07: python基础 零碎知识点
目录:
1.1 python异常处理返回顶部
1、Python中各种内建异常
1) Exception: 所有异常类型
2) AttributeError: 特性引用或赋值失败时引发
3) IOError: 试图打开不存在的文件时引发
4) IndexError: 在使用序列中不存在的索引时引发
5) KeyError: 在使用映射时不存在的键时引发
6) NameError: 在找不到变量名字时引发
7) SyntaxError: 代码有语法错误时引发
8) TypeError: 函数应用于错误类型的对象时引发
9) ValueError: 函数应用于正确类型的对象,但该对象使用不合适的值时引发
10) ZeroDivisionError: 在除操作时第二个参数为0时引发
Python中各种内建异常
2、几种常见捕获异常的方法
1. 捕获单个异常
names = ['alex','jack']
try:
names[2]
except IndexError as e:
print("列表操作错误",e)
# 运行结果: 列表操作错误 list index out of range
捕获单个异常
2. 多个except子句,捕获多个异常
try:
x = input("Enter the first number:")
y = input("Enter the second number:")
print(x/y)
except ZeroDivisionError:
print("The second number can't zero")
except NameError:
print('That was not a number....')
多个except子句
3. 一个except捕获多个异常
说明:如果需要用一个块扑捉多个异常类型,那么可以将他们作为元组列出
try:
x = input("Enter the first number:")
y = input("Enter the second number:")
print(x/y)
except (ZeroDivisionError, TypeError, NameError):
print("your numbers were bogus...")
一个except捕获多个异常
4. 捕捉对象: except (NameError) as e
try:
x = input("Enter the first number:")
y = input("Enter the second number:")
print(x/y)
except (ZeroDivisionError, TypeError, NameError) as e:
print(e)
捕捉对象: except (NameError) as e
import traceback try:
name = int('df11')
except Exception as e:
print(traceback.format_exc()) # Traceback (most recent call last):
# File "C:/Users/tom/Desktop/cmdb_cli_ser/AutoClient/test01.py", line 4, in <module>
# name = int('df11')
# ValueError: invalid literal for int() with base 10: 'df11'
traceback.format_exc()获取详细异常信息
5. 正真的全捕捉: except
try:
x = input("Enter the first number:")
y = input("Enter the second number:")
print(x/y)
except:
print('something wrong happened')
正真的全捕捉: except
6. 异常使用结构
try:
# 主代码块
pass
except KeyError as e:
# 异常时,执行该块
pass
else:
# 主代码块正常执行完,执行该块
pass
finally:
# 无论异常与否,最终执行该块
pass
异常使用结构
7. 主动触发异常
try:
raise Exception('错误了。。。')
except Exception as e:
print(e)
# 运行结果: 错误了。。。
主动触发异常
8. 自定义异常
class WupeiqiException(Exception):
def __init__(self, msg):
self.message = msg
def __str__(self):
return self.message #最终打印的结果就是这里return返回的值 try:
raise WupeiqiException('我的异常') #这里的字符串就会传入到class类的msg中
except WupeiqiException as e:
print(e)
# 运行结果: 我的异常
自定义异常
9. 断言
作用:Python的assert是用来检查一个条件,如果它为真,就不做任何事。如果它为假,则会抛出AssertError并且包含错误信息
n = 1
assert type(n) is int
print('aaaa')
# 1. Assert后的断言结果成立时才会执行:print('aaaa')
# 2. Assert后的断言结果不成立时会引发AssertError并退出程序
断言
1.2 三元运算,filter和map与lambda表达式结合使用举例返回顶部
1、三元运算
1. 三元运算格式: result=值1 if x<y else 值2 if条件成立result=1,否则result=2
2. 作用:三元运算,又称三目运算,主要作用是减少代码量,是对简单的条件语句的缩写
name = 'Tom' if 1 == 1 else 'fly'
print(name)
# 运行结果: Tom
三元运算
f = lambda x:x if x % 2 != 0 else x + 100
print(f(10)) #
三元运算与lambda结合
2、lambda基本使用
1. lambda只是一个表达式,函数体比def简单很多。
2. lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
3. lambda表达式是起到一个函数速写的作用。允许在代码内嵌入一个函数的定义。
4. 格式:lambda的一般形式是关键字lambda后面跟一个或多个参数,紧跟一个冒号,之后是一个表达式。
f = lambda x,y,z:x+y+z
print(f(1,2,3)) # my_lambda = lambda arg : arg + 1
print(my_lambda(10)) #
lambda基本使用
3、filter与lambda表达式结合使用
1. filter()函数可以对序列做过滤处理,就是说可以使用一个自定的函数过滤一个序列,把序列的每一项传到自定义
的过滤函数里处理,并返回结果做过滤。最终一次性返回过滤后的结果。
2. filter()函数有两个参数:
第一个,自定函数名,必须的
第二个,需要过滤的列,也是必须的
l1= [11,22,33,44,55]
a = filter(lambda x: x<33, l1)
print(list(a))
利用 filter、lambda表达式 获取l1中元素小于33的所有元素 l1 = [11, 22, 33, 44, 55]
l1= [11,22,33,44,55]
def func(num):
if num>33:
return num
result=filter(func,l1)
print(list(result))
自定义函数代替lambda实现相同功能
4、map与lambda表达式结合使用
1. map使用:第一个参数接收一个函数名,第二个参数接收一个可迭代对象
lt = [1, 2, 3, 4, 5, 6]
def add(num):
return num + 1
rs = map(add, lt)
print(list(rs)) #运行结果: [2, 3, 4, 5, 6, 7]
map最基本使用
2. 利用map,lambda表达式将所有偶数元素加100
l1= [11,22,33,44,55]
ret = map(lambda x:x if x % 2 != 0 else x + 100,l1)
print(list(ret))
# 运行结果: [11, 122, 33, 144, 55]
利用map,lambda表达式将所有偶数元素加100
l1= [11,22,33,44,55]
def add(num):
if num%2 == 0:
return num
else:
return num + 100
rs = map(add, l1)
print(list(rs))
自定义函数代替lambda实现相同功能
5、总结:filter()和map()函数区别
1. Filter函数用于对序列的过滤操作,过滤出需要的结果,一次性返回他的过滤设置于的是条件
2. Map函数是对序列根据设定条件进行操作后返回他设置的是操作方法,无论怎样都会返回结果
6、reduce函数
1. reduce()函数即为化简函数,它的执行过程为:每一次迭代,都将上一次的迭代结果与下一个元素一同传入二元func函数中去执行。
2. 在reduce()函数中,init是可选的,如果指定,则作为第一次迭代的第一个元素使用,如果没有指定,就取seq中的第一个元素。
from functools import reduce
def f(x, y):
return x + y print(reduce(f, [1, 3, 5, 7, 9])) #
# 1、先计算头两个元素:f(1, 3),结果为4;
# 2、再把结果和第3个元素计算:f(4, 5),结果为9;
# 3、再把结果和第4个元素计算:f(9, 7),结果为16;
# 4、再把结果和第5个元素计算:f(16, 9),结果为25;
# 5、由于没有更多的元素了,计算结束,返回结果25。 print( reduce(lambda x, y: x + y, [1, 3, 5, 7, 9]) ) #
使用reduce进行求和运算
'''使用reduce将字符串反转'''
s = 'Hello World'
from functools import reduce result = reduce(lambda x,y:y+x,s)
# 1、第一次:x=H,y=e => y+x = eH
# 2、第二次:x=l,y=eH => y+x = leH
# 3、第三次:x=l,y=leH => y+x = lleH
print( result ) # dlroW olleH
使用reduce将字符串反转
7、sorted函数
1)sorted和sort区别
1. sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。
2. sort 是对已经存在的列表进行操作,无返回值,而 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。
2)sorted使用
sorted 语法:sorted(iterable, cmp=None, key=None, reverse=False)
iterable -- 可迭代对象。
cmp -- 比较的函数
key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
reverse -- 排序规则,reverse = True 降序 , reverse = False 升序(默认)。
students = [('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10)]
print( sorted(students, key=lambda s: s[2], reverse=False) ) # 按年龄排序
# 结果:[('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)]
sorted对列表排序
d = {'k1':1, 'k3': 3, 'k2':2}
# d.items() = [('k1', 1), ('k3', 3), ('k2', 2)]
a = sorted(d.items(), key=lambda x: x[1])
print(a) # [('k1', 1), ('k2', 2), ('k3', 3)]
sorted对字典排序
1.3 内置方法返回顶部
#1、all 判断对象 全部为正才为真,有一个为假就为假
print(all([0,1,-5])) # False
print(all([1,-1])) # True #2、any 判断对象 全部为假才为假,有一个为真就为真
print(any([0,1,-5])) # True
print(any([])) # False #3、bin 将十进制转换成二进制
print(bin(8)) # 0b1000 #4、callable 判断对象是否可以调用
def func():pass
print(callable(func)) # True #5、chr() 把数字对应的ascii码值打印出来
print(chr(98)) # b
#6、ord() 将ascii码中对应用的a,b等打印出对应的数字
print(ord("a")) # #7、compile() 将字符串转换成可执行的代码
s="print('hello world')"
py_obj = compile(s,"err.log","exec")
exec(py_obj) # hello world #8、dir() 查一个对象有哪些方法:
a = 'aaa'
print(dir(a)) #9、eval() 将一个数据类型的字符串变成对应的数据类型 #10、filter() 在一组数据中过滤出你想要的结果
res = filter(lambda n:n>5,range(10))
print(list(res)) # [6, 7, 8, 9] #11、map() 生成对应的数据
res = map(lambda n:n**2,range(10))
print(list(res)) # [0, 1, 4, 9, 16, 25, 36, 49, 64, 81] #12、reduce 返回运算结果
import functools
res = functools.reduce(lambda x,y:x+y,range(10))
print(res) # #13、divmod() 将两个数相除商的值和余数存到一个元组中
print(divmod(5,2)) # (2, 1) #14、frozenset() 将集合变成不可变改变的
a = frozenset(set([1,2,3,2,3,5,6])) #15、globals() 打印这个文件中所有定义的变量
print(globals()) #16、hash 将汉字,字符串等对象转换成对应的有序数字
print(hash("tom")) # #17、hex() 将十进制数字转成十六进制
print(hex(255)) # 0xff #18、oct() 转八进制
print(oct(8)) # 0o10 #19、pow() 计算多少次幂
print(pow(2,8)) # 2的8次方: 256 #20、round() 包留小数点后几位有效数字
print(round(1.43234,2)) # 1.43 #21、sorted() 将无序的值变成有序的
d = {6:2,8:0,1:4,-5:6}
print(d)
print(sorted(d.items())) #22、zip 将两个列表中的数据按照位置一一对应
a = [1,2,3,4]
b = ['a','b','c','d']
l = zip(a,b)
print(list(l)) # [(1, 'a'), (2, 'b'), (3, 'c'), (4, 'd')] #23、__import__ 可以使用字符串的 .py名称将模块导入
__import__()("test3")
23个内置方法
1.4 动态导入模块返回顶部
1、动态导入基本使用
测试目的: 在.py 文件中动态导入同级目录中的lib模块下的aa.py文件,这样可以调用aa.py下的类属性
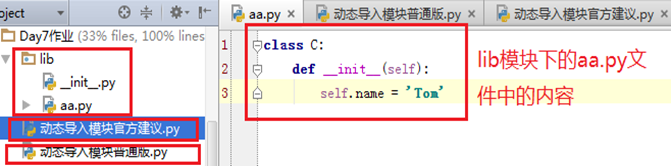
import importlib
aa = importlib.import_module('lib.aa') #这里的导入的直接就是aa.py这个文件
#<module 'lib.aa' from 'C:\\Users\\admin\\PycharmProjects\\s14\\Day7作业\\lib\\aa.py'>
print(aa.C().name) #直接可以打印 lib模块下的aa.py文件中类C的属性 self.name = Tom
法1:官方建议版 动态导入lib模块下的aa.py文件
mod = __import__('lib.aa')
#<module 'lib' from 'C:\\Users\\admin\\PycharmProjects\\s14\\Day7作业\\lib\\__init__.py'>
obj = mod.aa.C() #obj就是aa.py中类C的实例对象
print(obj.name) #打印出类C的属性name的值 self.name = Tom
法2:动态导入模块普通版 动态导入lib模块下的aa.py文件
2、cmdb中动态导入插件获取cpu等信息
import importlib
PLUGINS_DICT = {
'cpu': 'src.plugins.cpu.CpuPlugin',
'disk': 'src.plugins.disk.DiskPlugin',
}
for k, v in PLUGINS_DICT.items():
# module_path = module_path src.plugins.cpu
# cls_name = CpuPlugin
module_path, cls_name = v.rsplit('.', 1)
cls = getattr(importlib.import_module(module_path), cls_name)
obj = cls('c1.com').execute()
# cls = getattr(importlib.import_module('module_path src.plugins.cpu'), 'CpuPlugin')
run.py 动态导入模块
class BasePlugin(object):
def execute(self):
return self.linux() def linux(self):
raise Exception('You must implement linux method.') class BaseResponse(object):
def __init__(self):
self.status = True
self.message = None
self.data = None
self.error = None class CpuPlugin(BasePlugin):
def linux(self):
response = BaseResponse()
return response
src\plugins\cpu.py 其中的cup插件
07: python基础 零碎知识点的更多相关文章
- python基础全部知识点整理,超级全(20万字+)
目录 Python编程语言简介 https://www.cnblogs.com/hany-postq473111315/p/12256134.html Python环境搭建及中文编码 https:// ...
- Python基础——细琐知识点
注释 Python注释有两种方式 使用# 类似于Shell脚本的注释方式,单行注释 使用'''或者""" 使用成对的'''或者""".这种注 ...
- Python基础入门知识点——Python中的异常
前言 在先前的一些章节里你已经执行了一些代码,你一定遇到了程序“崩溃”或因未解决的错误而终止的情况.你会看到“跟踪记录(traceback)”消息以及随后解释器向你提供的信息,包括错误的名称.原因和发 ...
- Python基础入门知识点——深浅拷贝
深浅拷贝 对象引用.浅拷贝.深拷贝(拓展.难点.重点) Python中,对象的赋值,拷贝(深/浅拷贝)之间是有差异的,如果使用的时候不注意,就可能产生意外的结果 其实这个是由于共享内存导致的结果 拷贝 ...
- C#基础零碎知识点摘录
1.类分为静态类个非静态类(实例类) 静态类不能创建对象,使用方法时,直接类名.方法名(),常用的静态类有Console类 实例类:创建对象时通过对象调用类的方法 2.当我们声明一个类成员为静态时,意 ...
- 重学Python - Day 07 - python基础 -> linux命令行学习 -- 常用命令 一
常用命令和使用方法如下: man man 命令 #可以查询命令的用法 cat 和 tac cat是正序显示文件内容 tac是倒叙显示文件内容 sort 对文件内容排序 uniq 忽略文件中重复行 hi ...
- python基础---递归函数 知识点自查填空题
什么是递归函数:在函数中调()叫递归函数. 递归函数最大递归深度是997或998----是()设的限制. 注:如果递归次数太多,就不适合使用递归来解决问题. 递归的缺点: 占(). 递归的优点:会让代 ...
- Python基础入门知识点——if 语句简介
前言 if 语句是最简单的选择结构.如果满足条件就执行设定好的操作,不满足条件就执行其他其他操作. 判断的定义 如果 条件满足,才能做某件事情, 如果 条件不满足,就做另外一件事情,或者什么也不做 判 ...
- 学习python须知,Python基础进阶需掌握哪些知识点?
Python基础进阶需要掌握哪些知识点?Python将是每个程序员的标配,有编程基础再掌握Python语言对于日后的升职加薪更有利.Python语言简洁利于理解,语法上相对容易能够让开发者更专注于业务 ...
随机推荐
- EF 性能调优
--EF 批量增删改 http://www.cnblogs.com/lori/archive/2013/01/31/2887396.html http://www.cnblogs.com/gzalrj ...
- CodeForces - 586D Phillip and Trains 搜索。vis 剪枝。
http://codeforces.com/problemset/problem/586/D 题意:有一个3*n(n<100)的隧道.一个人在最左边,要走到最右边,每次他先向右移动一格,再上下移 ...
- Linux下的反调试技术
Linux下的反调试技术 2014年01月30日 ⁄ 综合 ⁄ 共 2669字 ⁄ 字号 小 中 大 ⁄ 评论关闭 转自 http://wangcong.org/blog/archives/310 ...
- 【RBAC】打造Web权限控制系统
引言 权限系统模块对于互联网产品是一个非常重要的功能,可以控制不同的角色合理的访问不同的资源从而达到安全访问的作用 此外本次课程有视频讲解: http://www.imooc.com/learn/79 ...
- 【JMeter】如何优雅的写脚本
cc给发的视频链接: http://v.youku.com/v_show/id_XMzA4Mjg1ODA0MA==.html?spm=a2h3j.8428770.3416059.1 ————————— ...
- requests库的get请求,带有cookies
(一)如何带cookies请求 方法一:headers中带cookies #coding:utf-8 import requests import re # 构建url url = 'http://w ...
- linux下的字符界面和图形界面转换
linux下的字符界面和图形界面转换 linux下有六个虚拟终端按键ctrl+alt+F1-F6可以进入相应的虚拟终端永久的话修改/etc/inittab将id:5:initdefault:中的5改成 ...
- filter push down
filter push down filter push down :先filter再做join 如果SQL里有where条件,那么数据库引擎会先filter再做join 但是MySQL5.6之前还不 ...
- [wx]自然数学规律
有趣的数学规律 椭圆 双曲线 抛物线都叫圆锥曲线 它们跟圆锥有着怎样的关系? 他们都是圆锥与平面在不同姿势下交配的产物. 参考 椭圆 抛物线 小结 e: 离线率 P: 任意一点 F: 焦点 准线: 一 ...
- [LeetCode] 64. Minimum Path Sum_Medium tag: Dynamic Programming
Given a m x n grid filled with non-negative numbers, find a path from top left to bottom right which ...