Kafka介绍及安装部署
本节内容:
- 消息中间件
- 消息中间件特点
- 消息中间件的传递模型
- Kafka介绍
- 安装部署Kafka集群
- 安装Yahoo kafka manager
- kafka-manager添加kafka cluster
一、消息中间件
消息中间件是在消息的传输过程中保存消息的容器。消息中间件在将消息从消息生产者到消费者时充当中间人的作用。队列的主要目的是提供路由并保证消息的传送;如果发送消息时接收者不可用,消息对列会保留消息,直到可以成功地传递它为止,当然,消息队列保存消息也是有期限的。
二、消息中间件特点
1. 采用异步处理模式
消息发送者可以发送一个消息而无须等待响应。消息发送者将消息发送到一条虚拟的通道(主题或者队列)上,消息接收者则订阅或者监听该通道。一条消息可能最终转发给一个或多个消息接收者,这些接收者都无需对消息发送者做出同步回应。整个过程是异步的。
- 比如用户信息注册。注册完成后过段时间发送邮件或者短信。
2. 应用程序和应用程序调用关系为松耦合关系
- 发送者和接收者不必要了解对方、只需要确认消息
- 发送者和接收者不必同时在线
比如在线交易系统为了保证数据的最终一致,在支付系统处理完成后会把支付结果放到信息中间件里通知订单系统修改订单支付状态。两个系统通过消息中间件解耦。
三、消息中间件的传递模型
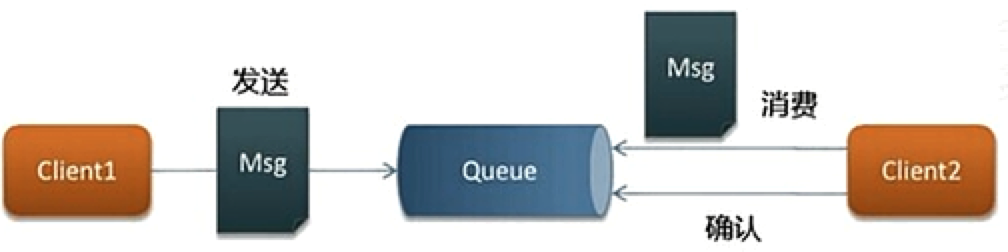
1. 点对点模型(PTP)
点对点模型用于消息生产者和消息消费者之间点对点的通信。消息生产者将消息发送到由某个名字标识的特定消费者。这个名字实际上对应于消费服务中的一个队列(Queue),在消息传递给消费者之前它被存储在这个队列中。队列消息可以放在内存中也可以是持久的,以保证在消息服务出现故障时仍然能够传递消息。
点对点模型特性:
- 每个消息只有一个消费者
- 发送者和接受者没有时间依赖
- 接受者确认消息接受和处理成功
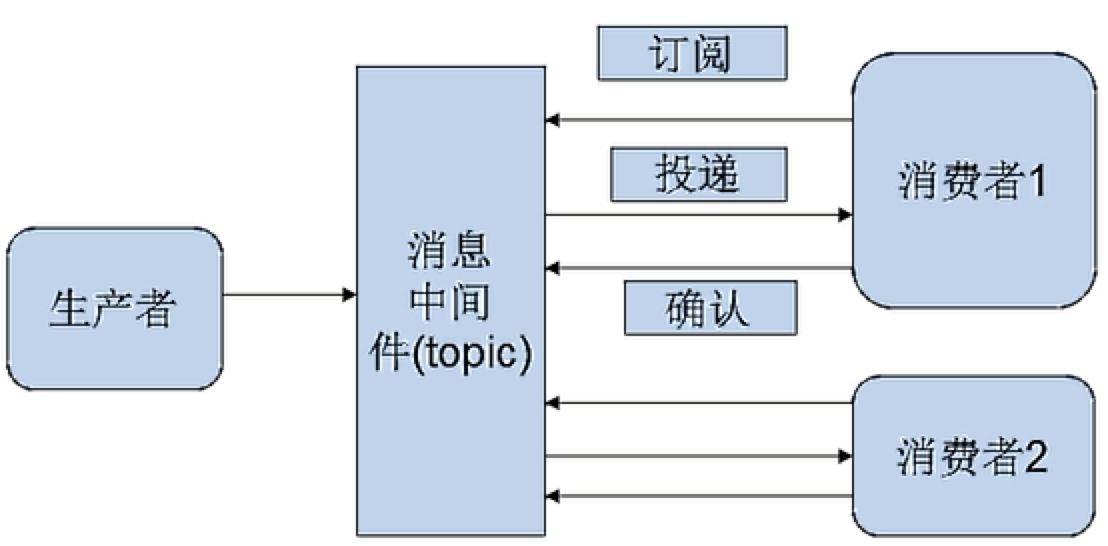
2. 发布—订阅模型(Pub/Sub)
发布者/订阅者模型支持向一个特定的消息主题生产消息。0或多个订阅者可能对接收来自特定消息主题的消息感兴趣。在这种模型下,发布者和订阅者彼此不知道对方。这种模式好比是匿名公告板。这种模式被概括为:多个消费者可以获得消息。在发布者和订阅者之间存在时间依赖性。发布者需要建立一个订阅(subscription),以便能够让消费者订阅。订阅者必须保持持续的活动状态以接收消息,除非订阅者建立了持久的订阅。在这种情况下,在订阅者未连接时发布的消息将在订阅者重新连接时重新发布。
其实消息中间件,像MySQL其实也可以作为消息中间件,只要你把消息中间件原理搞清楚,你会发现目前所有的存储,包括NoSQL,只要支持顺序性东西的,就可以作为一个消息中间件。就看你怎么去利用它了。就像redis里面那个队列list,就可以作为一个消息队列。
发布—订阅模型特性:
- 每个消息可以有多个订阅者
- 客户端只有订阅后才能接收到消息
- 持久订阅和非持久订阅
(1) 发布者和订阅者有时间依赖
接收者和发布者只有建立订阅关系才能收到消息。
(2) 持久订阅
订阅关系建立后,消息就不会消失,不管订阅者是否在线。
(3) 非持久订阅
订阅者为了接收消息,必须一直在线
当只有一个订阅者时约等于点对点模式。
大部分情况下会使用持久订阅。常用的消息队列有Kafka、RabbitMQ、ActiveMQ、metaq等。
四、Kafka介绍
Kafka是一种分布式消息系统,由LinkedIn使用Scala编写,用作LinkedIn的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础,具有高水平扩展和高吞吐量。
目前越来越多的开源分布式处理系统如Apache flume、Apache Storm、Spark、Elasticsearch都支持与Kafka集成。
五、安装部署Kafka集群
1. 环境信息
| 主机名 | 操作系统版本 | IP地址 | 安装软件 |
| log1 | CentOS 7.0 | 114.55.29.86 | JDK1.7、kafka_2.11-0.9.0.1 |
| log2 | CentOS 7.0 | 114.55.29.241 | JDK1.7、kafka_2.11-0.9.0.1 |
| log3 | CentOS 7.0 | 114.55.253.15 | JDK1.7、kafka_2.11-0.9.0.1 |
2. 安装JDK1.7
3台机器都需要安装JDK1.7。
[root@log1 local]# mkdir /usr/java
[root@log1 local]# tar zxf jdk-7u80-linux-x64.gz -C /usr/java/
[root@log1 local]# vim /etc/profile
export JAVA_HOME=/usr/java/jdk1..0_80
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
[root@log1 local]# source /etc/profile
安装JDK7
3. 安装集群
需要先安装好Zookeeper集群,见之前的文章《Zookeeper介绍及安装部署》。
(1)创建消息持久化目录
[root@log1 ~]# mkdir /kafkaLogs
(2)下载解压kafka,版本是kafka_2.11-0.9.0.1
[root@log1 local]# wget http://mirrors.cnnic.cn/apache/kafka/0.9.0.1/kafka_2.11-0.9.0.1.tgz
[root@log1 local]# tar zxf kafka_2.-0.9.0.1.tgz
(3)修改配置
[root@log1 local]# cd kafka_2.-0.9.0.1/config/
[root@log1 config]# vim server.properties
- 修改broker.id

- 修改kafka监听地址

注意: advertised.host.name参数用来配置返回的host.name值,把这个参数配置为IP地址。这样客户端在使用java.net.InetAddress.getCanonicalHostName()获取时拿到的就是ip地址而不是主机名。
- 修改消息持久化目录

- 修改zk地址

- 添加启用删除topic配置

- 关闭自动创建topic
是否允许自动创建topic。如果设为true,那么produce,consume或者fetch metadata一个不存在的topic时,就会自动创建一个默认replication factor和partition number的topic。默认是true。
auto.create.topics.enable=false

(4)把log1的配置好的kafka拷贝到log2和log3上
[root@log1 local]# scp -rp kafka_2.-0.9.0.1 root@114.55.29.241:/usr/local/
[root@log1 local]# scp -rp kafka_2.-0.9.0.1 root@114.55.253.15:/usr/local/
(5)log2和log3主机上创建消息持久化目录
[root@log2 ~]# mkdir /kafkaLogs
[root@log3 ~]# mkdir /kafkaLogs
(6)修改log2配置文件中的broker.id为1,log3主机的为2
[root@log2 config]# vim server.properties

4. 启动集群
log1主机启动kafka:
[root@log1 ~]# cd /usr/local/kafka_2.-0.9.0.1/
[root@log1 kafka_2.-0.9.0.1]# JMX_PORT= bin/kafka-server-start.sh -daemon config/server.properties &
log1主机启动kafka
log2主机启动kafka:
[root@log2 ~]# cd /usr/local/kafka_2.-0.9.0.1/
[root@log2 kafka_2.-0.9.0.1]# JMX_PORT= bin/kafka-server-start.sh -daemon config/server.properties &
log2主机启动kafka
log3主机启动kafka:
[root@log3 ~]# cd /usr/local/kafka_2.-0.9.0.1/
[root@log3 kafka_2.-0.9.0.1]# JMX_PORT= bin/kafka-server-start.sh -daemon config/server.properties &
log3主机启动kafka
5. 脚本定期清理logs下的日志文件
默认kafka是按天切割日志的,而且不删除:
这里写一个简单的脚本来清理这些日志,主要是清理server.log和controller.log。
[root@log1 ~]# cd /usr/local/kafka_2.-0.9.0.1/
[root@log1 kafka_2.-0.9.0.1]# vim clean_kafkalog.sh
#!/bin/bash
###Description:This script is used to clear kafka logs, not message file.
###Written by: jkzhao - jkzhao@wisedu.com
###History: -- First release. # log file dir.
logDir=/usr/local/kafka_2.-0.9.0.1/logs # Reserved files.
COUNT= ls -t $logDir/server.log* | tail -n +$[$COUNT+] | xargs rm -f
ls -t $logDir/controller.log* | tail -n +$[$COUNT+] | xargs rm -f
ls -t $logDir/state-change.log* | tail -n +$[$COUNT+] | xargs rm -f
ls -t $logDir/log-cleaner.log* | tail -n +$[$COUNT+] | xargs rm –f
清理kafka日志的脚本
赋予脚本执行权限:
[root@log1 kafka_2.-0.9.0.1]# chmod +x clean_kafkalog.sh
周期性任务策略:每周日的0点0分去执行这个脚本。
[root@log1 logs]# crontab -e
* * /usr/local/kafka_2.-0.9.0.1/clean_kafkalog.sh
把清理日志的脚本拷贝到第二台和第三台主机:
[root@log1 kafka_2.-0.9.0.1]# scp -p clean_kafkalog.sh root@114.55.29.241:/usr/local/kafka_2.-0.9.0.1
[root@log1 kafka_2.-0.9.0.1]# scp -p clean_kafkalog.sh root@114.55.253.15:/usr/local/kafka_2.-0.9.0.1
6. 停止kafka命令
[root@log1 ~]# /usr/local/kafka_2.-0.9.0.1/bin/kafka-server-stop.sh
7. 测试集群
(1)log1主机上创建一个名为test的topic
[root@log1 kafka_2.-0.9.0.1]# bin/kafka-topics.sh --create --zookeeper localhost: --replication-factor --partitions --topic test
(2)log2和log3主机上利用命令行工具创建一个consumer程序
[root@log2 kafka_2.-0.9.0.1]# bin/kafka-console-consumer.sh --zookeeper localhost: --topic test --from-beginning
[root@log2 kafka_2.-0.9.0.1]# bin/kafka-console-consumer.sh --zookeeper localhost: --topic test --from-beginning
(3)log1主机上利用命令行工具创建一个producer程序
[root@log1 kafka_2.-0.9.0.1]# bin/kafka-console-producer.sh --broker-list localhost: --topic test
log1主机上终端输入message,然后到log2和log3主机的终端查看:


8. 创建生产环境topic
如果kafka集群是3台,我们创建一个名为business的Topic,如下:
bin/kafka-topics.sh --create --zookeeper localhost: --replication-factor --partitions --topic business
注意:为Topic创建分区时,--partitions(分区数)最好是broker数量的整数倍,这样才能使一个Topic的分区均匀的分布在整个Kafka集群中。
9. Kafka常用命令
(1)启动kafka
nohup bin/kafka-server-start.sh config/server.properties > /dev/null >& &
(2)查看topic
bin/kafka-topics.sh --list --zookeeper localhost:
(3)控制台消费
bin/kafka-console-consumer.sh --zookeeper localhost: --topic middleware --from-beginning
(4)删除topic
- 删除kafka存储目录(server.properties文件log.dirs配置,默认为"/tmp/kafka-logs")相关topic目录
- 如果配置了delete.topic.enable=true直接通过命令删除,如果命令删除不掉,直接通过zookeeper-client 删除掉"/brokers/topics/"目录下相关topic节点。
注意: 如果你要删除一个topic并且重建,那么必须重新启动kafka,否则新建的topic在zookeeper的/brokers/topics/test-topic/目录下没有partitions这个目录,也就是没有分区信息。
六、安装Yahoo kafka manager
1. Yahoo kafka manager介绍
项目地址:https://github.com/yahoo/kafka-manager
Requirements:
- Kafka 0.8.1.1 or 0.8.2.*
- sbt 0.13.x
- Java 8+
Kafka Manager是一个管控台,这款工具主要支持以下几个功能:
- 管理多个不同的集群;
- 很容易地检查集群的状态(topics, brokers, 副本的分布, 分区的分布);
- 选择副本;
- 产生分区分配(Generate partition assignments)基于集群的当前状态;
- 重新分配分区。
2. 环境信息
| 主机名 | 操作系统版本 | IP地址 | 安装软件 |
| console | CentOS 7.0 | 114.55.29.246 | JDK1.8、kafka-manager-1.3.0.6.zip |
Kafka Manager可以装在任何一台机器上,我这里部署在一台单独的机器上。
3. 安装jdk1.8
[root@console local]# tar zxf jdk-8u73-linux-x64.gz -C /usr/java/
[root@console ~]# vim /etc/profile
export JAVA_HOME=/usr/java/jdk1..0_73
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
[root@console ~]# source /etc/profile
安装JDK8
4. 安装sbt0.13.9
[root@console ~]# curl https://bintray.com/sbt/rpm/rpm | sudo tee /etc/yum.repos.d/bintray-sbt-rpm.repo
[root@console ~]# yum install -y sbt
安装sbt0.13.9
5. 构建kafka manager包
[root@console ~]# git clone https://github.com/yahoo/kafka-manager.git
[root@console ~]# unzip -oq kafka-manager-upgrade-to-.zip
[root@console ~]# mv kafka-manager-upgrade-to- kafka-manager
[root@console ~]# cd kafka-manager
[root@console kafka-manager]# sbt clean dist
The command below will create a zip file which can be used to deploy the application.
使用sbt编译打包的时候时间可能会比较长。
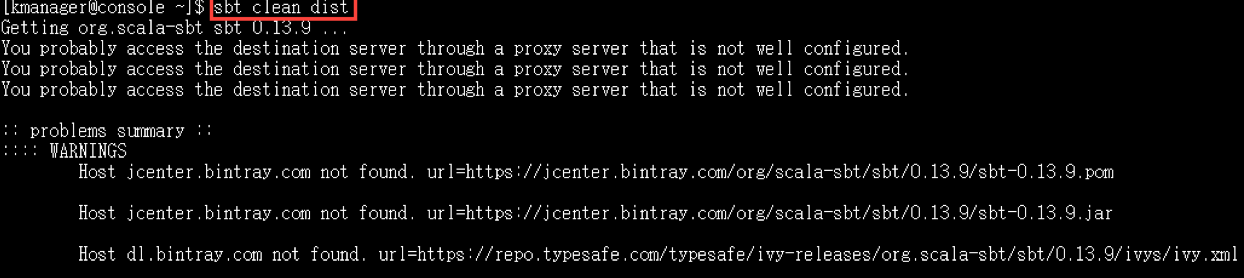
这个需要翻墙才能完成。配置代理:
[root@console ~]# vim /usr/share/sbt-launcher-packaging/conf/sbtconfig.txt
-Dhttp.proxyHost=proxy
-Dhttp.proxyPort=
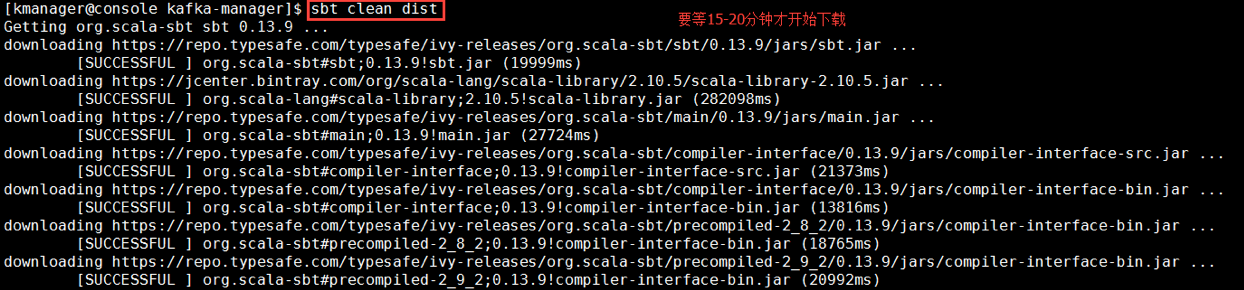
再次运行这个命令,依然需要等待较长的时间,有可能还会失败。如果失败就多次尝试打包:
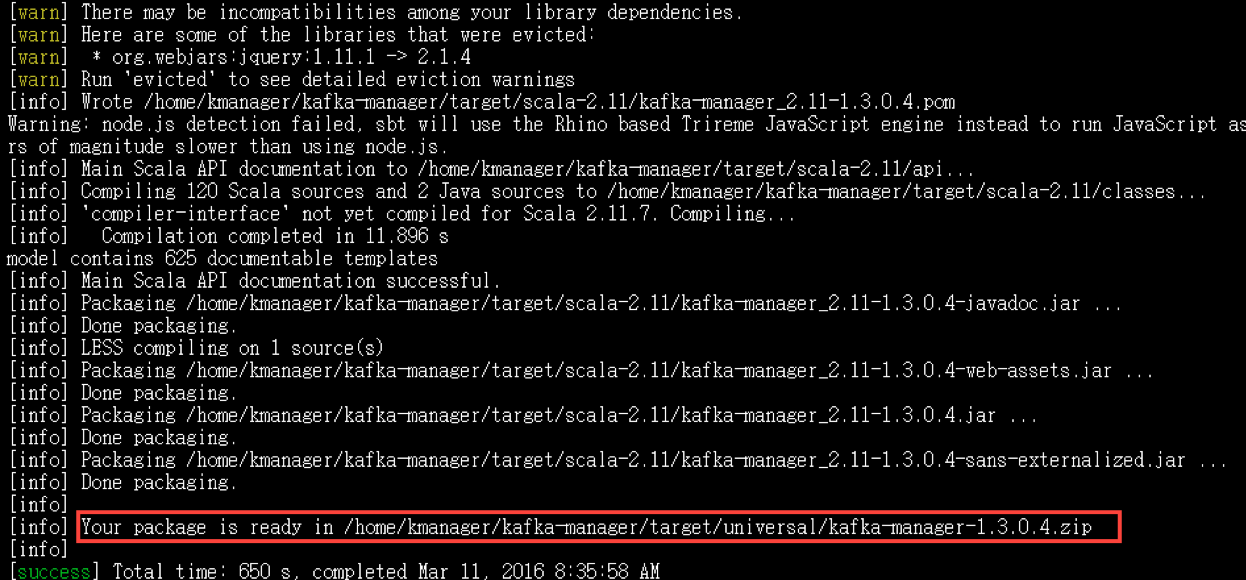
打包完成后会创建一个zip压缩包,而这个压缩包可以用来部署该应用。生成的包会在kafka-manager/target/universal 下面。生成的包只需要java环境就可以运行了,在以后部署到其他机器上不需要安装sbt进行打包构建了。
6. 安装kafka manager
[root@console kafka-manager]# cp target/universal/kafka-manager-1.3.0.6.zip ~/
[root@console kafka-manager]# cd
[root@console ~]# unzip -oq kafka-manager-1.3.0.6.zip
安装kafka manager
7. 配置kafka-manager
[root@console ~]# cd kafka-manager-1.3.0.6/
[root@console kafka-manager-1.3.0.6]# vim conf/application.conf
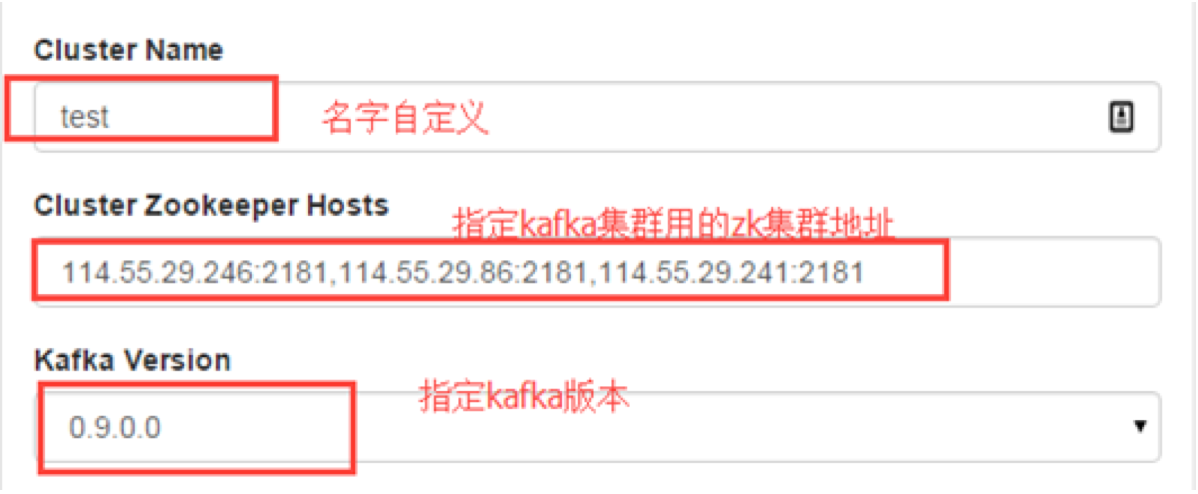
设置zkhosts:
kafka-manager.zkhosts="114.55.29.246:2181,114.55.29.86:2181,114.55.29.241:2181"
8. 启动kafka-manager
[root@console kafka-manager-1.3.0.6]# bin/kafka-manager

默认监听的端口是9000。你也可以在启动时指定配置文件和监听端口:
# bin/kafka-manager -Dconfig.file=/path/to/application.conf -Dhttp.port=
启动并置于后台运行:
[kmanager@console kafka-manager-1.3.0.6]$ nohup bin/kafka-manager > /dev/null >& &
七、kafka-manager添加kafka cluster
浏览器输入地址访问:http://114.55.29.246:9000/
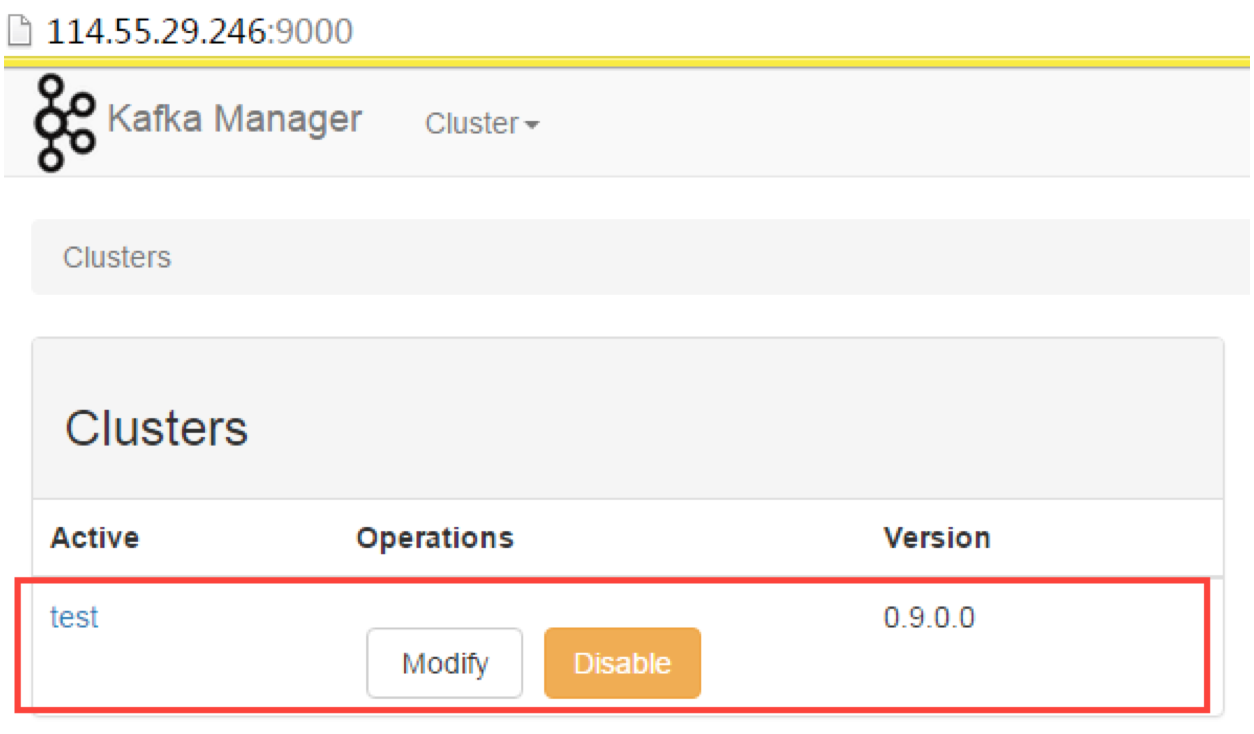
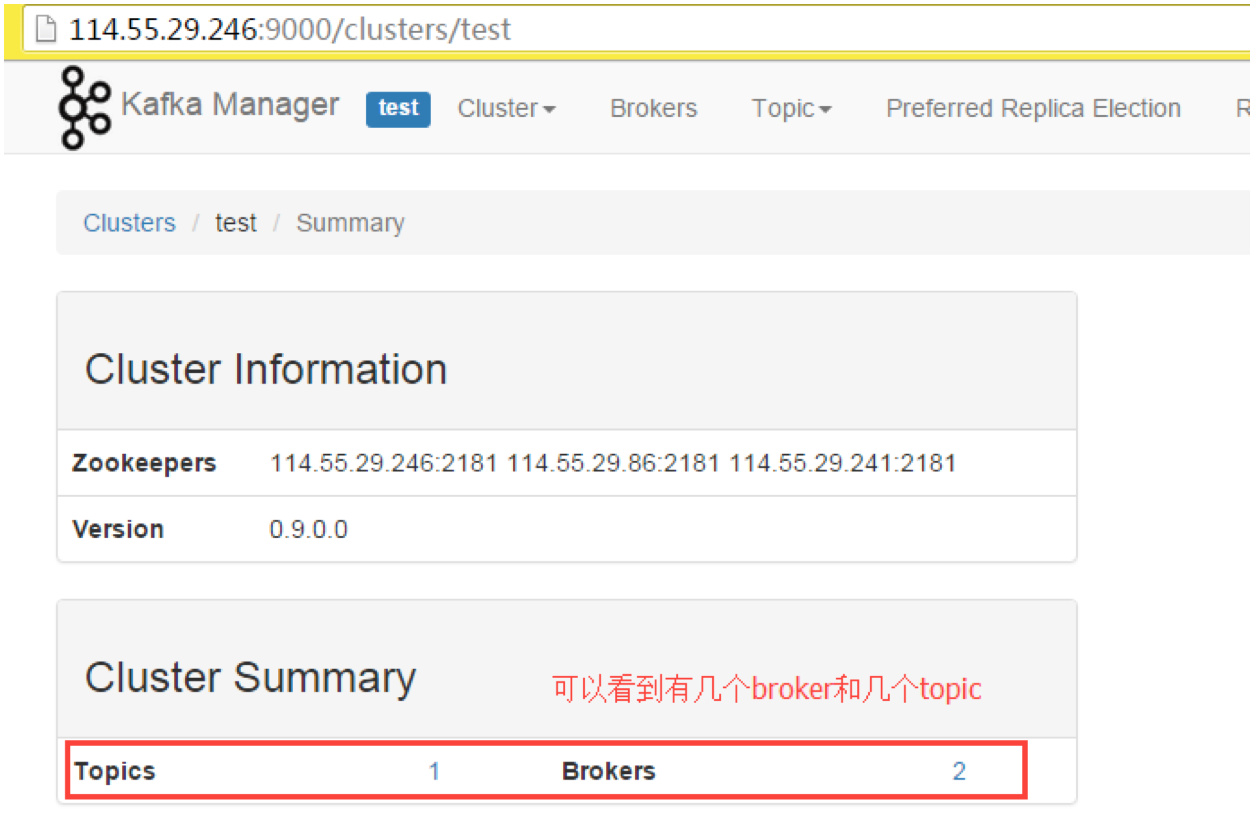
注意:安装完成后需要手动添加Cluster。添加Cluster是指添加一个已有的Kafka集群进入监控列表,而非通过Kafka Manager部署一个新的Kafka Cluster,这一点与Cloudera Manager不同。


Kafka介绍及安装部署的更多相关文章
- Storm介绍及安装部署
本节内容: Apache Storm是什么 Apache Storm核心概念 Storm原理架构 Storm集群安装部署 启动storm ui.Nimbus和Supervisor 一.Apache S ...
- Apache Solr 初级教程(介绍、安装部署、Java接口、中文分词)
Python爬虫视频教程零基础小白到scrapy爬虫高手-轻松入门 https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.482434a6E ...
- hue框架介绍和安装部署
大家好,我是来自内蒙古的小哥,我现在在北京学习大数据,我想把学到的东西分享给大家,想和大家一起学习 hue框架介绍和安装部署 hue全称:HUE=Hadoop User Experience 他是cl ...
- Kafka集群安装部署、Kafka生产者、Kafka消费者
Storm上游数据源之Kakfa 目标: 理解Storm消费的数据来源.理解JMS规范.理解Kafka核心组件.掌握Kakfa生产者API.掌握Kafka消费者API.对流式计算的生态环境有深入的了解 ...
- Spark介绍及安装部署
一.Spark介绍 1.1 Apache Spark Apache Spark是一个围绕速度.易用性和复杂分析构建的大数据处理框架(没有数据存储).最初在2009年由加州大学伯克利分校的AMPLab开 ...
- Hadoop入门进阶课程13--Chukwa介绍与安装部署
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan ...
- Kafka概述及安装部署
一.Kafka概述 1.Kafka是一个分布式流媒体平台,它有三个关键功能: (1)发布和订阅记录流,类似于消息队列或企业消息传递系统: (2)以容错的持久方式存储记录流: (3)记录发送时处理流. ...
- Elasticsearch介绍及安装部署
本节内容: Elasticsearch介绍 Elasticsearch集群安装部署 Elasticsearch优化 安装插件:中文分词器ik 一.Elasticsearch介绍 Elasticsear ...
- Zookeeper介绍及安装部署
本节内容: Zookeeper介绍 Zookeeper特点 Zookeeper应用场景 用到了Zookeeper的一些系统 Zookeeper集群安装部署 一.Zookeeper介绍 是一个针对大型分 ...
随机推荐
- hadoop关联文件处理
c001.txt ------------------------------ filetype|commid|commname|addressidcomm|1|罗湖小区1|1comm|2|罗湖小区2 ...
- 深入理解Auto Layout 第一弹
本文转载至 http://zhangbuhuai.com/2015/07/16/beginning-auto-layout-part-1/ By 张不坏 2015-07-16 更新日期:2015-07 ...
- codeforces水题100道 第九题 Codeforces Beta Round #63 (Div. 2) Young Physicist (math)
题目链接:http://www.codeforces.com/problemset/problem/69/A题意:给你n个三维空间矢量,求这n个矢量的矢量和是否为零.C++代码: #include & ...
- oracle闪回数据
方法一 数据删除了: select * from t_test as of timestamp to_timestamp('2011-10-25 13:45:00','yyyy-mm-dd hh2 ...
- WebService连接sql serever并使用Android端访问数据
一.下载sql serever(真真难下) 建立数据库 二.创建WebService VS2015中新建项目,进行连接调试 1. 服务资源管理文件->数据连接->新建连接 2. 继续-&g ...
- linux mutex
#include <iostream> #include <queue> #include <cstdlib> #include <unistd.h> ...
- jquery.peity.js简介
jQuery简单图表peity.js <html xmlns="http://www.w3.org/1999/xhtml"> <head> <titl ...
- 行逻辑链接的顺序表实现稀疏矩阵的相乘(Java语言描述)
行逻辑链接,带行链接信息.程序有空指针BUG,至今未解决.还是C/C++适合描述算法数据结构.以后复杂的算法还是改用C/C++吧. 有BUG的代码,总有一天会换成没有BUG的. package 行逻辑 ...
- 【前端安全】JavaScript防http劫持与XSS (转)
作为前端,一直以来都知道HTTP劫持与XSS跨站脚本(Cross-site scripting).CSRF跨站请求伪造(Cross-site request forgery).但是一直都没有深入研究过 ...
- 报错--"npm audit fix" or "npm audit"
如图: 根据提示输入 npm audit fix --force 如图: 根据提示输入: npm audit