solr入门之搜索建议的几种实现方式和最终选取实现思路
上篇博客中我简单的讲了下solr自身的suggest模块来实现搜索建议.但是今天研究了下在solr自身的suggest中添加进去拼音来智能推荐时不时很方便.在次从网上搜集和整理思考了下该问题的解决.
问题背景
搜索关键字智能提示是一个搜索应用的标配,主要作用是避免用户输入错误的搜索词,并将用户引导到相应的关键词上,以提升用户搜索体验。
美团CRM系统中存在数以百万计的商家,为了让用户快速查找到目标商家,我们基于solrcloud实现了商家搜索模块。用户在查找商家时主要输入 商户名、商户地址进行搜索,为了提升用户的搜索体验和输入效率,本文实现了一种基于solr前缀匹配查询关键字智能提示(Suggestion)实现。
需求分析
支持前缀匹配原则
在搜索框中输入“海底”,搜索框下面会以海底为前缀,展示“海底捞”、“海底捞火锅”、“海底世界”等等搜索词;输入“万达”,会提示“万达影城”、“万达广场”、“万达百货”等搜索词。同时支持汉字、拼音输入
由于中文的特点,如果搜索自动提示可以支持拼音的话会给用户带来更大的方便,免得切换输入法。比如,输入“haidi”提示的关键字和输入“海底”提示的一样,输入“wanda”与输入“万达”提示的关键字一样。支持多音字输入提示
比如输入“chongqing”或者“zhongqing”都能提示出“重庆火锅”、“重庆烤鱼”、“重庆小天鹅”。支持拼音缩写输入
对于较长关键字,为了提高输入效率,有必要提供拼音缩写输入。比如输入“hd”应该能提示出“haidi”相似的关键字,输入“wd”也一样能提示出“万达”关键字。基于用户的历史搜索行为,按照关键字热度进行排序
为了提供suggest关键字的准确度,最终查询结果,根据用户查询关键字的频率进行排 序,如输入[重庆,chongqing,cq,zhongqing,zq] —> [“重庆火锅”(f1),“重庆烤鱼”(f2),“重庆小天鹅”(f3),…],查询频率f1 > f2 > f3。
解决方案
关键字收集
当用户输入一个前缀时,碰到提示的候选词很多的时候,如何取舍,哪些展示在前面,哪些展示在 后面?这就是一个搜索热度的问题。用户在使用搜索引擎查找商家时,会输入大量的关键字,每一次输入就是对关键字的一次投票,那么关键字被输入的次数越多, 它对应的查询就比较热门,所以需要把查询的关键字记录下来,并且统计出每个关键字的频率,方便提示结果按照频率排序。搜索引擎会通过日志文件把用户每次检 索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。汉字转拼音
用户输入的关键字可能是汉字、数字,英文,拼音,特殊字符等等,由于需要实现拼音提示,我们需要把汉字转换成拼音,java中考虑使用pinyin4j组件实现转换。拼音缩写提取
考虑到需要支持拼音缩写,汉字转换拼音的过程中,顺便提取出拼音缩写,如“chongqing”,"zhongqing"--->"cq",”zq”。多音字全排列
要支持多音字提示,对查询串转换成拼音后,需要实现一个全排列组合,字符串多音字全排列算法如下:public static List getPermutationSentence(List<list> termArrays,int start) {
- if (CollectionUtils.isEmpty(termArrays))
- return Collections.emptyList();
- int size = termArrays.size();
- if (start < 0 || start >= size) {
- return Collections.emptyList();
- }
- if (start == size-1) {
- return termArrays.get(start);
- }
- List<String> strings = termArrays.get(start);
- List<String> permutationSentences = getPermutationSentence(termArrays, start + 1);
- if (CollectionUtils.isEmpty(strings)) {
- return permutationSentences;
- }
- if (CollectionUtils.isEmpty(permutationSentences)) {
- return strings;
- }
- List<String> result = new ArrayList<String>();
- for (String pre : strings) {
- for (String suffix : permutationSentences) {
- result.add(pre+suffix);
- }
- }
- return result;
}
索引与前缀查询
方案一 Trie树 + TopK算法
Trie树即字典树,又称单 词查找树或键树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频 统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。Trie是一颗存储多个字符串的树。相邻节点间的边代表一个字符,这样树的每条 分支代表一则子串,而树的叶节点则代表完整的字符串。和普通树不同的地方是,相同的字符串前缀共享同一条分支。例如,给出一组单词inn, int, at, age, adv, ant, 我们可以得到下面的Trie:
从 上图可知,当用户输入前缀i的时候,搜索框可能会展示以i为前缀的“in”,“inn”,”int"等关键词,再当用户输入前缀a的时候,搜索框里面可能 会提示以a为前缀的“ate”等关键词。如此,实现搜索引擎智能提示suggestion的第一个步骤便清晰了,即用trie树存储大量字符串,当前缀固 定时,存储相对来说比较热的后缀。
TopK算法用于解决统计热词的问题。解决TopK问题主要有两种策略:hashMap统计+排序、堆排序
hashmap 统计: 先对这批海量数据预处理。具体方法是:维护一个Key为Query字串,Value为该Query出现次数的HashTable,即 hash_map(Query,Value),每次读取一个Query,如果该字串不在Table中,那么加入该字串,并且将Value值设为1;如果该 字串在Table中,那么将该字串的计数加一即可,最终在O(N)的时间复杂度内用Hash表完成了统计。
堆排序:借助堆这个数据结构,找出 Top K,时间复杂度为N‘logK。即借助堆结构,我们可以在log量级的时间内查找和调整/移动。因此,维护一个K(该题目中是10)大小的小根堆,然后遍 历300万的Query,分别和根元素进行对比。所以,我们最终的时间复杂度是:O(N) + N' * O(logK),(N为1000万,N’为300万)。
该方案存在的问题是:
- 建索引和查询的时候都要把汉字转换成拼音,查询完成后还得把拼音转换成汉字显示,且需要考虑数字和特殊字符。
- 需要维护拼音、缩写两棵Trie树。
方案二 Solr自带Suggest智能提示
Solr作为一个应用广泛的搜索引擎系统,它内置了智能提示功能,叫做Suggest模块。该模块可选择基于提示词文本做智能提示,还支持通过针对索引的某个字段建立索引词库做智能提示。 (详见solr的wiki页面http://wiki.apache.org/solr/Suggester)
该方案存在的问题是:
- 返回的结果是基于索引中字段的词频进行排序,不是用户搜索关键字的频率,因此不能将一些热门关键字排在前面。
- 拼音提示,多音字,缩写还是要另外加索引字段。
方案三 Solrcloud建立单独的collection,利用solr前缀查询实现
如前所述,以上 两个方案在实施起来都存在一些问题,Trie树+TopK算法,在处理汉字suggest时不是很优雅,且需要维护两棵Trie树,实施起来比较复 杂;Solr自带的suggest智能提示组件存在问题是使用freq排序算法,返回的结果完全基于索引中字符的出现次数,没有兼顾用户搜索词语的频率, 因此无法将一些热门词排在更靠前的位置。于是,我们继续寻找一种解决这个问题更加优雅的方案。
至此,我们考虑专门为关键字建立一个索引collection,利用solr前缀查询实现。solr中的copyField能很好解决我们同时索引 多个字段(汉字、pinyin, abbre)的需求,且field的multiValued属性设置为true时能解决同一个关键字的多音字组合问题。配置如下:
- schema.xml:
- <field name="kw" type="string" indexed="true" stored="true" />
- <field name="pinyin" type="string" indexed="true" stored="false" multiValued="true"/>
- <field name="abbre" type="string" indexed="true" stored="false" multiValued="true"/>
- <field name="kwfreq" type="int" indexed="true" stored="true" />
- <field name="_version_" type="long" indexed="true" stored="true"/>
- <field name="suggest" type="suggest_text" indexed="true" stored="false" multiValued="true" />
- ------------------multiValued表示字段是多值的-------------------------------------
- <uniqueKey>kw</uniqueKey>
- <defaultSearchField>suggest</defaultSearchField>
- 说明:
- kw为原始关键字
- pinyin和abbre的multiValued=true,在使用solrj建此索引时,定义成集合类型即可:如关键字“重庆”的pinyin字段为{chongqing,zhongqing}, abbre字段为{cq, zq}
- kwfreq为用户搜索关键的频率,用于查询的时候排序
- -------------------------------------------------------
- <copyField source="kw" dest="suggest" />
- <copyField source="pinyin" dest="suggest" />
- <copyField source="abbre" dest="suggest" />
- ------------------suggest_text----------------------------------
- <fieldType name="suggest_text" class="solr.TextField" positionIncrementGap="100" autoGeneratePhraseQueries="true">
- <analyzer type="index">
- <tokenizer class="solr.KeywordTokenizerFactory" />
- <filter class="solr.SynonymFilterFactory"
- synonyms="synonyms.txt"
- ignoreCase="true"
- expand="true" />
- <filter class="solr.StopFilterFactory"
- ignoreCase="true"
- words="stopwords.txt"
- enablePositionIncrements="true" />
- <filter class="solr.LowerCaseFilterFactory" />
- <filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt" />
- </analyzer>
- <analyzer type="query">
- <tokenizer class="solr.KeywordTokenizerFactory" />
- <filter class="solr.StopFilterFactory"
- ignoreCase="true"
- words="stopwords.txt"
- enablePositionIncrements="true" />
- <filter class="solr.LowerCaseFilterFactory" />
- <filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt" />
- </analyzer>
- </fieldType>
KeywordTokenizerFactory:这个分词器不进行任何分词!整个字符流变为单个词元。String域类型也有类似的效果,但是它 不能配置文本分析的其它处理组件,比如大小写转换。任何用于排序和大部分Faceting功能的索引域,这个索引域只有能一个原始域值中的一个词元。
前缀查询构造:
- private SolrQuery getSuggestQuery(String prefix, Integer limit) {
- SolrQuery solrQuery = new SolrQuery();
- StringBuilder sb = new StringBuilder();
- sb.append(“suggest:").append(prefix).append("*");
- solrQuery.setQuery(sb.toString());
- solrQuery.addField("kw");
- solrQuery.addField("kwfreq");
- solrQuery.addSort("kwfreq", SolrQuery.ORDER.desc);
- solrQuery.setStart(0);
- solrQuery.setRows(limit);
- return solrQuery;
- }
效果如下图所示:
参考
- 从Trie树谈到后缀树 http://blog.csdn.net/v_july_v/article/details/6897097
- 搜索智能提示suggestion,附近地点搜索 http://blog.csdn.net/v_july_v/article/details/11288807
- solr suggester http://wiki.apache.org/solr/Suggester
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
方案实践---基础solr自身的suggest来实现 1.在中文建议后如何添加拼音建议? ---无法实现 2.使用新建库来实现suggest功能
基本实现原理
分词采用String方式 suggest:名星* mx* mingxing* 此种方式 将显示以指定字符开头的字段
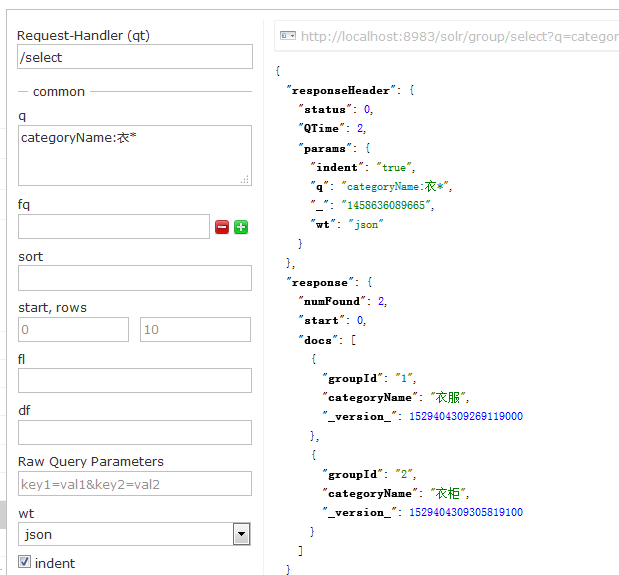
将原始词语放入一个多值的字段中,再将其经过处理的拼音也放入其中(类似第三个方法不过不需要写OR了) 索引存放成功后,再设置词频字段进行排序即可
其实就是上述第三种方案的实现和简单的优化. 涉及到拼音建议的问题就需要使用到拼音工具类来完成这个问题.
这个方法我放在下篇博客中讲解.
solr入门之搜索建议的几种实现方式和最终选取实现思路的更多相关文章
- 第二章 Vue快速入门-- 17 v-for指令的四种使用方式
1.v-for循环普通数组 <!DOCTYPE html> <html lang="en"> <head> <meta charset=& ...
- SpringMVC请求后台地址URL没有.*的几种实现方式
今天做项目,由于项目是通过扫二维码进入,二维码存放的地址不希望有 .do,而是http:xxxx:8080/xxx/yyy/zzz的格式(zzz为参数),但是项目其它请求url后面都必须要有.do,想 ...
- solr入门之參考淘宝搜索提示功能优化拼音加汉字搜索功能
首先看一下从淘宝输入搜索keyword获取到的一些数据信息: 第一张:使用拼音的全程来查询 能够看到提示的是匹配的转换的拼音的方式,看最后一个提示项 这里另一个在指定分类文件夹下搜索的功能,难道后台还 ...
- Apache Solr入门教程(初学者之旅)
Apache Solr入门教程(初学者之旅) 写在前面:本文涉及solr入门的各方面,建议边思考边实践,相信能帮助你对solr有个清晰全面的了解并能简单实用. 在Apache Solr初学者教程的这个 ...
- 后端技术杂谈4:Elasticsearch与solr入门实践
阮一峰:全文搜索引擎 Elasticsearch 入门教程 作者:阮一峰 本系列文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查看 https://g ...
- Solr入门之SolrServer实例化方式
随着solr版本的不断升级, 差异越来越大, 从以前的 solr1.2 到现在的 solr4.3, 无论是类还是功能都有很大的变换, 为了能及时跟上新版本的步伐, 在此将新版本的使用做一个简单的入门说 ...
- SOLR搭建企业搜索平台
一. SOLR搭建企业搜索平台 运行环境: 运行容器:Tomcat6.0.20 Solr版本:apache-solr-1.4.0 分词器:mmseg4j-1.6.2 词库:sogou-dic ...
- Solr入门指南
本文转自http://chuanliang2007.spaces.live.com/blog/cns!E5B7AB2851A4C9D2!499.entry?wa=wsignin1.0 因为搜索引擎功能 ...
- Solr入门和实践以及我对Solr的8点理解
友情提示Solr的内容还是比较多的,一篇文章只能讲解一部分.全面介绍,没兴趣,没时间,也没能力,回报还不大.本文只写点我认为比较重要的知识点,独特的个人想法.仅供参考哦,更多细节需要自己去琢磨. 概述 ...
随机推荐
- UI基础:UI程序执行顺序(UIApplicationMain()函数),自定义视图 分类: iOS学习-UI 2015-07-02 22:09 68人阅读 评论(0) 收藏
UI程序的一般执行顺序: 先进入main里面,执行函数UIApplicationMain(),通过该函数创建应用程序对象和指定其代理并实现监听,当执行函数UIApplicationMain()时还会做 ...
- rar ubuntu
http://jingyan.baidu.com/article/1612d5004095eee20e1eeeab.html sudo 7z x ***.rar
- stm32 看门狗配置
1.独立看门狗: 1) 取消寄存器写保护(向 IWDG_KR 写入 0X5555) IWDG_WriteAccessCmd(IWDG_WriteAccess_Enable); //使能或者失能 2) ...
- Adobe Flash Player - imsoft.cnblogs
Adobe Flash Player是一个跨平台.基于浏览器的应用程序.运行时,它可以跨屏幕和浏览器原汁原味地查看具有表现力的应用程序.内容和视频.Flash Player实现了移动屏幕上的高性能优化 ...
- EXCEL教程,包你一学就会
片名称:自动筛选 照片名称:在Excel中字符替换 照片名称:在Excel中直接编辑“宏” 照片名称:在Excel中为导入外部数据 照片名称:在Excel中行列快速转换 照片名称:在Excel中运行“ ...
- Spring如何解析XML文件——Spring源码之XML初解析
首先,在我的这篇博客中已经说到容器是怎么初步实现的,并且要使用XmlBeanDefinitionReader对象对Xml文件进行解析,那么Xml文件是如何进行解析的,将在这片博客中进行一些陈述. 数据 ...
- 谈ObjC对象的两段构造模式
前言 Objective-c语言在申请对象的时,需要使用两段构造(Two Stage Creation)的模式.一个对象的创建,需要先调用alloc方法或allocWithZone方法,再调用init ...
- Immutable集合
转自:https://blog.csdn.net/michaellufhl/article/details/6314333 大家都知道JDK提供了Collections.UnmodifiableLis ...
- spring boot 好文
配置: https://www.jianshu.com/p/3af2a8721d86 : Spring Boot启动报错:Whitelabel Error Page 分页: https://bbs.c ...
- LG2375 [NOI2014]动物园
题意 给定一个长为\(L\)的字符串(\(L \leq 1e6\)) 求一个\(num\)数组,\(num[i]\)表示长度为\(i\)的前缀中字符串\(S'\)的数量,其中\(S'\)既是该前缀的前 ...