务 隔离级别read uncommi ...
- spring mvc 下 applicationContext 和webApplicationContext
spring中的ApplicationContexts可以被限制在不同的作用域.在web框架中,每个DispatcherServlet有它自己的WebApplicationContext,它包含了Di ...
- 设置SVN忽略文件和目录(文件夹)
在多数项目中你总会有文件和目录不需要进行版本控制.这可能包括一些由编译器生成的文件,*.obj,*.lst,或许是一个用于存放可执行程序的输出文件夹.只要你提交修改,TortoiseSVN 就会在提交 ...
- 浅谈Android RecyclerView
Android RecyclerView 是Android5.0推出来的,导入support-v7包即可使用. 个人体验来说,RecyclerView绝对是一款功能强大的控件. 首先总结下Recycl ...
- Java JDBC 基础知识
一.JDBC常用接口.类介绍 JDBC提供对独立于数据库统一的API,用以执行SQL命令.API常用的类.接口如下: DriverManager 管理JDBC驱动的服务类,主要通过它获取Connect ...