[SQL入门级] 这篇咱'薄利多销',记录多一点
这个系列的博文知识回顾sql知识作的记录,温故而知新。上一篇内容达不到知识分享的层级被移出园子首页,对不住各位看官,内容简单了些。下面咱就记录多一些的基础知识,薄利多销:
控制用户权限
• 创建用户
CREATE USER user
IDENTIFIED BY password;
• 创建用户表空间
ALTER USER user QUOTA UNLIMITED
ON users
• 赋予系统权限
– CREATE SESSION(创建会话)
– CREATE TABLE(创建表)
– CREATE SEQUENCE(创建序列)
– CREATE VIEW(创建视图)
– CREATE PROCEDURE(创建过程)
• 赋予对象权限
GRANT object_priv [(columns)]
ON object
TO {user|role|PUBLIC} --PUBLIC代表数据库所有用户
[WITH GRANT OPTION]; --使用户同样具有分配权限的权利
--分配表 EMPLOYEES 的查询权限
GRANT select
ON employees
TO sue, rich;
• 回收对象权限
REVOKE {privilege [, privilege...]|ALL} --使用 WITH GRANT OPTION 子句所分配的权限同样被收回
ON object
FROM {user[, user...]|role|PUBLIC}
[CASCADE CONSTRAINTS];
--回收对象权限举例
REVOKE select, insert
ON departments
FROM scott;
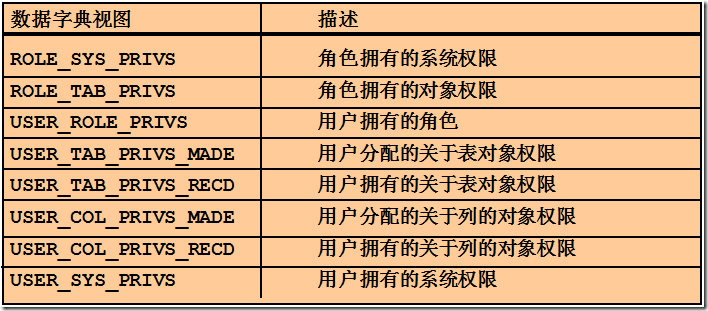
• 查询权限
SELECT *
FROM user_sys_privs


多表查询
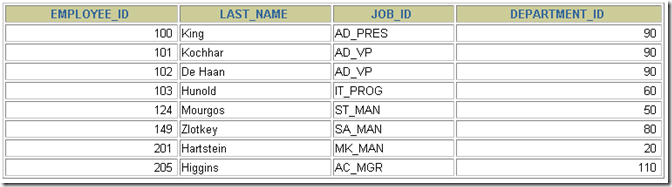
首先明确我们要做的事:
如上图是我们平时业务中再正常不过的了,那么这小节咱就说说连接多表查询数据。
内连接:合并具有同一列的两个以上的表的行, 结果集中不包含一个表与另一个表不匹配的行
• 等值连接
- 方式一:在 WHERE 子句中写入连接条件,连接 n个表,至少需要 n-1个连接条件(通用型)
SELECT e.employee_id, e.last_name, e.department_id,
d.department_id, d.location_id
FROM employees e , departments d
WHERE e.department_id = d.department_id;
- 方式二:使用JOIN…ON创建多表连接(常用方式:较通用型WHERE条件,更易实现外连接(左、右、满))
SELECT employee_id, city, department_name
FROM employees e
JOIN departments d
ON d.department_id = e.department_id
JOIN locations l
ON d.location_id = l.location_id;
- 方式三:使用USING子句创建连接(局限性:好于自然连接,但若多表的连接列列名不同,此法不合适)
SELECT e.employee_id, e.last_name, d.location_id
FROM employees e JOIN departments d
USING (department_id); --JOIN和USING经常同时使用
• 不等值连接
SELECT e.last_name, e.salary, j.grade_level
FROM employees e, job_grades j
WHERE e.salary BETWEEN j.lowest_sal AND j.highest_sal;
• 自连接
SELECT worker.last_name || ' works for ' || manager.last_name
FROM employees worker, employees manager
WHERE worker.manager_id = manager.employee_id;
• 自然连接(局限性:会自动连接两个表中相同的列)
- NATURAL JOIN 子句,会以两个表中具有相同名字的列为条件创建等值连接。
- 在表中查询满足等值条件的数据。
- 如果只是列名相同而数据类型不同,则会产生错误。
SELECT department_id, department_name, location_id, city
FROM departments
NATURAL JOIN locations ;
外连接:两个表在连接过程中除了返回满足连接条件的行以外还返回左(或右)表中不满足条件的行 ,这种连接称为左(或右) 外连接。没有匹配的行时, 结果表中相应的列为空(NULL)。
• 左外连接
- 方式一:外连接运算符
SELECT table1.column, table2.column
FROM table1, table2
WHERE table1.column = table2.column(+);
- 方式二:SQL1999语法
SELECT e.last_name, e.department_id, d.department_name
FROM employees e
LEFT OUTER JOIN departments d
ON (e.department_id = d.department_id) ;
• 右外连接
- 方式一:外连接运算符
SELECT table1.column, table2.column
FROM table1, table2
WHERE table1.column(+) = table2.column;
- 方式二:SQL1999语法
SELECT e.last_name, e.department_id, d.department_name
FROM employees e
RIGHT OUTER JOIN departments d
ON (e.department_id = d.department_id);
• 满外连接
SELECT e.last_name, e.department_id, d.department_name
FROM employees e
FULL OUTER JOIN departments d
ON (e.department_id = d.department_id);

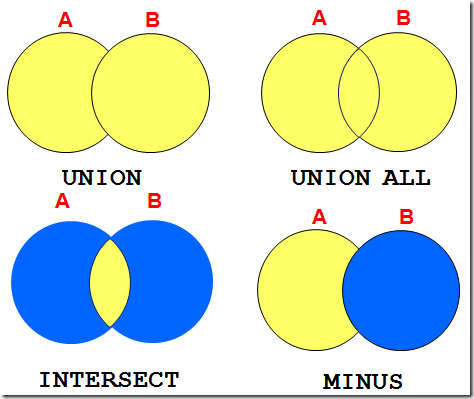
SET运算符:将多个查询用SET操作符连接组成一个新的查询
• 在SELECT 列表中的列名和表达式在数量和数据类型上要相对应,所以就有了各种字段匹配
SELECT department_id, TO_NUMBER(null) location, hire_date
FROM employees
UNION
SELECT department_id, location_id, TO_DATE(null)
FROM departments;
• 括号可以改变执行的顺序
• ORDER BY 子句:
– 只能在语句的最后出现
– 可以使用第一个查询中的列名, 别名或相对位置
• 除 UNION ALL之外,系统会自动将重复的记录删除
• 系统将第一个查询的列名显示在输出中
• 除 UNION ALL之外,系统自动按照第一个查询中的第一个列的升序排列
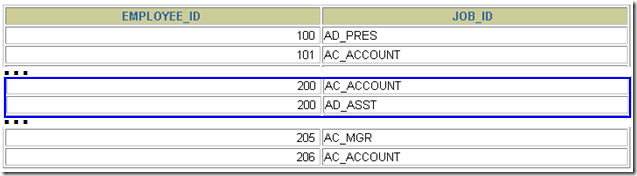
UNION 返回两个查询的结果集的并集
SELECT employee_id, job_id
FROM employees
UNION
SELECT employee_id, job_id
FROM job_history;
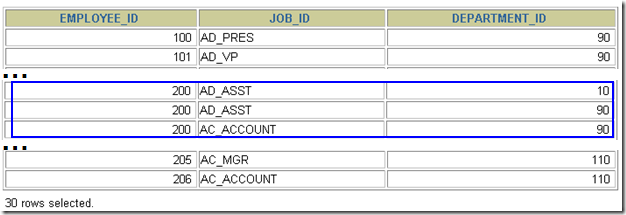
UNION ALL 返回两个查询的结果集的并集。对于两个结果集的重复部分,不去重
SELECT employee_id, job_id, department_id
FROM employees
UNION ALL
SELECT employee_id, job_id, department_id
FROM job_history
ORDER BY employee_id;
INTERSECT 返回两个结果集的交集
SELECT employee_id, job_id
FROM employees
INTERSECT
SELECT employee_id, job_id
FROM job_history;
MINUS 返回两个结果集的差集
SELECT employee_id,job_id
FROM employees
MINUS
SELECT employee_id,job_id
FROM job_history;

子查询
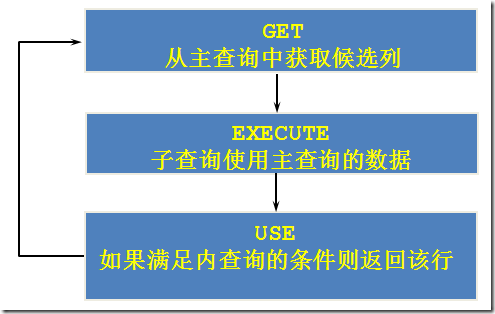
• 在查询时基于未知的值时,应使用子查询
• 子查询(内查询)在主查询之前一次执行完成
• 子查询的结果被主查询(外查询)使用
• 子查询要包含在括号内
• 将子查询放在比较条件的右侧
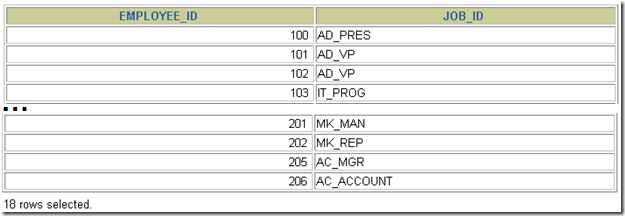
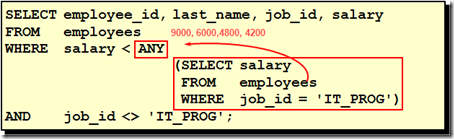
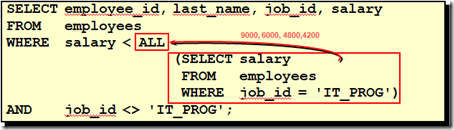
• 单行操作符对应单行子查询,多行操作符对应多行子查询(注意理解ANY和ALL的区别)
SELECT select_list
FROM table
WHERE expr operator (
SELECT select_list
FROM table
);
高级子查询
<例子说明一切!>
1. 多列子查询
--查询与141号或174号员工的manager_id和department_id相同的其他员工的employee_id, manager_id, department_id
--不成对比较
select employee_id, manager_id, department_id
from employees
where manager_id in(
select manager_id
from employees
where employee_id in(141,174)
)
and department_id in(
select department_id
from employees
where employee_id in(141,174)
)
and employee_id not in(141,174)--成对比较
select employee_id, manager_id, department_id
from employees
where (manager_id,department_id) in(
select manager_id,department_id --多列子查询
from employees
where employee_id in(141,174)
)
and employee_id not in(141,174)2. 在FROM子句中使用子查询
--返回比本部门平均工资高的员工的last_name, department_id, salary及平均工资
select last_name, e.department_id, salary,temp.avg_sal
from employees e,(
select department_id,avg(salary) avg_sal
from employees
group by department_id
) temp
where e.department_id = temp.department_id3. 单列子查询 单列子查询表达式是在一行中只返回一列的子查询
• Oracle8i 只在下列情况下可以使用, 例如:
– SELECT 语句 (FROM 和 WHERE 子句)
– INSERT 语句中的VALUES列表中
• Oracle9i中单列子查询表达式可在下列情况下使用:
– DECODE 和 CASE
– SELECT 中除 GROUP BY 子句以外的所有子句中
--显示员工的employee_id,last_name和location。其中,若员工department_id与location_id为1800的department_id相同,则location为’Canada’,其余则为’USA’
SELECT employee_id, last_name,
(CASE
WHEN department_id =
(SELECT department_id FROM departments
WHERE location_id = 1800)
THEN 'Canada' ELSE 'USA' END) location
FROM employees;
4. 相关子查询
什么是相关?
先来举个栗子!
--查询员工的employee_id,last_name,要求按照员工的department_name排序
SELECT employee_id, last_name
FROM employees e
ORDER BY (SELECT department_name
FROM departments d
WHERE e.department_id = d.department_id); --首先看内层子查询使用了外层查询的表,并通过WHERE语句使他俩产生关系,这种就叫相关子查询
如上语句的执行步骤是这样的:先从e表中select一条数据,然后执行子查询,子查询用外查询select的数据进行操作返回一条结果,然后外层查询再用这个结果来执行order by,这样主查询和子查询就发生了相关性!如图:
5. EXISTS操作符
• EXISTS 操作符检查在子查询中是否存在满足条件的行
• 如果在子查询中存在满足条件的行:
– 不在子查询中继续查找
– 条件返回 TRUE
• 如果在子查询中不存在满足条件的行:
– 条件返回 FALSE
– 继续在子查询中查找
--查询公司管理者的employee_id,last_name,job_id,department_id信息
SELECT employee_id, last_name, job_id, department_id
FROM employees outer
WHERE EXISTS ( SELECT 'X'
FROM employees
WHERE manager_id = outer.employee_id);
--查询departments表中,不存在于employees表中的部门的department_id和department_name
SELECT department_id, department_name
FROM departments d
WHERE NOT EXISTS ( SELECT 'X'
FROM employees
WHERE department_id = d.department_id);
6. 相关更新、删除
使用相关子查询依据一个表中的数据更新、删除另一个表的数据
UPDATE table1 alias1
SET column = (SELECT expression
FROM table2 alias2
WHERE alias1.column = alias2.column);
DELETE FROM table1 alias1
WHERE column operator
(SELECT expression
FROM table2 alias2
WHERE alias1.column = alias2.column);
7. WITH子句
• 使用 WITH 子句, 可以避免在 SELECT 语句中重复书写相同的语句块
• WITH 子句将该子句中的语句块执行一次并存储到用户的临时表空间中
• 使用 WITH 子句可以提高查询效率
--查询公司中各部门的总工资大于公司中各部门的平均总工资的部门信息
WITH
dept_costs AS (SELECT d.department_name, SUM(e.salary) AS dept_total
FROM employees e, departments d
WHERE e.department_id = d.department_id
GROUP BY d.department_name),
avg_cost AS (
SELECT SUM(dept_total)/COUNT(*) AS dept_avg
FROM dept_costs)
SELECT *
FROM dept_costs
WHERE dept_total >
(
SELECT dept_avg
FROM avg_cost)
ORDER BY department_name;

增删改
插入数据(注意非空约束的列)
• 手动插入
INSERT INTO table [(column [, column...])]
VALUES (value [, value...]);
• 从其它表中拷贝数据(不必书写VALUES子句;子查询中的列与INSERT语句中的列一一对应;)
INSERT INTO sales_reps(id, name, salary, commission_pct)
SELECT employee_id, last_name, salary, commission_pct
FROM employees
WHERE job_id LIKE '%REP%';
更新数据
UPDATE table
SET column = value [, column = value, ...]
[WHERE condition];
删除数据
DELETE FROM table
[WHERE condition];
创建管理表
以下这些DDL的命令,操作完后皆不可回滚!
创建表
• 白手起家自己动手创建表
CREATE TABLE [schema.]table
(column datatype [DEFAULT expr][, ...]);
• 长袖善舞咱依据他表创建新表
CREATE TABLE table
[(column, column...)]
AS subquery;
--复制现有表(包含数据)
create table emp1 as select * from employees;
--复制现有表结构
create table emp2 as select * from employees where 1=2;
修改表
• 追加新的列
ALTER TABLE table
ADD (column datatype [DEFAULT expr]
[, column datatype]...);
• 修改现有的列/为新追加的列定义默认值
ALTER TABLE table
MODIFY (column datatype [DEFAULT expr]
[, column datatype]...);
• 删除一个列
ALTER TABLE table
DROP COLUMN column_name;
• 重命名表的一个列名
ALTER TABLE table_name RENAME COLUMM old_column_name
TO new_column_name;
删除表
• 数据和结构都被删除
• 所有正在运行的相关事务被提交
• 所有相关索引被删除
• DROP TABLE 语句不能回滚
DROP TABLE table;
清空表
• 删除表中所有的数据
• 释放表的存储空间
• TRUNCATE语句不能回滚
• 清空表的操作也可以用DELETE语句,可以回滚
TRUNCATE TABLE table;
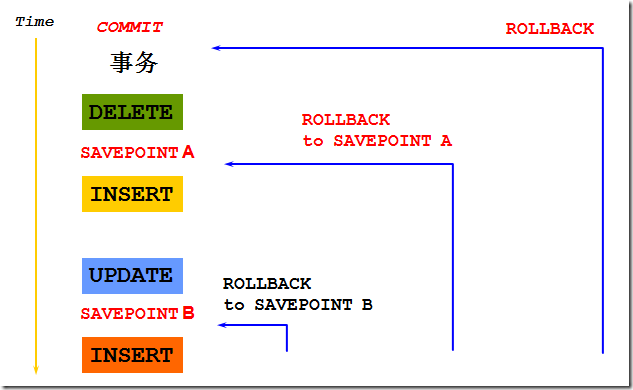
事务管理 COMMIT ROLLBACK SAVEPOINT
首先来看看事务:一组逻辑操作单元,使数据从一种状态变换为另一种状态。由以下部分组成:
• 一个或多个DML 语句
• 一个 DDL语句
• 一个 DCL语句
一图胜千言!
提交或回滚前的数据状态
• 改变前的数据状态是可以恢复的
• 执行 DML 操作的用户可以通过 SELECT 语句查询之前的修正
• 其他用户不能看到当前用户所做的改变,直到当前用户结束事务
• DML语句所涉及到的行被锁定, 其他用户不能操作
提交后的数据状态
• 数据的改变已经被保存到数据库中
• 改变前的数据已经丢失
• 所有用户可以看到结果
• 锁被释放,其他用户可以操作涉及到的数据
• 所有保存点被释放
约束 CONSTRAINT
• NOT NULL(非空,只能是列级约束) 对INSERT语句有影响
create table emp4(
id number(10) constraint emp2_id_nn not null, --命名约束,见名知意
name varchar2(20) not null, --系统默认命名 SYS_Cn
salary number(10,2)
)• UNIQUE(唯一) UNIQUE约束可以插入NULL值
create table emp3(
--列级约束
id number(10) constraint emp3_id_uk unique,
name varchar2(20) constraint emp3_name_nn not null,
email varchar2(30),
salary number(10,2),
--表级约束 在所有列定义完后加个逗号写约束
constraint emp3_email_uk unique(email)
)• PRIMARY KEY(主键) 非空且唯一
create table emp1(
id number(10),
name varchar2(20) constraint emp1_name_nn not null,
email varchar2(20),
salary number(10,2),
constraint emp1_email_uk unique(email),
constraint emp1_id_pk primary key(id)
)• FOREIGN KEY(外键) 外键是联系两张表,在子表(emp2)中插入数据时外键字段的值必须在父表(departments)中存在
create table emp2(
id number(10),
name varchar2(20) constraint emp2_name_nn not null,
email varchar2(20),
salary number(10,2),
department_id number(10),
constraint emp2_email_uk unique(email),
constraint emp2_id_pk primary key(id),
constraint emp2_dept_id_fk foreign key(department_id) references departments(department_id)
)- ON DELETE CASCADE(级联删除):当父表中的列被删除的时候,子表中相对应的列也被删除(想成某个部门被砍了,那么下面的员工也一把被砍掉了)
- ON SELETE SET NULL(级联置空):子表中相对应的列置空
• CHECK 定义每一行必须满足的条件
create table emp2(
id number(10) constraint emp2_id_pk primary key,
name varchar2(20) constraint emp2_name_nn not null,
salary number(10) constraint emp2_salary_ck check(salary > 1500 and salary < 30000),
dept_id number(10),
constraint emp2_dept_id_fk foreign key(dept_id) references dept1(id) on delete cascade
)添加删除约束
• 添加或删除约束,但是不能修改约束
ALTER TABLE employees
ADD CONSTRAINT emp_manager_fk
FOREIGN KEY(manager_id)
REFERENCES employees(employee_id);
ALTER TABLE employees
DROP CONSTRAINT emp_manager_fk;
• 有效化或无效化约束
ALTER TABLE employees
DISABLE CONSTRAINT emp_emp_id_pk;
--当定义或激活UNIQUE 或 PRIMARY KEY 约束时系统会自动创建UNIQUE 或 PRIMARY KEY索引
ALTER TABLE employees
ENABLE CONSTRAINT emp_emp_id_pk;
• 添加 NOT NULL 约束要使用 MODIFY 语句
ALTER TABLE emp
MODIFY(emp_name varchar2(50) NOT NULL);
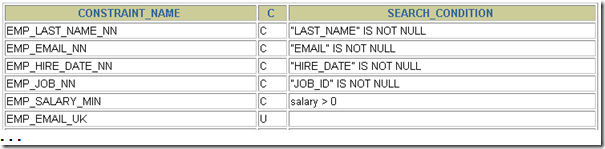
查询约束
SELECT constraint_name, constraint_type,
search_condition
FROM user_constraints
WHERE table_name = 'EMPLOYEES';
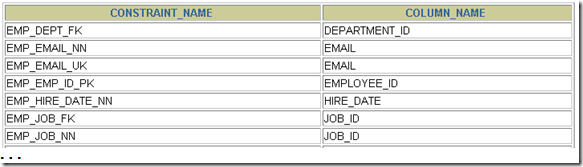
--查询定义约束的列
SELECT constraint_name, column_name
FROM user_cons_columns
WHERE table_name = 'EMPLOYEES';
视图 View
视图是干嘛使的?
• 视图是一种虚表。
• 视图建立在已有表的基础上, 视图赖以建立的这些表称为基表。
• 向视图提供数据内容的语句为 SELECT 语句, 可以将视图理解为存储起来的 SELECT 语句
• 视图向用户提供基表数据的另一种表现形式
视图有哪些好处?
• 控制数据访问
• 简化查询(可以关联多张表创建视图)
• 对视图的操作会同步到基表中
• 避免重复访问相同的数据
创建修改和删除视图
create or replace view empview(id,name,salary,dept_name) --同创建表,字段要一一对应,或此处不写明也可
as
select employee_id,first_name||' '||last_name,salary,department_name --给视图的列定义了别名,在选择视图的中列时用别名
from employees e, departments d
where e.department_id = d.department_idwith read only --可以使用 WITH READ ONLY 选项屏蔽对视图的DML操作
drop view empview; --删除视图,只是删除视图的定义,并不会删除基表的数据
区别简单视图和复杂视图 → 是否使用了聚合函数
create or replace view empview3
as
select d.department_name name, MIN(e.salary) minsal, MAX(e.salary) maxsal, AVG(e.salary) avgsal --使用局和函数的列必须取别名
from employees e,departments d
where e.department_id = d.department_id
group by d.department_name --使用了分组函数即为复杂视图视图中使用DML的规定,原因也很简单,想想就清楚
• 可以在简单视图中执行 DML 操作
• 当视图定义中包含以下元素之一时不能使用delete:
– 组函数
– GROUP BY 子句
– DISTINCT 关键字
– ROWNUM 伪列
• 当视图定义中包含以下元素之一时不能使用update:
– 组函数
– GROUP BY子句
– DISTINCT 关键字
– ROWNUM 伪列
– 列的定义为表达式
• 当视图定义中包含以下元素之一时不能使insert:
– 组函数
– GROUP BY 子句
– DISTINCT 关键字
– ROWNUM 伪列
– 列的定义为表达式
– 表中非空的列在视图定义中未包括
使用“TOP-N”分析
这个咱一步步来解释:
首先老板说了,把公司中工资前十名的信息给他。
好!咱写出这样的语句:
select employee_id,first_name||' '||last_name name,salary,hire_date
from employees
order by salary desc给老板的是全公司员工的数据,这不合适,不能让他去数前十个吧!
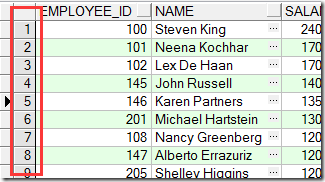
那咱干不下去啦?不,事情总有解决方案!咱先引入一个新的概念:伪列 ROWNUM,它是啥呢,如图:
这个就叫伪列,它与一张表中数据挂钩!
有了这个那简单了!
select rownum,employee_id,first_name||' '||last_name name,salary,hire_date
from employees
where rownum <=10
order by salary desc
但是!发现结果好像有点不对啊!这分明就不是工资最高的前十个人嘛!你特么在逗我!
那么原因呢上面我也说了这个ROWNUM是和表中数据对应的,每变更一条数据时ROWNUM都唯一对应着一条数据。
那咱就利用这个概念,既然我SELECT查询的结果集也有ROWNUM,那我就查询出排好序的数据,按结果集的ROWNUM我就可以找到前10个人啦!
select employee_id,name,salary,hire_date
from ( --此处用到子查询
select employee_id,first_name||' '||last_name name,salary,hire_date
from employees
order by salary desc
)
where rownum <= 10
,咱大功告成!
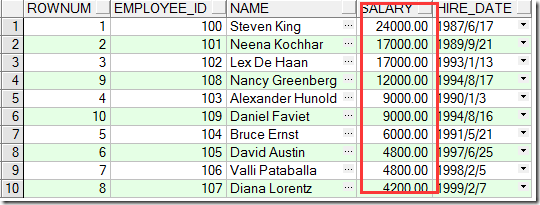
这时候老板又说了,你给我找到40~50名工资的有哪些人我要做报表。
接到任务很兴奋啊!这简单,把上面那个改改!
select rownum,employee_id,name,salary,hire_date
from (
select employee_id,first_name||' '||last_name name,salary,hire_date
from employees
order by salary desc
)
where rownum <= 50 and rownum >= 40
看到结果的我眼泪掉下来!
这特么数据呢!再一看表中是有数据的呀!
后来咱知道了,对 ROWNUM 只能使用 < 或 <=, 而用 =, >, >= 都将不能返回任何数据!
你说你咋恁多事呢!
那咱就得想其它办法啦,怎么做呢?
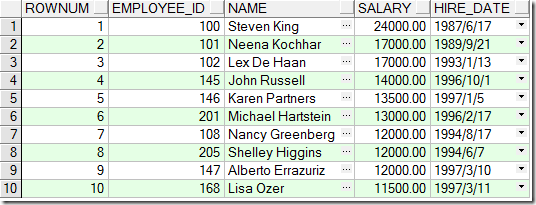
既然对ROWNUM这个特有的列我们不能使用=, >, >=,但是一般的列咱行啊!那咱就复制这个列呗!
select *
from(
select rownum rn,employee_id,name,salary,hire_date --通过将ROWNUM这个特有列取别名跟数据库关键字区别开
from (
select employee_id,first_name||' '||last_name name,salary,hire_date
from employees
order by salary desc
)
)
where rn <= 50 and rn >= 40
老板!你是不是要这个!

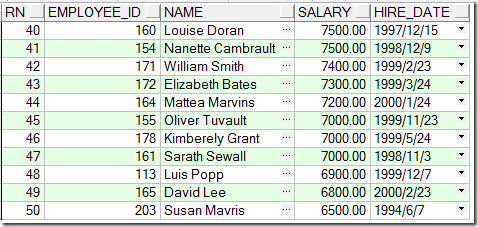
序列 SEQUENCE:可供多个用户用来产生唯一数值的数据库对象
• 自动提供唯一的数值
• 共享对象
• 主要用于提供主键值,唯一且非空
• 将序列值装入内存可以提高访问效率
创建序列
CREATE SEQUENCE sequence
[INCREMENT BY n] --每次增长的数值
[START WITH n] --从哪个值开始
[{MAXVALUE n | NOMAXVALUE}]
[{MINVALUE n | NOMINVALUE}]
[{CYCLE | NOCYCLE}] --是否需要循环
[{CACHE n | NOCACHE}]; --是否缓存登录
查询序列
SELECT sequence_name, min_value, max_value, increment_by, last_number
FROM user_sequences; --如果指定NOCACHE 选项,则列LAST_NUMBER 显示序列中下一个有效的值
使用序列
INSERT INTO departments(department_id, department_name, location_id)
VALUES (dept_deptid_seq.NEXTVAL, 'Support', 2500);
• NEXTVAL 返回序列中下一个有效的值,任何用户都可以引用
• CURRVAL 中存放序列的当前值
• NEXTVAL 应在 CURRVAL 之前指定,否则会报CURRVAL 尚未在此会话中定义的错误
• 将序列值装入内存可提高访问效率
• 序列在下列情况下出现裂缝:
– 回滚 ROLLBACK
– 系统异常
– 多个表同时使用同一序列
• 如果不将序列的值装入内存(NOCACHE), 可使用表 USER_SEQUENCES 查看序列当前的有效值
修改序列
ALTER SEQUENCE dept_deptid_seq
INCREMENT BY 20
MAXVALUE 999999
NOCACHE
NOCYCLE;
• 必须是序列的拥有者或对序列有 ALTER 权限
• 只有将来的序列值会被改变
• 改变序列的初始值只能通过删除序列之后重建序列的方法实现
删除序列
DROP SEQUENCE dept_deptid_seq;
• 使用 DROP SEQUENCE 语句删除序列
• 删除之后,序列不能再次被引用
索引 INDEX
• 一种独立于表的模式对象, 可以存储在与表不同的磁盘或表空间中
• 索引被删除或损坏, 不会对表产生影响, 其影响的只是查询的速度
• 索引一旦建立, Oracle 管理系统会对其进行自动维护, 而且由 Oracle 管理系统决定何时使用索引。用户不用在查询语句中指定使用哪个索引
• 在删除一个表时,所有基于该表的索引会自动被删除
• 通过指针加速 Oracle 服务器的查询速度
• 通过快速定位数据的方法,减少磁盘 I/O
• 索引加速查询,但是插入删除操作会变慢,因为要维护索引表
创建索引
• 自动创建: 在定义 PRIMARY KEY 或 UNIQUE 约束后系统自动在相应的列上创建唯一性索引
• 手动创建: 用户可以在其它列上创建非唯一的索引,以加速查询
CREATE INDEX index
ON table (column[, column]...);
• 以下情况可以创建索引:
– 列中数据值分布范围很广
– 列经常在 WHERE 子句或连接条件中出现
– 表经常被访问而且数据量很大,访问的数据大概占数据总量的2%到4%
• 什么时候不要创建索引
– 表很小
– 列不经常作为连接条件或出现在WHERE子句中
– 查询的数据大于2%到4%
– 表经常更新
查询索引
SELECT ic.index_name, ic.column_name, ic.column_position col_pos,ix.uniqueness
FROM user_indexes ix, user_ind_columns ic
WHERE ic.index_name = ix.index_name AND ic.table_name = 'EMPLOYEES';
删除索引
DROP INDEX index;
• 只有索引的拥有者或拥有DROP ANY INDEX 权限的用户才可以删除索引
• 删除操作是不可回滚的
同义词 SYNONYM
• 方便访问其它用户的对象
• 缩短对象名字的长度
创建同义词
CREATE [PUBLIC] SYNONYM synonym
FOR object; –object可以使表、视图等
删除同义词
DROP SYNONYM d_sum;
[SQL入门级] 这篇咱'薄利多销',记录多一点的更多相关文章
- 阿里巴巴(alibaba)系列_druid 数据库连接池_监控(一篇搞定)记录执行慢的sql语句
参考帖子:http://www.cnblogs.com/han-1034683568/p/6730869.html Druid数据连接池简介 Druid是Java语言中最好的数据库连接池.Druid能 ...
- oracle(sql)基础篇系列(五)——PLSQL、游标、存储过程、触发器
PL/SQL PL/SQL 简介 每一种数据库都有这样的一种语言,PL/SQL 是在Oracle里面的一种编程语言,在Oracle内部使用的编程语言.我们知道SQL语言是没有分支和循环的,而PL语 ...
- oracle(sql)基础篇系列(五)——PLSQL、游标、存储过程、触发器
PL/SQL PL/SQL 简介 每一种数据库都有这样的一种语言,PL/SQL 是在Oracle里面的一种编程语言,在Oracle内部使用的编程语言.我们知道SQL语言是没有分支和循环的,而PL语言是 ...
- PL/SQL之高级篇
原文地址:http://www.cnblogs.com/sin90lzc/archive/2012/08/30/2661117.html 参考文献:<Oracle完全学习手册> 1.概述 ...
- 【目录】sql server 进阶篇系列
随笔分类 - sql server 进阶篇系列 sql server 下载安装标记 摘要: SQL Server 2017 的各版本和支持的功能 https://docs.microsoft.com/ ...
- 【目录】sql server 架构篇系列
随笔分类 - sql server 架构篇系列 sql server 高可用镜像 摘要: 一.什么是数据库镜像 基本软件的高可用性解决方案 快速的故障转移恢复(3秒转移),低硬件成本 基于数据库级别的 ...
- sql 删除表中的重复记录
嗯,遇见了表中存在重复的记录的问题,直接写sql删除时最快的,才不要慢慢的复制到excel表中慢慢的人工找呢.哼. 如下sql,找出重复的记录,和重复记录中ID值最小的记录(表中ID为自增长) sel ...
- SQL查询多条不重复记录值简要解析【转载】
转载http://hi.baidu.com/my_favourate/item/3716b0cbe125f312505058eb SQL查询多条不重复记录值简要解析2008-02-28 11:36 以 ...
- Microsoft SQL server2017初次安装与使用记录
Microsoft SQL server2017初次安装与使用记录 学校数据库课程以Microsoft SQL server为例, 由于老师给的软件版本和我的window10不兼容,选择官网的最新版2 ...
随机推荐
- MacOS 安装 nginx
brew install nginx 开机启动 $ sudo cp `brew --prefix nginx`/homebrew.mxcl.nginx.plist /Library/LaunchDae ...
- 深入浅出WPF之Binding的使用(一)
在WPF中Binding可以比作数据的桥梁,桥梁的两端分别是Binding的源(Source)和目标(Target).一般情况下,Binding源是逻辑层对象,Binding目标是UI层的控件对象:这 ...
- ps软件使用的问题解决记录
1.PS的字体颜色改变不了的解决方法,添加字体的时颜色无论怎么选都只能有[黑.白.灰]三种颜色, 问题的原因:图像的模式选择了灰度(G) 解决方法:图像-->模式-->RG ...
- 云存储命令行工具---libs3
ceph 的客户端有很多,有s3cmd.cloudberryExplorer等,今天介绍另一个libs3 一. 安装 Libs3是RGW s3接口的命令行工具,与s3cmd类似,使用C++生成. 1. ...
- 【Android】 导入项目报错的解决方案
1.打项目的properties -->android 为其指一个运版本, 2.修改default properties 文件 ,改相应版本等级 3.选中项目,单击右键,选中properties ...
- python---修改编辑器的配色和字体大小
因为习惯黑色的背景,所以必须修改成对应的配色: 在这里设置theme: 设置字体大小: 找到Font,这里设置字体大小,首先要Scheme 后 进行 Save as 操作后,才能设置 Size ,设置 ...
- Docker容器挂载宿主目录的情形分析
Docker容器启动的时候,如果要挂载宿主机的一个目录,可以用-v参数指定. 譬如我要启动一个centos容器,宿主机的/test目录挂载到容器的/soft目录,可通过以下方式指定: # docker ...
- 持续集成之jenkins
代码部署规划 安装jenkins yum -y install java-1.8.0cd /etc/yum.repos.d/wget http://pkg.jenkins.io/redhat/jenk ...
- Linq 多连接及 left join 实例 记录
var retList = from d in mbExList.Cast<MaterialBaseEx>().ToList() join c in umcList.Cast<Cla ...
- Git 使用篇一:初步使用GitHub,下载安装git,并上传项目
首先在MAC上怎么操作. 在gitHub创立一个账户,在创立一个项目,这就不用我说了对吧. 创建完之后是这样的: 接下来,我们打开https://brew.sh 这是下载homebrew的网站,hom ...