机器学习之利用KNN近邻算法预测数据
前半部分是简介, 后半部分是案例
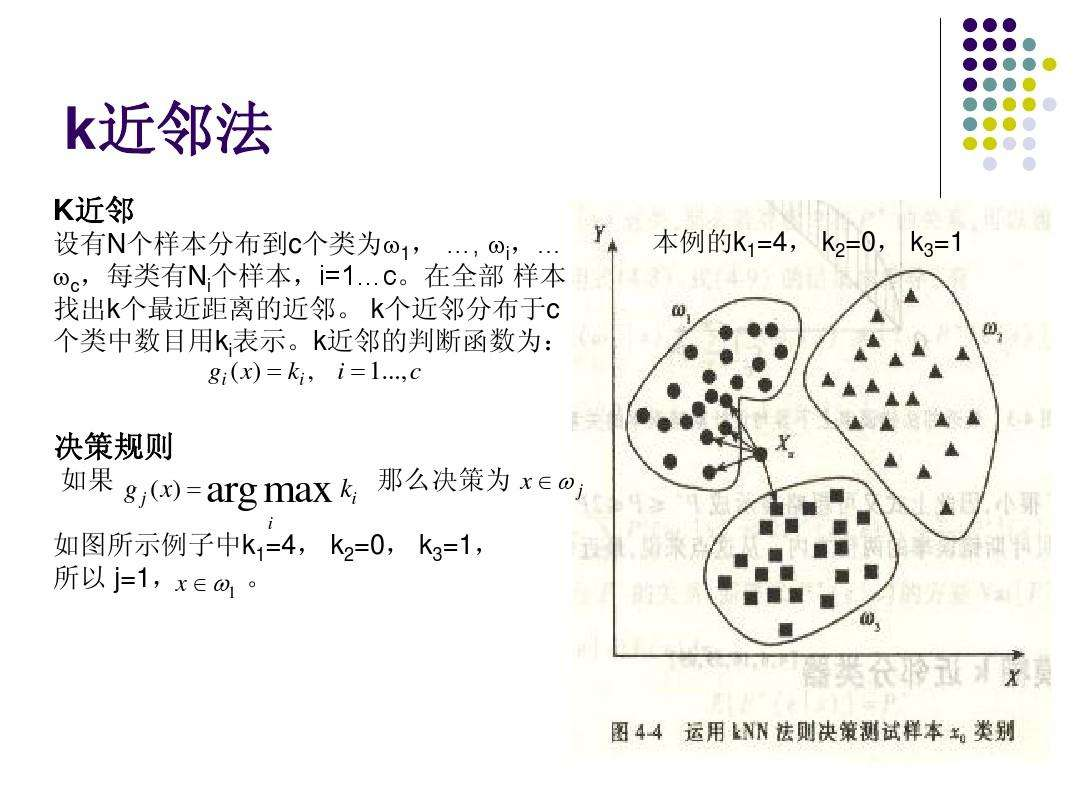
KNN近邻算法:
简单说就是采用测量不同特征值之间的距离方法进行分类(k-Nearest Neighbor,KNN)
优点: 精度高、对异常值不敏感、无数据输入假定
缺点:时间复杂度高、空间复杂度高
- 1、当样本不平衡时,比如一个类的样本容量很大,其他类的样本容量很小,输入一个样本的时候,K个临近值中大多数都是大样本容量的那个类,这时可能就会导致分类错误。改进方法是对K临近点进行加权,也就是距离近的点的权值大,距离远的点权值小。
- 2、计算量较大,每个待分类的样本都要计算它到全部点的距离,根据距离排序才能求得K个临近点,改进方法是:先对已知样本点进行剪辑,事先去除对分类作用不大的样本。
适用数据范围:
- 标称型(离散型):标称型目标变量的结果只在有限目标集中取值,如真与假(标称型目标变量主要用于分类)
- 数值型:数值型目标变量则可以从无限的数值集合中取值,如0.100,42.001等 (数值型目标变量主要用于回归分析)
工作原理:
- 训练样本集—>存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。输人没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前K个最相似的数据,这就是K-近邻算法中K的出处,通常K是不大于20的整数。 最后 ,选择K个最相似数据中出现次数最多的分类,作为新数据的分类。
- 电影类别KNN分析(图片来源于网络)
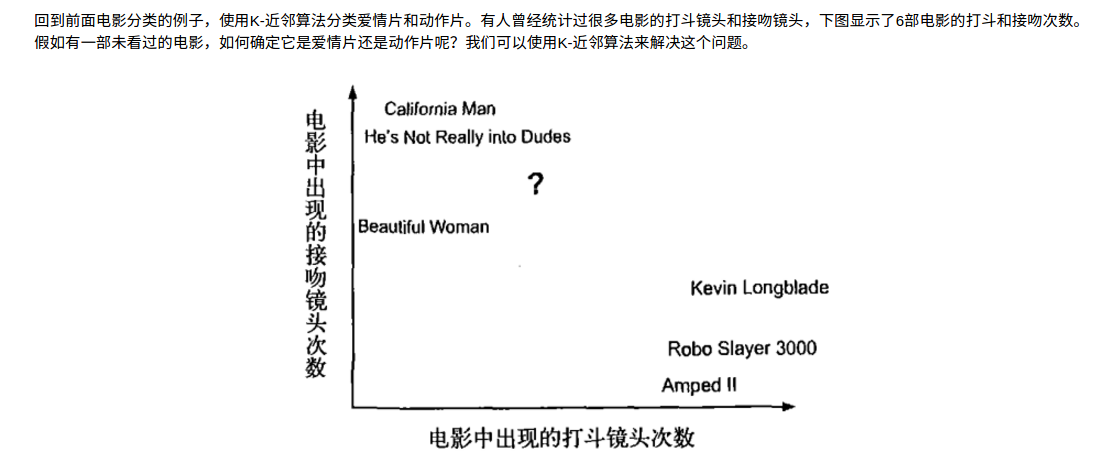

- 欧氏距离(Euclidean Distance,欧几里得度量)

- 计算过程图
- 案例
代码都是在 jupyter notebook 中写的
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
%matplotlib inline
# 以上导入的包都是自己习惯性导入, 因为随时都可能会用到, 就每次先把这些都导入了 #这儿是我自己写了一个excel表格,方便快速的读取数据, 演示使用, 就不用series或者dataframe写了
film = pd.read_excel('films.xlsx',sheet_name=1)
#输入film后出现表格
fil

# 电影的样本特征
train=film[['动作镜头','接吻镜头']]
# 样本标签,即要预测的标签,这儿要预测新数据是属于什么类别的电影
target=film['电影类别']
# 创建机器学习模型,需要导入
from sklearn.neighbors import KNeighborsClassifier
# 创建对象, 这儿的数据因为是离散型, 所以使用KNeighborsClassifier,
knn=KNeighborsClassifier()
# 对knn模型进行训练, 传入样本特征 和 样本标签
# 构建函数原型、构建损失函数、求损失函数最优解
knn.fit(train,target)
knn
当输入knn后出现如下代码, 表示训练完成
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=5, p=2,
weights='uniform')
# 这儿随意写3个样本数据,需要按照样本数据的维度来写
cat=np.array([[5,19],[21,6],[23,24]])
# cat=np.array([[21,4]]) 也可以写1个
# 使用predict函数对数据进行预测
knn.predict(cat)
运行会出现下图:

预测完成 ! 成功判断出3个新样本的归属类别
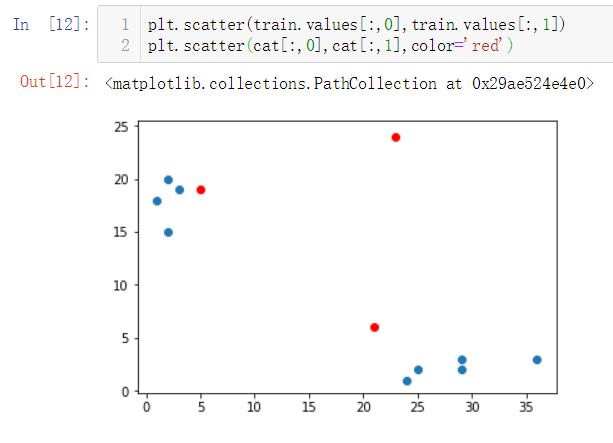
接下来也可以绘制图, 直观的查看近邻情况
# scatter画出来的是散点图, 取数据使用 .values,二维数组中, 一维全部取出, 二维取0,表示出来就是[:,0]
plt.scatter(train.values[:,0],train.values[:,1])
# scatter可以有一些属性, 下边的color可以自定义显示的颜色
plt.scatter(cat[:,0],cat[:,1],color='red')
效果图为:
在使用KNN近邻算法时, 注意要分清楚样本集, 样本特征,样本标签
技术交流可以留言评论哦 ! 虚心学习, 不忘初心, 共同奋进 !
机器学习之利用KNN近邻算法预测数据的更多相关文章
- KNN近邻算法
K近邻(KNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表.kNN算法的核 ...
- 机器学习入门KNN近邻算法(一)
1 机器学习处理流程: 2 机器学习分类: 有监督学习 主要用于决策支持,它利用有标识的历史数据进行训练,以实现对新数据的表示的预测 1 分类 分类计数预测的数据对象是离散的.如短信是否为垃圾短信,用 ...
- 机器学习03:K近邻算法
本文来自同步博客. P.S. 不知道怎么显示数学公式以及排版文章.所以如果觉得文章下面格式乱的话请自行跳转到上述链接.后续我将不再对数学公式进行截图,毕竟行内公式截图的话排版会很乱.看原博客地址会有更 ...
- 02机器学习实战之K近邻算法
第2章 k-近邻算法 KNN 概述 k-近邻(kNN, k-NearestNeighbor)算法是一种基本分类与回归方法,我们这里只讨论分类问题中的 k-近邻算法. 一句话总结:近朱者赤近墨者黑! k ...
- 机器学习 Python实践-K近邻算法
机器学习K近邻算法的实现主要是参考<机器学习实战>这本书. 一.K近邻(KNN)算法 K最近邻(k-Nearest Neighbour,KNN)分类算法,理解的思路是:如果一个样本在特征空 ...
- 机器学习随笔01 - k近邻算法
算法名称: k近邻算法 (kNN: k-Nearest Neighbor) 问题提出: 根据已有对象的归类数据,给新对象(事物)归类. 核心思想: 将对象分解为特征,因为对象的特征决定了事对象的分类. ...
- 《机器学习实战》-k近邻算法
目录 K-近邻算法 k-近邻算法概述 解析和导入数据 使用 Python 导入数据 实施 kNN 分类算法 测试分类器 使用 k-近邻算法改进约会网站的配对效果 收集数据 准备数据:使用 Python ...
- 机器学习:1.K近邻算法
1.简单案例:预测男女,根据身高,体重,鞋码 import numpy as np import matplotlib import sklearn from skleran.neighbors im ...
- 机器学习实战笔记--k近邻算法
#encoding:utf-8 from numpy import * import operator import matplotlib import matplotlib.pyplot as pl ...
随机推荐
- Qt如何设置应用ico图标
第一步,创建ico文件.将ico图标文件复制到工程文件夹目录中(注意必须是图标文件,任何格式的改后缀都不行) ,重命名为"myico.ico“.然后在该目录中右击,新建文本文档,并输入一行代 ...
- QT导入libcurl支持HTTPS
对于我这种不会编译的人来说,必须找到已经编译好的DLL文件,以及头文件才能使用. 幸运的在这个网站https://stackoverflow.com/questions/28137379/libcur ...
- SQLServer创建链接服务器
--SQLServer创建链接服务器----1.访问接口中Oracle接口 属性 选择 允许进程内-- --删除链接服务器EXEC master.dbo.sp_dropserver @server=N ...
- JPA规范实现
JPA全称Java Persistence API.JPA通过JDK 5.0注解或XML描述对象-关系表的映射关系,并将运行期的实体对象持久化到数据库中. JPA 是 JCP定义的一种规范,要使用此规 ...
- java面向切面编程总结-面向切面的本质
面向切面的本质:定义切面类并将切面类的功能织入到目标类中: 实现方式:将切面应用到目标对象从而创建一个新的代理对象的过程.替换: 使用注解@Aspect来定义一个切面,在切面中定义切入点(@Point ...
- R3.4.0安装包时报错“需要TRUE/FALSE值的地方不可以用缺少值”,需升级到R3.5.0
错误: 解决方案: 升级R3.5.0后,解决:
- HDU 1251 统计难题(字典树入门模板题 很重要)
统计难题 Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 131070/65535 K (Java/Others)Total Submi ...
- K2 BPM介绍(2)
K2 BPM介绍(2) 上一篇已经讲了一些K2 BPM基本特性,本遍讲K2 BPM大概的组件以及组件关系. K2 BPM组件 K2 BPM分别由以下组件构成: K2产品已经发展很多年,所以它有很多版本 ...
- Hadoop应用开发,常见错误
错误1:在windows执行mr Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.had ...
- iOS开发过程中易犯的小错误
addGestureRecognizer(_:) 一个手势对象只绑定一个view // 只有最后一个imgv有点击事件 let tap = UITapGestureRecognizer(target: ...