Hadoop MapReduce执行过程实例分析
1.MapReduce是如何执行任务的?
2.Mapper任务是怎样的一个过程?
3.Reduce是如何执行任务的?
4.键值对是如何编号的?
5.实例,如何计算没见最高气温?
分析MapReduce执行过程
MapReduce运行的时候,会通过Mapper运行的任务读取HDFS中的数据文件,然后调用自己的方法,处理数据,最后输出。Reducer任务会接收Mapper任务输出的数据,作为自己的输入数据,调用自己的方法,最后输出到HDFS的文件中。整个流程如图: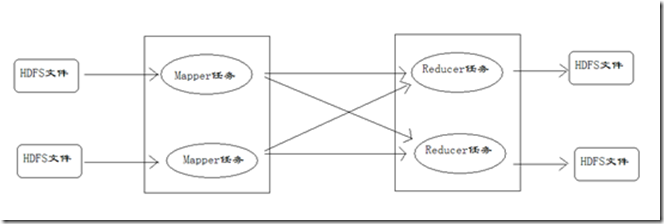
Mapper任务的执行过程详解
每个Mapper任务是一个java进程,它会读取HDFS中的文件,解析成很多的键值对,经过我们覆盖的map方法处理后,转换为很多的键值对再输出。整个Mapper任务的处理过程又可以分为以下几个阶段,如图所示。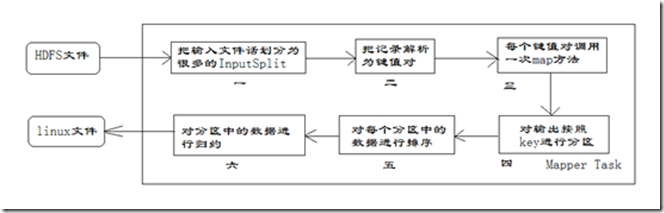
在上图中,把Mapper任务的运行过程分为六个阶段。
- 第一阶段是把输入文件按照一定的标准分片(InputSplit),每个输入片的大小是固定的。默认情况下,输入片(InputSplit)的大小与数据块(Block)的大小是相同的。如果数据块(Block)的大小是默认值64MB,输入文件有两个,一个是32MB,一个是72MB。那么小的文件是一个输入片,大文件会分为两个数据块,那么是两个输入片。一共产生三个输入片。每一个输入片由一个Mapper进程处理。这里的三个输入片,会有三个Mapper进程处理。
- 第二阶段是对输入片中的记录按照一定的规则解析成键值对。有个默认规则是把每一行文本内容解析成键值对。“键”是每一行的起始位置(单位是字节),“值”是本行的文本内容。
- 第三阶段是调用Mapper类中的map方法。第二阶段中解析出来的每一个键值对,调用一次map方法。如果有1000个键值对,就会调用1000次map方法。每一次调用map方法会输出零个或者多个键值对。
- 第四阶段是按照一定的规则对第三阶段输出的键值对进行分区。比较是基于键进行的。比如我们的键表示省份(如北京、上海、山东等),那么就可以按照不同省份进行分区,同一个省份的键值对划分到一个区中。默认是只有一个区。分区的数量就是Reducer任务运行的数量。默认只有一个Reducer任务。
- 第五阶段是对每个分区中的键值对进行排序。首先,按照键进行排序,对于键相同的键值对,按照值进行排序。比如三个键值对<2,2>、<1,3>、<2,1>,键和值分别是整数。那么排序后的结果是<1,3>、<2,1>、<2,2>。如果有第六阶段,那么进入第六阶段;如果没有,直接输出到本地的linux文件中。
- 第六阶段是对数据进行归约处理,也就是reduce处理。键相等的键值对会调用一次reduce方法。经过这一阶段,数据量会减少。归约后的数据输出到本地的linxu文件中。本阶段默认是没有的,需要用户自己增加这一阶段的代码。
Reducer任务的执行过程详解
每个Reducer任务是一个java进程。Reducer任务接收Mapper任务的输出,归约处理后写入到HDFS中,可以分为如下图所示的几个阶段。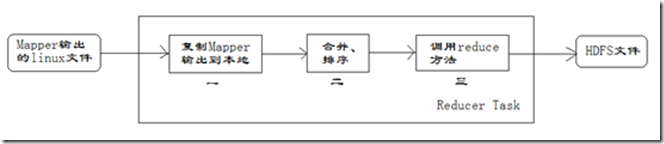
- 第一阶段是Reducer任务会主动从Mapper任务复制其输出的键值对。Mapper任务可能会有很多,因此Reducer会复制多个Mapper的输出。
- 第二阶段是把复制到Reducer本地数据,全部进行合并,即把分散的数据合并成一个大的数据。再对合并后的数据排序。
- 第三阶段是对排序后的键值对调用reduce方法。键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对。最后把这些输出的键值对写入到HDFS文件中。
在整个MapReduce程序的开发过程中,我们最大的工作量是覆盖map函数和覆盖reduce函数。
键值对的编号
在对Mapper任务、Reducer任务的分析过程中,会看到很多阶段都出现了键值对,读者容易混淆,所以这里对键值对进行编号,方便大家理解键值对的变化情况,如下图所示。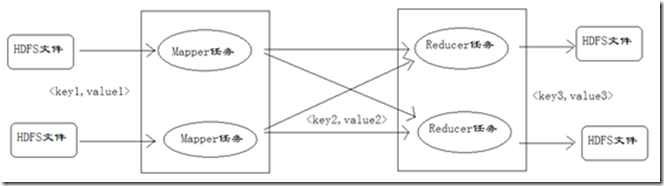
在上图中,对于Mapper任务输入的键值对,定义为key1和value1。在map方法中处理后,输出的键值对,定义为key2和value2。reduce方法接收key2和value2,处理后,输出key3和value3。在下文讨论键值对时,可能把key1和value1简写为<k1,v1>,key2和value2简写为<k2,v2>,key3和value3简写为<k3,v3>。
以上内容来自:http://www.superwu.cn/2013/08/21/530/
-----------------------分------------------割----------------线-------------------------
例子:求每年最高气温
在HDFS中的根目录下有以下文件格式: /input.txt
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
2014010114201401021620140103172014010410201401050620120106092012010732201201081220120109192012011023200101011620010102122001010310200101041120010105292013010619201301072220130108122013010929201301102320080101052008010216200801033720080104142008010516200701061920070107122007010812200701099920070110232010010114201001021620100103172010010410201001050620150106492015010722201501081220150109992015011023 |
比如:2010012325表示在2010年01月23日的气温为25度。现在要求使用MapReduce,计算每一年出现过的最大气温。
在写代码之前,先确保正确的导入了相关的jar包。我使用的是maven,可以到http://mvnrepository.com去搜索这几个artifactId。
此程序需要以Hadoop文件作为输入文件,以Hadoop文件作为输出文件,因此需要用到文件系统,于是需要引入hadoop-hdfs包;我们需要向Map-Reduce集群提交任务,需要用到Map-Reduce的客户端,于是需要导入hadoop-mapreduce-client-jobclient包;另外,在处理数据的时候会用到一些hadoop的数据类型例如IntWritable和Text等,因此需要导入hadoop-common包。于是运行此程序所需要的相关依赖有以下几个:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.4.0</version></dependency><dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-jobclient</artifactId> <version>2.4.0</version></dependency><dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.4.0</version></dependency> |
包导好了后, 设计代码如下:
|
001
002
003
004
005
006
007
008
009
010
011
012
013
014
015
016
017
018
019
020
021
022
023
024
025
026
027
028
029
030
031
032
033
034
035
036
037
038
039
040
041
042
043
044
045
046
047
048
049
050
051
052
053
054
055
056
057
058
059
060
061
062
063
064
065
066
067
068
069
070
071
072
073
074
075
076
077
078
079
080
081
082
083
084
085
086
087
088
089
090
091
092
093
094
095
096
097
098
099
100
101
102
103
104
105
|
package com.abc.yarn; import java.io.IOException; import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class Temperature { /** * 四个泛型类型分别代表: * KeyIn Mapper的输入数据的Key,这里是每行文字的起始位置(0,11,...) * ValueIn Mapper的输入数据的Value,这里是每行文字 * KeyOut Mapper的输出数据的Key,这里是每行文字中的“年份” * ValueOut Mapper的输出数据的Value,这里是每行文字中的“气温” */ static class TempMapper extends Mapper<LongWritable, Text, Text, IntWritable> { @Override public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 打印样本: Before Mapper: 0, 2000010115 System.out.print("Before Mapper: " + key + ", " + value); String line = value.toString(); String year = line.substring(0, 4); int temperature = Integer.parseInt(line.substring(8)); context.write(new Text(year), new IntWritable(temperature)); // 打印样本: After Mapper:2000, 15 System.out.println( "======" + "After Mapper:" + new Text(year) + ", " + new IntWritable(temperature)); } } /** * 四个泛型类型分别代表: * KeyIn Reducer的输入数据的Key,这里是每行文字中的“年份” * ValueIn Reducer的输入数据的Value,这里是每行文字中的“气温” * KeyOut Reducer的输出数据的Key,这里是不重复的“年份” * ValueOut Reducer的输出数据的Value,这里是这一年中的“最高气温” */ static class TempReducer extends Reducer<Text, IntWritable, Text, IntWritable> { @Override public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int maxValue = Integer.MIN_VALUE; StringBuffer sb = new StringBuffer(); //取values的最大值 for (IntWritable value : values) { maxValue = Math.max(maxValue, value.get()); sb.append(value).append(", "); } // 打印样本: Before Reduce: 2000, 15, 23, 99, 12, 22, System.out.print("Before Reduce: " + key + ", " + sb.toString()); context.write(key, new IntWritable(maxValue)); // 打印样本: After Reduce: 2000, 99 System.out.println( "======" + "After Reduce: " + key + ", " + maxValue); } } public static void main(String[] args) throws Exception { //输入路径 String dst = "hdfs://localhost:9000/intput.txt"; //输出路径,必须是不存在的,空文件加也不行。 String dstOut = "hdfs://localhost:9000/output"; Configuration hadoopConfig = new Configuration(); hadoopConfig.set("fs.hdfs.impl", org.apache.hadoop.hdfs.DistributedFileSystem.class.getName() ); hadoopConfig.set("fs.file.impl", org.apache.hadoop.fs.LocalFileSystem.class.getName() ); Job job = new Job(hadoopConfig); //如果需要打成jar运行,需要下面这句 //job.setJarByClass(NewMaxTemperature.class); //job执行作业时输入和输出文件的路径 FileInputFormat.addInputPath(job, new Path(dst)); FileOutputFormat.setOutputPath(job, new Path(dstOut)); //指定自定义的Mapper和Reducer作为两个阶段的任务处理类 job.setMapperClass(TempMapper.class); job.setReducerClass(TempReducer.class); //设置最后输出结果的Key和Value的类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //执行job,直到完成 job.waitForCompletion(true); System.out.println("Finished"); }} |
上面代码中,注意Mapper类的泛型不是java的基本类型,而是Hadoop的数据类型Text、IntWritable。我们可以简单的等价为java的类String、int。
代码中Mapper类的泛型依次是<k1,v1,k2,v2>。map方法的第二个形参是行文本内容,是我们关心的。核心代码是把行文本内容按照空格拆分,把每行数据中“年”和“气温”提取出来,其中“年”作为新的键,“温度”作为新的值,写入到上下文context中。在这里,因为每一年有多行数据,因此每一行都会输出一个<年份, 气温>键值对。
下面是控制台打印结果:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
Before Mapper: 0, 2014010114======After Mapper:2014, 14Before Mapper: 11, 2014010216======After Mapper:2014, 16Before Mapper: 22, 2014010317======After Mapper:2014, 17Before Mapper: 33, 2014010410======After Mapper:2014, 10Before Mapper: 44, 2014010506======After Mapper:2014, 6Before Mapper: 55, 2012010609======After Mapper:2012, 9Before Mapper: 66, 2012010732======After Mapper:2012, 32Before Mapper: 77, 2012010812======After Mapper:2012, 12Before Mapper: 88, 2012010919======After Mapper:2012, 19Before Mapper: 99, 2012011023======After Mapper:2012, 23Before Mapper: 110, 2001010116======After Mapper:2001, 16Before Mapper: 121, 2001010212======After Mapper:2001, 12Before Mapper: 132, 2001010310======After Mapper:2001, 10Before Mapper: 143, 2001010411======After Mapper:2001, 11Before Mapper: 154, 2001010529======After Mapper:2001, 29Before Mapper: 165, 2013010619======After Mapper:2013, 19Before Mapper: 176, 2013010722======After Mapper:2013, 22Before Mapper: 187, 2013010812======After Mapper:2013, 12Before Mapper: 198, 2013010929======After Mapper:2013, 29Before Mapper: 209, 2013011023======After Mapper:2013, 23Before Mapper: 220, 2008010105======After Mapper:2008, 5Before Mapper: 231, 2008010216======After Mapper:2008, 16Before Mapper: 242, 2008010337======After Mapper:2008, 37Before Mapper: 253, 2008010414======After Mapper:2008, 14Before Mapper: 264, 2008010516======After Mapper:2008, 16Before Mapper: 275, 2007010619======After Mapper:2007, 19Before Mapper: 286, 2007010712======After Mapper:2007, 12Before Mapper: 297, 2007010812======After Mapper:2007, 12Before Mapper: 308, 2007010999======After Mapper:2007, 99Before Mapper: 319, 2007011023======After Mapper:2007, 23Before Mapper: 330, 2010010114======After Mapper:2010, 14Before Mapper: 341, 2010010216======After Mapper:2010, 16Before Mapper: 352, 2010010317======After Mapper:2010, 17Before Mapper: 363, 2010010410======After Mapper:2010, 10Before Mapper: 374, 2010010506======After Mapper:2010, 6Before Mapper: 385, 2015010649======After Mapper:2015, 49Before Mapper: 396, 2015010722======After Mapper:2015, 22Before Mapper: 407, 2015010812======After Mapper:2015, 12Before Mapper: 418, 2015010999======After Mapper:2015, 99Before Mapper: 429, 2015011023======After Mapper:2015, 23Before Reduce: 2001, 12, 10, 11, 29, 16, ======After Reduce: 2001, 29Before Reduce: 2007, 23, 19, 12, 12, 99, ======After Reduce: 2007, 99Before Reduce: 2008, 16, 14, 37, 16, 5, ======After Reduce: 2008, 37Before Reduce: 2010, 10, 6, 14, 16, 17, ======After Reduce: 2010, 17Before Reduce: 2012, 19, 12, 32, 9, 23, ======After Reduce: 2012, 32Before Reduce: 2013, 23, 29, 12, 22, 19, ======After Reduce: 2013, 29Before Reduce: 2014, 14, 6, 10, 17, 16, ======After Reduce: 2014, 17Before Reduce: 2015, 23, 49, 22, 12, 99, ======After Reduce: 2015, 99 |
执行结果:

对分析的验证
从打印的日志中可以看出:
- Mapper的输入数据(k1,v1)格式是:默认的按行分的键值对<0, 2010012325>,<11, 2012010123>...
- Reducer的输入数据格式是:把相同的键合并后的键值对:<2001, [12, 32, 25...]>,<2007, [20, 34, 30...]>...
- Reducer的输出数(k3,v3)据格式是:经自己在Reducer中写出的格式:<2001, 32>,<2007, 34>...
其中,由于输入数据太小,Map过程的第1阶段这里不能证明。但事实上是这样的。
结论中第一点验证了Map过程的第2阶段:“键”是每一行的起始位置(单位是字节),“值”是本行的文本内容。
另外,通过Reduce的几行
|
1
2
3
4
5
6
7
8
|
Before Reduce: 2001, 12, 10, 11, 29, 16, ======After Reduce: 2001, 29Before Reduce: 2007, 23, 19, 12, 12, 99, ======After Reduce: 2007, 99Before Reduce: 2008, 16, 14, 37, 16, 5, ======After Reduce: 2008, 37Before Reduce: 2010, 10, 6, 14, 16, 17, ======After Reduce: 2010, 17Before Reduce: 2012, 19, 12, 32, 9, 23, ======After Reduce: 2012, 32Before Reduce: 2013, 23, 29, 12, 22, 19, ======After Reduce: 2013, 29Before Reduce: 2014, 14, 6, 10, 17, 16, ======After Reduce: 2014, 17Before Reduce: 2015, 23, 49, 22, 12, 99, ======After Reduce: 2015, 99 |
可以证实Map过程的第4阶段:先分区,然后对每个分区都执行一次Reduce(Map过程第6阶段)。
对于Mapper的输出,前文中提到:如果没有Reduce过程,Mapper的输出会直接写入文件。于是我们把Reduce方法去掉(注释掉第95行即可)。
再执行,下面是控制台打印结果:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
Before Mapper: 0, 2014010114======After Mapper:2014, 14Before Mapper: 11, 2014010216======After Mapper:2014, 16Before Mapper: 22, 2014010317======After Mapper:2014, 17Before Mapper: 33, 2014010410======After Mapper:2014, 10Before Mapper: 44, 2014010506======After Mapper:2014, 6Before Mapper: 55, 2012010609======After Mapper:2012, 9Before Mapper: 66, 2012010732======After Mapper:2012, 32Before Mapper: 77, 2012010812======After Mapper:2012, 12Before Mapper: 88, 2012010919======After Mapper:2012, 19Before Mapper: 99, 2012011023======After Mapper:2012, 23Before Mapper: 110, 2001010116======After Mapper:2001, 16Before Mapper: 121, 2001010212======After Mapper:2001, 12Before Mapper: 132, 2001010310======After Mapper:2001, 10Before Mapper: 143, 2001010411======After Mapper:2001, 11Before Mapper: 154, 2001010529======After Mapper:2001, 29Before Mapper: 165, 2013010619======After Mapper:2013, 19Before Mapper: 176, 2013010722======After Mapper:2013, 22Before Mapper: 187, 2013010812======After Mapper:2013, 12Before Mapper: 198, 2013010929======After Mapper:2013, 29Before Mapper: 209, 2013011023======After Mapper:2013, 23Before Mapper: 220, 2008010105======After Mapper:2008, 5Before Mapper: 231, 2008010216======After Mapper:2008, 16Before Mapper: 242, 2008010337======After Mapper:2008, 37Before Mapper: 253, 2008010414======After Mapper:2008, 14Before Mapper: 264, 2008010516======After Mapper:2008, 16Before Mapper: 275, 2007010619======After Mapper:2007, 19Before Mapper: 286, 2007010712======After Mapper:2007, 12Before Mapper: 297, 2007010812======After Mapper:2007, 12Before Mapper: 308, 2007010999======After Mapper:2007, 99Before Mapper: 319, 2007011023======After Mapper:2007, 23Before Mapper: 330, 2010010114======After Mapper:2010, 14Before Mapper: 341, 2010010216======After Mapper:2010, 16Before Mapper: 352, 2010010317======After Mapper:2010, 17Before Mapper: 363, 2010010410======After Mapper:2010, 10Before Mapper: 374, 2010010506======After Mapper:2010, 6Before Mapper: 385, 2015010649======After Mapper:2015, 49Before Mapper: 396, 2015010722======After Mapper:2015, 22Before Mapper: 407, 2015010812======After Mapper:2015, 12Before Mapper: 418, 2015010999======After Mapper:2015, 99Before Mapper: 429, 2015011023======After Mapper:2015, 23Finished |
再来看看执行结果:
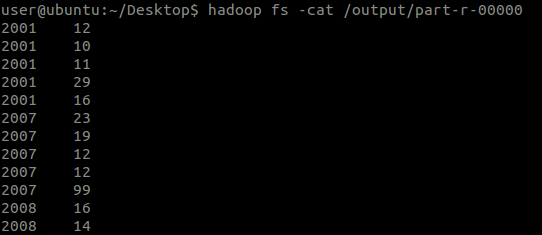
结果还有很多行,没有截图了。
由于没有执行Reduce操作,因此这个就是Mapper输出的中间文件的内容了。
从打印的日志可以看出:
- Mapper的输出数据(k2, v2)格式是:经自己在Mapper中写出的格式:<2010, 25>,<2012, 23>...
从这个结果中可以看出,原数据文件中的每一行确实都有一行输出,那么Map过程的第3阶段就证实了。
从这个结果中还可以看出,“年份”已经不是输入给Mapper的顺序了,这也说明了在Map过程中也按照Key执行了排序操作,即Map过程的第5阶段。
Hadoop MapReduce执行过程实例分析的更多相关文章
- Hive(六)hive执行过程实例分析与hive优化策略
一.Hive 执行过程实例分析 1.join 对于 join 操作:SELECT pv.pageid, u.age FROM page_view pv JOIN user u ON (pv.useri ...
- Hadoop MapReduce执行过程详解(带hadoop例子)
https://my.oschina.net/itblog/blog/275294 摘要: 本文通过一个例子,详细介绍Hadoop 的 MapReduce过程. 分析MapReduce执行过程 Map ...
- Hadoop mapreduce执行过程涉及api
资源的申请,分配过程略过,从开始执行开始. mapper阶段: 首先调用默认的PathFilter进行文件过滤,确定哪些输入文件是需要的哪些是不需要的,然后调用inputFormat的getSplit ...
- Hive学习之路 (二十)Hive 执行过程实例分析
一.Hive 执行过程概述 1.概述 (1) Hive 将 HQL 转换成一组操作符(Operator),比如 GroupByOperator, JoinOperator 等 (2)操作符 Opera ...
- Hive(九)Hive 执行过程实例分析
一.Hive 执行过程概述 1.概述 (1) Hive 将 HQL 转换成一组操作符(Operator),比如 GroupByOperator, JoinOperator 等 (2)操作符 Opera ...
- hadoop -- mapreduce执行过程
1.运行mapreduce程序 ---run2.本次运行将会生成呢个一个Job , 于是JobClient向JobTracker申请一个JobID 标识该Job.3.JobClient将Job需要的 ...
- Hadoop学习之Mapreduce执行过程详解
一.MapReduce执行过程 MapReduce运行时,首先通过Map读取HDFS中的数据,然后经过拆分,将每个文件中的每行数据分拆成键值对,最后输出作为Reduce的输入,大体执行流程如下图所示: ...
- 分析MapReduce执行过程
分析MapReduce执行过程 MapReduce运行的时候,会通过Mapper运行的任务读取HDFS中的数据文件,然后调用自己的方法,处理数据,最后输出. Reducer任务会接收Mapper任务输 ...
- 分析MapReduce执行过程+统计单词数例子
MapReduce 运行的时候,会通过 Mapper 运行的任务读取 HDFS 中的数据文件,然后调用自己的方法,处理数据,最后输出.Reducer 任务会接收 Mapper 任务输出的数据,作为自己 ...
随机推荐
- easyui_2----messager
<script> $.messager.alert("这是头","这是内容"); </script> 必须放在 $(function() ...
- 蓝桥杯 - G将军有一支训练有素的军队 - [树形DP]
G将军有一支训练有素的军队,这个军队除开G将军外,每名士兵都有一个直接上级(可能是其他士兵,也可能是G将军).现在G将军将接受一个特别的任务,需要派遣一部分士兵(至少一个)组成一个敢死队,为了增加敢死 ...
- Codeforces 592D - Super M - [树的直径][DFS]
Time limit 2000 ms Memory limit 262144 kB Source Codeforces Round #328 (Div. 2) Ari the monster is n ...
- python数据结构之动态数组
数组列表:动态数组(Array List) 简介: 最基础简单的数据结构.最大的优点就是支持随机访问(O(1)),但是增加和删除操作效率就低一些(平均时间复杂度O(n)) 动态数组也称数组列表,在py ...
- iOS-多语言版本开发(二)(转载)
题记 iOS 多语言版本的开发(一) 中我们完成了让应用跟随系统语言进行切换,而用户自己却不能切换的功能,也基本上算是实现了多语言版本:可是,对于某些应用来说,实现跟随系统语言切换的同时, 也想要 ...
- django比较相等或者不相等的模板语法ifequal / ifnotequal
转自:http://blog.csdn.net/goupper1991/article/details/50768346 ifequal / ifnotequal 在模板语言里比较两个值并且 ...
- 场景服务只创建了 Service Difinition 和feature layer
环境:物理机 pro1.4:虚拟机 (server + datastore + portal + adaptor) 10.4.1 发布场景服务,正常情况应portal中查看,应包含四部分内容:Serv ...
- 如何让dedecms文章点击量增加一定的数值
用dedecms建站都知道有一个文章点击量这个参数,我们可不可以用这个浏览量做些延伸扩展呢?比如加上一个固定值变成另外一个指标.很多朋友已经想到了,如下图,我们将本文浏览量286设为点击量,加上300 ...
- java获取屏幕密度
方法1: float xdpi = getResources().getDisplayMetrics().widthPixels;float ydpi = getResources().getDisp ...
- matlab 绘制条状图形
clear,clc;A=zeros(1080,1920,3);A(:,1:384,:)=0;A(:,385:768,:)=10;A(:,769:1152,:)=20;A(:,1153:1536,:)= ...