Spark GraphX 的数据可视化
概述
详细
Spark 和 GraphX 对并不提供对数据可视化的支持, 它们所关注的是数据处理。但是, 一图胜千言, 尤其是在数据分析时。接下来, 我们构建一个可视化分析图的 Spark 应用。需要用到的第三方库有:
GraphStream: 用于画出网络图
BreezeViz: 用户绘制图的结构化信息, 比如度的分布。
这些第三方库尽管并不完美, 而且有些限制, 但是相对稳定和易于使用。
一、安装 GraphStream 和 BreezeViz
因为我们只需要绘制静态网络, 所以下载 core 和 UI 两个 JAR 就可以了。
gs-core-1.2.jar(请看下载的压缩包里的jars.zip)
gs-ui-1.2.jar(请看下载的压缩包里的jars.zip
breeze 也需要两个 JAR:
breeze_2.10-0.9.jar(请看下载的压缩包里的jars.zip
breeze-viz_2.10-0.9.jar(请看下载的压缩包里的jars.zip
由于 BreezeViz 是一个 Scala 库, 它依赖了另一个叫做 JfreeChart 的 Java 库, 所以也需要安装:
jcommon-1.0.16.jar(请看下载的压缩包里的jars.zip
jfreechart-1.0.13.jar(请看下载的压缩包里的jars.zip
可以到 maven 仓库去下载, 下载完成后放到项目根目录下 lib 文件夹下即可. 用 sbt 来管理依赖比较方便, 所以我使用 sbt 来安装这些依赖:
// Graph Visualization
// https://mvnrepository.com/artifact/org.graphstream/gs-core
libraryDependencies += "org.graphstream" % "gs-core" % "1.2"
// https://mvnrepository.com/artifact/org.graphstream/gs-ui
libraryDependencies += "org.graphstream" % "gs-ui" % "1.2" // https://mvnrepository.com/artifact/org.scalanlp/breeze_2.10
libraryDependencies += "org.scalanlp" % "breeze_2.11" % "0.12"
// https://mvnrepository.com/artifact/org.scalanlp/breeze-viz_2.11
libraryDependencies += "org.scalanlp" % "breeze-viz_2.11" % "0.12" // https://mvnrepository.com/artifact/org.jfree/jcommon
libraryDependencies += "org.jfree" % "jcommon" % "1.0.24" // https://mvnrepository.com/artifact/org.jfree/jfreechart
libraryDependencies += "org.jfree" % "jfreechart" % "1.0.19"
二、画图
一、导入
在导入环节需要注意的是, 如果是与 GraphX 的 Graph 一同使用, 在导入时将 graphstream 的 Graph 重命名为 GraphStream, 否则都叫 Graph 会有命名空间上的冲突。当然, 如果只使用一个就无所谓了。
import org.graphstream.graph.{Graph => GraphStream}
二、绘制
首先是使用 GraphX 加载一个图, 然后将这个图的信息导入 graphstream 的图中进行可视化. 具体是:
1、创建一个 SingleGraph 对象, 它来自 graphstream:
val graph: SingleGraph = new SingleGraph("visualizationDemo")
2、我们可以调用 SingleGraph 的 addNode 和 addEdge 方法来添加节点和边, 也可以调用 addAttribute 方法来给图, 或是单独的边和顶点来设置可视化属性. graphsteam API 非常好的一点是, 它将图的结构和可视化用一个类 CSS 的样式文件完全分离了开来, 我们可以通过这个样式文件来控制可视化的方式. 比如, 我们新建一个 stylesheet 文件并放到用户目录下的 style 文件下面:
node {
fill-color: #a1d99b;
size: 20px;
text-size: 12;
text-alignment: at-right;
text-padding: 2;
text-background-color: #fff7bc;
}
edge {
shape: cubic-curve;
fill-color: #dd1c77;
z-index: 0;
text-background-mode: rounded-box;
text-background-color: #fff7bc;
text-alignment: above;
text-padding: 2;
}
上面的样式文件定义了节点与边的样式, 更多内容可见其官方文档.
准备好样式文件以后, 就可以使用它:
// Set up the visual attributes for graph visualization
graph.addAttribute("ui.stylesheet","url(file:/home/xlc/style/stylesheet)")
graph.addAttribute("ui.quality")
graph.addAttribute("ui.antialias")
ui.quality 和 ui.antialias 属性是告诉渲染引擎在渲染时以质量为先而非速度。 如果不设置样式文件, 顶点与边默认渲染出来的效果是黑色。
3、加入节点和边。将 GraphX 所构建图的 VertexRDD 和 EdgeRDD 里面的内容加入到 GraphStream 的图对象中:
// Given the egoNetwork, load the graphX vertices into GraphStream
for ((id,_) <- egoNetwork.vertices.collect()) {
val node = graph.addNode(id.toString).asInstanceOf[SingleNode]
}
// Load the graphX edges into GraphStream edges
for (Edge(x,y,_) <- egoNetwork.edges.collect()) {
val edge = graph.addEdge(x.toString ++ y.toString, x.toString, y.toString, true).asInstanceOf[AbstractEdge]
}
加入顶点时, 只需要将顶点的 vertex ID 转换成字符串传入即可。
对于边, 稍显麻烦。addEdge 的 API 文档在 这里, 我们需要传入 4 个参数。第一个参数是每条边的字符串标识符, 由于在 GraphX 原有的图中并不存在, 所以我们需要自己创建。最简单的方式是将这条边的两个端点的 vertex ID 连接起来。
注意, 在上面的代码中, 为了避免我们的 scala 代码与 Java 库 GraphStream 互用上的一些问题, 采用了小的技巧。在 GraphStream 的 org.graphstream.graph.implementations.AbstractGraph API o文档中, addNode 和 addEdge 分别返回顶点和边。但是由于 GraphStream 是一个第三方的 Java 库, 我们必须强制使用 asInstanceOf[T], 其中 [T] 为 SingleNode 和 AbstractEdge, 作为 addNode 和 addEdge 的返回类型。 如果我们漏掉了这些显式的类型转换, 可能会得到一个奇怪的异常:
java.lang.ClassCastException:
org.graphstream.graph.implementations.SingleNode cannot
be cast to scala.runtime.Nothing$
4、显示图像
graph.display()
5、部分示例代码:
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
.setAppName("GraphStreamDemo")
.set("spark.master", "local[*]")
val sc = new SparkContext(sparkConf)
val graph: SingleGraph = new SingleGraph("graphDemo")
val vertices: RDD[(VertexId, String)] = sc.parallelize(List(
(1L, "A"),
(2L, "B"),
(3L, "C"),
(4L, "D"),
(5L, "E"),
(6L, "F"),
(7L, "G")))
val edges: RDD[Edge[String]] = sc.parallelize(List(
Edge(1L, 2L, "1-2"),
Edge(1L, 3L, "1-3"),
Edge(2L, 4L, "2-4"),
Edge(3L, 5L, "3-5"),
Edge(3L, 6L, "3-6"),
Edge(5L, 7L, "5-7"),
Edge(6L, 7L, "6-7")))
三、运行效果与文件截图
1、运行效果:
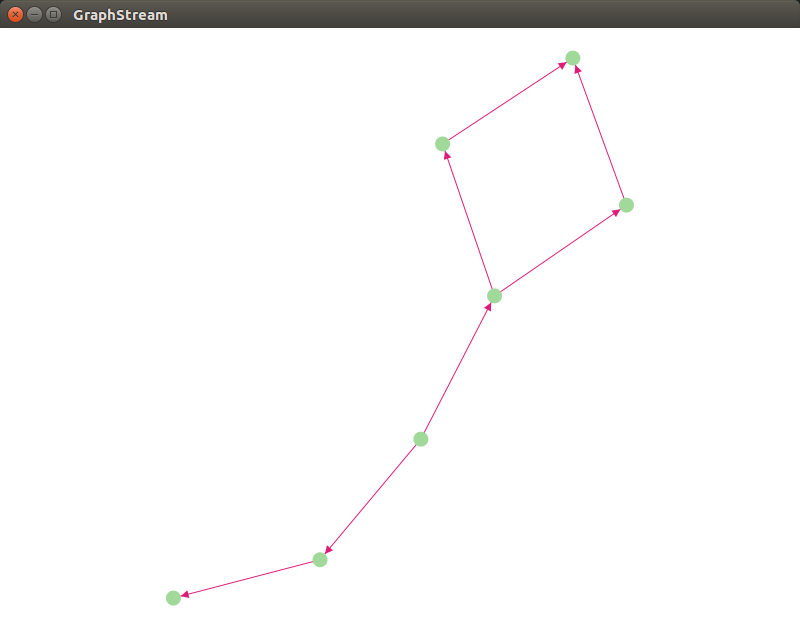
至此, 一个简单的示例完成. 更多实用的内容可自行研究。
2、文件截图:

四、其他补充
目前, 如果不消耗大量的计算资源, 对于大规模的网络图绘制仍然缺乏一个有力的工具. 类似的工具有:
另外, zeepelin 也可与 Spark 集成, 可自行了解。
注:本文著作权归作者,由demo大师发表,拒绝转载,转载需要作者授权
Spark GraphX 的数据可视化的更多相关文章
- 大数据技术之_19_Spark学习_05_Spark GraphX 应用解析 + Spark GraphX 概述、解析 + 计算模式 + Pregel API + 图算法参考代码 + PageRank 实例
第1章 Spark GraphX 概述1.1 什么是 Spark GraphX1.2 弹性分布式属性图1.3 运行图计算程序第2章 Spark GraphX 解析2.1 存储模式2.1.1 图存储模式 ...
- Spark GraphX宝刀出鞘,图文并茂研习图计算秘笈与熟练的掌握Scala语言【大数据Spark实战高手之路】
Spark GraphX宝刀出鞘,图文并茂研习图计算秘笈 大数据的概念与应用,正随着智能手机.平板电脑的快速流行而日渐普及,大数据中图的并行化处理一直是一个非常热门的话题.图计算正在被广泛地应用于社交 ...
- GraphX学习笔记——可视化
首先自己造了一份简单的社交关系的图 第一份是人物数据,id和姓名,person.txt 1 孙俪 2 邓超 3 佟大为 4 冯绍峰 5 黄晓明 6 angelababy 7 李冰冰 8 范冰冰 第二份 ...
- Spark GraphX图算法应用【分区策略、PageRank、ConnectedComponents,TriangleCount】
一.分区策略 GraphX采用顶点分割的方式进行分布式图分区.GraphX不会沿着边划分图形,而是沿着顶点划分图形,这可以减少通信和存储的开销.从逻辑上讲,这对应于为机器分配边并允许顶点跨越多台机器. ...
- 使用bokeh-scala进行数据可视化
目录 前言 bokeh简介及胡扯 bokeh-scala基本代码 我的封装 总结 一.前言 最近在使用spark集群以及geotrellis框架(相关文章见http://www.cnbl ...
- 数据可视化工具zeppelin安装
介绍 zeppelin主要有以下功能 数据提取 数据发现 数据分析 数据可视化 目前版本(0.5-0.6)之前支持的数据搜索引擎有如下 安装 环境 centOS 6.6 编译准备工作 sudo yum ...
- 明风:分布式图计算的平台Spark GraphX 在淘宝的实践
快刀初试:Spark GraphX在淘宝的实践 作者:明风 (本文由团队中梧苇和我一起撰写,并由团队中的林岳,岩岫,世仪等多人Review,发表于程序员的8月刊,由于篇幅原因,略作删减,本文为完整版) ...
- 大数据实时处理-基于Spark的大数据实时处理及应用技术培训
随着互联网.移动互联网和物联网的发展,我们已经切实地迎来了一个大数据 的时代.大数据是指无法在一定时间内用常规软件工具对其内容进行抓取.管理和处理的数据集合,对大数据的分析已经成为一个非常重要且紧迫的 ...
- Spark Graphx编程指南
问题导读1.GraphX提供了几种方式从RDD或者磁盘上的顶点和边集合构造图?2.PageRank算法在图中发挥什么作用?3.三角形计数算法的作用是什么?Spark中文手册-编程指南Spark之一个快 ...
随机推荐
- 怎样用代码方式退出IOS程序
原文 :iOS Developer Library Technical Q&A QA1561 How do I programmatically quit my iOS application ...
- Android中关于项目中对Thread的管理(不是线程池)
背景 项目中对于一些并不复杂的耗时操作,比如计算,不频繁操作数据库等,因为没必要使用线程池,所以之前项目会直接使用new Thread的方式,时间一长,回头再看,原来new Thread之处已经很多了 ...
- Ext ComboBox 动态查询
Ext中的combobox有属性typeAhead:true 可以实现模糊匹配,但是是从开始匹配的,如果需要自定的的匹配,则需要监听beforequery方法,实现自己的匹配查询方法: var gfx ...
- facebook开源项目集合
Facebook的开源大手笔 1. 开源Facebook平台代码 Facebook在2008年选择将该平台上的重要部分的代码和应用工具开源.Facebook称,平台已经基本发展成熟,此举可以让开发 ...
- Java发邮件带附件(且重命名附件)
环境:spring3.2.2+jquery 用户的附件管理要实现发送附件可以是单个也可以是多个.由于用户在上传附件的时候采用了重命名机制,所以存在服务器上的文件是重命名后的文件,如果用户要将文件以邮件 ...
- [JQuery] jQuery选择器ID、CLASS、标签获取对象值、属性、设置css样式
reference : http://www.suyunyou.com/aid1657.html jQuery是继prototype之后又一个优秀的Javascrīpt框架.它是轻量级的js库(压缩后 ...
- 原创BULLET物理的DEMO
原创BULLET物理的DEMO 按空格和0,1,2,3,4,5,6会发射不同的刚体. 具体的使用说明: 鼠标右键按下并拖动 旋转视角WSAD ...
- UVA 10194 (13.08.05)
:W Problem A: Football (aka Soccer) The Problem Football the most popular sport in the world (ameri ...
- graphic rendering pipeline
整理下管线 此时一定要有这张图 注意表中的数据流向 强调几个细节 之前对次序理解有点乱 rasterizer之前 管线里是只有逐顶点信息的 IA里面会setup primitive 通过Primit ...
- JQuery模仿淘宝天猫魔盒抢购页面倒计时效果
1.效果及功能说明 通过对时间的控制来告诉用户一个活动还剩多少时间,精确到秒.2.实现原理 首先定义活动的截至的时间,要重年份精确到毫秒,在获得当前的年份到秒钟,在用截至时间,减去现在的时间,剩下的还 ...