数据库性能高校:CPU使用过高(下)
CPU使用率过高的常见原因
查询优化器会尽量从CPU,IO和内存资源成本最小的角度,找到最高效的数据访问方式。如果没有正确的索引,或者写的语句本身就会忽略索引,
又或者不准确的统计信息等情况下,查询计划可能不是最优的。
有些查询计划可能对只对某种条件下的查询是高效,而不是所有条件下都是。
缺失索引
索引的缺失,会导致查询处理的行数大大超出必要的行数,从而加重CPU和IO的负载。简单的例子:

SELECT per .FirstName ,
per.LastName ,
p.Name ,
p.ProductNumber ,
OrderDate ,
LineTotal ,
soh.TotalDue
FROM Sales.SalesOrderHeader AS soh
INNER JOIN Sales.SalesOrderDetail sod
ON soh.SalesOrderID = sod.SalesOrderID
INNER JOIN Production.Product AS p ON sod.ProductID = p.ProductID
INNER JOIN Sales.Customer AS c ON soh.CustomerID = c.CustomerID
INNER JOIN Person.Person AS per
ON c.PersonID = per.BusinessEntityID
WHERE LineTotal > 25000 SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times:
CPU time = 452 ms, elapsed time = 458 ms.
上面的查询使用AdventureWorks2008数据库,字段LineTotal上没有索引,会导致SalesOrderDetail全表扫描。然后创建如下索引后,改善很明显:
CREATENONCLUSTEREDINDEX
idx_SalesOrde
ON
Sales.SalesOrderDetail (LineTotal)
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 8 ms.
过期的统计信息
查询优化器使用统计信息计算各种查询操作的基数(开销)。查询操作的成本(cost)又决定了查询计划的成本。过期的统计信息会导致生成非最优的查询计划,
如预估成本很低,但实际成本很高的计划。
最常见就是预估行数很少,并选择了那些适合少量数据的操作(如嵌套循环,LookUp),但当实际执行时要处理的行数却很多,查询效率就变得很低。
可以通过SSMS或者set statistics profile on为索引查找和扫描操作,返回实际行数与预估行数做比较。如果两者差异较大,就很有可能统计信息过期了。
过期时,可以使用update statistics tableName更新表上所有的统计信息,update statistics tableName statisticsName更新指定统计信息。
为了防止统计信息过期的问题,有如下三种方法:
a. 开启数据库的Auto_Update_Statistics选项或者用定时作业更新全库的统计信息。
b. 如果某些索引的自动更新统计信息被禁用,则需要指定STATISTICS_NORECOMPUTE=OFF重建索引开启。
c. 对于某些经常因为统计信息过期而导致性能问题的统计信息,可以创建定时作业频繁地更新它们。
非SAGR谓词
SAGR=Search Agrument.简单说就是能够使用索引查找的谓词。列应该直接与表达式进行比较则符合SAGR,如WHERE SomeFunction(Column) = @Value就符合,
WHERE Column = SomeOtherFunction(@Value) 则符合。注意LIKE和BETWEEN也是SAGR谓词。
非SAGR会导致表或者索引扫描,它的影响跟缺失索引类似。使得CPU处理大量非必需的数据行。下面查询会导致索引扫描:
SELECT soh .SalesOrderID ,
OrderDate ,
DueDate ,
ShipDate ,
Status ,
SubTotal ,
TaxAmt ,
Freight ,
TotalDue
FROM Sales.SalesOrderheader AS soh
INNER JOIN Sales.SalesOrderDetail AS sod
ON soh.SalesOrderID = sod.SalesOrderID
WHERE CONVERT(VARCHAR(10), sod.ModifiedDate , 101) = '01/01/2010'
改写成如下则会使用索引查找:
SELECT soh .SalesOrderID ,
OrderDate ,
DueDate ,
ShipDate ,
Status ,
SubTotal ,
TaxAmt ,
Freight ,
TotalDue
FROM Sales.SalesOrderheader AS soh
INNER JOIN Sales.SalesOrderDetail AS sod ON soh.SalesOrderID = sod.SalesOrderID
WHERE sod.ModifiedDate >= '2010/01/01'
AND sod.ModifiedDate < '2010/01/02'
UPPER,LOWER,LTRIM,RTRIM,ISNULL这些经常会被滥用,甚至用于WHERE和JOIN条件中。
在不区分大小写排序规则中,大小写被视为相等的,像UPPER,LOWER这种拖累性能的函数就不必要用了。
SQL中字符串比较会忽略末尾空格,所以RTRIM也没必要用。
下面两个过滤条件,前者,字段NULL值转换成0从而被排除;后者中,其实NULL值与任何值比较操作都不会返回TURE,而被排除。
NULL值只在IS NULL或者IS NOT NULL检查时才可能返回TRUE。所以是等效的,但后者才能使用索引查找。
WHERE ISNULL(SomeCol,0) > 0
WHERE SomeCol > 0
隐式转换
隐式转换发生在比较两个不同数据类型时。SQL不能对不同类型数据进行比较,所以查询优化器会在比较操作前把低优先级的数据类型转换成高优先级的数据类型再比较。
这跟非SARG谓词一样,将不能使用Index Seek,从而处理很多不必要的数据行,增加CPU开销。最常见例子是使用NVARCHAR类型的参数与VARCHAR类型的列进行比较。如:
SELECTp .FirstName , p.LastName , c.AccountNumber
FROM
Sales.Customer ASc
INNER JOINPerson.Person AS p
ON c.PersonID = p.BusinessEntityID
WHERE AccountNumber = N'AW00029594'
上面的查询导致一个非聚集索引扫描,在Filter操作中会看有一个COVERT_IMPLICIT。
为了避免隐式转换:
1. JOIN的列,数据类型尽量相同
2. 与列比较时,任何参数,变量和常量的类型要和列的类型相同
3. 当参数,变量或常量的类型与要比较的列不同时,斟酌地使用类型转换函数,使其与列类型相同
4. 有些数据访问组件和开发框架会把字符串类型默认地设置为NVARCHAR
参数探测(Parameter Sniffing)
参数探测是SQL Server为存储过程,函数和参数化查询创建查询计划时用到的处理方式。当首次编译查询计划时,SQL Server会检测或者探测输入参数的值并结合统计信
息,预估受影响的行数,
并以之估算查询计划成本。当根据传入的参数值创建查询计划,得到的受影响行数不是典型的情况时,就产生问题了。参数探测只出现在编译和重编译时,之后的存储过程,函数和
参数化查询,
会重用此查询计划。最初编译时只有输入参数的值会被探测到,本地变量是没有值的。如果批处理中的语句被重编译,则参数和变量将会被赋值并探测到。示例如下:
CREATEPROCEDUREuser_GetCustomerShipDates
( @ShipDateStart DATETIME
, @ShipDateEnd DATETIME
)
AS
SELECT CustomerID , SalesOrderNumber
FROM Sales.SalesOrderHeader
WHERE ShipDate BETWEEN @ShipDateStart AND @ShipDateEnd
GO
Sales.SalesOrderHeader表的ShipDate字段范围是2004-08-07~2011-08-07,并创建非聚集索引:
CREATENONCLUSTEREDINDEX IDX_ShipDate_ASC
ON Sales.SalesOrderHeader (ShipDate )
GO
首先我们执行两次SP,并用DBCC FREEPROCCACHE在运行前清空计划缓存:
DBCC FREEPROCCACHE
EXEC user_GetCustomerShipDates '2001/07/08', '2004/01/01'
EXEC user_GetCustomerShipDates '2001/07/10', '2001/07/20'

==FIRST EXECUTION (LARGE DATE RANGE)=== (Table 'SalesOrderHeader'. Scan count 1, logical reads 686, physical reads 0. SQL Server Execution Times:
CPU time = 16 ms, elapsed time = 197 ms. SQL Server Execution Times:
CPU time = 16 ms, elapsed time = 197 ms. ==SECOND EXECUTION (SMALL DATE RANGE)=== Table 'SalesOrderHeader'. Scan count 1, logical reads 686, physical reads 0. SQL Server Execution Times:
CPU time = 15 ms, elapsed time = 5 ms. SQL Server Execution Times:
CPU time = 15 ms, elapsed time = 5 ms.
DBCC FREEPROCCACHE
EXEC user_GetCustomerShipDates '2001/07/10', '2001/07/20'
EXEC user_GetCustomerShipDates '2001/07/08', '2004/01/01'
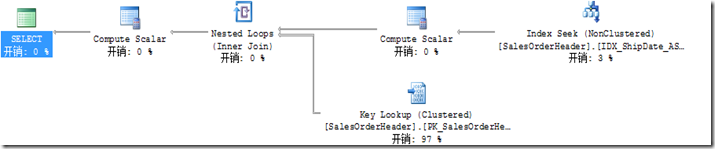
==FIRST EXECUTION (SMALL DATE RANGE)=== Table 'SalesOrderHeader'. Scan count 1, logica
ahead reads 0, lob logical reads 0, lob physic SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms. ==SECOND EXECUTION (LARGE DATE RANGE)=== Table 'SalesOrderHeader'. Scan count 1, logica SQL Server Execution Times:
CPU time = 47 ms, elapsed time = 182 ms.
CREATE PROCEDURE user_GetCustomerShipDates
(
@ShipDateStart DATETIME ,
@ShipDateEnd DATETIME
)
AS
SELECT CustomerID ,
SalesOrderNumber
FROM Sales.SalesOrderHeader
WHERE ShipDate BETWEEN @ShipDateStart AND @ShipDateEnd
OPTION ( OPTIMIZE FOR ( @ShipDateStart = '2001/07/08' ,
@ShipDateEnd = '2004/01/01' ) )
GO
在创建存储过程可以指定WITH RECOMPILE重编译选项。指定后SP每次执行时会基于当前参数值重新编译,同时也不缓存执行计划。但是这样会增加执行处理时间。
CREATE PROCEDURE user_GetCustomerShipDates
(
@ShipDateStart DATETIME ,
@ShipDateEnd DATETIME
)
WITH RECOMPILE
AS
SELECT CustomerID ,SalesOrderNumber
FROM Sales.SalesOrderHeader
WHERE ShipDate BETWEEN @ShipDateStart AND @ShipDateEnd
当SP中的多个语句,只是某个语句会产生参数探测问题,则可以对这个语句使用OPTION(RECOMPILE)查询提示。这样每次执行时只会对这个语句重编译,
而不像WITH RECOMPILE对整个SP重编译。如果可能尽量使用查询提示,减少重编译的影响范围和开销。
CREATE PROCEDURE user_GetCustomerShipDates
(
@ShipDateStart DATETIME ,
@ShipDateEnd DATETIME
)
AS
SELECT CustomerID ,
SalesOrderNumber
FROM Sales.SalesOrderHeader
WHERE ShipDate BETWEEN @ShipDateStart AND @ShipDateEnd
OPTION ( RECOMPILE )
即席非参数化查询
即席查询不能重用执行计划,每次执行时都会被编译,消耗大量资源(特别是CPU)。像下面的查询,每次因为WHERE条件中参数值不同而产生不同的执行计划。
虽然SQL Server有简单参数化(Simple Parameterization)的技术,但是此语句相对”太复杂”了。
SELECT soh .SalesOrderNumber ,
sod.ProductID
FROM Sales.SalesOrderHeader AS soh
INNER JOIN Sales.SalesOrderDetail AS sod
ON soh.SalesOrderID = sod.SalesOrderID
WHERE soh.SalesOrderNumber = 'SO43662'
非参数化查询主要有两方面的影响:
1. 即席查询产生的一次性的查询计划会填满计划缓存。由此带来的内存压力,会让那些本可以重用的计划迫于内存压力而被清除掉等等。
2. 编译这些一次性的查询计划浪费了大量的CPU资源。
可以用下面的计数器来判断即席非参数化查询的影响程度:
SQLServer: SQL Statistics: SQL Compilations/Sec
SQLServer: SQL Statistics: Auto-Param Attempts/Sec
SQLServer: SQL Statistics: Failed Auto-Param/Sec
解决的方法有:
1. 修改应用程序代码,使发送到SQL Server语句尽量被参数化。
2. 在SQL Server 2005及以上版本中,能在数据库级别设定强制参数化。但可能会带来类型参数探测一样的问题。
ALTER DATABASE AdventureWorks SET PARAMETERIZATION FORCED
3. SQL Server 2008及以上版本中,启用实例级别的optimize for ad hoc workloads。
启用后当即席查询第一次执行时只保存查询计划的一个“存根”,第二次执行时则缓存执行计划。“存根”使用很少的内存,
这样就减少了那些本可以重用的执行计划,因内存压力而被清除掉的机率。
EXEC sp_configure 'show advanced options',1
RECONFIGURE
EXEC sp_configure 'optimize for ad hoc workloads',1
RECONFIGURE
不恰当的并行
并行查询是把一个查询的工作分解成多个线程执行,每一个线程使用单独的计划程序。查询并行发生在操作符(Operator)级别。
查询优化器在编译执行计划时总是会让其尽可能的快。如果执行计划的预估成本连续超过cost threshold of prillelism,同时SQL Server可用
CPU个数多于1个,并且max degree of prallelism为0或大于1,则产生的执行计划将会包括并行。
并行查询通过水平分割输入数据,然后分布到多个逻辑CPU上同时执行,从而减少执行时间。对于数据仓库和报表系统会有好处,对于OLTP系统
则并行会占用过多的CPU资源,而其它的请求不得不等待CPU资源。
SQL Server有两个控制并行执行的sp_configure选项:
cost threshold of prillelism:控制优化器为查询使用并行执行的阀值
max degree of prallelism:避免单个查询用完所有可用的处理器内核
cost threshold of prallelism的默认值为5秒。在较大的数据库上,默认阀值可能太低了,会导致并行执行的资源争用。
可以通过下面的查询获取存于计划缓存中的并行执行计划,做为调整cost threshold of prillelism的重要参考依据:
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED ; WITH XMLNAMESPACES
(DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT query_plan AS CompleteQueryPlan ,
n.value ('(@StatementText)[1]', 'VARCHAR(4000)' ) AS StatementText ,
n.value ('(@StatementOptmLevel)[1]', 'VARCHAR(25)')
AS StatementOptimizationLevel ,
n.value ('(@StatementSubTreeCost)[1]', 'VARCHAR(128)')
AS StatementSubTreeCost ,
n.query ('.' ) AS ParallelSubTreeXML ,
ecp.usecounts ,
ecp.size_in_bytes
FROM sys .dm_exec_cached_plans AS ecp
CROSS APPLY sys .dm_exec_query_plan(plan_handle) AS eqp
CROSS APPLY query_plan.nodes
('/ShowPlanXML/BatchSequence/Batch/Statements/StmtSimple')
AS qn ( n )
WHERE n.query ('.' ).exist ('//RelOp[@PhysicalOp="Parallelism"]' ) = 1
并行中使用到处理器数是取自后面三者中的最小值:max degree of prallelis的值,可用的处理器数和MAXDOP查询提示(会覆盖max degree of prallelis指定的值)。
合适的max degree of prallelis值取决于工作负载类型和硬件资源支撑并行开销的能力。很多砖家推荐将其设定为1,前提是你的系统是真正的单独的OLTP系统,
只有大量的并发的小事务。对于NUMA和SMP系统的设定是不同的。SQL Server 2008及以上版本利用resource governor能将max degree of prallelis绑定到特定的查询组。
当系统出现并行性能问题时,通常会CXPACKET等待会比较明显,其实它很冤,它只是个表面现象。根本原因还是要查看产生CXPACKET等待的子线程的等待类型。
如果伴随着如IO_COMPLETION,ASYNC_IO_COMPLETION,PAGEIOLATCH_*的等待,则要提高IO性能;
如果伴随着LATCH_* and SOS_SCHEDULER_YIELD,则表示并行本身导致了性能问题,如果此时还有ACCESS_METHODS_DATASET_PARENT等待,则执行的并行度是根本原因。
出现这些问题时首先应该优化并行执行的语句,其次才是结合max degree of prallelis和cost threshold of prillelism两者进行限制,再次是提升硬件。
在硬件暂时无法提升时,只能对并行做一定限制,做折中和权衡考量。
在SQL Server 2005,有个关于TokenAndPermUserStore的CPU问题。当数据库用户很多,adhoc和动态查询很多且非AWE内存空间很多时, 可能会出现CMEMTHREAD大量等待和TokenAndPermUserStore使用过量并持续增长。微软已经推出的解决方案http://support.microsoft.com/kb/927396。
长期的解决方案是修改程序架构,尽量减少可能导致此问题的adhoc和动态查询的使用。
短期解决方案是:
1. 给应用程序账户提升为sysadmin,从而规避权限检查而极大的减少TokenAndPermUserStore的缓存使用量。这是有安全风险的
2. 使用DBCC FREESYSTEMCACHE ('TokenAndPermUserStore'),定期清理这一部分缓存。
3. SQL Server 2005 SP2及以上版本,可以使用Trace Flag 4618&4610.4610限制缓存条目为1024,两者都启用则限制缓存条目为8192.
4. SQL Server 2005 SP3及以上版本,使用Trace Flag 4621,可以设定缓存配额。 http://support.microsoft.com/kb/959823。
5. SQL Server 2008有access check cache bucket count & access check cache quota两个sp_configure项,
用于设置TokenAndPermUserStore的hash bucket数量和缓存条目数。
关于超线程和BIOS节能控制选项
很多砖家推荐SQL Server服务器不宜开启超线程,根据作者的研究,这种推荐做法在过去是对的,现在不一定是对的。
在过去,超线出来的CPU会一起共享板载缓存,而这个缓存是KB量级的。而且windows 2000本身不支持超线程,“超”出来的它会认为是物理CPU。“CPU”一多就会造成缓存命中率低下,进而影响性能。 而很多DBA管理的OLTP&DSS的混合环境,那么超线程对于那些DSS型查询的提升,在混合环境中很不明显,甚至有时会导致需要迅速响应OLTP弄查询等待。
现在,硬件和软件进步了,现在板载缓存量级都是MB级的了,CPU缓存命中率不再是问题。而windows 2003也支持超线程了。而且现在OLTP,OLAP,DW等系统一般会隔离使用。
当然是否开启还是需要经过测试才能最终决定。
绿色节能现在也是硬件和服务器一种标准了,自动降低系统中某些暂时未用到的硬件能耗和CPU频率。BioS中可以设定为硬件自己控制或者OS控制。
windows 2008&r2默认设定电源计划为“平衡”,以允许其切换到节能模式。有时在windows 2008 or R2的新服务器升级系统一段时间后,性能下降明显,这就是电源管理造成的CPU降频导致的。
windows的性能计数器 % Processor Usage 是已使用CPU频率除以可用CPU频率得到的。如果CPU被降频了,那么这个计算器会较高,会让人误会成工作负载很高。
可以使用CPU-Z来检测CPU的状态。
建议将windows的电源计划调定为“高性能”,并且检查BIOS的电源控制选项,设定为OS Control.
总结:
1. SQL SERVER CPU调整的地方很少,很多时候还是因为语句性能低下导致CPU使用过高。
2. 解决参数嗅探问题,还有拼动态语句,使用plan_guide等方法。
来源:http://www.cnblogs.com/Joe-T/p/3261177.html
数据库性能高校:CPU使用过高(下)的更多相关文章
- 数据库性能高校:CPU使用过高(上)
CPU使用率过高问题很容易被发现,但是诊断却不是很容易.CPU使用过高很多时候会成为其它问题的替罪羊,所以在确认和故障诊断时要抽丝剥茧. 调查CPU压力 三个主要的工具:性能监视器,SQLTrace, ...
- 性能测试问题_Mysql数据库服务器的CPU占用很高
MySQl服务器CPU占用很高 1. 问题描述 一个简单的接口,根据传入的号段查询号码归属地,运行性能测试脚本,20个并发mysql的CPU就很高,监控发现只有一个select语句,且表建立了索引 ...
- 性能优化-CPU占用过高问题排查
1. 性能优化是什么? 1.1 性能优化就是发挥机器本来的性能 1.2 性能瓶颈在哪里,木桶效应. CPU占用过高 1.现象重现 CPU占用过高一般情况是代码中出现了循环调用,最容易出现的情况有几 ...
- 《Troubleshooting SQL Server》读书笔记-CPU使用率过高(下)
<Troubleshooting SQL Server>读书笔记-CPU使用率过高(下) 第三章 High CPU Utilization. CPU使用率过高的常见原因 查询优化器会尽量从 ...
- [Oracle]Oracle数据库CPU利用率很高解决方案
Oracle数据库经常会遇到CPU利用率很高的情况,这种时候大都是数据库中存在着严重性能低下的SQL语句,这种SQL语句大大的消耗了CPU资源,导致整个系统性能低下.当然,引起严重性能低下的SQL语句 ...
- 性能分析(5)- 软中断导致 CPU 使用率过高的案例
性能分析小案例系列,可以通过下面链接查看哦 https://www.cnblogs.com/poloyy/category/1814570.html 前言 软中断基本原理,可参考这篇博客:https: ...
- Linux下java进程CPU占用率高分析方法
Linux下java进程CPU占用率高分析方法 在工作当中,肯定会遇到由代码所导致的高CPU耗用以及内存溢出的情况.这种情况发生时,我们怎么去找出原因并解决. 一般解决方法是通过top命令找出消耗资源 ...
- 性能调优之MYSQL高并发优化下
三.算法的优化 尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写..使用基于游标的方法或临时表方法之前,应先寻找基于集的解决方案来解决问题,基于集的方法通常更有效 ...
- Linux下分析某个进程CPU占用率高的原因
Linux下分析某个进程CPU占用率高的原因 通过top命令找出消耗资源高的线程id,利用strace命令查看该线程所有系统调用 1.top 查到占用cpu高的进程pid 2.查看该pid的线程 ...
随机推荐
- 如何实现Azure虚拟网络中点到站VPN的自动重连
在Windows Azure早期版本中,用户要在某台Azure平台之外的机器与Azure平台内部的机器建立专用连接,可以借助Azure Connect这个功能.当前的Azure版本,已经没有Az ...
- bat处理打开关门exe
@echo off rem rem 注释 tastkill /f /im a.exe cd %CD% %CD:~0,1%: cd %Cd%b start %CD%a.exe cd .. %CD:~0 ...
- 美工代码注意事项(html+div+css+js)
window.location.href的target控制 在使用框架时,经常会对框架子页面进行页面引导的情况,如果只是简单的设置location. href="",会使得整个页面 ...
- 一步一步写一个简单通用的makefile(一)
经常会用写一些小的程序有的是作为测试,但是每次都需要写一些简单的GCC 命令,有的时候移植一些项目中的部分代码到小程序里面进行测试,这个时候GCC 命令并不好些,如果写啦一个比较常用的makefile ...
- 初识chromium thread的实现
接触chromium已有一段时间,写点东西学习一下吧. 首先说一下用法,如何利用chromium封装好的thread类来开一个线程.在base里有一个封装该类的头文件thread.h,include它 ...
- 小Q书桌的下载、安装和使用
最近,无意之间,在某大牛电脑里,使用到了这款软件.感谢! 确实,挺实用和方便的,强烈推荐!!! 1. 下载 http://qdesk.qq.com/ 2. 安装 3. 使用 多么方便啊!
- Power of Cryptography
//只用一行核心代码就可以过的天坑题目............= = 题目: Description Current work in cryptography involves (among othe ...
- ASP.NET- 播放视频代码
在网上找的,还不错,支持很多格式.只需要在页面放个lable,建一个放视频文件的文件夹movie,加入代码: protected void Page_Load(object sender, Event ...
- JDBC——事物管理
案例:银行转账问题,数据库如下 相关API setAutoCommit(boolean autoCommit) 将此连接的自动提交模式设置为给定状态.设置事务是否自动提交如果设置为false,表示手 ...
- java版本 ueditor 在线编辑器 配置
上传文件大小的配置 1. ueditor\dialogs\video\video.js 搜索 file_size_limit 修改这个数值 (这是前台 flash的限制) 2. ueditor ...