STL容器读书笔记
vector
vector维护的是一个连续线性空间
vector是动态空间,随着元素的加入会自动扩容,扩充至当前size的两倍,然后将原内容拷贝,开始在原内容之后构造新元素,并释放空间
vector提供的迭代器是 random access iterators 随机访问迭代器,vector迭代器是普通指针
list
list插入和结合(splice)操作都不会造成原有的list迭代器失效
list不能用是STL算法sort,必须使用自己的sort,因为STL sort只接受random access iterators 随机访问迭代器
deque
双向开口的连续线性空间,动态的以分段连续空间组合而成,由一段一段的定量连续空间构成
deque有一段中控器,叫map
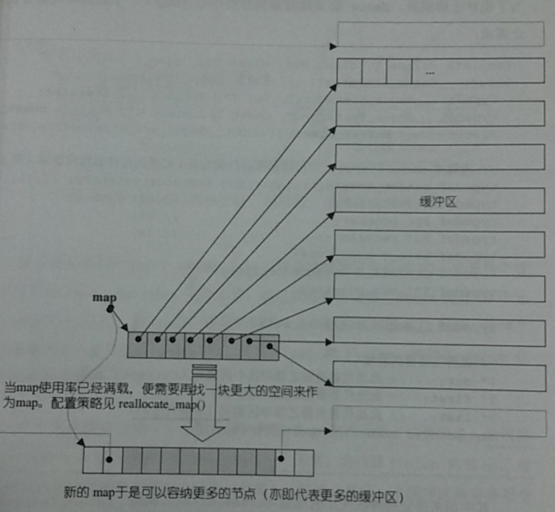
stack和queue有deque进化而来,这两个没有迭代器
heap
heap扮演priority_queue的助手,priority_queue允许用户以任何次序推入,取出一定是数值最高的元素
push_heap:新加入的元素放在最下一层作为叶节点,上溯
pop_heap:将根节点取出,把最下一层最右元素放在根节点位置,下溯
sort_heap:不断对heap进行pop操作,达到排序效果
priority_queue
权值高者排在前面(权值通常用实值)
平衡二叉树 (AVL树):树的深度为Ologn 通过左旋,右旋,双旋来让树保持平衡
红黑树(RB树):
每个节点不是红就是黑,根节点是黑,红节点的孩子一定是黑,任意节点到叶节点的路径黑节点数必须相同
时间复杂度Ologn
红黑树属于不严格平衡二叉树。说它不严格是因为它不是严格控制左、右子树高度或节点数之差小于等于1。不用严格控制高度,使得插入效率更高。红黑树插入效率比AVL树高,因为rebalance操作O(1)比AVL树O(logn)快(插入都是O(1),删除O(1) vs O(n))
红黑树的查询性能略微逊色于AVL树,因为他比avl树会稍微不平衡最多一层,也就是说红黑树的查询性能只比相同内容的avl树最多多一次比较,但是,红黑树在插入和删除上完爆avl树,avl树每次插入删除会进行大量的平衡度计算,而红黑树为了维持红黑性质所做的红黑变换和旋转的开销,相较于avl树为了维持平衡的开销要小得多
红黑树能够以O(log2 n) 的时间复杂度进行搜索、插入、删除操作。此外,由于它的设计,任何不平衡都会在三次旋转之内解决。
如果插入一个node引起了树的不平衡,AVL和RB-Tree都是最多只需要2次旋转操作,即两者都是O(1);但是在删除node引起树的不平衡时,最坏情况下,AVL需要维护从被删node到root这条路径上所有node的平衡性,因此需要旋转的量级O(logN),而RB-Tree最多只需3次旋转,只需要O(1)的复杂度。
应用红黑树的关联容器:set multiset map multimap
应用哈希的关联容器:hash_set hash_map hash_multiset hash_multimap unordered_map
1、STL的map底层是用红黑树实现的,查找时间复杂度是log(n);
2、STL的hash_map底层是用hash表存储的,查询时间复杂度是O(1);
3、什么时候用map,什么时候用hash_map?
不一定常数级别的hash_map一定比log(n)级别的map要好,hash_map的hash函数以及解决地址冲突等都要耗时间,而且众所周知hash表是以空间换时间的,因而hash_map的内存消耗肯定要大,一般情况下,考虑查找速度用hash_map,考虑内存消耗用map,海量数据一般用map
set
所有元素会根据元素的键值自动排列
map
map所有元素都是pair,同时拥有value和key,pair第一个元素被视为key,第二个是value
hashtable
哈希函数构造方法:
1 直接定址: H(key) = a * key + b
2 除留余数: H(key) = key % p
3 平方取中 ……
STL中
1.对于Int,long,short char,是直接返回原值
__STL_TEMPLATE_NULL struct hash<int> {
size_t operator()(int __x) const { return __x; }
};
2.对于const char *
inline size_t __stl_hash_string(const char* __s)
{
unsigned long __h = ;
for ( ; *__s; ++__s)
__h = *__h + *__s; return size_t(__h);
}
处理冲突:
1 线性探测 用下一个可用元素 缺点容易造成大量元素在相邻散列地址上的堆积
2 再散列
3 拉链
hash_map简单实现
选择“除留取余法”作为hash函数,选择“开散列地址链”作为冲入解决算法
struct Node//地址链节点
{
int key;//键
int value;//值
Node*next;//链接指针
Node(int k,int v):key(k),value(v),next(NULL){}
};
#define SIZE 100 //地址链个数,足够大
class SimHash
{
Node**map;//地址链数组
size_t hash(int key)//hash函数,除留取余法
{
return key%SIZE;
}
public:
SimHash()
{
map=new Node*[SIZE];
for(size_t i=;i<SIZE;i++)map[i]=NULL;//初始化数组为空
}
~SimHash()
{
for(size_t i=;i<SIZE;i++)//清除所有节点
{
Node*p;
while(p=map[i])
{
map[i]=p->next;
delete p;
}
}
delete[] map;//清除数组
}
void insert(int key,int value)
{
Node*f=find(key);//插入前查询
if(f)
{
f->value=value;//存在键则覆盖
return;
}
Node*p=map[hash(key)];//确定地址链索引
Node*q=new Node(key,value);//创建节点
while(p&&p->next)p=p->next;//索引到地址链末端
if(p)p->next=q;//添加节点
else map[hash(key)]=q;//地址链的第一个节点
}
void remove(int key)
{
Node*p=map[hash(key)];//确定地址链索引
Node*q=NULL;//前驱指针
while(p)
{
if(p->key==key)//找到键
{
if(q)q->next=p->next;//删除节点
else map[hash(key)]=p->next;//删除地址链的最后一个节点
delete p;
break;
}
q=p;
p=p->next;
}
}
Node* find(int key)
{
Node*p=map[hash(key)];//确定地址链索引
while(p)
{
if(p->key==key)break;//查询成功
p=p->next;
}
return p;
}
};
c++中map与unordered_map的区别
头文件
- map: #include < map >
- unordered_map: #include < unordered_map >
内部实现机理
- map: map内部实现了一个红黑树,该结构具有自动排序的功能,因此map内部的所有元素都是有序的,红黑树的每一个节点都代表着map的一个元素,因此,对于map进行的查找,删除,添加等一系列的操作都相当于是对红黑树进行这样的操作,故红黑树的效率决定了map的效率。
- unordered_map: unordered_map内部实现了一个哈希表,因此其元素的排列顺序是杂乱的,无序的
优缺点以及适用处
- map
- 优点:
- 有序性,这是map结构最大的优点,其元素的有序性在很多应用中都会简化很多的操作
- 红黑树,内部实现一个红黑书使得map的很多操作在lgn的时间复杂度下就可以实现,因此效率非常的高
- 缺点:
- 空间占用率高,因为map内部实现了红黑树,虽然提高了运行效率,但是因为每一个节点都需要额外保存父节点,孩子节点以及红/黑性质,使得每一个节点都占用大量的空间
- 适用处,对于那些有顺序要求的问题,用map会更高效一些
- 优点:
- unordered_map
- 优点:
- 因为内部实现了哈希表,因此其查找速度非常的快
- 缺点:
- 哈希表的建立比较耗费时间
- 适用处,对于查找问题,unordered_map会更加高效一些,因此遇到查找问题,常会考虑一下用unordered_map
- 优点:
容器的区别
容器的分类:
- 序列式容器:vector, list, deque
- 关联式容器: set, multiset, map , multimap
- 无序容器:unordered_set, unordered_multiset, unordered_map, unordered_multimap.
vector和List的区别:
- vector 迭代器中元素的插入可能引起迭代器失效(扩容);list中元素的插入和删除不会引起迭代器失效;
- vector没有提供sort成员函数,可以直接使用std::sort;std::sort要求ramdomAccessIterator,所以不能使用std::sort,但可以使用成员函数 list.sort();
- vector可以在常数时间求得size,list则不行,内部需要通过遍历来求size,因为list提供merge,spice等操作。
list.sort内部使用归并排序,std::sort内部使用introSort,其内部结合了快排、堆排和插入排序。vector和deque区别:
- deque可以在头部进行常数时间的插入和删除,vector不行
- deque没有容量概念,因为其内部是动态地将分段的连续空间组合而成,deque不会出现内存空间重分配的情况,只会在首部或者尾部增加新空间并连接起来。
- vector和deque都提供ramdomAccessIterator
- deque内部不连续,通过迭代器来维护其连续的假象;vector元素内部连续的,迭代器就是元素指针,很方便。
vector、list、deque的适用场景:
- 默认情况使用vector,适用于大多数场景,连续数组,支持随机访问;
- 经常需要在头部或者尾部插入或移除数据,则应该采用deque;
- 经常需要在容器中部进行插入、删除和移动,则应该使用List;
- 元素无序,但提供常数时间的查找,unorderd_set,unorderd_map(内部使用hash结构实现,unordered_map适用于key-value)
- 有序有序,对数时间的查找,set,map(内部使用红黑树实现)
STL容器读书笔记的更多相关文章
- Docker系列之Docker容器(读书笔记)
一.介绍 容器是独立运行的一个或一组应用,以及它们的运行态环境.对应的,虚拟机可以理解为模拟运行的一整套操作系统和排在上面的应用. 二.容器 2.1 启动容器 启动容器有两种方式,一种是基于镜像新建一 ...
- STL源码剖析读书笔记--第四章--序列式容器
1.什么是序列式容器?什么是关联式容器? 书上给出的解释是,序列式容器中的元素是可序的(可理解为可以按序索引,不管这个索引是像数组一样的随机索引,还是像链表一样的顺序索引),但是元素值在索引顺序的方向 ...
- STL源码分析读书笔记--第二章--空间配置器(allocator)
声明:侯捷先生的STL源码剖析第二章个人感觉讲得蛮乱的,而且跟第三章有关,建议看完第三章再看第二章,网上有人上传了一篇读书笔记,觉得这个读书笔记的内容和编排还不错,我的这篇总结基本就延续了该读书笔记的 ...
- STL源码剖析读书笔记之vector
STL源码剖析读书笔记之vector 1.vector概述 vector是一种序列式容器,我的理解是vector就像数组.但是数组有一个很大的问题就是当我们分配 一个一定大小的数组的时候,起初也许我们 ...
- Effective STL 读书笔记
Effective STL 读书笔记 标签(空格分隔): 未分类 慎重选择容器类型 标准STL序列容器: vector.string.deque和list(双向列表). 标准STL管理容器: set. ...
- Effective STL读书笔记
Effective STL 读书笔记 本篇文字用于总结在阅读<Effective STL>时的笔记心得,只记录书上描写的,但自己尚未熟练掌握的知识点,不记录通用.常识类的知识点. STL按 ...
- 《精通Spring 4.X企业应用开发实战》读书笔记1-1(IoC容器和Bean)
很长一段时间关注在Java Web开发的方向上,提及到Jave Web开发就绕不开Spring全家桶系列,使用面向百度,谷歌的编程方法能够完成大部分的工作.但是这种不系统的了解总觉得自己的知识有所欠缺 ...
- how tomcat works 读书笔记(二)----------一个简单的servlet容器
app1 (建议读者在看本章之前,先看how tomcat works 读书笔记(一)----------一个简单的web服务器 http://blog.csdn.net/dlf123321/arti ...
- Java编程思想——第17章 容器深入研究 读书笔记(三)
七.队列 排队,先进先出. 除并发应用外Queue只有两个实现:LinkedList,PriorityQueue.他们的差异在于排序而非性能. 一些常用方法: 继承自Collection的方法: ad ...
随机推荐
- P1147 连续自然数和
P1147 连续自然数和 题目描述 对一个给定的自然数 M ,求出所有的连续的自然数段,这些连续的自然数段中的全部数之和为 M . Solution 两点问题 弄两个点 \(l,r\) , 因为前缀和 ...
- 转:UIView之userInteractionEnabled属性介绍
属性作用 该属性值为布尔类型,如属性本身的名称所释,该属性决定UIView是否接受并响应用户的交互. 当值设置为NO后,UIView会忽略那些原本应该发生在其自身的诸如touch和keyboard等用 ...
- 基本UDP套接字编程
概述 使用TCP编写的应用程序和使用UDP编写的应用程序之间存在一些本质差异,其原因在于这两个传输层之间的差别:UDP是无连接不可靠的数据报协议,非常不同于TCP提供的面向连接的可靠字节流.然而相比T ...
- Linux清屏命令
1:clear 2:Ctrl+L 3:printf "\033c" 4:ALT+F8 By KillerLegend Ref:http://www.coolcoder.in/201 ...
- Liunx操作指令搜素引擎
链接:http://wangchujiang.com/linux-command/c/vi.html
- 如何利用mount命令挂载另一台服务器上的目录
文件服务器(被挂载机):192.168.1.100 操作机(挂载到机):192.168.1.200 也就是说,你在操作机上进行的操作,实际上都到文件服务器上去了: 1. 开启NFS服务: 在文件服务器 ...
- 当今最流行的Web项目管理工具精选
代码管理 以前各种开源项目的代码都是通过博客和个人网页来发布的.这种分享方式并不是最容易的一种,也不便于他人对代码做出贡献.下面是几个管理项目代码的工具,不管对于个人开发者还是团队开发者来说,它们都是 ...
- Docker 初相见
Docker 是一个开源的应用容器引擎,基于 Go 语言 并遵从Apache2.0协议开源. Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级.可移植的容器中,然后发布到任何流行的 Li ...
- 51nod1450 闯关游戏
题目来源: TopCoder 基准时间限制:1 秒 空间限制:131072 KB 分值: 320 一个游戏App由N个小游戏(关卡)构成,将其标记为0,1,2,..N-1.这些小游戏没有相互制约的性质 ...
- HAOI 2005 路由选择问题 (最短路+次短路)
问题描述 X城有一个含有N个节点的通信网络,在通信中,我们往往关心信息从一个节点I传输到节点J的最短路径.遗憾的是,由于种种原因,线路中总有一些节点会出故障,因此在传输中要避开故障节点. 任务一:在己 ...