第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启
第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启
scrapy的每一个爬虫,暂停时可以记录暂停状态以及爬取了哪些url,重启时可以从暂停状态开始爬取过的URL不在爬取
实现暂停与重启记录状态
1、首先cd进入到scrapy项目里
2、在scrapy项目里创建保存记录信息的文件夹
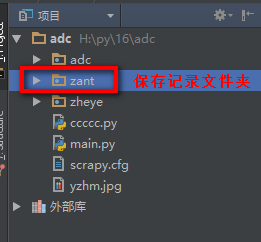
3、执行命令:
scrapy crawl 爬虫名称 -s JOBDIR=保存记录信息的路径
如:scrapy crawl cnblogs -s JOBDIR=zant/001
执行命令会启动指定爬虫,并且记录状态到指定目录
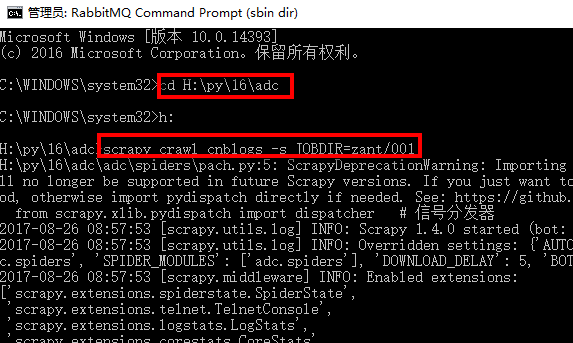
爬虫已经启动,我们可以按键盘上的ctrl+c停止爬虫
停止后我们看一下记录文件夹,会多出3个文件
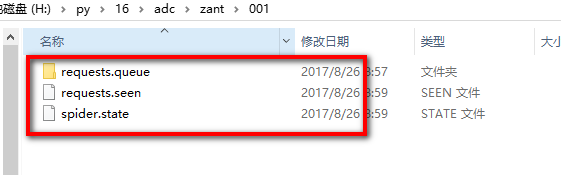
其中的requests.queue文件夹里的p0文件就是URL记录文件,这个文件存在就说明还有未完成的URL,当所有URL完成后会自动删除此文件
当我们重新执行命令:scrapy crawl cnblogs -s JOBDIR=zant/001 时爬虫会根据p0文件从停止的地方开始继续爬取,
第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启的更多相关文章
- 第三百五十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—chrome谷歌浏览器无界面运行、scrapy-splash、splinter
第三百五十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—chrome谷歌浏览器无界面运行.scrapy-splash. splinter 1.chrome谷歌浏览器无界面运行 chrome ...
- 第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目 scrapyd模块是专门用于部署scrapy项目的,可以部署和管理scrapy项目 下载地址:h ...
- 第三百六十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作、增、删、改、查
第三百六十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作.增.删.改.查 elasticsearch(搜索引擎)基本的索引 ...
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
- 第三百五十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy信号详解
第三百五十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy信号详解 信号一般使用信号分发器dispatcher.connect(),来设置信号,和信号触发函数,当捕获到信号时执行 ...
- 第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图 1.基本概念 2.反爬虫的目的 3.爬虫和反爬的对抗过程以及策略 scra ...
- 第三百四十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—通过downloadmiddleware中间件全局随机更换user-agent浏览器用户代理
第三百四十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—通过downloadmiddleware随机更换user-agent浏览器用户代理 downloadmiddleware介绍中间件是 ...
- 第三百四十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器
第三百四十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器 编写spiders爬虫文件循环 ...
- Python分布式爬虫打造搜索引擎完整版-基于Scrapy、Redis、elasticsearch和django打造一个完整的搜索引擎网站
Python分布式爬虫打造搜索引擎 基于Scrapy.Redis.elasticsearch和django打造一个完整的搜索引擎网站 https://github.com/mtianyan/Artic ...
- 四十六 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
前面我们讲到的elasticsearch(搜索引擎)操作,如:增.删.改.查等操作都是用的elasticsearch的语言命令,就像sql命令一样,当然elasticsearch官方也提供了一个pyt ...
随机推荐
- Fetch API 接口参考
前言 Fetch API是新的ajax解决方案,用于解决古老的XHR对象不能实现的问题,Fetch API 提供了一个获取资源的接口(包括跨域请求),任何使用过 XMLHttpRequest 的人都能 ...
- [Windows Azure] How to Scale a SQL Database Solution
How to Scale a SQL Database Solution On Windows Azure, database scalability is synonymous with scale ...
- 每日英语:Why Rate Your Marriage? A Numerical Score Can Help Couples Talk About Problems
When marriage therapist Sharon Gilchrest O'Neill met with new clients recently, she asked them why t ...
- hive外部表删除遇到的一个坑
hive外部表删除遇到的一个坑 操作步骤 创建某个表(create external table xxx location xxx) 插入数据(insert xxx select xxx from x ...
- BOE系统与BW系统间的单点登录(注:这里先简单写一下,改天有时间再进行详细的描述)
1,在BOE系统内进行配置,将BW系统内的用户信息导入BOE 2,在BOE系统内定义这些导入用户对BOE对象有哪些权限 3,用户使用BW系统的用户名密码登录BOE系统:BOE将登录凭证转发给BW系统让 ...
- 一个实体对象不能由多个 IEntityChangeTracker 实例引用。
错误代码 public bool addSubOptionItem(csModel.cs_Answer answers) { bool result = false; wpe = new csWeiP ...
- ADO.NET 实体数据模型 异常-“序列化类型为 XX 的对象时检测到循环引用”
发生异常的代码如下: 1: public JsonResult GetSaleByNo1(string id) 2: { 3: SaleMvcUI.Helper.saleDBEntities sale ...
- LR中,URL -based script与HTML -based script区别
在Web(HTTP/HTML)录制中,有2种重要的录制模式.用户该选择那种录制模式呢?HTML-mode录制是缺省也是推荐的录制模式.它录制当前网页中的HTML动作.在录制会话过程中不会录制所有的资源 ...
- Java springboot项目的jar发布方式
做springboot的都知道,发布方式不是war发布了,是jar发布,启动jar就可以直接运行,并且环境都是集成的. 首先,先将项目打包成jar,这里假设你的eclipse已经安装了maven插件. ...
- gulp监听文件变化,并拷贝到指定目录(转)---参考记录
###暂时不支持目录修改.创建.删除.var gulp = require('gulp'); var fs = require('fs'); var path = require('path'); v ...